


本篇論文描述了Haystack,一個為Facebook的照片應用而專門優化定制的對象存儲系統。Facebook當前存儲了超過260 billion的圖片,相當於20PB的數據。用戶每個星期還會上傳1 billion的新照片(60TB),Facebook在峰值時需提供每秒查詢超過1 million圖片的能力。相比我們以前的方案(基於NAS和NFS),Haystack提供了一個成本更低的、性能更高的解決方案。我們觀察到一個非常關鍵的問題:傳統的設計因為元數據查詢而導致了過多的磁盤操作。我們竭盡全力的減少每個圖片的元數據,讓Haystack能在內存中執行所有的元數據查詢。這個突破讓系統騰出了更多的性能來讀取真實的數據,增加了整體的吞吐量。
分享照片是Facebook最受歡迎的功能之一。迄今為止,用戶已經上傳了超過65 billion的圖片,使得Facebook成為世界上最大的圖片分享網站。對每個上傳的照片,Facebook生成和存儲4種不同大小的圖片(比如在某些場景下只需展示縮略圖),這就產生了超過260 billion張圖片、超過20PB的數據。用戶每個星期還在上傳1 billion的新照片(60TB),Facebook峰值時需要提供每秒查詢1 million張圖片的能力。這些數字未來還會不斷增長,圖片存儲對Facebook的基礎設施提出了一個巨大的挑戰。
這篇論文介紹了Haystack的設計和實現,它已作為Facebook的圖片存儲系統投入生產環境24個月了。Haystack是一個為Facebook上分享照片而設計的對象存儲技術,在這個應用場景中,每個數據只會寫入一次、讀操作頻繁、從不修改、很少刪除。在Facebook遭遇的負荷下,傳統的文件系統性能很差,優化定制出Haystack是大勢所趨。
根據我們的經驗,傳統基於POSIX的文件系統的缺點主要是目錄和每個文件的元數據。對於圖片應用,很多元數據(比如文件權限),是無用的而且浪費了很多存儲容量。而且更大的性能消耗在於文件的元數據必須從磁盤讀到內存來定位文件。文件規模較小時這些花費無關緊要,然而面對幾百billion的圖片和PB級別的數據,訪問元數據就是吞吐量瓶頸所在。這是我們從之前(NAS+NFS)方案中總結的血的教訓。通常情況下,我們讀取單個照片就需要好幾個磁盤操作:一個(有時候更多)轉換文件名為Linux/1672.html' target='_blank'>inode number,另一個從磁盤上讀取inode,最後一個讀取文件本身。簡單來說,為了查詢元數據使用磁盤I/O是限制吞吐量的重要因素。在實際生產環境中,我們必須依賴內容分發網絡(CDN,比如Akamai)來支撐主要的讀取流量,即使如此,文件元數據的大小和I/O同樣對整體系統有很大影響。
了解傳統途徑的缺點後,我們設計了Haystack來達到4個主要目標:
本篇文章3個主要的貢獻是:
文章剩余部分結構如下。章節2闡述了背景、突出了之前架構遇到的挑戰。章節3描述了Haystack的設計和實現。章節4描述了各種圖片讀寫場景下的系統負載特征,通過實驗數據證明Haystack達到了設計目標。章節5是對比和相關工作,以及章節6的總結。
在本章節,我們將描述Haystack之前的架構,突出其主要的經驗教訓。由於文章大小限制,一些細節就不細述了。
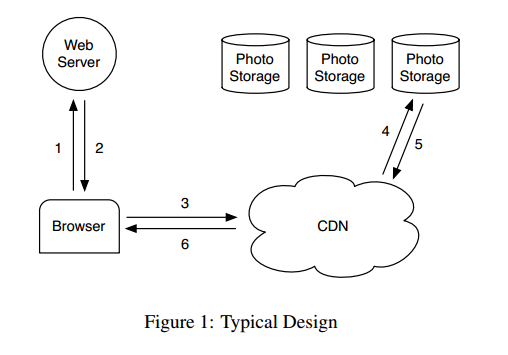
我們先來看一個概覽圖,它描述了通常的設計方案,web服務器、CDN和存儲系統如何交互協作,來實現一個熱門站點的圖片服務。圖1描述了從用戶訪問包含某個圖片的頁面開始,直到她最終從磁盤的特定位置下載此圖片結束的全過程。訪問一個頁面時,用戶的浏覽器首先發送HTTP請求到一個web服務器,它負責生成markup以供浏覽器渲染。對每張圖片,web服務器為其構造一個URL,引導浏覽器在此位置下載圖片數據。對於熱門站點,這個URL通常指向一個CDN。如果CDN緩存了此圖片,那麼它會立刻將數據回復給浏覽器。否則,CDN檢查URL,URL中需要嵌入足夠的信息以供CDN從本站點的存儲系統中檢索圖片。拿到圖片後,CDN更新它的緩存數據、將圖片發送回用戶的浏覽器。
在我們最初的設計中,我們使用了一個基於NFS的方案。我們吸取的主要教訓是,對於一個熱門的社交網絡站點,只有CDN不足以為圖片服務提供一個實用的解決方案。對於熱門圖片,CDN確實很高效——比如個人信息圖片和最近上傳的照片——但是一個像Facebook的社交網絡站點,會產生大量的對不熱門(較老)內容的請求,我們稱之為long tail(長尾理論中的名詞)。long tail的請求也占據了很大流量,它們都需要訪問更下游的圖片存儲主機,因為這些請求在CDN緩存裡基本上都會命中失敗。緩存所有的圖片是可以解決此問題,但這麼做代價太大,需要極大容量的緩存。

基於NFS的設計中,圖片文件存儲在一組商用NAS設備上,NAS設備的卷被mount到Photo Store Server的NFS上。圖2展示了這個架構。Photo Store Server解析URL得出卷和完整的文件路徑,在NFS上讀取數據,然後返回結果到CDN。
我們最初在NFS卷的每個目錄下存儲幾千個文件,導致讀取文件時產生了過多的磁盤操作,哪怕只是讀單個圖片。由於NAS設備管理目錄元數據的機制,放置幾千個文件在一個目錄是極其低效的,因為目錄的blockmap太大不能被設備有效的緩存。因此檢索單個圖片都可能需要超過10個磁盤操作。在減少到每個目錄下幾百個圖片後,系統仍然大概需要3個磁盤操作來獲取一個圖片:一個讀取目錄元數據到內存、第二個裝載inode到內存、最後讀取文件內容。
為了繼續減少磁盤操作,我們讓圖片存儲服務器明確的緩存NAS設備返回的文件"句柄"。第一次讀取一個文件時,圖片存儲服務器正常打開一個文件,將文件名與文件"句柄"的映射緩存到memcache中。同時,我們在os內核中添加了一個通過句柄打開文件的接口,當查詢被緩存的文件時,圖片存儲服務器直接用此接口和"句柄"參數打開文件。遺憾的是,文件"句柄"緩存改進不大,因為越冷門的圖片越難被緩存到(沒有解決long tail問題)。值得討論的是可以將所有文件"句柄"緩存到memcache,不過這也需要NAS設備能緩存所有的inode信息,這麼做是非常昂貴的。總結一下,我們從NAS方案吸取的主要教訓是,僅針對緩存——不管是NAS設備緩存還是額外的像memcache緩存——對減少磁盤操作的改進是有限的。存儲系統終究是要處理long tail請求(不熱門圖片)。
我們很難提出一個指導方針關於何時應該構建一個自定義的存儲系統。下面是我們在最終決定搭建Haystack之前的一些思考,希望能給大家提供參考。
面對基於NFS設計的瓶頸,我們探討了是否可以構建一個類似GFS的系統。而我們大部分用戶數據都存儲在Mysql數據庫,文件存儲主要用於開發工作、日志數據以及圖片。NAS設備其實為這些場景提供了性價比很好的方案。此外,我們補充了hadoop以供海量日志數據處理。面對圖片服務的long tail問題,Mysql、NAS、Hadoop都不太合適。
我們面臨的困境可簡稱為"已存在存儲系統缺乏合適的RAM-to-disk比率"。然而,沒有什麼比率是絕對正確的。系統需要足夠的內存才能緩存所有的文件系統元數據。在我們基於NAS的方案中,一個圖片對應到一個文件,每個文件需要至少一個inode,這已經占了幾百byte。提供足夠的內存太昂貴。所以我們決定構建一個定制存儲系統,減少每個圖片的元數據總量,以便能有足夠的內存。相對購買更多的NAS設備,這是更加可行的、性價比更好的方案。
Facebook使用CDN來支撐熱門圖片查詢,結合Haystack則解決了它的long tail問題。如果web站點在查詢靜態內容時遇到I/O瓶頸,傳統方案就是使用CDN,它為下游的存儲系統擋住了絕大部分的查詢請求。在Facebook,為了傳統的、廉價的的底層存儲不受I/O擺布,CDN往往需要緩存難以置信的海量靜態內容。
上面已經論述過,在不久的將來,CDN也不能完全的解決我們的問題,所以我們設計了Haystack來解決這個嚴重瓶頸:磁盤操作。我們接受long tail請求必然導致磁盤操作的現實,但是會盡量減少除了訪問真實圖片數據之外的其他操作。Haystack有效的減少了文件系統元數據的空間,並在內存中保存所有元數據。
每個圖片存儲為一個文件將會導致元數據太多,難以被全部緩存。Haystack的對策是:將多個圖片存儲在單個文件中,控制文件個數,維護大型文件,我們將論述此方案是非常有效的。另外,我們強調了它設計的簡潔性,以促進快速的實現和部署。我們將以此核心技術展開,結合它周邊的所有架構組件,描述Haystack是如何實現了一個高可靠、高可用的存儲系統。在下面對Haystack的介紹中,需要區分兩種元數據,不要混淆。一種是應用元數據,它是用來為浏覽器構造檢索圖片所需的URL;另一種是文件系統元數據,用於在磁盤上檢索文件。
Haystack架構包含3個核心組件:Haytack Store、Haystack Directory和Haystack Cache(簡單起見我們下面就不帶Haystack前綴了)。Store是持久化存儲系統,並負責管理圖片的文件系統元數據。Store將數據存儲在物理的卷上。比如,在一台機器上提供100個物理卷,每個提供100GB的存儲容量,整台機器則可以支撐10TB的存儲。更進一步,不同機器上的多個物理卷將對應一個邏輯卷。Haystack將一個圖片存儲到一個邏輯卷時,圖片被寫入到所有對應的物理卷。這個冗余可避免由於硬盤故障,磁盤控制器bug等導致的數據丟失。Directory維護了邏輯到物理卷的映射以及其他應用元數據,比如某個圖片寄存在哪個邏輯卷、某個邏輯卷的空閒空間等。Cache的功能類似我們系統內部的CDN,它幫Store擋住熱門圖片的請求(可以緩存的就絕不交給下游的持久化存儲)。在獨立設計Haystack時,我們要設想它處於一個沒有CDN的大環境中,即使有CDN也要預防其節點故障導致大量請求直接進入存儲系統,所以Cache是十分必要的。

圖3說明了Store、Directory、Cache是如何協作的,以及如何與外部的浏覽器、web服務器、CDN和存儲系統交互。在Haystack架構中,浏覽器會被引導至CDN或者Cache上。需要注意的是Cache本質上也是一個CDN,為了避免困惑,我們使用"CDN"表示外部的系統、使用"Cache"表示我們內部的系統。有一個內部的緩存設施能減少對外部CDN的依賴。
當用戶訪問一個頁面,web服務器使用Directory為每個圖片來構建一個URL(Directory中有足夠的應用元數據來構造URL)。URL包含幾塊信息,每一塊內容可以對應到從浏覽器訪問CDN(或者Cache)直至最終在一台Store機器上檢索到圖片的各個步驟。一個典型的URL如下:
http://<cdn>/<cache>/<machine id="">/<logical volume,="" photo="">
第一個部分<cdn>指明了從哪個CDN查詢此圖片。到CDN後它使用最後部分的URL(邏輯卷和圖片ID)即可查找緩存的圖片。如果CDN未命中緩存,它從URL中刪除<cdn>相關信息,然後訪問Cache。Cache的查找過程與之類似,如果還沒命中,則去掉<cache>相關信息,請求被發至指定的Store機器(<machine id="">)。如果請求不經過CDN直接發至Cache,其過程與上述類似,只是少了CDN這個環節。

圖4說明了在Haystack中的上傳流程。用戶上傳一個圖片時,她首先發送數據到web服務器。web服務器隨後從Directory中請求一個可寫邏輯卷。最後,web服務器為圖片分配一個唯一的ID,然後將其上傳至邏輯卷對應的每個物理卷。
Directory提供4個主要功能。首先,它提供一個從邏輯卷到物理卷的映射。web服務器上傳圖片和構建圖片URL時都需要使用這個映射。第二,Directory在分配寫請求到邏輯卷、分配讀請求到物理卷時需保證負載均衡。第三,Directory決定一個圖片請求應該被發至CDN還是Cache,這個功能可以讓我們動態調整是否依賴CDN。第四,Directory指明那些邏輯卷是只讀的(只讀限制可能是源自運維原因、或者達到存儲容量上限;為了運維方便,我們以機器粒度來標記卷的只讀)。
當我們增加新機器以增大Store的容量時,那些新機器是可寫的;僅僅可寫的機器會收到upload請求。隨時間流逝這些機器的可用容量會不斷減少。當一個機器達到容量上限,我們標記它為只讀,在下一個子章節我們將討論如何這個特性如何影響Cache和Store。
Directory將應用元數據存儲在一個冗余復制的數據庫,通過一個PHP接口訪問,也可以換成memcache以減少延遲。當一個Store機器故障、數據丟失時,Directory在應用元數據中刪除對應的項,新Store機器上線後則接替此項。
【譯者YY】3.2章節是整篇文章中唯一一處譯者認為沒有解釋清楚的環節。結合3.1章節中的URL結構解析部分,讀者可以發現Directory需要拿到圖片的"原始URL"(頁面html中link的URL),再結合應用元數據,就可以構造出"引導URL"以供下游使用。從3.2中我們知道Directory必然保存了邏輯卷到物理卷的映射,僅用此映射+原始URL足夠發掘其他應用元數據嗎?原始URL中到底包含了什麼信息(論文中沒看到介紹)?我們可以做個假設,假如原始URL中僅僅包含圖片ID,那Directory如何得知它對應哪個邏輯卷(必須先完成這一步映射,才能繼續挖掘更多應用元數據)?Directory是否在upload階段將圖片ID與邏輯卷的映射也保存了?如果是,那這個映射的數據量不能忽略不計,論文也不該一筆帶過。
從原文一些細枝末節的描述中,譯者認為Directory確實保存了很多與圖片ID相關的元數據(存儲在哪個邏輯卷、cookie等)。但整篇論文譯者也沒找到對策,總感覺這樣性價比太低,不符合Haystack的作風。對於這個疑惑,文章末尾擴展閱讀部分將嘗試解答。讀者先認為其具備此能力吧。
Cache會從CDN或者直接從用戶浏覽器接收到圖片查詢請求。Cache的實現可理解為一個分布式Hash Table,使用圖片ID作為key來定位緩存的數據。如果Cache未命中,Cache則根據URL從指定Store機器上獲取圖片,視情況回復給CDN或者用戶浏覽器。
我們現在強調一下Cache的一個重要行為概念。只有當符合兩種條件之一時它才會緩存圖片:(a)請求直接來自用戶浏覽器而不是CDN;(b)圖片獲取自一個可寫的Store機器。第一個條件的理由是一個請求如果在CDN中沒命中(非熱門圖片),那在我們內部緩存也不太需要命中(即使此圖片開始逐漸活躍,那也能在CDN中命中緩存,這裡無需多此一舉;直接的浏覽器請求說明是不經過CDN的,那就需要Cache代為CDN,為其緩存)。第二個條件的理由是間接的,有點經驗論,主要是為了保護可寫Store機器;原因挺有意思,大部分圖片在上傳之後很快會被頻繁訪問(比如某個美女新上傳了一張自拍),而且文件系統在只有讀或者只有寫的情況下執行的更好,不太喜歡同時並發讀寫(章節4.1)。如果沒有Cache,可寫Store機器往往會遭遇頻繁的讀請求。因此,我們甚至會主動的推送最近上傳的圖片到Cache。
Store機器的接口設計的很簡約。讀操作只需提供一些很明確的元數據信息,包括圖片ID、哪個邏輯卷、哪台物理Store機器等。機器如果找到圖片則返回其真實數據,否則返回錯誤信息。
每個Store機器管理多個物理卷。每個物理卷存有百萬張圖片。讀者可以將一個物理卷想象為一個非常大的文件(100GB),保存為'/hay/haystack<logical volume="" id="">'。Store機器僅需要邏輯卷ID和文件offset就能非常快的訪問一個圖片。這是Haystack設計的主旨:不需要磁盤操作就可以檢索文件名、偏移量、文件大小等元數據。Store機器會將其下所有物理卷的文件描述符(open的文件"句柄",卷的數量不多,數據量不大)緩存在內存中。同時,圖片ID到文件系統元數據(文件、偏移量、大小等)的映射(後文簡稱為"內存中映射")是檢索圖片的重要條件,也會全部緩存在內存中。
現在我們描述一下物理卷和內存中映射的結構。一個物理卷可以理解為一個大型文件,其中包含一系列的needle。每個needle就是一張圖片。圖5說明了卷文件和每個needle的格式。Table1描述了needle中的字段。


為了快速的檢索needle,Store機器需要為每個卷維護一個內存中的key-value映射。映射的Key就是(needle.key+needle.alternate_key)的組合,映射的Value就是needle的flag、size、卷offset(都以byte為單位)。如果Store機器崩潰、重啟,它可以直接分析卷文件來重新構建這個映射(構建完成之前不處理請求)。下面我們介紹Store機器如何響應讀寫和刪除請求(Store僅支持這些操作)。
【譯者注】從Table1我們看到needle.key就是圖片ID,為何僅用圖片ID做內存中映射的Key還不夠,還需要一個alternate_key?這是因為一張照片會有4份副本,它們的圖片ID相同,只是類型不同(比如大圖、小圖、縮略圖等),於是將圖片ID作為needle.key,將類型作為needle.alternate_key。根據譯者的理解,內存中映射不是一個簡單的HashMap結構,而是類似一個兩層的嵌套HashMap,Map<long *needle.key*="" ,map<int="" *alternate_key*="" ,object="">>。這樣做可以讓4個副本共用同一個needle.key,避免為重復的內容浪費內存空間。
Cache機器向Store機器請求一個圖片時,它需要提供邏輯卷id、key、alternate key,和cookie。cookie是個數字,嵌在URL中。當一張新圖片被上傳,Directory為其隨機分配一個cookie值,並作為應用元數據之一存儲在Directory。它就相當於一張圖片的"私人密碼",此密碼可以保證所有發往Cache或CDN的請求都是經過Directory"批准"的(Cache和Store都持有圖片的cookie,若用戶自己在浏覽器中偽造、猜測URL或發起攻擊,則會因為cookie不匹配而失敗,從而保證Cache、Store能放心處理合法的圖片請求)。
當Store機器接收到Cache機器發來的圖片查詢請求,它會利用內存中映射快速的查找相關的元數據。如果圖片沒有被刪除,Store則在卷文件中seek到相應的offset,從磁盤上讀取整個needle(needle的size可以提前計算出來),然後檢查cookie和數據完整性,若全部合法則將圖片數據返回到Cache機器。
上傳一個圖片到Haystack時,web服務器向Directory咨詢得到一個可寫邏輯卷及其對應的多台Store機器,隨後直接訪問這些Store機器,向其提供邏輯卷id、key、alternate key、cookie和真實數據。每個Store機器為圖片創建一個新needle,append到相應的物理卷文件,更新內存中映射。過程很簡單,但是append-only策略不能很好的支持修改性的操作,比如旋轉(圖片順時針旋轉90度之類的)。Haystack並不允許覆蓋needle,所以圖片的修改只能通過添加一個新needle,其擁有相同的key和alternate key。如果新needle被寫入到與老needle不同的邏輯卷,則只需要Directory更新它的應用元數據,未來的請求都路由到新邏輯卷,不會獲取老版本的數據。如果新needle寫入到相同的邏輯卷,Store機器也只是將其append到相同的物理卷中。Haystack利用一個十分簡單的手段來區分重復的needle,那就是判斷它們的offset(新版本的needle肯定是offset最高的那個),在構造或更新內存中映射時如果遇到相同的needle,則用offset高的覆蓋低的。
在刪除圖片時,Store機器將內存中映射和卷文件中相應的flag同步的設置為已刪除(軟刪除機制,此刻不會刪除needle的磁盤數據)。當接收到已刪除圖片的查詢請求,Store會檢查內存中flag並返回錯誤信息。值得注意的是,已刪除needle依然占用的空間是個問題,我們稍後將討論如何通過壓縮技術來回收已刪除needle的空間。
Store機器使用一個重要的優化——索引文件——來幫助重啟初始化。盡管理論上一個機器能通過讀取所有的物理卷來重新構建它的內存中映射,但大量數據(TB級別)需要從磁盤讀取,非常耗時。索引文件允許Store機器快速的構建內存中映射,減少重啟時間。
Store機器為每個卷維護一個索引文件。索引文件可以想象為內存中映射的一個"存檔"。索引文件的布局和卷文件類似,一個超級塊包含了一系列索引記錄,每個記錄對應到各個needle。索引文件中的記錄與卷文件中對應的needle必須保證相同的存儲順序。圖6描述了索引文件的布局,Table2解釋了記錄中的不同的字段。


使用索引幫助重啟稍微增加了系統復雜度,因為索引文件都是異步更新的,這意味著當前索引文件中的"存檔"可能不是最新的。當我們寫入一個新圖片時,Store機器同步append一個needle到卷文件末尾,並異步append一個記錄到索引文件。當我們刪除圖片時,Store機器在對應needle上同步設置flag,而不會更新索引文件。這些設計決策是為了讓寫和刪除操作更快返回,避免附加的同步磁盤寫。但是也導致了兩方面的影響:一個needle可能沒有對應的索引記錄、索引記錄中無法得知圖片已刪除。
我們將對應不到任何索引記錄的needle稱為"孤兒"。在重啟時,Store機器順序的檢查每個孤兒,重新創建匹配的索引記錄,append到索引文件。我們能快速的識別孤兒是因為索引文件中最後的記錄能對應到卷文件中最後的非孤兒needle。處理完孤兒問題,Store機器則開始使用索引文件初始化它的內存中映射。
由於索引記錄中無法得知圖片已刪除,Store機器可能去檢索一個實際上已經被刪除的圖片。為了解決這個問題,可以在Store機器讀取整個needle後檢查其flag,若標記為已刪除,則更新內存中映射的flag,並回復Cache此對象未找到。
Haystack可以理解為基於通用的類Unix文件系統搭建的對象存儲,但是某些特殊文件系統能更好的適應Haystack。比如,Store機器的文件系統應該不需要太多內存就能夠在一個大型文件上快速的執行隨機seek。當前我們所有的Store機器都在使用的文件系統是XFS,一個基於"范圍(extent)"的文件系統。XFS有兩個優勢:首先,XFS中鄰近的大型文件的"blockmap"很小,可放心使用內存存儲;第二,XFS提供高效文件預分配,減輕磁盤碎片等問題。
使用XFS,Haystack可以在讀取一張圖片時完全避免檢索文件系統元數據導致的磁盤操作。但是這並不意味著Haystack能保證讀取單張圖片絕對只需要一個磁盤操作。在一些極端情況下會發生額外的磁盤操作,比如當圖片數據跨越XFS的"范圍(extent)"或者RAID邊界時。不過Haystack會預分配1GB的"范圍(extent)"、設置RAID stripe大小為256KB,所以實際上我們很少遭遇這些極端場景。
對於運行在普通硬件上的大規模系統,容忍各種類型的故障是必須的,包括硬盤驅動故障、RAID控制器錯誤、主板錯誤等,Haystack也不例外。我們的對策由兩個部分組成——一個為偵測、一個為修復。
為了主動找到有問題的Store機器,我們維護了一個後台任務,稱之為pitchfork,它周期性的檢查每個Store機器的健康度。pitchfork遠程的測試到每台Store機器的連接,檢查其每個卷文件的可用性,並嘗試讀取數據。如果pitchfork確定某台Store機器沒通過這些健康檢查,它會自動標記此台機器涉及的所有邏輯卷為只讀。我們的工程師將在線下人工的檢查根本故障原因。
一旦確診,我們就能快速的解決問題。不過在少數情況下,需要執行一個更加嚴厲的bulk同步操作,此操作需要使用復制品中的卷文件重置某個Store機器的所有數據。Bulk同步發生的幾率很小(每個月幾次),而且過程比較簡單,只是執行很慢。主要的瓶頸在於bulk同步的數據量經常會遠遠超過單台Store機器NIC速度,導致好幾個小時才能恢復。我們正積極解決這個問題。
Haystack的成功還歸功於幾個非常重要的細節優化。
壓縮操作是直接在線執行的,它能回收已刪除的、重復的needle所占據的空間。Store機器壓縮卷文件的方式是,逐個復制needle到一個新的卷文件,並跳過任何重復項、已刪除項。在壓縮時如果接收到刪除操作,兩個卷文件都需處理。一旦復制過程執行到卷文件末尾,所有對此卷的修改操作將被阻塞,新卷文件和新內存中映射將對前任執行原子替換,隨後恢復正常工作。
上面描述過,Store機器會在內存中映射中維護一個flag,但是目前它只會用來標記一個needle是否已刪除,有點浪費。所以我們通過設置偏移量為0來表示圖片已刪除,物理上消除了這個flag。另外,映射Value中不包含cookie,當needle從磁盤讀出之後Store才會進行cookie檢查。通過這兩個技術減少了20%的內存占用。
當前,Haystack平均為每個圖片使用10byte的內存。每個上傳的圖片對應4張副本,它們共用同一個key(占64bits),alternate keys不同(占32bits),size不同(占16bits),目前占用(64+(32+16)*4)/8=32個bytes。另外,對於每個副本,Haystack在用hash table等結構時需要消耗額外的2個bytes,最終總量為一張圖片的4份副本共占用40bytes。作為對比,一個xfs_inode_t結構在Linux中需占用536bytes。
磁盤在執行大型的、連續的寫時性能要優於大量小型的隨機寫,所以我們盡量將相關寫操作捆綁批量執行。幸運的是,很多用戶都會上傳整個相冊到Facebook,而不是頻繁上傳單個圖片。因此只需做一些巧妙的安排就可以捆綁批量upload,實現大型、連續的寫操作。
章節4、5、6是實驗和總結等內容,這裡不再贅述了。
【擴展閱讀】
提到CDN和分布式文件存儲就不得不提到淘寶,它的商品圖片不會少於Facebook的個人照片。其著名的CDN+TFS的解決方案由於為公司節省了巨額的預算開支而獲得創新大獎,團隊成員也得到不菲的獎金(羨慕嫉妒恨)。淘寶的CDN技術做了非常多的技術創新和突破,不過並非本文范疇,接下來的討論主要是針對Haystack與TFS在存儲、檢索環節的對比,並嘗試提取出此類場景常見的技術難點。(譯者對TFS的理解僅限於介紹文檔,若有錯誤望讀者矯正)
淘寶CDN、TFS的介紹請移步:http://tfs.taobao.org/index.html
注意:下文中很多術語(比如應用元數據、Store、文件系統元數據等,都是基於本篇論文的上下文,請勿混淆)

上圖是整個CDN+TFS解決方案的全貌,對應本文就是圖3。CDN在前三層上實現了各種創新和技術突破,不過並非本文焦點,這裡主要針對第四層Storage(淘寶的分布式文件系統TFS),對比Haystack,看其是否也解決了long tail問題。下面是TFS的架構概覽:

從粗粒度的宏觀視角來看,TFS與Haystack的最大區別就是: TFS只care存儲層面,它沒有Haystack Cache組件;Haystack期望提供的是從浏覽器、到CDN、到最終存儲的一整套解決方案,架構定位稍有不同,Haystack也是專門為這種場景下的圖片服務所定制的,做了很多精細的優化;TFS的目標是通用分布式文件存儲,除了CDN還會支持其他各種場景。
到底是定制一整套優化的解決方案,還是使用通用分布式文件存儲平台強強聯手?Facebook的工程師也曾糾結過(章節2.3),這個沒有標准答案,各有所長,視情況去選擇最合適的方案吧。
下面我們以本文中關注的一些難點來對比一下雙方的實現:
1 存儲機器上的文件結構、文件系統元數據對策
Haystack的機器上維護了少量的大型物理卷文件,其中包含一系列needle來存儲小文件,同時needle的文件系統元數據被全量緩存、持久化"存檔"。
在TFS中(後文為清晰起見,引用TFS文獻的內容都用淘寶最愛的橙色展示):
"……在TFS中,將大量的小文件(實際用戶文件)合並成為一個大文件,這個大文件稱為塊(Block)。TFS以Block的方式組織文件的存儲……"
"……!DataServer進程會給Block中的每個文件分配一個ID(File ID,該ID在每個Block中唯一),並將每個文件在Block中的信息存放在和Block對應的Index文件中。這個Index文件一般都會全部load在內存……"
看來面對可憐的操作系統,大家都不忍心把海量的小文件直接放到它的文件系統上,合並成super block,維護super block中各entry的元數據和索引信息(並全量緩存),才是王道。這裡TFS的Block應該對應到Haystack中的一個物理卷。
2 分布式協調調度、應用元數據策略
Haystack在接收到讀寫請求時,依靠Directory分析應用元數據,再結合一定策略(如負載均衡、容量、運維、只讀、可寫等),決定請求被發送到哪台Store機器,並向Store提供足夠的存儲或檢索信息。Directory負責了整體分布式環境的協調調度、應用元數據管理職能,並基於此幫助實現了系統的可擴展性、容錯性。
在TFS中:
"……!NameServer主要功能是: 管理維護Block和!DataServer相關信息,包括!DataServer加入,退出, 心跳信息, block和!DataServer的對應關系建立,解除。正常情況下,一個塊會在!DataServer上存在, 主!NameServer負責Block的創建,刪除,復制,均衡,整理……"
"……每一個Block在整個集群內擁有唯一的編號,這個編號是由NameServer進行分配的,而DataServer上實際存儲了該Block。在!NameServer節點中存儲了所有的Block的信息……"
TFS中與Directory對應的就是NameServer了,職責大同小異,就是分布式協調調度和應用元數據分配管理,並基於此實現系統的平滑擴容、故障容忍。下面專門討論一下這兩個重要特性。
3 擴展性
Haystack和TFS都基於(分布式協調調度+元數據分配管理)實現了非常優雅的可擴展方案。我們先回顧一下傳統擴展性方案中的那些簡單粗暴的方法。
最簡單最粗暴的場景:
現在有海量的數據,比如data [key : value],有100台機器,通過一種策略讓這些數據能負載均衡的發給各台機器。策略可以是這樣,int index=Math.abs(key.hashCode)%100,這就得到了一個唯一的、確定的、[0,99]的序號,按此序號發給對應的某台機器,最終能達到負載均衡的效果。此方案的粗暴顯而易見,當我們新增機器後(比如100變成130),大部分老數據的key執行此策略後得到的index會發生變化,這也就意味著對它們的檢索都會發往錯誤的機器,找不到數據。
稍微改進的場景是:
現在有海量的數據,比如data [key : value],我假想自己是高富帥,有一萬台機器,同樣按照上述的策略進行路由。但是我只有100台機器,這一萬台是假想的,怎麼辦?先給它們一個稱號,叫虛擬節點(簡稱vnode,vnode的序號簡稱為vnodeId),然後想辦法將vnode與真實機器建立多對一映射關系(每個真實機器上100個vnode),這個辦法可以是某種策略,比如故技重施對vnodeId%100得到[0,99]的機器序號,或者在數據庫中建幾張表維護一下這個多對一的映射關系。在路由時,先按老辦法得到vnodeId,再執行一次映射,找到真實機器。這個方案還需要一個架構假設:我的系統規模在5年內都不需要上漲到一萬台機器(5年差不多了,像我等碼農估計一輩子也玩不了一萬台機器的集群吧),因此10000這個數字"永遠"不會變,這就保證了一個key永遠對應某個vnodeId,不會發生改變。然後在擴容時,我們改變的是vnode與真實機器的映射關系,但是此映射關系一改,也會不可避免的導致數據命中失敗,因為必然會產生這樣的現象:某個vnodeId(v1)原先是對應機器A的,現在變成了機器B。但是相比之前的方案,現在已經好很多了,我們可以通過運維手段先阻塞住對v1的讀寫請求,然後執行數據遷移(以已知的vnode為粒度,而不是千千萬萬個未知的data,這種遷移操作還是可以接受的),遷移完畢後新機器開始接收請求。做的更好一點,可以不阻塞請求,想辦法做點容錯處理和寫同步之類的,可以在線無痛的完成遷移。
上面兩個老方案還可以加上一致性Hash等策略來盡量避免數據命中失敗和數據遷移。但是始終逃避不了這樣一個公式:
int machine_id=function(data.key , x)
machine_id指最終路由到哪台機器,function代表我們的路由策略函數,data.key就是數據的key(數據ID之類的),x在第一個方案裡就是機器數量100,在第二個方案裡就是vnode數量+(vnode與機器的映射關系)。在這個公式裡,永遠存在了x這個未知數,一旦它風吹草動,function的執行結果就可能改變,所以它逃避不了命中失敗。
只有當公式變成下面這個,才能絕對避免:
Map<data.key,final machine_id=""> map = xxx;
int machine_id=map.get(data.key);
注意map只是個理論上的結構,這裡只是簡單的偽代碼,並不強制它是個簡單的<key-value>結構,它的結構可能會更復雜,但是無論怎麼復雜,此map都真實的、明確的存在,其效果都是——用data.key就能映射到machine_id,找到目標機器,不管是直接,還是間接,反正不是用一個function去動態計算得到。map裡的final不符合語法,加在這裡是想強調,此map一旦為某個data.key設置了machine_id,就永不改變(起碼不會因為日常擴容而改變)。當增加機器時,此map的已有值也不會受到影響。這樣一個沒有未知數x的公式,才能保證新老數據來了都能根據key拿到一個永遠不變的machine_id,永遠命中成功。
因此我們得出這樣一個結論,只要擁有這樣一個map,系統就能擁有非常優雅平滑的可擴展潛力。當系統擴容時,老的數據不會命中失敗,在分布式協調調度的保證下,新的增量數據會更傾向於寫入新機器,整個集群的負載會逐漸均衡。
很顯然Haystack和TFS都做到了,下面忽略其他細節問題,著重討論一下它們是如何裝備上這個map的。
讀者回顧一下3.2章節留下的那個疑惑——原始URL中到底包含什麼信息,是不是只有圖片ID?Directory到底需不需要維護圖片ID到邏輯卷的映射?
這個"圖片ID到邏輯卷的映射",就是我們需要的map,用圖片ID(data.key)能get到邏輯卷ID(此值是upload時就明確分配的,不會改變),再間接從"邏輯卷到物理卷映射"中就能get到目標Store機器;無論是新增邏輯卷還是新增物理卷,"圖片ID到邏輯卷的映射"中的已有值都可以不受影響。這些都符合map的行為定義。
Haystack也因此,具備了十分優雅平滑的可擴展能力。但是譯者提到的疑惑並沒有解答——"這個映射(圖片ID到邏輯卷的映射)的數據量不能忽略不計,論文也不該一筆帶過"
作者提到過memcache,也許這就是相關的解決方案,此數據雖然不小,但是也沒大到望而生畏的地步。不過我們依然可以發散一下,假如Haystack沒保存這個映射呢?
這就意味著原始URL不只包含圖片ID,還包含邏輯卷ID等必要信息。這樣也是遵循map的行為定義的,即使map的信息沒有集中存儲在系統內,但是卻分散在各個原始URL中,依然存在。不可避免的,這些信息就要在upload階段返回給業務系統(比如Facebook的照片分享應用系統),業務系統需要理解、存儲和處理它們(隨後再利用它們組裝為原始URL去查詢圖片)。這樣相當於把map的維護工作分擔給了各個用戶系統,這也是讓人十分痛苦的,導致了不可接受的耦合。
我們可以看看TFS的解決方案:
"……TFS的文件名由塊號和文件號通過某種對應關系組成,最大長度為18字節。文件名固定以T開始,第二字節為該集群的編號(可以在配置項中指定,取值范圍 1~9)。余下的字節由Block ID和File ID通過一定的編碼方式得到。文件名由客戶端程序進行編碼和解碼,它映射方式如下圖……"


"……根據TFS文件名解析出Block ID和block中的File ID.……dataserver會根據本地記錄的信息來得到File ID所在block的偏移量,從而讀取到正確的文件內容……"
一切,迎刃而解了…… 這個方案可以稱之為"結構化ID"、"聚合ID",或者是"命名規則大於配置"。當我們糾結於僅僅有圖片ID不夠時,可以給ID簡單的動動手腳,比如ID是long類型,8個byte,左邊給點byte用於存儲邏輯卷ID,剩下的用於存儲真實的圖片ID(某些場景下還可以多截幾段給更多的元數據),於是既避免了保存大量的映射數據,又避免了增加系統間的耦合,魚和熊掌兼得。不過這個方案對圖片ID有所約束,也不支持自定義的圖片名稱,針對這個問題,TFS在新版本中:
"……metaserver是我們在2.0版本引進的一個服務. 用來存儲一些元數據信息, 這樣原本不支持自定義文件名的 TFS 就可以在 metaserver 的幫助下, 支持自定義文件名了.……"
此metaserver的作用無疑就和Directory中部分應用元數據相關的職責類似了。個人認為可以兩者結合雙管齊下,畢竟自定義文件名這種需求應該不是主流。
值得商榷的是,全量保存這部分應用元數據其實還是有很多好處的,最典型的就是順帶保存的cookie,有效的幫助Haystack不受偽造URL攻擊的困擾,這個問題不知道TFS是如何解決的(大量的文件檢索異常勢必會影響系統性能)。如果Haystack的作者能和TFS的同學們做個交流,說不定大家都能少走點彎路吧(這都是後話了~)
小結一下,針對第三個可擴展性痛點,譯者描述了傳統方案的缺陷,以及Haystack和TFS是如何彌補了這些缺陷,實現了平滑優雅的可擴展能力。此小節的最後再補充一個TFS的特性:
"……同時,在集群負載比較輕的時候,!NameServer會對!DataServer上的Block進行均衡,使所有!DataServer的容量盡早達到均衡。進行均衡計劃時,首先計算每台機器應擁有的blocks平均數量,然後將機器劃分為兩堆,一堆是超過平均數量的,作為移動源;一類是低於平均數量的,作為移動目的……"
均衡計劃的職責是在負載較低的時候(深夜),按計劃執行Block數據的遷移,促進整體負載更加均衡。根據譯者的理解,此計劃會改變公式中的map,因為根據文件名拿到的BlockId對應的機器可能發生變化,這也是它為何要在深夜負載較低時按計劃缜密執行的原因。其效果是避免了因為運維操作等原因導致的數據分布不均。
4 容錯性
Haystack的容錯是依靠:一個邏輯卷對應多個物理卷(不同機器上);"客戶端"向一個邏輯卷的寫操作會翻譯為對多個物理卷的寫,達到冗余備份;機器故障時Directory優雅的修改應用元數據(在牽涉到的邏輯卷映射中刪除此機器的物理卷項)、或者標記只讀,繼而指導路由過程(分布式協調調度)將請求發送到後備的節點,避免請求錯誤;通過bulk復制重置來安全的恢復數據。等等。
在TFS中:
"……TFS可以配置主輔集群,一般主輔集群會存放在兩個不同的機房。主集群提供所有功能,輔集群只提供讀。主集群會把所有操作重放到輔集群。這樣既提供了負載均衡,又可以在主集群機房出現異常的情況不會中斷服務或者丟失數據。……"
"……每一個Block會在TFS中存在多份,一般為3份,並且分布在不同網段的不同!DataServer上……"
"……客戶端向master dataserver開始數據寫入操作。master server將數據傳輸為其他的dataserver節點,只有當所有dataserver節點寫入均成功時,master server才會向nameserver和客戶端返回操作成功的信息。……"
可以看出冗余備份+協調調度是解決這類問題的慣用范式,在大概思路上兩者差不多,但是有幾個技術方案卻差別很大:
第一,冗余寫機制。Haystack Store是將冗余寫的責任交給"客戶端"(發起寫操作的客戶端,就是圖3中的web server),"客戶端"需要發起多次寫操作到不同的Store機器上;而TFS是依靠自身的master-slave機制,由master向slave復制。
第二,機房容錯機制。TFS依然是遵循master-slave機制,集群也分主輔,主輔集群分布在不同機房,主集群負責重放數據操作到輔集群。而Haystack在這方面沒有詳細介紹,只是略微提到"……Haystack復制每張圖片到地理隔離的多個地點……"
針對上面兩點,按譯者的理解,Haystack可能更偏向於對等結構的設計,也就是說沒有master、slave之分,各個Store是對等的節點,沒有誰負責給誰復制數據,"客戶端"向各個Store寫入數據,一視同仁。
不考慮webserver、Directory等角色,只考慮Store,來分析一下它的容錯機制:如果單台Store掛了,Directory在應用元數據的相關邏輯卷映射中刪除此台機器的物理卷(此過程簡稱為"調整邏輯物理映射"),其他"對等"的物理卷能繼續服務,沒有問題;一整個機房掛了,Directory處理過程和單台故障相同,只是會對此機房中每台機器都執行一遍"調整邏輯物理映射",由於邏輯卷到物理卷的映射是在Directory中明確維護的,所以只要在維護和管理過程中確保一個邏輯卷下不同的物理卷分布在不同的機房,哪怕在映射中刪除一整個機房所有機器對應的物理卷,各個邏輯卷下依然持有到其他機房可用物理卷的映射,依然有對等Store的物理卷做後備,沒有問題。
主從結構和對等結構各有所長,視情況選擇。對等結構看似簡潔美好,也有很多細節上的妥協;主從結構增加了復雜度,比如嚴格角色分配、約定角色行為等等(TFS的輔集群為何只讀?在主集群掛掉時是否依然只讀?這些比較棘手也是因為此復雜度吧)
第三,修復機制。Haystack的修復機制依靠周期性後台任務pitchfork和離線bulk重置等。在TFS中:
"……Dataserver後台線程介紹……"
"……心跳線程……這裡的心跳是指Ds向Ns發的周期性統計信息……負責keepalive……匯報block的工作……"
"……檢查線程……修復checkfile_queue中的邏輯塊……每次對文件進行讀寫刪操作失敗的時候,會tryadd_repair_task(blockid, ret)來將ret錯誤的block加入check_file_queue中……若出錯則會請求Ns進行update_block_info……"
除了類似的遠程心跳機制,TFS還多了在DataServer上對自身的錯誤統計和自行恢復,必要時還會請求上級(NameServer)幫助恢復。
5 文件系統
Haystack提到了預分配、磁盤碎片、XFS等方案,TFS中也有所涉及:
"……在!DataServer節點上,在掛載目錄上會有很多物理塊,物理塊以文件的形式存在磁盤上,並在!DataServer部署前預先分配,以保證後續的訪問速度和減少碎片產生。為了滿足這個特性,!DataServer現一般在EXT4文件系統上運行。物理塊分為主塊和擴展塊,一般主塊的大小會遠大於擴展塊,使用擴展塊是為了滿足文件更新操作時文件大小的變化。每個Block在文件系統上以"主塊+擴展塊"的方式存儲。每一個Block可能對應於多個物理塊,其中包括一個主塊,多個擴展塊。在DataServer端,每個Block可能會有多個實際的物理文件組成:一個主Physical Block文件,N個擴展Physical Block文件和一個與該Block對應的索引文件……"
各有各的考究吧,比較了解底層的讀者可以深入研究下。
6 刪除和壓縮
Haystack使用軟刪除(設置flag)、壓縮回收來支持delete操作,在TFS中:
"……壓縮線程(compact_block.cpp)……真正的壓縮線程也從壓縮隊列中取出並進行執行(按文件進行,小文件合成一起發送)。壓縮的過程其實和復制有點像,只是說不需要將刪除的文件數據以及index數據復制到新創建的壓縮塊中。要判斷某個文件是否被刪除,還需要拿index文件的offset去fileinfo裡面取刪除標記,如果標記不是刪除的,那麼就可以進行write_raw_data的操作,否則則濾過……"
可見兩者大同小異,這也是此類場景中常用的解決機制。
總結
本篇論文以long tail無法避免出發,探究了文件元數據導致的I/O瓶頸,推導了海量小文件的存儲和檢索方案,以及如何與CDN等外部系統配合搭建出整套海量圖片服務。其在各