Hadoop 由 Apache Software Foundation 公司於 2005 年秋天作為 Lucene 的子項目 Nutch 的一部分正式引入。它受到最先由 Google Lab 開發的 MapReduce 和 Google File System 的啟發。2006 年 3 月份,MapReduce 和 Nutch Distributed File System (NDFS) 分別被納入稱為 Hadoop 的項目中。
Hadoop 是最受歡迎的在 Internet 上對搜索關鍵字進行內容分類的工具,但它也可以解決許多要求極大伸縮性的問題。例如,如果您要 grep 一個 10TB 的巨型文件,會出現什麼情況?在傳統的系統上,這將需要很長的時間。但是 Hadoop 在設計時就考慮到這些問題,因此能大大提高效率。
先決條件
Hadoop 是一個能夠對大量數據進行分布式處理的軟件框架。但是 Hadoop 是以一種可靠、高效、可伸縮的方式進行處理的。Hadoop 是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。Hadoop 是高效的,因為它以並行的方式工作,通過並行處理加快處理速度。Hadoop 還是可伸縮的,能夠處理 PB 級數據。此外,Hadoop 依賴於社區服務器,因此它的成本比較低,任何人都可以使用。
您可能已經想到,Hadoop 運行在 Linux 生產平台上是非常理想的,因為它帶有用 Java™ 語言編寫的框架。Hadoop 上的應用程序也可以使用其他語言編寫,比如 C++。
Hadoop 架構
Hadoop 有許多元素構成。最底部是 Hadoop Distributed File System(HDFS),它存儲 Hadoop 集群中所有存儲節點上的文件。HDFS(對於本文)的上一層是 MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。
HDFS
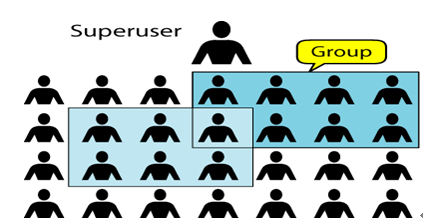
對外部客戶機而言,HDFS 就像一個傳統的分級文件系統。可以創建、刪除、移動或重命名文件,等等。但是 HDFS 的架構是基於一組特定的節點構建的(參見圖 1),這是由它自身的特點決定的。這些節點包括 NameNode(僅一個),它在 HDFS 內部提供元數據服務;DataNode,它為 HDFS 提供存儲塊。由於僅存在一個 NameNode,因此這是 HDFS 的一個缺點(單點失敗)。
圖 1. Hadoop 集群的簡化視圖
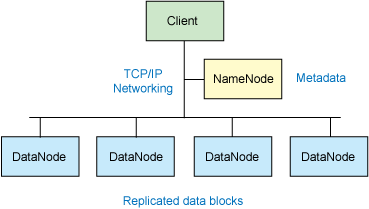
存儲在 HDFS 中的文件被分成塊,然後將這些塊復制到多個計算機中(DataNode)。這與傳統的 RAID 架構大不相同。塊的大小(通常為 64MB)和復制的塊數量在創建文件時由客戶機決定。NameNode 可以控制所有文件操作。HDFS 內部的所有通信都基於標准的 TCP/IP 協議。
NameNode
NameNode 是一個通常在 HDFS 實例中的單獨機器上運行的軟件。它負責管理文件系統名稱空間和控制外部客戶機的訪問。NameNode 決定是否將文件映射到 DataNode 上的復制塊上。對於最常見的 3 個復制塊,第一個復制塊存儲在同一機架的不同節點上,最後一個復制塊存儲在不同機架的某個節點上。注意,這裡需要您了解集群架構。
實際的 I/O 事務並沒有經過 NameNode,只有表示 DataNode 和塊的文件映射的元數據經過 NameNode。當外部客戶機發送請求要求創建文件時,NameNode 會以塊標識和該塊的第一個副本的 DataNode IP 地址作為響應。這個 NameNode 還會通知其他將要接收該塊的副本的 DataNode。
NameNode 在一個稱為 FsImage 的文件中存儲所有關於文件系統名稱空間的信息。這個文件和一個包含所有事務的記錄文件(這裡是 EditLog)將存儲在 NameNode 的本地文件系統上。FsImage 和 EditLog 文件也需要復制副本,以防文件損壞或 NameNode 系統丟失。
DataNode
NameNode 也是一個通常在 HDFS 實例中的單獨機器上運行的軟件。Hadoop 集群包含一個 NameNode 和大量 DataNode。DataNode 通常以機架的形式組織,機架通過一個交換機將所有系統連接起來。Hadoop 的一個假設是:機架內部節點之間的傳輸速度快於機架間節點的傳輸速度。
DataNode 響應來自 HDFS 客戶機的讀寫請求。它們還響應創建、刪除和復制來自 NameNode 的塊的命令。NameNode 依賴來自每個 DataNode 的定期心跳(heartbeat)消息。每條消息都包含一個塊報告,NameNode 可以根據這個報告驗證塊映射和其他文件系統元數據。如果 DataNode 不能發送心跳消息,NameNode 將采取修復措施,重新復制在該節點上丟失的塊。
文件操作
可見,HDFS 並不是一個萬能的文件系統。它的主要目的是支持以流的形式訪問寫入的大型文件。如果客戶機想將文件寫到 HDFS 上,首先需要將該文件緩存到本地的臨時存儲。如果緩存的數據大於所需的 HDFS 塊大小,創建文件的請求將發送給 NameNode。NameNode 將以 DataNode 標識和目標塊響應客戶機。同時也通知將要保存文件塊副本的 DataNode。當客戶機開始將臨時文件發送給第一個 DataNode 時,將立即通過管道方式將塊內容轉發給副本 DataNode。客戶機也負責創建保存在相同 HDFS 名稱空間中的校驗和(checksum)文件。在最後的文件塊發送之後,NameNode 將文件創建提交到它的持久化元數據存儲(在 EditLog 和 FsImage 文件)。
Linux 集群
Hadoop 框架可在單一的 Linux 平台上使用(開發和調試時),但是使用存放在機架上的商業服務器才能發揮它的力量。這些機架組成一個 Hadoop 集群。它通過集群拓撲知識決定如何在整個集群中分配作業和文件。Hadoop 假定節點可能失敗,因此采用本機方法處理單個計算機甚至所有機架的失敗。
Hadoop 應用程序
Hadoop 的最常見用法之一是 Web 搜索。雖然它不是惟一的軟件框架應用程序,但作為一個並行數據處理引擎,它的表現非常突出。Hadoop 最有趣的方面之一是 Map and Reduce 流程,它受到 Google 開發的啟發。這個流程稱為創建索引,它將 Web 爬行器檢索到的文本 Web 頁面作為輸入,並且將這些頁面上的單詞的頻率報告作為結果。然後可以在整個 Web 搜索過程中使用這個結果從已定義的搜索參數中識別內容。
MapReduce
最簡單的 MapReduce 應用程序至少包含 3 個部分:一個 Map 函數、一個 Reduce 函數和一個 main 函數。main 函數將作業控制和文件輸入/輸出結合起來。在這點上,Hadoop 提供了大量的接口和抽象類,從而為 Hadoop 應用程序開發人員提供許多工具,可用於調試和性能度量等。
MapReduce 本身就是用於並行處理大數據集的軟件框架。MapReduce 的根源是函數性編程中的 map 和 reduce 函數。它由兩個可能包含有許多實例(許多 Map 和 Reduce)的操作組成。Map 函數接受一組數據並將其轉換為一個鍵/值對列表,輸入域中的每個元素對應一個鍵/值對。Reduce 函數接受 Map 函數生成的列表,然後根據它們的鍵(為每個鍵生成一個鍵/值對)縮小鍵/值對列表。
這裡提供一個示例,幫助您理解它。假設輸入域是 one small step for man, one giant leap for mankind。在這個域上運行 Map 函數將得出以下的鍵/值對列表:
(one, 1) (small, 1) (step, 1) (for, 1) (man, 1) (one, 1) (giant, 1) (leap, 1) (for, 1) (mankind, 1)
如果對這個鍵/值對列表應用 Reduce 函數,將得到以下一組鍵/值對:
(one, 2) (small, 1) (step, 1) (for, 2) (man, 1) (giant, 1) (leap, 1) (mankind, 1)
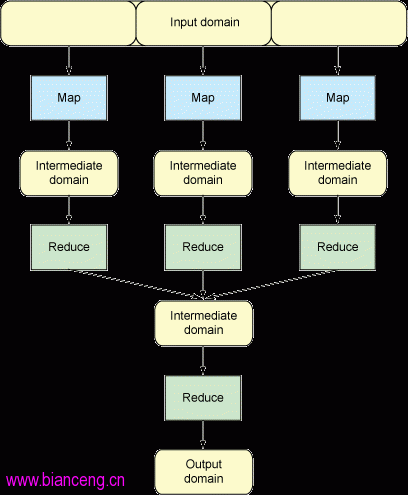
結果是對輸入域中的單詞進行計數,這無疑對處理索引十分有用。但是,現在假設有兩個輸入域,第一個是 one small step for man,第二個是 one giant leap for mankind。您可以在每個域上執行 Map 函數和 Reduce 函數,然後將這兩個鍵/值對列表應用到另一個 Reduce 函數,這時得到與前面一樣的結果。換句話說,可以在輸入域並行使用相同的操作,得到的結果是一樣的,但速度更快。這便是 MapReduce 的威力;它的並行功能可在任意數量的系統上使用。圖 2 以區段和迭代的形式演示這種思想。
圖 2. MapReduce 流程的概念流
現在回到 Hadoop 上,它是如何實現這個功能的?一個代表客戶機在單個主系統上啟動的 MapReduce 應用程序稱為 JobTracker。類似於 NameNode,它是 Hadoop 集群中惟一負責控制 MapReduce 應用程序的系統。在應用程序提交之後,將提供包含在 HDFS 中的輸入和輸出目錄。JobTracker 使用文件塊信息(物理量和位置)確定如何創建其他 TaskTracker 從屬任務。MapReduce 應用程序被復制到每個出現輸入文件塊的節點。將為特定節點上的每個文件塊創建一個惟一的從屬任務。每個 TaskTracker 將狀態和完成信息報告給 JobTracker。圖 3 顯示一個示例集群中的工作分布。
圖 3. 顯示處理和存儲的物理分布的 Hadoop 集群
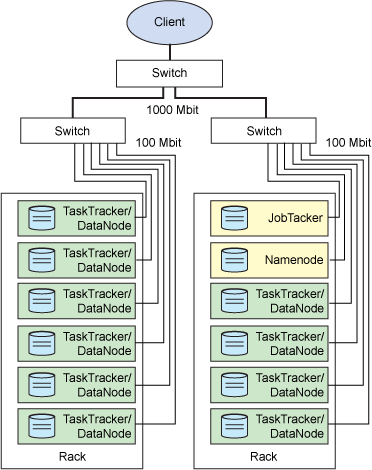
Hadoop 的這個特點非常重要,因為它並沒有將存儲移動到某個位置以供處理,而是將處理移動到存儲。這通過根據集群中的節點數調節處理,因此支持高效的數據處理。
Hadoop 的其他應用程序
Hadoop 是一個用於開發分布式應用程序的多功能框架;從不同的角度看待問題是充分利用 Hadoop 的好方法。回顧一下 圖 2,那個流程以階梯函數的形式出現,其中一個組件使用另一個組件的結果。當然,它不是萬能的開發工具,但如果碰到的問題屬於這種情況,那麼可以選擇使用 Hadoop。
Hadoop 一直幫助解決各種問題,包括超大型數據集的排序和大文件的搜索。它還是各種搜索引擎的核心,比如 Amazon 的 A9 和用於查找酒信息的 Able Grape 垂直搜索引擎。Hadoop Wiki 提供了一個包含大量應用程序和公司的列表,這些應用程序和公司通過各種方式使用 Hadoop(參見 參考資料)。
當前,Yahoo! 擁有最大的 Hadoop Linux 生產架構,共由 10,000 多個內核組成,有超過 5PB 字節的儲存分布到各個 DataNode。在它們的 Web 索引內部差不多有一萬億個鏈接。不過您可能不需要那麼大型的系統,如果是這樣的話,您可以使用 Amazon Elastic Compute Cloud (EC2) 構建一個包含 20 個節點的虛擬集群。事實上,紐約時報 使用 Hadoop 和 EC2 在 36 個小時內將 4TB 的 TIFF 圖像 — 包括 405K 大 TIFF 圖像,3.3M SGML 文章和 405K XML 文件 — 轉換為 800K 適合在 Web 上使用的 PNG 圖像。這種處理稱為雲計算,它是一種展示 Hadoop 的威力的獨特方式。
結束語
毫無疑問,Hadoop 正在變得越來越強大。從使用它的應用程序看,它的前途是光明的。您可以從 參考資料 小節更多地了解 Hadoop 及其應用程序,包括設置您自己的 Hadoop 集群的建議。