內核的內存使用不像用戶空間那樣隨意,內核的內存出現錯誤時也只有靠自己來解決(用戶空間的內存錯誤可以拋給內核來解決)。
所有內核的內存管理必須要簡潔而且高效。
主要內容:
內存的管理單元
獲取內存的方法
獲取高端內存
內核內存的分配方式
總結
1. 內存的管理單元
內存最基本的管理單元是頁,同時按照內存地址的大小,大致分為3個區。
1.1 頁
頁的大小與體系結構有關,在 x86 結構中一般是 4KB或者8KB。
可以通過 getconf 命令來查看系統的page的大小:
[wangyubin@localhost ]$ getconf -a | grep -i 'page'
PAGESIZE 4096
PAGE_SIZE 4096
_AVPHYS_PAGES 637406
_PHYS_PAGES 2012863
以上的 PAGESIZE 就是當前機器頁大小,即 4KB
頁的結構體頭文件是: <linux/mm_types.h> 位置:include/linux/mm_types.h

/*
* 頁中包含的成員非常多,還包含了一些聯合體
* 其中有些字段我暫時還不清楚含義,以後再補上。。。
*/
struct page {
unsigned long flags; /* 存放頁的狀態,各種狀態參見<linux/page-flags.h> */
atomic_t _count; /* 頁的引用計數 */
union {
atomic_t _mapcount; /* 已經映射到mms的pte的個數 */
struct { /* 用於slab層 */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* 此page作為私有數據時,指向私有數據 */
struct address_space *mapping; /* 此page作為頁緩存時,指向關聯的address_space */
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* 指向slab層 */
struct page *first_page; /* 尾部復合頁中的第一個頁 */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* 將頁關聯起來的鏈表項 */
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* 頁的虛擬地址 */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};物理內存的每個頁都有一個對應的 page 結構,看似會在管理上浪費很多內存,其實細細算來並沒有多少。
比如上面的page結構體,每個字段都算4個字節的話,總共40多個字節。(union結構只算一個字段)
那麼對於一個頁大小 4KB 的 4G內存來說,一個有 4*1024*1024 / 4 = 1048576 個page,
一個page 算40個字節,在管理內存上共消耗內存 40MB左右。
如果頁的大小是 8KB 的話,消耗的內存只有 20MB 左右。相對於 4GB 來說並不算很多。
1.2 區
頁是內存管理的最小單元,但是並不是所有的頁對於內核都一樣。
內核將內存按地址的順序分成了不同的區,有的硬件只能訪問有專門的區。
內核中分的區定義在頭文件 <linux/mmzone.h> 位置:include/linux/mmzone.h
內存區的種類參見 enum zone_type 中的定義。
內存區的結構體定義也在 <linux/mmzone.h> 中。
具體參考其中 struct zone 的定義。
其實一般主要關注的區只有3個:
區
描述
物理內存
ZONE_DMADMA使用的頁<16MBZONE_NORMAL正常可尋址的頁16~896MBZONE_HIGHMEM動態映射的頁>896MB某些硬件只能直接訪問內存地址,不支持內存映射,對於這些硬件內核會分配 ZONE_DMA 區的內存。
某些硬件的內存尋址范圍很廣,比虛擬尋址范圍還要大的多,那麼就會用到 ZONE_HIGHMEM 區的內存,
對於 ZONE_HIGHMEM 區的內存,後面還會討論。
對於大部分的內存申請,只要用 ZONE_NORMAL 區的內存即可。
2. 獲取內存的方法
內核中提供了多種獲取內存的方法,了解各種方法的特點,可以恰當的將其用於合適的場景。
2.1 按頁獲取 - 最原始的方法,用於底層獲取內存的方式
以下分配內存的方法參見:<linux/gfp.h>
方法
描述
alloc_page(gfp_mask)只分配一頁,返回指向頁結構的指針alloc_pages(gfp_mask, order)分配 2^order 個頁,返回指向第一頁頁結構的指針__get_free_page(gfp_mask)只分配一頁,返回指向其邏輯地址的指針__get_free_pages(gfp_mask, order)分配 2^order 個頁,返回指向第一頁邏輯地址的指針get_zeroed_page(gfp_mask)只分配一頁,讓其內容填充為0,返回指向其邏輯地址的指針alloc** 方法和 get** 方法的區別在於,一個返回的是內存的物理地址,一個返回內存物理地址映射後的邏輯地址。
如果無須直接操作物理頁結構體的話,一般使用 get** 方法。
相應的釋放內存的函數如下:也是在 <linux/gfp.h> 中定義的
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_page(struct page *page);
在請求內存時,參數中有個 gfp_mask 標志,這個標志是控制分配內存時必須遵守的一些規則。
gfp_mask 標志有3類:(所有的 GFP 標志都在 <linux/gfp.h> 中定義)
行為標志 :控制分配內存時,分配器的一些行為
區標志 :控制內存分配在那個區(ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM 之類)
類型標志 :由上面2種標志組合而成的一些常用的場景
行為標志主要有以下幾種:
行為標志
描述
__GFP_WAIT分配器可以睡眠__GFP_HIGH分配器可以訪問緊急事件緩沖池__GFP_IO分配器可以啟動磁盤I/O__GFP_FS分配器可以啟動文件系統I/O__GFP_COLD分配器應該使用高速緩存中快要淘汰出去的頁__GFP_NOWARN分配器將不打印失敗警告__GFP_REPEAT分配器在分配失敗時重復進行分配,但是這次分配還存在失敗的可能__GFP_NOFALL分配器將無限的重復進行分配。分配不能失敗__GFP_NORETRY分配器在分配失敗時不會重新分配__GFP_NO_GROW由slab層內部使用__GFP_COMP添加混合頁元數據,在 hugetlb 的代碼內部使用區標志主要以下3種:
區標志
描述
__GFP_DMA從 ZONE_DMA 分配__GFP_DMA32只在 ZONE_DMA32 分配 (注1)__GFP_HIGHMEM從 ZONE_HIGHMEM 或者 ZONE_NORMAL 分配 (注2)注1:ZONE_DMA32 和 ZONE_DMA 類似,該區包含的頁也可以進行DMA操作。
唯一不同的地方在於,ZONE_DMA32 區的頁只能被32位設備訪問。
注2:優先從 ZONE_HIGHMEM 分配,如果 ZONE_HIGHMEM 沒有多余的頁則從 ZONE_NORMAL 分配。
類型標志是編程中最常用的,在使用標志時,應首先看看類型標志中是否有合適的,如果沒有,再去自己組合 行為標志和區標志。
類型標志
實際標志
描述
GFP_ATOMIC__GFP_HIGH這個標志用在中斷處理程序,下半部,持有自旋鎖以及其他不能睡眠的地方GFP_NOWAIT0與 GFP_ATOMIC 類似,不同之處在於,調用不會退給緊急內存池。
這就增加了內存分配失敗的可能性GFP_NOIO__GFP_WAIT這種分配可以阻塞,但不會啟動磁盤I/O。
這個標志在不能引發更多磁盤I/O時能阻塞I/O代碼,可能會導致遞歸GFP_NOFS(__GFP_WAIT | __GFP_IO)這種分配在必要時可能阻塞,也可能啟動磁盤I/O,但不會啟動文件系統操作。
這個標志在你不能再啟動另一個文件系統的操作時,用在文件系統部分的代碼中GFP_KERNEL(__GFP_WAIT | __GFP_IO | __GFP_FS )這是常規的分配方式,可能會阻塞。這個標志在睡眠安全時用在進程上下文代碼中。
為了獲得調用者所需的內存,內核會盡力而為。這個標志應當為首選標志GFP_USER(__GFP_WAIT | __GFP_IO | __GFP_FS )這是常規的分配方式,可能會阻塞。用於為用戶空間進程分配內存時GFP_HIGHUSER(__GFP_WAIT | __GFP_IO | __GFP_FS )|__GFP_HIGHMEM)從 ZONE_HIGHMEM 進行分配,可能會阻塞。用於為用戶空間進程分配內存GFP_DMA__GFP_DMA從 ZONE_DMA 進行分配。需要獲取能供DMA使用的內存的設備驅動程序使用這個標志
通常與以上的某個標志組合在一起使用。以上各種類型標志的使用場景總結:
場景
相應標志
進程上下文,可以睡眠使用 GFP_KERNEL進程上下文,不可以睡眠使用 GFP_ATOMIC,在睡眠之前或之後以 GFP_KERNEL 執行內存分配中斷處理程序使用 GFP_ATOMIC軟中斷使用 GFP_ATOMICtasklet使用 GFP_ATOMIC需要用於DMA的內存,可以睡眠使用 (GFP_DMA|GFP_KERNEL)需要用於DMA的內存,不可以睡眠使用 (GFP_DMA|GFP_ATOMIC),或者在睡眠之前執行內存分配
2.2 按字節獲取 - 用的最多的獲取方法
這種內存分配方法是平時使用比較多的,主要有2種分配方法:kmalloc()和vmalloc()
kmalloc的定義在 <linux/slab_def.h> 中
/**
* @size - 申請分配的字節數
* @flags - 上面討論的各種 gfp_mask
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
#+end_src
vmalloc的定義在 mm/vmalloc.c 中
#+begin_src C
/**
* @size - 申請分配的字節數
*/
void *vmalloc(unsigned long size)
kmalloc 和 vmalloc 區別在於:
kmalloc 分配的內存物理地址是連續的,虛擬地址也是連續的
vmalloc 分配的內存物理地址是不連續的,虛擬地址是連續的
因此在使用中,用的較多的還是 kmalloc,因為kmalloc 的性能較好。
因為kmalloc的物理地址和虛擬地址之間的映射比較簡單,只需要將物理地址的第一頁和虛擬地址的第一頁關聯起來即可。
而vmalloc由於物理地址是不連續的,所以要將物理地址的每一頁都和虛擬地址關聯起來才行。
kmalloc 和 vmalloc 所對應的釋放內存的方法分別為:
void kfree(const void *)
void vfree(const void *)
2.3 slab層獲取 - 效率最高的獲取方法
頻繁的分配/釋放內存必然導致系統性能的下降,所以有必要為頻繁分配/釋放的對象內心建立緩存。
而且,如果能為每個處理器建立專用的高速緩存,還可以避免 SMP鎖帶來的性能損耗。
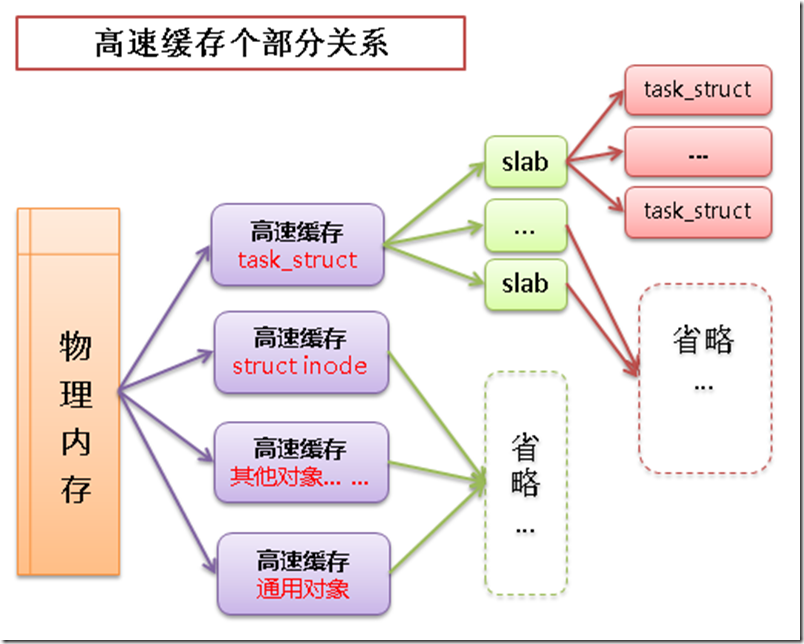
2.3.1 slab層實現原理linux中的高速緩存是用所謂 slab 層來實現的,slab層即內核中管理高速緩存的機制。
整個slab層的原理如下:
可以在內存中建立各種對象的高速緩存(比如進程描述相關的結構 task_struct 的高速緩存)
除了針對特定對象的高速緩存以外,也有通用對象的高速緩存
每個高速緩存中包含多個 slab,slab用於管理緩存的對象
slab中包含多個緩存的對象,物理上由一頁或多個連續的頁組成
高速緩存->slab->緩存對象之間的關系如下圖:
2.3.2 slab層的應用slab結構體的定義參見:mm/slab.c
struct slab {
struct list_head list; /* 存放緩存對象,這個鏈表有 滿,部分滿,空 3種狀態 */
unsigned long colouroff; /* slab 著色的偏移量 */
void *s_mem; /* 在 slab 中的第一個對象 */
unsigned int inuse; /* slab 中已分配的對象數 */
kmem_bufctl_t free; /* 第一個空閒對象(如果有的話) */
unsigned short nodeid; /* 應該是在 NUMA 環境下使用 */
};slab層的應用主要有四個方法:
高速緩存的創建
從高速緩存中分配對象
向高速緩存釋放對象
高速緩存的銷毀
/**
* 創建高速緩存
* 參見文件: mm/slab.c
* 這個函數的注釋很詳細,這裡就不多說了。
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))
/**
* 從高速緩存中分配對象也很簡單
* 函數參見文件:mm/slab.c
* @cachep - 指向高速緩存指針
* @flags - 之前討論的 gfp_mask 標志,只有在高速緩存中所有slab都沒有空閒對象時,
* 需要申請新的空間時,這個標志才會起作用。
*
* 分配成功時,返回指向對象的指針
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
/**
* 向高速緩存釋放對象
* @cachep - 指向高速緩存指針
* @objp - 要釋放的對象的指針
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
/**
* 銷毀高速緩存
* @cachep - 指向高速緩存指針
*/
void kmem_cache_destroy(struct kmem_cache *cachep)我做了創建高速緩存的例子,來嘗試使用上面的幾個函數。
測試代碼如下:(其中用到的 kn_common.h 和 kn_common.c 參見之前的博客《Linux內核設計與實現》讀書筆記(六)- 內核數據結構)
#include <linux/slab.h>
#include <linux/slab_def.h>
#include "kn_common.h"
MODULE_LICENSE("Dual BSD/GPL");
#define MYSLAB "testslab"
static struct kmem_cache *myslab;
/* 申請內存時調用的構造函數 */
static void ctor(void* obj)
{
printk(KERN_ALERT "constructor is running....\n");
}
struct student
{
int id;
char* name;
};
static void print_student(struct student *);
static int testslab_init(void)
{
struct student *stu1, *stu2;
/* 建立slab高速緩存,名稱就是宏 MYSLAB */
myslab = kmem_cache_create(MYSLAB,
sizeof(struct student),
0,
0,
ctor);
/* 高速緩存中分配2個對象 */
printk(KERN_ALERT "alloc one student....\n");
stu1 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);
stu1->id = 1;
stu1->name = "wyb1";
print_student(stu1);
printk(KERN_ALERT "alloc one student....\n");
stu2 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);
stu2->id = 2;
stu2->name = "wyb2";
print_student(stu2);
/* 釋放高速緩存中的對象 */
printk(KERN_ALERT "free one student....\n");
kmem_cache_free(myslab, stu1);
printk(KERN_ALERT "free one student....\n");
kmem_cache_free(myslab, stu2);
/* 執行完後查看 /proc/slabinfo 文件中是否有名稱為 “testslab”的緩存 */
return 0;
}
static void testslab_exit(void)
{
/* 刪除建立的高速緩存 */
printk(KERN_ALERT "*************************\n");
print_current_time(0);
kmem_cache_destroy(myslab);
printk(KERN_ALERT "testslab is exited!\n");
printk(KERN_ALERT "*************************\n");
/* 執行完後查看 /proc/slabinfo 文件中是否有名稱為 “testslab”的緩存 */
}
static void print_student(struct student *stu)
{
if (stu != NULL)
{
printk(KERN_ALERT "**********student info***********\n");
printk(KERN_ALERT "student id is: %d\n", stu->id);
printk(KERN_ALERT "student name is: %s\n", stu->name);
printk(KERN_ALERT "*********************************\n");
}
else
printk(KERN_ALERT "the student info is null!!\n");
}
module_init(testslab_init);
module_exit(testslab_exit);Makefile文件如下:
# must complile on customize kernel
obj-m += myslab.o
myslab-objs := testslab.o kn_common.o
#generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned執行測試代碼:(我是在 centos6.3 x64 上實驗的)
[root@vbox chap12]# make
[root@vbox chap12]# insmod myslab.ko
[root@vbox chap12]# dmesg | tail -220
# 可以看到第一次申請內存時,系統一次分配很多內存用於緩存(構造函數執行了多次)
[root@vbox chap12]# cat /proc/slabinfo | grep test #查看我們建立的緩存名在不在系統中
testslab 0 0 16 202 1 : tunables 120 60 0 : slabdata 0 0 0
[root@vbox chap12]# rmmod myslab.ko #卸載內核模塊
[root@vbox chap12]# cat /proc/slabinfo | grep test #我們的緩存名已經不在系統中了
3. 獲取高端內存
高端內存就是之前提到的 ZONE_HIGHMEM 區的內存。
在x86體系結構中,這個區的內存不能映射到內核地址空間上,也就是沒有邏輯地址,
為了使用 ZONE_HIGHMEM 區的內存,內核提供了永久映射和臨時映射2種手段:
3.1 永久映射
永久映射的函數是可以睡眠的,所以只能用在進程上下文中。
/* 將 ZONE_HIGHMEM 區的一個page永久的映射到內核地址空間
* 返回值即為這個page對應的邏輯地址
*/
static inline void *kmap(struct page *page)
/* 允許永久映射的數量是有限的,所以不需要高端內存時,應該及時的解除映射 */
static inline void kunmap(struct page *page)
3.2 臨時映射
臨時映射不會阻塞,也禁止了內核搶占,所以可以用在中斷上下文和其他不能重新調度的地方。
/**
* 將 ZONE_HIGHMEM 區的一個page臨時映射到內核地址空間
* 其中的 km_type 表示映射的目的,
* enum kn_type 的定義參見:<asm/kmap_types.h>
*/
static inline void *kmap_atomic(struct page *page, enum km_type idx)
/* 相應的解除映射是個宏 */
#define kunmap_atomic(addr, idx) do { pagefault_enable(); } while (0)以上的函數都在 <linux/highmem.h> 中定義的。
4. 內核內存的分配方式
內核的內存分配和用戶空間的內存分配相比有著更多的限制條件,同時也有著更高的性能要求。
下面討論2個和用戶空間不同的內存分配方式。
4.1 內核棧上的靜態分配
用戶空間中一般不用擔心棧上的內存不足,也不用擔心內存的管理問題(比如內存越界之類的),
即使出了異常也有內核來保證系統的正常運行。
而在內核空間則完全不一樣,不僅棧空間有限,而且為了管理的效率和盡量減少問題的發生,
內核棧一般都是小而且固定的。
在x86體系結構中,內核棧的大小一般就是1頁或2頁,即 4KB ~ 8KB
內核棧可以在編譯內核時通過配置選項將內核棧配置為1頁,
配置為1頁的好處是分配時比較簡單,只有一頁,不存在內存碎片的情況,因為一頁是本就是分配的最小單位。
當有中斷發生時,如果共享內核棧,中斷程序和被中斷程序共享一個內核棧會可能導致空間不足,
於是,每個進程除了有個內核棧之外,還有一個中斷棧,中斷棧一般也就1頁大小。
查看當前系統內核棧大小的方法:
[xxxxx@localhost ~]$ ulimit -a | grep 'stack'
stack size (kbytes, -s) 8192
4.2 按CPU分配
與單CPU環境不同,SMP環境下的並行是真正的並行。單CPU環境是宏觀並行,微觀串行。
真正並行時,會有更多的並發問題。
假定有如下場景:
void* p;
if (p == NULL)
{
/* 對 P 進行相應的操作,最終 P 不是NULL了 */
}
else
{
/* P 不是NULL,繼續對 P 進行相應的操作 */
}在上述場景下,可能會有以下的執行流程:
剛開始 p == NULL
線程A 執行到 [if (p == NULL)] ,剛進入 if 內的代碼時被線程B 搶占
由於線程A 還沒有執行 if 內的代碼,所以 p 仍然是 NULL
線程B 搶占到CPU後開始執行,執行到 [if (p == NULL)]時, 發現 p 是 NULL,執行 if 內的代碼
線程B 執行完後,線程A 重新被調度,繼續執行 if 的代碼
其實此時由於線程B 已經執行完,p 已經不是 NULL了,線程A 可能會破壞線程B 已經完成的處理,導致數據不一致
在單CPU環境下,上述情況無需加鎖,只需在 if 處理之前禁止內核搶占,在 else 處理之後恢復內核搶占即可。
而在SMP環境下,上述情況必須加鎖,因為禁止內核搶占只能禁止當前CPU的搶占,其他的CPU仍然調度線程B 來搶占線程A 的執行
SMP環境下加鎖過多的話,會嚴重影響並行的效率,如果是自旋鎖的話,還會浪費其他CPU的執行時間。
所以內核中才有了按CPU分配數據的接口。
按CPU分配數據之後,每個CPU自己的數據不會被其他CPU訪問,雖然浪費了一點內存,但是會使系統更加的簡潔高效。
4.2.1 按CPU分配的優勢按CPU來分配數據主要有2個優點:
最直接的效果就是減少了對數據的鎖,提高了系統的性能
由於每個CPU有自己的數據,所以處理器切換時可以大大減少緩存失效的幾率 (*注1)
注1:如果一個處理器操作某個數據,而這個數據在另一個處理器的緩存中時,那麼存放這個數據的那個
處理器必須清理或刷新自己的緩存。持續的緩存失效成為緩存抖動,對系統性能影響很大。
4.2.2 編譯時分配可以在編譯時就定義分配給每個CPU的變量,其分配的接口參見:<linux/percpu-defs.h>
/* 給每個CPU聲明一個類型為 type,名稱為 name 的變量 */
DECLARE_PER_CPU(type, name)
/* 給每個CPU定義一個類型為 type,名稱為 name 的變量 */
DEFINE_PER_CPU(type, name)
注意上面兩個宏,一個是聲明,一個是定義。
其實也就是 DECLARE_PER_CPU 中多了個 extern 的關鍵字
分配好變量後,就可以在代碼中使用這個變量 name 了。
DEFINE_PER_CPU(int, name); /* 為每個CPU定義一個 int 類型的name變量 */
get_cpu_var(name)++; /* 當前處理器上的name變量 +1 */
put_cpu_var(name); /* 完成對name的操作後,激活當前處理器的內核搶占 */
通過 get_cpu_var 和 put_cpu_var 的代碼,我們可以發現其中有禁止和激活內核搶占的函數。
相關代碼在 <linux/percpu.h> 中
#define get_cpu_var(var) (*({ \
extern int simple_identifier_##var(void); \
preempt_disable();/* 這句就是禁止當前處理器上的內核搶占 */ \
&__get_cpu_var(var); }))
#define put_cpu_var(var) preempt_enable() /* 這句就是激活當前處理器上的內核搶占 */
4.2.3 運行時分配除了像上面那樣靜態的給每個CPU分配數據,還可以以指針的方式在運行時給每個CPU分配數據。
動態分配參見:<linux/percpu.h>
/* 給每個處理器分配一個 size 字節大小的對象,對象的偏移量是 align */
extern void *__alloc_percpu(size_t size, size_t align);
/* 釋放所有處理器上已分配的變量 __pdata */
extern void free_percpu(void *__pdata);
/* 還有一個宏,是按對象類型 type 來給每個CPU分配數據的,
* 其實本質上還是調用了 __alloc_percpu 函數 */
#define alloc_percpu(type) (type *)__alloc_percpu(sizeof(type), \
__alignof__(type))動態分配的一個使用例子如下:
void *percpu_ptr;
unsigned long *foo;
percpu_ptr = alloc_percpu(unsigned long);
if (!percpu_ptr)
/* 內存分配錯誤 */
foo = get_cpu_var(percpu_ptr);
/* 操作foo ... */
put_cpu_var(percpu_ptr);
5. 總結
在眾多的內存分配函數中,如何選擇合適的內存分配函數很重要,下面總結了一些選擇的原則:
應用場景
分配函數選擇
如果需要物理上連續的頁選擇低級頁分配器或者 kmalloc 函數如果kmalloc分配是可以睡眠指定 GFP_KERNEL 標志如果kmalloc分配是不能睡眠指定 GFP_ATOMIC 標志如果不需要物理上連續的頁vmalloc 函數 (vmalloc 的性能不如 kmalloc)如果需要高端內存alloc_pages 函數獲取 page 的地址,在用 kmap 之類的函數進行映射如果頻繁撤銷/創建教導的數據結構建立slab高速緩存上文來自:http://www.cnblogs.com/wang_yb/archive/2013/05/23/3095907.html


