


一.安裝Scala
Scala程序運行在java虛擬機(JVM)上,所以安裝Scala之前需要先在linux系統中安裝Java。由於之前已經安裝了,沒安裝的可以到我的文章http://blog.csdn.net/xqclll/article/details/53466713去查看。
到Scala的官網上去下載相應操作系統的scala版本,解壓到安裝路徑下,然後修改文件權限,使hadoop用戶擁有對scala目錄的權限。
chown -R hadoop ./scala-2.11.8配置環境變量:
sudo gedit ~/.bashrcexport SCALA_HOME=/home/hadoop/hadoop/scala-2.11.8export PATH=$PATH:$SCALA_HOME/bin使環境變量生效:
source ~/.bashrc檢驗一下是否設置正確,可以輸入scala命令:
scala結果:

二. 安裝Spark 安裝Spark之前要裝好hadoop, 到Spark官網上去下載Spark,要選hadoop2.6的: spark-2.0.2-bin-hadoop2.6 Spark可以安裝單機的,也可以安裝分布式的,由於之前已經配置了hadoop的集群,所以這裡的Spark也配置成分布 式的。
具體步驟: 1.解壓Spark,並且設置hadoop用戶的使用權限
sudo chown -R hadoop:hadoop /home/hadoop/hadoop/spark-2.0.2-bin-hadoop2.62.配置環境變量:
gedit ~/.bashrcexport SPARK_HOME=/home/hadoop/hadoop/spark-2.0.2-bin-hadoop2.6export PATH=$PATH:$SPARK_HOME/binsource ~/.bashrc3.修改配置文件 修改spark-env.sh conf文件下的spark-env.sh.template拷貝為spark-env.sh
cp spark-env.sh.template spark-env.sh在該文件中添加java,Scala,hadoop,spark的環境變量
修改slaves
cp slaves.template slaves
把配置好的scala整個文件傳到其他三台slave主機:
scp -r /home/hadoop/hadoop/scala-2.11.8 hadoop-slave1:/home/hadoop/hadoop/scp -r /home/hadoop/hadoop/scala-2.11.8 hadoop-slave2:/home/hadoop/hadoop/scp -r /home/hadoop/hadoop/scala-2.11.8 hadoop-slave3:/home/hadoop/hadoop/把配置好的spark整個文件傳到其他三台slave主機:
scp -r /home/hadoop/hadoop/spark-2.0.2-bin-hadoop2.6 hadoop-slave1:/home/hadoop/hadoop/scp -r /home/hadoop/hadoop/spark-2.0.2-bin-hadoop2.6 hadoop-slave2:/home/hadoop/hadoop/scp -r /home/hadoop/hadoop/spark-2.0.2-bin-hadoop2.6 hadoop-slave3:/home/hadoop/hadoop/然後配置其他幾台slave主機上的scala和spark環境變量。
開始測試Spark 進入到spark的sbin下面,使用如下命令啟動spark,啟動之前要先啟動hadoop。
./start-all.sh如果除hadoop的其他進程之外在hadoop-master1上面出現了Master進程,hadoop-slave1,hadoop-slave2,hadoop-slave3上出現了Worker進程。那麼可以說明Spark安裝配置成功。
還可以到web頁面下去看: hadoop-master1:8080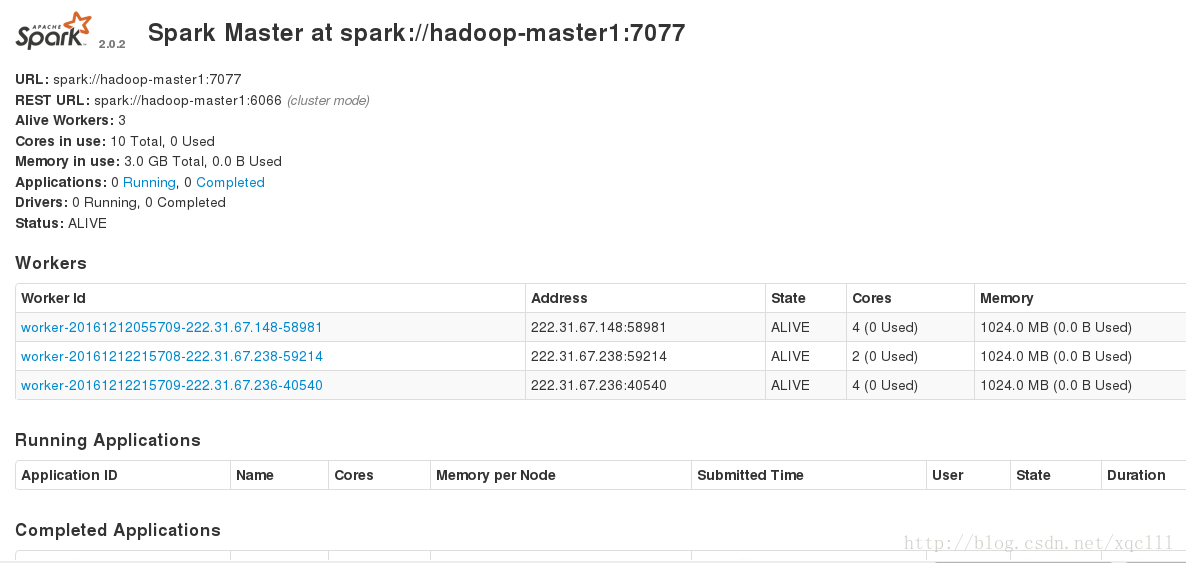
http://xxxxxx/Linuxjc/1184790.html TechArticle