


匯編器構造
一、 匯編器簡介
前面介紹了編譯器構造和靜態鏈接器構造的具體方法,而且我們實現了一個將高級語言轉化為匯編語言的編譯器,同時又實現了一個將多個目標文件鏈接為一個可執行文件的鏈接器。現在需要一個連接這兩個模塊的功能模塊——匯編器,它能將一個單獨的匯編文件轉換為一個可重定位目標文件,如圖1-1反映出匯編器在整個編譯系統中的地位和功能。
 圖 1-1 靜態編譯步驟
圖 1-1 靜態編譯步驟
從本質上講,匯編器也是編譯器,只是它和我們熟知的編譯器的有略微的差別。匯編器處理的“高級語言”是匯編語言,輸出的是機器語言二進制形式。因此,對於匯編器的構造,實質上和編譯器大同小異,也都需要進行詞法分析、語法分析、語義處理、符號表管理和代碼生成(機器代碼)等階段。
對於編譯器來說,代碼生成階段只需要將解析的語法樹映射到匯編語言子模塊即可(當然還要考慮指令優化問題),而對於匯編器,將解析出的指令簡潔的映射到正確機器代碼相對比較復雜。另外,由於本匯編器處理的輸入文件為編譯器生成的匯編文件,經測試,編譯生成的匯編文件是正確的匯編文件,因此匯編器不需要考慮源文件會產生錯誤,因此它的語法分析的目的是識別出輸入語言的語法結構並進行解析引導機器代碼生成。
另外,匯編器和編譯器最大的不同是:匯編語言允許符號後置定義,因此通過一遍掃描無法保證獲得某個符號的准確定義信息,所以對於匯編器必須采用兩邊掃描的方式進行設計,匯編器的設計結構如圖1-2所示。
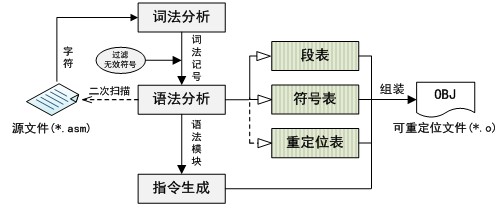 圖1-2 匯編器結構
圖1-2 匯編器結構
從圖中可以看出匯編器的設計中,在語法分析模塊之前和前述編譯器的結構完全相同,只是語法分析時要進行兩遍的掃描過程,通過第一遍掃描獲取文件定義的所有的段的信息以及全部的符號信息,第二遍掃描根據最新的段表和符號表,將所有的重定位信息收集到重定位表中,然後通過指令生成模塊生成了代碼段數據。最後,從符號表中抽取有效數據定義形成數據段,符號導出到文件符號表段,再把所有的段按照elf文件的格式組裝起來,形成最終的可重定位目標文件*.o。下面就按照上述路程具體說明匯編器設計的內容。
二、 文法定義
和編譯器設計過程相同,首先必須明確處理匯編語言的文法定義,按照符合LL(1)文法的規則定義的待處理匯編語言的文法如表2-1所示:
表2-1 匯編文法
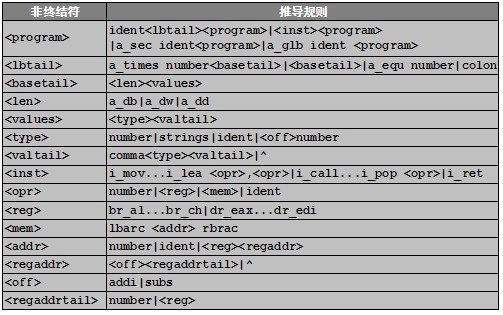 上述匯編文法可以識別之前編譯器生成的所有代碼,從文法定義中,可以看出匯編語言的功能主要如下:
上述匯編文法可以識別之前編譯器生成的所有代碼,從文法定義中,可以看出匯編語言的功能主要如下:
(1)支持段聲明,全局符號聲明,數據定義db|dw|dd,times關鍵字和equ宏命令。
(2)支持數據為整數和字符串格式,允許定義中引用符號,數據使用逗號分隔。
(3)支持的指令數:雙操作數指令5條,單操作數指令17條,無操作數指令1條。
(4)支持尋址模式:寄存器尋址,立即尋址,寄存器間址,間接尋址,基址+偏移尋址,基址+變址尋址。
明確匯編語言的文法後就可以構造分析程序識別語言的語法結構。
三、 詞法分析
匯編器的詞法分析過程和編譯器相同,也需要掃描器和解析器,區別在於字母表和詞法記號的差別。匯編語言的詞法記號如表3-1所示。
表 3-1 詞法記號
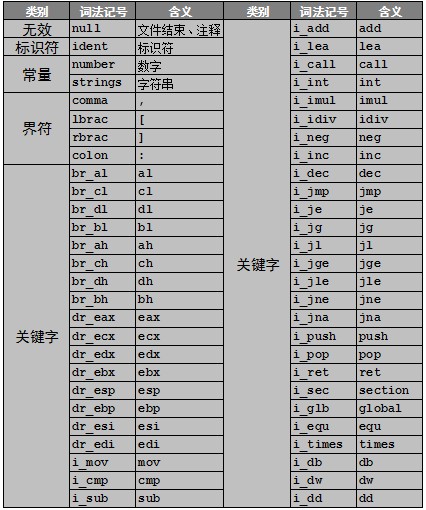 從詞法記號表中可以看出匯編語言詞法記號的變化:
從詞法記號表中可以看出匯編語言詞法記號的變化:
(1)標識符可以用符號‘@’開頭。
(2)增加一部分界符‘[’,‘]’,‘:’。
(3)刪除了一部分界符‘*’,‘/’,‘=’,‘>’,‘<’,‘!’,‘;’,‘(’,‘)’,‘{’,‘}’。
(4)注釋由分號引導的單行注釋。
(5)關鍵字表有重大變化,所有的匯編助記符、寄存器、匯編器操作符都是關鍵字。
很明顯,隨著匯編語法結構的相對簡化,詞法記號的識別的復雜度也有所降低。另外由於由編譯器生成的匯編語言文件是經過測試正確的,因此不需要進行異常處理。
四、 語法分析
語法分析是匯編器設計的核心,從圖1-2就可以看出語法分析模塊的重要地位。匯編器的語法分析模塊不需要進行錯誤處理和修復的操作,但是必須正確識別並處理每一個關鍵的語法模塊。匯編語言有兩大類型的語法模塊:數據和指令。數據語法模塊要能識別所有類型的符號並存儲到符號表,供指令模塊和重定位表使用。指令語法模塊要填充臨時數據結構,供指令生成模塊生成正確的操作碼和操作數二進制信息。
簡單的說,語法分析的目的是填充系統需要的三張表:段表、符號表、重定位表。通過第一遍掃描將輸入文件的所有的段信息收集到段表中,所有的符號信息收集到符號表中,然後第二面掃描在產生重定位的地方生成重定位項,填充重定位表。這三張表是輸出文件信息的核心,下邊就按照這三張表的構造流程逐個說明。
4.1 段表
匯編語言使用section關鍵字聲明段開始,直到下一個段聲明或者文件結束位置結束,整個中間部分都屬於section聲明的段的內容。具體的說,由於編譯器生成的匯編文件共有三個段:.text,.data,.bss。又因為我們使用兩邊掃描源文件的方式,因此,在第二遍掃描之前(第一遍.bss段結束後)匯編器就可以獲得所有的段信息。參考鏈接器設計中elf文件Elf32_Shdr的數據結構可以看出段表項信息的最關鍵的信息是:段名、偏移、大小。段名在每次section聲明時候記錄下來即可,偏移計算之前必須知道上一個段的大小,因此段的大小計算是關鍵中的關鍵。為此匯編器使用一個全局變量curAddr記錄了相對於當前段的起始偏移,每次匯編語言定義一個需要地址空間存儲的語法模塊,這個curAddr就會累加當前語法模塊的大小,直到段聲明結束時記錄了整個段的大小。至於每個語法模塊的大小如何計算,在後邊符號表中再具體介紹。另外,由於.bss的特殊性,它的物理大小為0,但是虛擬大小需要計算。比如編譯器只使用.bss存儲了輔助棧供64k字節,因此虛擬大小為64k,但是占用磁盤空間大小為0。
另外還需要注意的是段的偏移並不是簡單的累加段的大小計算,因為還涉及另一個概念——段對齊。這裡和鏈接器類似,段的開始位置必須是一個數的整數倍(一般重定位目標文件是按照4字節對齊),因此在每次累加段偏移的時候需要考慮段對齊的影響。圖4-1給出了一個構造段表項一個例子:
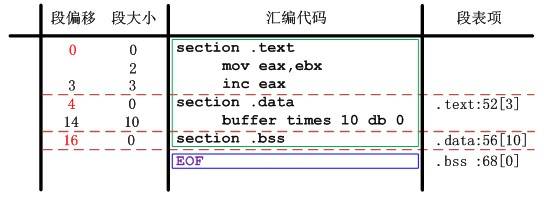 圖4-1 段表構造實例
圖4-1 段表構造實例
下面給出了段表項的相關代碼:
void Table::switchSeg()
函數switchSeg在每次段聲明的位置被調用,但是只是在第一次掃描時候生成段表項,每次調用後都會記錄當前段名到curSeg,並清零curAddr。dataLen記錄了當前的段偏移,添加段表項之前都會將之按照4字節對齊後在加上52(elf文件頭大小)作為真正的段偏移添加到段表。另外,.bss段聲明結束後是不累加段偏移的,這就反映了.bss無物理空間的含義。最後,addShdr按照段名分別生成具體的段表項,記錄到段表。
4.2 符號表
符號表是所有表中最重要的,段表使用它計算自身大小,重定位需要它識別重定位符號,最終的數據段和符號表段還需要符號表進行導出。符號表相關的有三個最重要的數據結構:lb_record,Inst和Table。顧名思義,lb_record記錄了當前分析出來的符號,Inst記錄了當前分析出來的指令,Table是對所有符號的記錄,即傳統意義上的符號表,不過這裡把Inst也作為符號表數據結構的一部分看待。下面首先給出這三種數據結構的定義:
首先說明符號數據結構:
struct lb_record//符號聲明記錄(1) curAddr:當前段偏移的靜態變量。
(2) segName:符號隸屬於的段名。
(3) lnName:符號名。
(4) isEqu:符號是否是equ定義的常量。
(5) externed:符號是否是外部符號。
(6) addr:符號的段偏移,若isEqu為true則表示符號的值。
(7) times:符號定義重復次數,不帶times關鍵字默認為1,equ和外部符號為0。
(8) len:符號類型長度,db,dw,dd分別為1,2,4字節,無類型為0。
(9) cont:符號定義的內容,無內容為NULL。
(10) cont_len:符號定義內容長度,無內容為0。
(11) lb_record(string n,bool ex):形如L:或者符號引用L dd @e_esp。
(12) lb_record(string n,int a):形如L equ 1。
(13) lb_record(string n,int t,int l,int c[],int c_l):形如L times 5 dw 1或者 L dd 2。
(14) write():輸出符號的二進制形式。
可以看出,構造符號記錄有五種可能;
(1)形如L:這種標號形式,符號記錄為本地局部符號,它代表一個32位地址,不占用任何存儲空間。
(2)形如L equ 1這種標號形式,符號記錄為本地局部符號,它代表一個32位立即數,不占用任何存儲空間。
(3)形如L db 0這種標號形式,符號記錄為全局符號,它對應了一串具體的數據,是數據段的組成部分,數據占用的空間大小為times*len*cont_len字節。
(4)形如L db 1這種標號形式,符號記錄為全局符號的引用,是extern變量生成的代碼,不占用存儲空間。
(5)形如call fun這種標號形式,fun如果不存在本地,那麼fun就是一個外部符號,它也不占用存儲空間。
這些所有的符號都會記錄在Table的中,含有實際數據的符號記錄在defLbs列表中。
指令數據結構如下,Intel x86指令格式在指令生成時會具體介紹。
struct ModRM//modrm字段(1) ModRM:指令的modrm字段,若mod=-1說明不存在modrm字段。
(2) SIB:指令的sib字段,若scale=-1說明不存在SIB字段。
(3) Inst:指令中其余需要的字段集合。
(4) opcode:本意為了記錄指令的操作碼,但由於操作碼的不具有統一性,因此此字段不再使用,輸出操作碼在指令生成的時候確定。
(5) disp:指令中偏移的大小,用於間接尋址和基址+偏移尋址。
(6) imm32:32位立即數,用於立即數尋址。
(7) dispLen:標識disp是8位還是32位。
指令長度的計算在後邊指令生成部分會具體說明。
符號表數據結構定義如下:
class Table//符號表(1) lb_map:
符號數據結構和符號名的哈希表。
(2) defLbs:記錄數據段中所有的符號定義。
(3) hasName():查看某個符號名是否存在。
(4) addLb():添加一個符號記錄。
(5) getLb():獲取指定名字的符號記錄,若不存在添加一個外部符號。
(6) switchSeg():添加段表項。
(7) exportSyms():導出所有的非equ定義符號到elf文件中。
(8) write():輸出數據段,即defLbs記錄的符號對應的所有數據。
符號表除了記錄符號的信息之外,還要保證使用符號表的模塊能正確訪問對應符號的信息。這裡主要處理在addLb和getLb函數中。首先看看addLb的功能:
void Table::addlb(lb_record*p_lb)//添加符號可以看出每次添加符號的時候都會檢查符號是否存在,若不存在則說明是第一次遇到這個符號,添加這個符號到符號表,否則說明符號出現過(可能是定義,也可能是引用)則決定是否替換,如果替換符號是本地定義的符號那麼就更新符號,否則就不更新。這裡只在第一次掃描時決定,第二次掃描直接忽略這個動作。
另外這個函數還記錄了含有實體數據的符號,函數在第二次掃描中檢查數據段中times不為0的本地變量,這些變量必然是有實際數據的,把它們記錄在defLbs列表中,而且它們是按照定義的順序有序的,這就保證了地址的正確性,這就為生成數據段做了准備。
或許有人會有疑問如何符號的引用生成符號記錄的,這裡需要了解getLb函數:
lb_record * Table::getlb(string name)
getLb函數返回制定符號名稱對應的符號結構,當符號不存在的時候,就生成一個外部符號引用結構,一旦出現本地這個符號定義就被替換為更完整的符號結構信息。這樣經過一遍的掃描,本地符號引用被替換為真實的符號定義,未被替換的外部符號記錄就是真正的外部符號引用。結合上述的addLb的功能可以完整的獲得所有符號的結構。
到此為止,匯編程序已經能獲得所有的符號信息。但是這些符號並不是最終導入到目標文件的符號,在此之前還必須對一些符號進行過濾和處理,規則如下:
(1)equ定義的符號僅僅是立即時,並不需要導入到目標文件。
(2)按照編譯器的約定,以@cal_,@lab_,@while_,@if_以及符號@s_stack都是不會用到或者是局部跳轉不會產生重定位信息的符號,這些符號占有很大的比重,可以被優化刪除。
(3)按照編譯器約定,全局符號的名稱格式為:.text段中@str2long,@procBuf,和非@開頭的符號(函數名)都是全局符號;.data段中@str_開頭的緊跟非數字的符號或者其他符號都是全局的;所有的外部符號都是全局的。
按照這種約定構造的符號記錄添加到Elf32_Sym類型的符號表中構成elf文件的符號表,對符號的導出操作在exportSyms函數中。
4.3 重定位表
重定位是支持鏈接的編譯器的核心操作,因為在編譯匯編過程中,程序無法確定代碼的其實位置的虛擬地址,這個過程被推遲到鏈接的時候進行計算。由於無法確定數據起始位置的虛擬地址,那麼所有數據定義的符號地址都是“假”的地址,但是指令或者數據定義中一旦引用該符號,就有可能需要這個符號的“真實”的地址,這就需要重定位來修正這種偏差,因此,可以簡單的說:重定位來源於對符號的引用。無論這種引用是在數據段還是在代碼段,當然.bss不會出現重定位,因為.bss內的數據都是0,沒法重定位。另外,對符號的絕對、引用絕對是需要重定位的,因為符號定義的段的地址是無法確定的,而引用符號的地方需要的是符號的真實虛擬地址,因此必須重定位。對外部符號的相對引用是絕對需要重定位的,因為外部富符號的地址是未知的,因此必須到鏈接時重定位。對相同段內符號的相對引用絕對不需要重定位,因為內部符號與當前引用位置的相對位置不會發生變化,因為重定位就沒有必要了。
基於此,我們在語法分析時就需要留意對符號引用的語句,一旦出現這種引用就需要查看是否需要為此產生重定位項。在本匯編器文法中共用三種出現重定位項的可能:
(1)數據段中使用了符號引用:如:@s_esp dd @s_base,這個語句是本匯編器唯一一處對數據段沖定位的地方。實際上@s_base是.bss的段的符號,但是不管@s_base出現在何處,因為它是絕對地址,因此必須重定位。
(2)代碼段使用符號引用作為立即數,如mov eax,@buffer,由於@buffer真實地址不確定,因此需要對@buffer引用位置重定位。
(3)代碼段使用符號引用作為內存地址,如mov [@buffer_len],al,這裡@buffer_len地址也不確定,也需要重定位。
(4)代碼段使用符號引用作為跳轉地址,和之前的指令不同,類似call,jmp,jcc的指令不是把符號地址作為操作數,而是把被引用的符號的地址相對與當前指令的下一條指令的起始地址的偏移作為操作數。因為這種指令是否形成重定位項需要查看被引用的符號是否是外部符號。
這樣和鏈接器聯系起來,我們知道elf重定位類型有兩種:R_386_32和R_386_PC32,即絕對地址重定位和相對地址重定位,其含義如上所述。那麼匯編程序如何處理以上情況呢,這裡分別討論:
對於(1),它是數據段中惟一出現重定位的情況,但是很具有代表性。文法中允許符號定義dd後跟著一系列由都好連接的合法的數據,如L dd 1,2,L2等,這裡就需要確定L2出現的地址。在文法中每解析一個逗號數據項都會將數據按照單位放在一個臨時整形數組中,放入整數或者標識符數組長度加1,對於標識符記錄值為0(反正都需要重定位,記錄什麼值沒有區別),對於串就需要將串按照字節拆分,分別放入數組,數組長度增加量為串長。這樣重定位位置就很好確定了,即標號地址+數組長度*類型長度,重定位相關符號位當前引用符號,類型為絕對地址重定位R_386_32。
對於(2)、(3)(4),由於是在指令中重定位,而指令由於形式的不同,指令的操作碼和相關字節都會發生變化,因此無法在語法分析階段確定重定位的位置。現在我們假設已經知道了重定位的位置,對於一般的指令能確定重定位類型為R_386_32,對於call,jmp,jcc指令重定位類型為R_386_PC32,但是是否這得需要重定位還得繼續分析:
bool processRel(int type)//處理可能的重定位信息
relLb記錄了重定位引用符號的結構,根據傳遞來的重定位類型分別處理:對於絕對地址重定位必須保證被重定位的符號是非equ的符號,這裡不再解釋。對於相對重定位的符號必須保證是外部符號,因為內部符號不需要相對重定位。這裡沒有判斷引用符號是否是本段的符號,因為跳轉指令肯定在代碼段中,而跳轉指令不可能也不允許跳轉到其他段中,因此不需要再做比較。每次調用obj.addRel都會給當前目標文件添加一個重定位項目。
最後一步最“神秘”的部分來介紹指令裡邊都有什麼,如何確定指令的長度,怎麼計算指令重定位的位置?
五、 指令生成
作為匯編器最後一個模塊,也是最貼近底層的一個模塊,指令生成嚴重依賴於x86的指令的格式。
作者統計了編譯器生成的匯編代碼的所有指令,一共是23條:雙操作數指令5條,mov,cmp,add,sub,lea;但操作數指令17條,call,int,imul,idiv,neg,inc,dec,jmp,je,jg,jl,jge,jle,jne,jna;無操作數指令一條,ret。
那麼這些指令信息是如何保存的,以及最後如何輸出的,在深入討論之前,我們必須清楚了解x86的通用指令格式結構。
5.1 x86指令格式
圖5-1給出了x86指令的通用結構:
 圖5-1 x86指令格式
圖5-1 x86指令格式
為了直入正題,我們這裡只關心我們需要的結構:Opcode,ModRM,SIB,Disp,Imm字段。
對於操作碼,大多數通用指令的Opcode是單字節,最多是 2 字節的。Opcode是指令的核心部分,代表指令的功能,是不可缺少的。
ModRM 字節,意為:mod-reg-r/m 按2-3-3比例劃分字節。最主要作用是對指令的 operands 提供尋址,另外是對 Opcode 進行補充。ModRM.mod提供尋址模式, ModRM.reg用來提供寄存器 ID,ModRM.r/m 提供register的 ID或直接memory或者引導SIB字節。
有兩種情況下是無需用 ModRM 提供尋址的:
(1)一部分操作數是寄存器的,它直接嵌入 Opcode 中。
(2)一部分操作數是立即數的,它直接嵌入指令編碼中。
ModRM字節結構如下:
表 5-1 ModRM字節
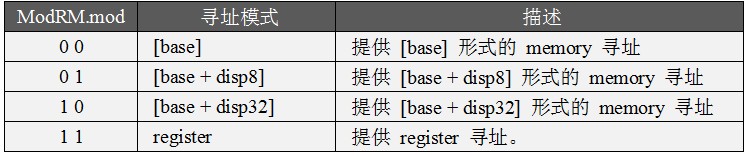
 ModRM.mod 提供r/m尋址的模式,這個模式以 disp長度或者值作區別。當 ModRM.mod = 11 時,它提供 register 尋址。如表5-2所示:
ModRM.mod 提供r/m尋址的模式,這個模式以 disp長度或者值作區別。當 ModRM.mod = 11 時,它提供 register 尋址。如表5-2所示:
表 5-2 ModRM.mod尋址模式
 ModRM.reg 提供寄存器尋址,reg 表示寄存器ID值,或者對 Group屬性的Opcode進行補充。如表5-3所示:
ModRM.reg 提供寄存器尋址,reg 表示寄存器ID值,或者對 Group屬性的Opcode進行補充。如表5-3所示:
表 5-3 ModRM.reg值
 ModRm.r/m提供 register尋址或memory 尋址。尋址模式由ModRM.mod決定。不過需要注意的是當ModRM.mod!=11,且ModRM.r/m==100時,表示引導SIB字段,disp信息仍有效。另外,當ModRm.mod==00時,ModRM.r/m==101,表示32位直接尋址模式,即[disp32]。
ModRm.r/m提供 register尋址或memory 尋址。尋址模式由ModRM.mod決定。不過需要注意的是當ModRM.mod!=11,且ModRM.r/m==100時,表示引導SIB字段,disp信息仍有效。另外,當ModRm.mod==00時,ModRM.r/m==101,表示32位直接尋址模式,即[disp32]。
對於ModRM字段的具體含義可以參考圖5-2:
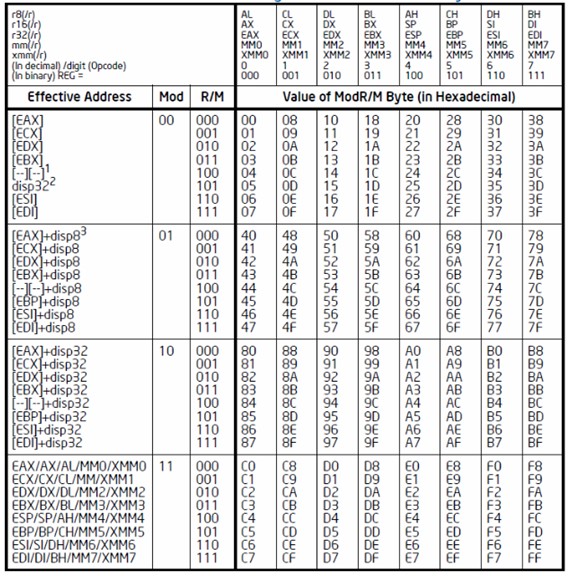 圖5-2 ModRM字段含義
圖5-2 ModRM字段含義
SIB 意即:Sacle-Index-Base 也是按 2-3-3比例劃分字節。這兩個字節用來為 memory 操作數提供 base, index 以及 scale,SIB 是對 ModRM 尋址的一個補充,ModRM 提供的是 registers 尋址、[register] 尋址(寄存器間接尋址)以及 [register + displacement](寄存器基址尋址),SIB 提供的是 [base + index * scale] 這種形式的尋址。即:基址 + 變址尋址。同樣,SIB 是可選的,前面已經說明SIB 字節由 ModRM.r/m = 100 引導出來,指令中命名用了 [base + index] 這種地址形式時,必須使用 SIB 進行編碼,SIB字節結構如表5-4所示:
表 5-4 SIB字節
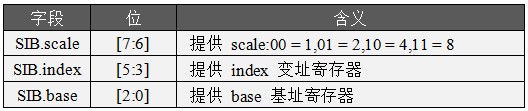 (1)SIB.scale 提供 index 寄存器乘數因子,正如表5-4所示,因子值=2^SIB.scale。
(1)SIB.scale 提供 index 寄存器乘數因子,正如表5-4所示,因子值=2^SIB.scale。
(2)SIB.index 提供 index 寄存器尋址,index寄存器的ID見表5-3。另外,當SIB.index==100時,說明沒有變址寄存器,只有基址尋址。
(3)SIB.base 提供 base 寄存器尋址,base寄存器的ID見表5-3。另外,當ModRM.mod==00,且SIB.base==101時,說明沒有基址寄存器,只有變址尋址。
對於SIB字段的具體含義可以參考圖5-3:
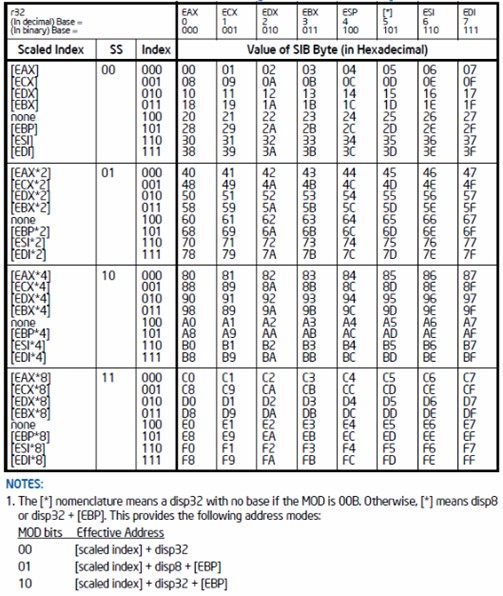 圖5-3 SIB字段含義
圖5-3 SIB字段含義
Disp字段記錄需要的偏移,有兩處需要記錄disp:一個是形如mov eax,[@buffer]直接內存尋址,這裡@buffer就是disp,毫無疑問它是32位的。另一個形如inc [ebp+1]的寄存器基址+偏移尋址,這裡disp等於1,按照數據的大小,它是8位的。如果這個值超過127或者小於-128,那麼就是32位的。
Imm字段記錄立即數尋址的指令,形如mov eax,1,這裡imm等於1,imm的長度去決定於另一個寄存器操作數長度。上述指令imm為32位,對於mov al,1,imm表示為8位。
至此對x86指令的格式簡單介紹完畢,下邊就是在語法模塊中分析指令的格式,填充指令的信息到之前的ModRM,SIB,Inst數據結構中去,為生成模塊服務。
5.2 指令信息記錄
指令信息的記錄是隨著指令的識別逐漸填充到對應的字段中的,下面按照操作數的類型進行填充指令數據結構。
(1) 首先識別出操作符關鍵字,記錄下來,作為後邊處理的依據。
(2) 按照操作數個數分類指令,識別每個操作數類型。
(3) 操作數為整數:mov eax,1,記錄裡imm=1,操作數類型為立即數。
(4) 操作數為符號:mov eax,@buffer,記錄imm為符號地址(重定位),操作數類型為立即數。
(5) 操作數為寄存器:mov eax,ebx,記錄寄存器編碼到modrm.reg,記錄寄存器長度。若第二個操作數也是寄存器,modrm.mod=3,交換rm和reg字節(因此雙操作數指令操作選用指令將rm作為目的操作數)。
(6) 操作數包含[],繼續識別內存尋址模式,操作數類型為內存。
(7) 直接尋址(一般是符號):modrm.mod=0,modrm.rm=5使用[disp32]尋址方式,disp記錄4字節的符號地址(重定位)。
(8) 寄存器間址:對於[esp]:modrm=0x00xxx100引導SIB,SIB=0x00100100。對於[ebp]:實際上是[ebp+0],modrm=0x01xxx101,disp=0,8位。對於一般的寄存器modrm.mod=0,modrm.rm為寄存器編號(reg記錄另一個操作數)。
(9) 基址+偏移:對於一般基址寄存器,將modrm.rm設置為基址寄存器編號,disp記錄偏移,根據[-128,127]區分disp位數,8位設置mod=1,32位設置modrm.mod=2。若基址寄存器是esp,modrm.rm=4,sib=0x00100100。
(10) 基址+變址:modrm=0x00xxx100引導sib,sib.scale=0,sib.index=變址寄存器編號,sib.base=基址寄存器編號。
這樣,23種指令的信息就可以全部記錄下來了,生成指令二進制信息時只需要訪問對應的三個數據結構即可。
5.3 指令輸出
模塊定義了一個輸出字節的函數:
void writeBytes(int value,int len)
它按照指定的長度按照little endian(小字節序)的方式輸出,而且只在第二次掃描時真正輸出數據,一般情況下僅僅累加輸出的數據量,即數據偏移,這既是為什麼重定位位置能確定以及代碼段的長度在第一遍掃描就能計算出看來的原因。
另外對於ModRM和SIB字節輸出代碼如下:
void writeModRM()
首先看雙操作數指令的輸出方法,這裡引入一個操作碼表5-5:
表 5-5 雙操作數操作碼表
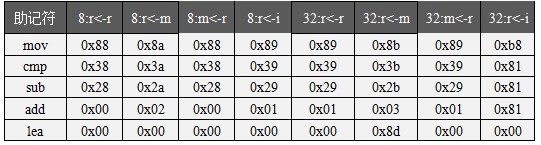 每種指令按照先8位操作數後32位操作數分組,每組按照r,r、r,rm、rm,r、r,im的形式記錄對應的操作碼。按照上述解析出的操作數的類型,不難索引查找到對應的操作碼。具體形式分以下情況考慮:
每種指令按照先8位操作數後32位操作數分組,每組按照r,r、r,rm、rm,r、r,im的形式記錄對應的操作碼。按照上述解析出的操作數的類型,不難索引查找到對應的操作碼。具體形式分以下情況考慮:
(1)mod=-1時表示立即數指令,這裡參考Intel的指令文檔。Mov指令需要opcode+modrm.reg後輸出1字節操作碼。而cmp,add,sub是輸出操作碼後,在輸出一個固定字節+mod.reg字節。對應固定字節為0xf8,0xc0,0xe8。在接下來輸出立即數之前還需要在此時處理可能存在的重定位項,因為此時的數據偏移就是重定位的位置。最後根據寄存器操作數的長度輸出立即數。
(2)mod=0時表示寄存器尋址,此時輸出操作碼、ModRM字段,若modrm.rm=5,說明是[disp32]尋址,需要處理重定位項後輸出32位disp。若modrm.rm=4需要輸出sib字節。
(3)mod=1、2時表示8、32位偏移基址尋址:輸出操作碼、ModRM和可能的SIB字段後輸出disp8/32。
(4)mod=3時表示雙寄存器操作數,輸出 操作碼和ModRM即可。
接著看單操作數指令的處理方法,和雙操作數類似,但操作數指令也有一個操作碼表,不過卻沒有雙操作數指令操作碼那麼有規律:
static unsigned short int i_1opcode[]=
這個表中僅僅記錄了某類指令的一部分操作碼,特殊情況的操作碼還需要具體補充。
(1)首先分析跳轉指令:call,jmp,jcc共9條指令,call和jmp都是單字節的,jcc都是雙字節的,因此分別輸出。注意這裡jcc操作碼不能使用writeBytes(opcode,2)進行輸出,因為雙字節操作數並不是小字節序的,因此應該拆分輸出:writeBytes(opcode>>8,1); writeBytes(opcode,1);接著就需要處理可能存在的相對重定位項,如果重定位項不存在那麼輸出4字節的偏移=imm-(curAddr+4),否則輸出-4,即當前位置相對於下一條指令的偏移。
(2)int指令:輸出操作碼和8位立即數。
(3)push指令:操作數為立即數時輸出0x68操作碼和32位立即數,操作數為32位寄存器時輸出opcode+modrm.reg字節。
(4)inc指令:操作數為8位寄存器時輸出操作碼0xfe和0xc0+modrm.reg,操作數是32位寄存器時輸出opcode+modrm.reg。
(5)dec指令:操作數為8位寄存器時輸出操作碼0xfe和0xc8+modrm.reg,操作數是32位寄存器時輸出opcode+modrm.reg。
(6)neg指令:若操作數是8位寄存器操作碼為0xf6,然後輸出0xd8+modrm.reg。
(7)pop指令:輸出操作碼+modrm.reg。
(8)imul指令:輸出操作碼和0xe8+modrm.reg。
(9)idiv指令:輸出操作碼和0xf8+modrm.reg。
無操作數指令只有一條ret,輸出字節0xc3。
至此,所有的指令二進制輸出完成。
六、 目標文件組裝
和之前介紹的鏈接器文件拼裝類似,這裡目標文件就是將段表、符號表、重定位表、數據段、代碼段組合到elf文件中去,子模塊的順序為elf文件頭,.text,.data,.shstrtab,段表,.syntab,.strtab,.rel.text,.rel.data,輸出主要流程如下,由於和鏈接器輸出方式類似,這裡不做具體代碼說明:
(1)輸出elf文件頭,段表加上空項共8個條目,e_shstrndx=3。
(2)輸出代碼段數據,填充代碼段和數據段的間隙,由於代碼段是在第二次掃描時輸出的,所以代碼段事先輸出到一個臨時文件中,這裡做了一次文件合並,最後刪除臨時文件。
(3)輸出數據段數據,即輸出defLbs的符號數據,填充數據段和.bss段的間隙,這裡調用了符號記錄的write方法。
void lb_record::write()(4)輸出所有段名抽取的字符串形成的.shstrtab。
(5)輸出段表,拼裝時e_shoff為當前偏移。
(6)輸出符號表。
(7)輸出所有符號名抽取的字符串形成的.strtab。
(8)輸出代碼段重定位表和數據段重定位表。
七、 匯編實例
用前述的編譯器生成的匯編文件common.s和main.s作為輸入,輸出文件common.o和main.o,使用readelf命令查看結果如下:
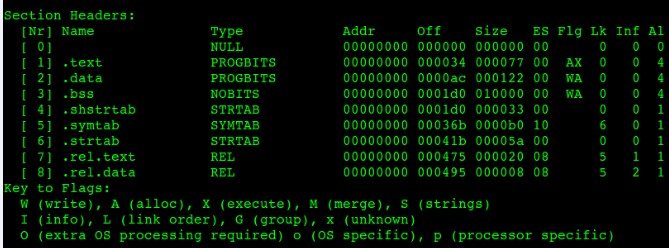 圖7-1 common.o段表
圖7-1 common.o段表
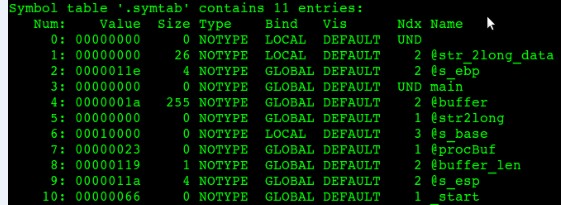 圖7-2 common.o符號表
圖7-2 common.o符號表
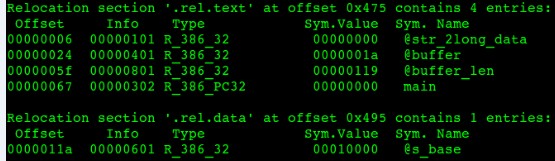 圖7-3 common.o重定位表
圖7-3 common.o重定位表
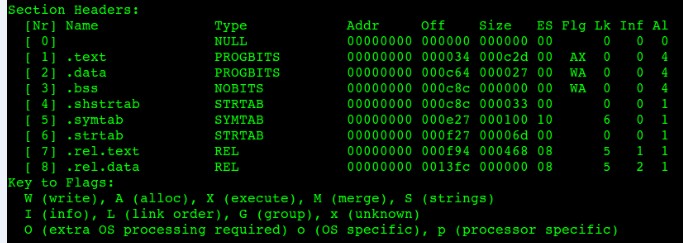 圖7-4 main.o段表
圖7-4 main.o段表
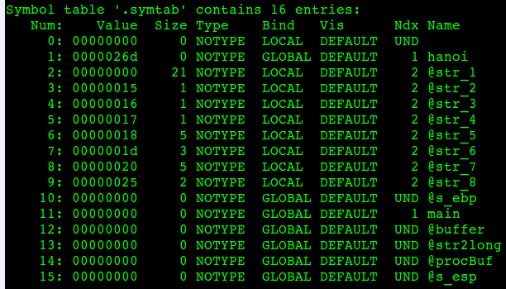 圖7-5 main.o符號表
圖7-5 main.o符號表
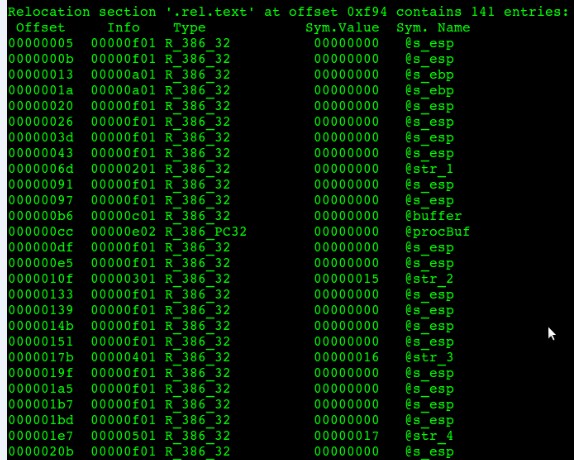 圖7-6 main.o部分重定位表
圖7-6 main.o部分重定位表
將這兩個目標文件作為鏈接器的輸入,生成的可執行文件的執行效果在編譯器構造中已經演示了,結果說明整個流程下來程序的執行是正常的。
八、 總結
通過對編譯器、匯編器、鏈接器構造的敘述,我們構造了一套完整的編譯系統程序,經過代碼測試,驗證了整個編譯系統的正確性。當然,該編譯系統僅僅是為了學習gcc相關知識而構造的,不具有主流編譯器的工業化性能。但是作為一款親手構造的的編譯系統來說,對於學習和理解編譯系統的內容部流程還是有一定的學習價值的。
http://xxxxxx/Linuxjc/1153664.html TechArticle