awk中FS的一點細節
在學習Effective awk Program。在工作中雖然shell也算是自己的常規武器,但是shell的運用並不純熟,把書中自己理解不深,或者沒注意到的地方記錄一下,畢竟每次看英文書有點重點不突出。
Effective awk Program 第三章Reading Input Files中的Using Regular Expression to Separate Fields中提到了一個很有趣的現象。
echo " a b c d " | awk '{ print $2 }'
echo " a b c d " | awk 'BEGIN {FS="[ \t\n]"} {print $2}'
這兩個的輸出是否一致,我學習這一章節之前,認為輸出是相同的,都是b。實際上:
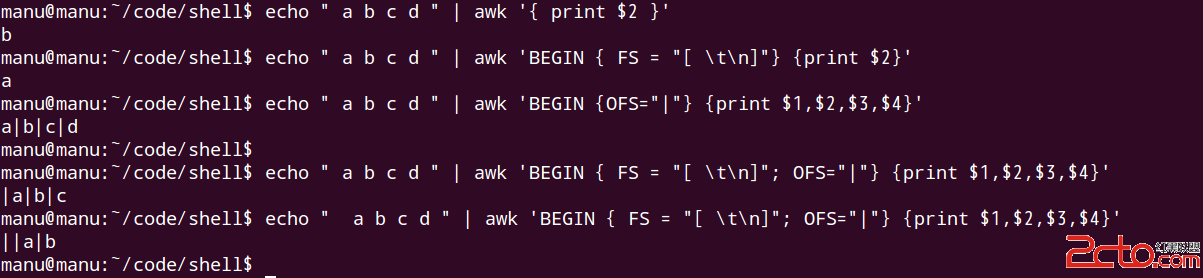
我們看到第一個命令和第二個命令的輸出是不一樣的。原因在於,默認的情況下,FS是空格,這種情況下,處理之前,首先會將strip掉頭部的空格和tab,以及尾部的空格和tab,但是如果FS修改成[ \t\n]這種形式,就不會strip掉頭部和尾部的空白字符,那麼,如果頭部有1個空格,我們看到$1是null或者empty。
另一個比較有意思的現象是,如果record重新組建,會導致頭部和尾部的空白字符strip掉。
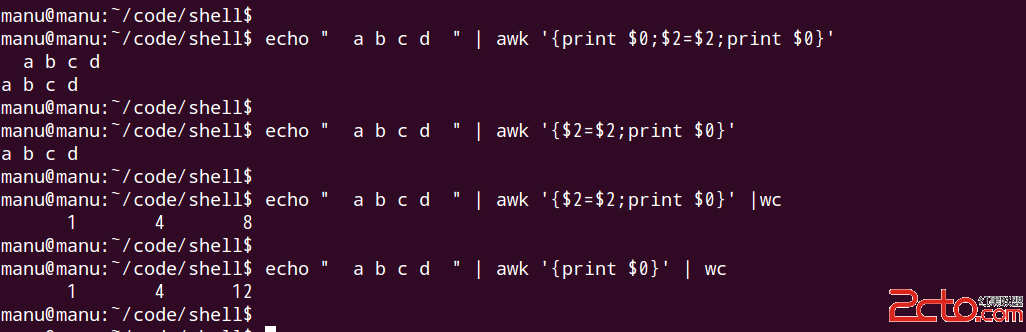
我們看到,僅僅是執行了$2=$2這個看起來毫無意義的操作,頭部的空格就被strip掉了,事實上尾部的2個空格也被strip掉了。因為賦值操作引發了字符串的rebuild,而rebuild的過程要查找$1,$2...$NF,鏈接起來,查找$1的過程等同與FS=“ ”的時候的$1,空白字符(空格和tab)會被忽略掉,所以,concatenated string 也就沒有頭部和尾部的空白字符了。