


內核版本:2.6.34
報文的IP校驗和、ICMP校驗和、TCP/UDP校驗和使用相同的算法,在RFC1071中定義,網上這方面的 資料和例子很多,就不解釋算法流程了,而是側重於在實現的變化和技巧。
The checksum algorithm is simply to add up all the 16-bit words in one's complement and then to take the one's complement of the sum.
校驗和的計算可以分為兩步:累加、取反。這個劃分很重要,它大大減少了校驗和計算的消耗。校驗和計 算首要要明確一點:校驗和計算是很耗時的!原因並不在於算法復雜,而是在於輸入數據的龐大,試想傳送500M文件,則內核要 校驗500M字節的數據,並且對於每個報文,都是要進行校驗和。所以協議棧的校驗和實現並不是簡單明了的,使用了很多方法來 規避這種開銷。
第一:推遲校驗和計算
按照協議的規定,報文到達每一層,首先驗證校驗 和是否正確,丟棄掉不正確的報文,再才會進行後續操作。對於傳輸層下的協議,內核是這樣做的,因為IP只需要校驗IP報頭, 最多60字節;而對於網絡層上的協議,內核就不是這樣做的,ICMP/TCP/UDP都需要校驗報文的內容,而這部分消耗是很大的。
以UDP為例,在報文傳遞到UDP處理時,它並不會去驗證校驗和是否正確,而是直接將報文skb插入 到相應socket的接收隊列sk_receive_queue中。等到真正有程序要接收這個報文,從接收隊列中取出時,內核才去計算校驗和。 考量下這種做法,由於推遲了校驗和計算,因此很多錯誤的報文都被接收了,它們會占用處理報文的流程,直到報文准備進入用 戶空間時,這時候才計算了校驗和,發現錯誤並丟棄掉。這樣看似乎平白無故增加了開銷,必竟校驗和的計算是一定要進行的。 但這樣做,將校驗和計算推遲到了拷貝報文到用戶空間時,這兩個操作的綁定是很關鍵的。本來,校驗和計算要遍歷一次報文, 而拷貝又要遍歷一次報文,這樣就是兩次遍歷操作,合並後用一次遍歷搞定,它所節約的開銷是遠遠多於額外支付的。
第二:分離校驗和計算步驟
開始提到校驗和的計算分為兩步:累加、取反,將這兩步分開後,會 發現校驗和是可以一部分一部分計算的,最後再用每部分計算的值求和取反。這個特性在另一方面對拷貝和校驗和計算同時進行 提供了支持。並且,由於報文可能是分片重組的,這樣報文內容並不是一起存儲在線性地址空間中,而是將分片掛在第一個分片 skb的frag_list上,這部分內容是存儲在非線性地址空間的。因此,拷貝會一個分片一個分片的進行,由於校驗和計算的劃分, 它也可以一個分片一個分片的計算。csum_partial()和csum_fold()就是為此而生的,前者計算累加,後者計算取反。
所以一般校驗和會這樣計算,skb_checksum()計算skb的累加和,並和之前已經計算出的累加和skb- >csum相加,然後csum_fold()對最後結果取反,就是得到的校驗和。s
um = csum_fold(skb_checksum(skb, 0, len, skb->csum));
第三:改進校驗和計算
RFC1071中校驗和計算是每16bit為 單位的,但實際在累加這一步是可以調整的,內核計算是每32bit計算的,單位越大,循環就少,效率也自然會高。下面要說明 的是32bit累加與16bit累加結果是一致的。
假設要計算8個字節的校驗和,這8字節按每16bit分成 4份:1,2,3,4。左邊是每16bit累加的過程,右邊是每32bit累加的過程:
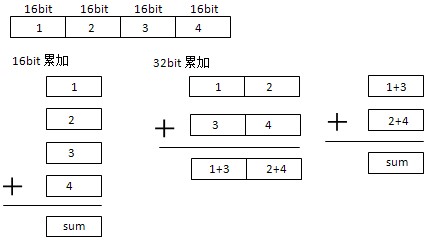
會出現疑惑的地方就是累加的進位問題,左邊16bit累加進位加到sum中,右邊32bit累加進位也要加到sum中,至於2,4相 加產生的進位,和16bit累加進位的結果是一樣的。下面就是32bit累加的代碼段,w>result判斷是否產生了進位,假設X+Y=Z 產生了進位溢出,則X<Z且Y<Z,否則Z>X且Z>Y。
unsigned int
carry = 0;
do {
unsigned int w = *(unsigned int *) buff;
count--;
buff += 4;
result += carry;
result += w;
carry = (w > result);
} while (count);
result += carry;
result = (result & 0xffff) + (result >> 16);
第四:校驗和計算技巧
節 省校驗和最好的辦法就是不計算校驗和,這在某些情況下是可行的,比如大流量發包時或局域網中,這時效率比正確性更為重要 。skb->ip_summed參數就是為此目的,CHECKSUM_UNNECESSARY就跳過校驗和計算。或者用戶在發包時設置校驗和字段 checksum=0,也會跳過校驗和計算。
skb->ip_summed = CHECKSUM_UNNECESSARY;
另外為了加速校驗和計算,很多網卡都提供了硬件計算校驗和,特別的,linux使用了skb->ip_summed和skb->csum 來使用硬件計算能力來幫助校驗TCP/UDP報文。CHECKSUM_COMPLETE表示硬件進行了計算,計算結果存儲在skb->csum中。
skb->ip_summed == CHECKSUM_COMPLETE;
在很多芯片的實現上,校驗和的計 算代碼都是用匯編來實現了,這也是出於校驗和計算的效率考慮。
最後,簡單分析下校驗和計算的兩個核心函數 。
do_csum() 校驗和累加
校驗和計算的主體部分是32bit為單位計算的,並假設buff起始地 址是對齊過的,長度也是對齊過的。因此,傳入的buff要進行處理以滿足假設。
保證計算的起始地址 是字節對齊
這裡的對齊有16bit對齊和32bit對齊。起始地址是對齊是為了效率,比如起始地址是 奇數,那麼累加時用16bit或32bit就很可能跨越一個int范圍,即讀一個數要兩次內存操作;對齊後讀一個數都只用一次內存操 作。
如果不是偶數字節,則odd=1,處理掉第一個字節,使超地址變成偶數。
odd = 1 & (unsigned long) buff;
if (odd) {
#ifdef __LITTLE_ENDIAN
result += (*buff << 8);
#else
result = *buff;
#endif
len--;
buff++;
}
當然處理掉第一個字節後,從buff計算校驗和與從buf+1計算校驗和結果顯然是不同的,下面這步在校驗和計算完成 後,就是為了處理這種差異的。
if (odd) result = ((result >> 8) & 0xff) | ((result & 0xff) << 8);
還是以例子說明,一個5字節 的buff,起始地址addr(1)=0x1,下面是傳統計算和從偶數地址開始計算的對比,要注意的是累加進程中是循環進位的,即溢出 的進位會加到最低位。因此,無論哪種方法,1,3,5累加進位會加到2+4中,而2,4累加進位會加到1+3+5中,這也是最後調換前後 8bit的值就可以保證兩者相等原因。
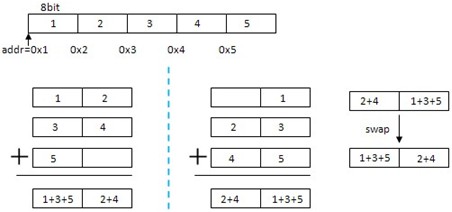
保證計算的長度是偶數字節
長度對齊理由很簡單,累加是 以16bit為單位的,因此主體部分只計算偶數字節,如果有多余的一個字節len & 1,則進行如下處理。
if (len & 1) #ifdef __LITTLE_ENDIAN result += *buff; #else result += (*buff << 8); #endif
最後是計算的主體部分,可以看到,它並不是單純的16bit累加,而是用32bit累加do-while循環。當然,為了 進行32bit累加,要將起始地址處理成32bit對齊,長度也要處理成32bit對齊。
count = len >> 1; /* nr of 16-bit words.. */
if (count) {
if (2 & (unsigned long) buff) {
result += *(unsigned short *) buff;
count--;
len -= 2;
buff += 2;
}
count >>= 1; /* nr of 32-bit words.. */
if (count) {
unsigned int carry = 0;
do {
unsigned int w = *(unsigned int *) buff;
count--;
buff += 4;
result += carry;
result += w;
carry = (w > result);
} while (count);
result += carry;
result = (result & 0xffff) + (result >> 16);
}
if (len & 2) {
result += *(unsigned short *) buff;
buff += 2;
}
}
csum_fold() 校驗和取反
取反操作很簡單,~sum
static inline __sum16 csum_fold(__wsum csum)
{
u32 sum = (__force u32)csum;
sum = (sum & 0xffff) + (sum >> 16);
sum = (sum & 0xffff) + (sum >> 16);
return (__force __sum16)~sum;
}