今天這篇文章接著昨天的相關知識,一樣是為了前天剛做的mysql熱備;
大家知道實現mysql_Ha的方案有很多,常見的heartbeat、keepalived,這裡說的就是keepalived,優點就是簡單,快速,下面就是詳情了;
1、系統:Centos6.0;lamp平台(lamp平台是我一個習慣,非必須)
vip:192.168.135.200
master:192.168.135.134
slave:192.168.135.135
實現134實時復制135,135實時復制134,也就是說修改每一個數據庫都會數據統一,master機器配置好點,我這邊配置preempt(搶占),也就說134掛了以後,135提供服務,134恢復以後,繼續134為master提供服務;
master(192.168.135.134)操作:
yum install http mysql* php* ipvsadm keepalived -y
1>、修改MySQL配置文件
兩台MySQL均要開啟binlog日志功能,在MySQL配置文件[MySQLd]段中加上log-bin=mysql-bin選項
兩台MySQL的server-ID不能一樣,默認情況下兩台MySQL的serverID都是1,、其中一台修改為2;
2>、初始化下服務
service httpd restart
service mysqld restart
關閉服務:service iptables stop
修改selinux
3>、首先先將兩台機器的同步做好;
master:同步slave上的數據庫
授權用戶;grant replication slave on *.* to 'leo'@'%' identified by 'leo123';
![]()
查詢主數據庫狀態;並記下FILE及Position的值,這個在後面配置從服務器的時候要用到。
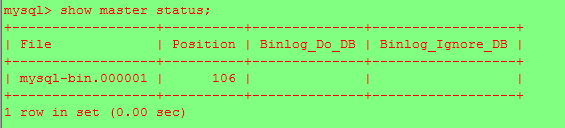
在另一台(slave)機器操作將此台機器設置為主服務器
change master to master_host='192.168.135.134',master_user='leo',master_password='leo123',master_log_file='mysql-bin.000001',master_log_pos=106;
![]()
授權用戶;
grant replication slave on *.* to 'leo'@'%' identified by 'leo123';
同樣查詢主數據庫狀態
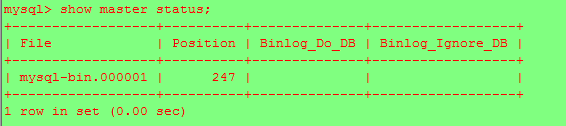
在另一台(master)機器操作將此台機器設置為主服務器
change master to master_host='192.168.135.135',master_user='leo',master_password='leo123',master_log_file='mysql-bin.000001',master_log_pos=247;
![]()
然後兩台機器同時啟動slave
start slave
查看slave狀態
檢查主從同步,如果您看到Slave_IO_Running和Slave_SQL_Running均為Yes,則主從復制連接正常。
show slave status\G
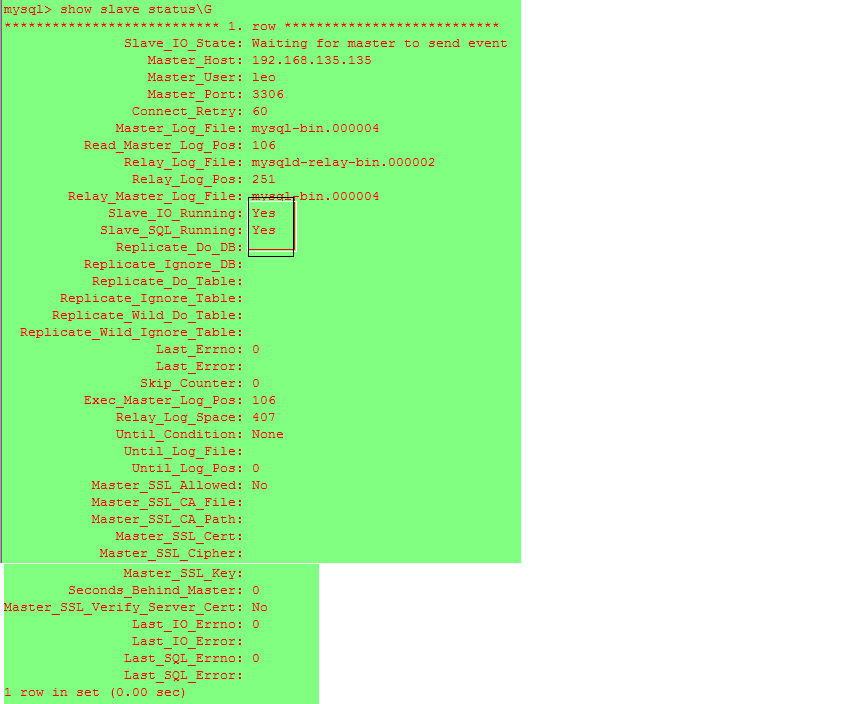
重點查看圈住的地方
在slave機器上同樣查看是否正常
test:現在在兩台服務器上其中一台,修改下數據,看看另一台的狀況是否也修改,比如:
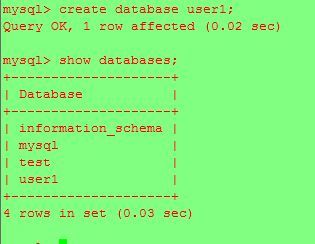
在另一台發現已經同步過去了;
2、接下來配置keepalived
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
全局定義(global definition)配置
global_defs {
notification_email {
[email protected] 故障聯系人
}
notification_email_from [email protected] 故障發送人
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id Mysql_ha
}
global_defs全局配置標識
notification_email
{
[email protected]
[email protected]
}
VRRP實例(instance)
vrrp_instance mysql{
state MASTER state 指定instance(Initial)的初始狀態,實質是經過優先級決定
interface eth0 實例綁定的網卡,因為在配置虛擬IP的時候必須是在已有的網卡上添加的
virtual_router_id 50 這裡設置VRID,這裡非常重要,相同的VRID為一個組,他將決定多播的MAC地址
priority 100 設置本節點的優先級,優先級高的為master
advert_int 1 檢查間隔,默認為1秒
preempt 設置搶占,這裡只能設置在state為master的節點上,而且這個節點的優先級必須別另外的高
authentication {
auth_type PASS 認證方式,可以是PASS或AH兩種認證方式
auth_pass 123456 認證密碼
}
virtual_ipaddress {
192.168.152.200 這裡設置的就是VIP,也就是虛擬IP地址,他隨著state的變化而增加刪除,
}
}
virtual_server 192.168.135.200 3306 { 設置一個virtual server: VIP:Vport
delay_loop 2 service polling的delay時間,即服務輪詢的時間間隔
lb_algo wrr LVS調度算法 rr|wrr|lc|wlc|lblc|sh|dh
lb_kind DR LVS集群模式 NAT|DR|TUN
persistence_timeout 60 會話保持時間(秒為單位),即以用戶在120秒內被分配到同一個後端realserver
protocol TCP 健康檢查用的是TCP還是UDP
real_server 192.168.135.134 3306 { 後端真實節點主機的權重等設置,主要,後端有幾台這裡就要設置幾個
weight 3 給每台的權重,0表示失效(不知給他轉發請求知道他恢復正常),默認是1
# notify_up <STRING> | <QUOTED-STRING> #檢查服務器正常(UP)後,要執行的腳本
notify_down /usr/local/Mysql/bin/mysql.sh 檢查服務器失敗(down)後,要執行的腳本
#下面是常用的健康檢查方式,健康檢查方式一共有HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK這些方式
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
}
編寫檢測服務down後所要執行的腳本
#!/bin/sh pkill keepalived
簡單吧,只要mysqld進程不見了,就殺掉keepalived,讓備機頂替
3、在備機操作keepalived
上master的基本一樣,只是幾個地方修改下而已
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id Mysql_ha
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.135.200
}
}
virtual_server 192.168.135.200 3306 {
delay_loop 2
lb_algo wrr
lb_kind DR
persistence_timeout 10
protocol TCP
real_server 192.168.135.135 3306 {
weight 3
notify_down /usr/local/Mysql/bin/mysql.sh
TCP_CHECK {
connect_timeout 10
nb_get_retry 3
delay_before_retry 3
connect_port 3306
}
}
}
找一台機器進行測試
ping 192.168.135.200(vip)
正常,當把master上mysqld殺掉,發現keepalived進程也不見了,說明我們的腳本觸發了,但是vip還是可以ping通,說明備機起作用了;
大家也可以查看vrrp協議的信息;根據優先級100或90進行判斷

黑線的地方說明備機頂替了;
當把master的mysqld進程和keepalived重啟後發現:

說明master又頂替了slave;進行了搶占
繼續測試
再兩台機器上授權遠程登錄、操作
grant all privileges on *.* to 'root'@'%' identified by '1234567890';
找一台機器mysql -h 192.168.135.200 -p 1234567890
可以進行查看,當你新增,比如create個數據庫,發現兩台機器也是可以同步的,過程是你先寫入了當前服務的機器,然後另一台進行了同步;
為了方便查看keepalived的日志,我們可以單獨將他的日志寫入個日志文件,請查看前面的博文
http://lansgg.blog.51cto.com/5675165/1178903
當我們將服務器更換IP或是停掉slave,然後開啟後發現其狀態異常,
show slave status\G 可以看到,表現如下
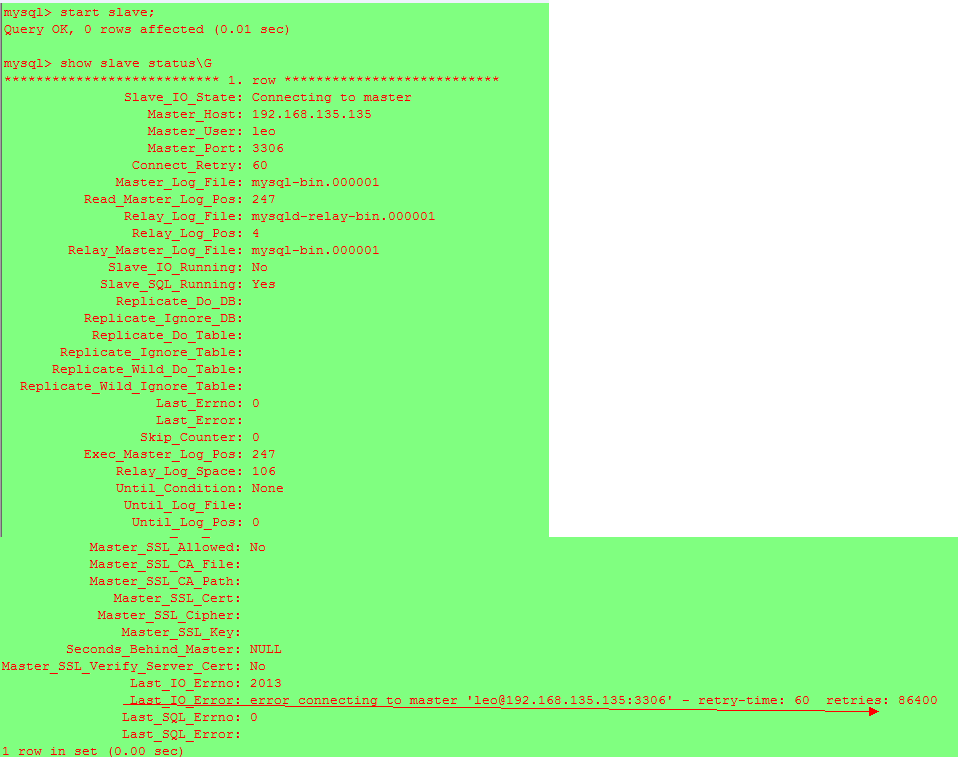
解決方法如下:
分別在兩台機器
stop slave;
flush logs;
show master status;
再次分別執行:
change master to master_host='192.168.135.XXX',master_user='leo',master_password='leo123',master_log_file='mysql-bin.XXXXXX',master_log_pos=XXX;
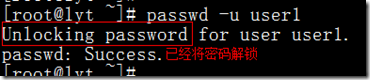
提示 不同步Mysql數據庫,當上線後,發現修改一個機器的密碼,兩台機器重啟服務後,另一台機器的密碼也修改了,只要修改my.cnf即可讓其不同步Mysql數據庫
新加:binlog-ignore-db=mysql (不同步mysql庫)
在show master status;是可以看到的
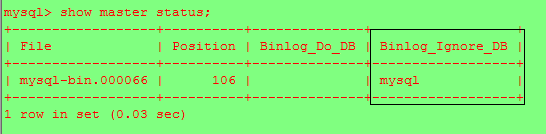
同樣發現,新加binlog_do_db=xxx可以指定同步某庫
這樣即可;
大概先寫到這裡,以後會編寫heartbeat的方法,希望大家可以多多交流,指出問題,共同進步
出處:http://lansgg.blog.51cto.com/5675165/1180305