


作為聊聊架構群裡的新人,今天很榮幸在這裡和大家分享一些自己的心得體會。做過碼農,帶過項目,倒騰過產品,現在在看銀行基礎架構上的一些事情。資歷淺薄,只能從自己熟悉的領域跟大家做一些分享,就算是拋磚引玉,給大家一個靶子來討論。
我自06年開始做兼職,就一直在金融行業,更准確地說,一直在銀行業。這樣的經歷是幸運的,也是比較悲催的。悲催的是,基本上只懂銀行,而且銀行IT的壓力比較大。幸運的是,銀行在信息化建設中是前沿行業,同時要求高,所以也呆過很多不錯團隊,見到過很多比較好的東西。
今天的分享主要是基於我最近的工作,基於自主可控技術的新一代銀行架構,來看銀行這個領域的一些架構特點。
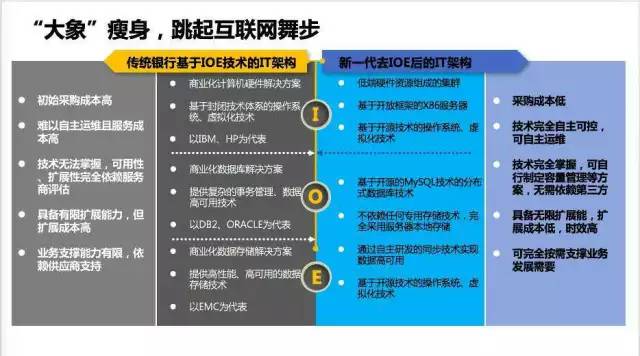
首先,為什麼把基於自主可控技術的架構稱為新一代架構?這裡說的新一代本身並不是指采用了像“量子計算”這樣的前沿技術的架構。這裡的“新一代”是相對於當前銀行業的主流的“IOE”架構而 言的。“IOE”指代的是由以IBM、ORACLE和EMC(被收購之前)為代表的商業解決方案。這些解決方案對於銀行來說,是一個黑盒子,無法自主掌 握。一切的開發、運維均需要服務商的支持與協助。而新一代的基於自主可控技術的銀行架構,則更多的選擇開放性的技術平台以及開源的技術產品,例如 XML:X86框架的PC服務器、MySQL為代表的開源數據庫和LINUX為代表的開源操作系統。是的,沒什麼了不起的技術,但是從來沒有哪個銀行把一 家銀行的架構完完全全地交給XML來構建。
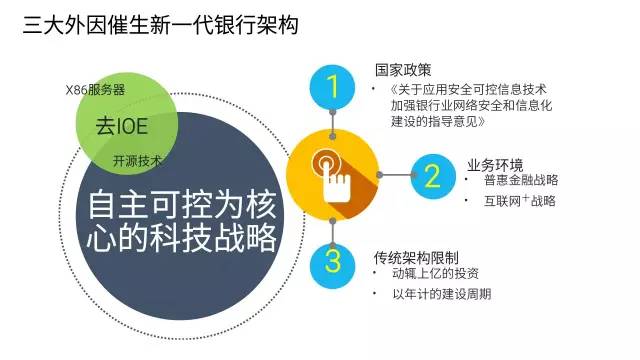
既然從來沒有發生過,那麼為什麼突然想要去做呢?三大外因驅動新一代銀行架構的誕生。
從國家層面,尤其是“稜鏡門”曝光之後,相關監管機構推出了著名的“39號文”: 《關於應用安全可控信息技術加強銀行業網絡安全和信息化建設的指導意見》。無論後續的發展被解讀為“叫停”、“暫停”,國家鼓勵在銀行也推動自主可控技術的應用已經是一個明確的方向。
其次,從行業發展的角度,銀行從依托對公及高淨值個人客戶,依靠利差為主要收入來源的“躺著賺錢時代”逐步步入了“以客戶為中心,通過場景服務更多人群”的“互聯網+”戰略下的普惠金融時代。而傳統架構下,居高不下的成本是一個巨大的障礙。
最後,傳統架構的雙高也是很多新興金融機構所無法接受的:“資金成本高”和“時間成本高”。
因此,尋求基於自主可控技術的架構,幾乎是新一代架構的必然選擇。
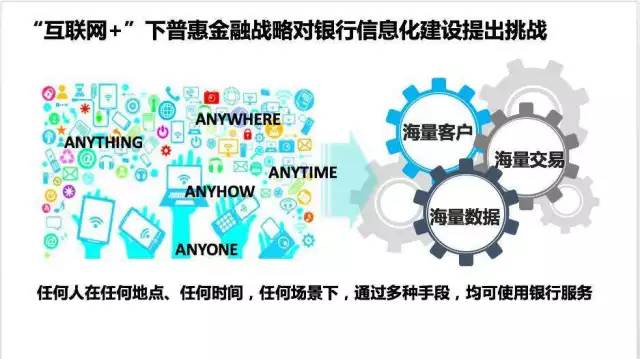
在業務形態上,互聯網銀行往往有以下一些特點:“純線上、輕人力、強系統”。因此,互聯網作為這些機構唯一的客戶觸點, 完全打破了所有已知的銀行運營模式。一個看似簡單的遠景:“任何人在任何地點、任何時間、任何場景下,通過多種手段均可使用銀行服務”,同時這也令新一代 架構站在了海量挑戰的風口浪尖:源源不斷的來自各個不同階層、不同背景的海量客戶,隨之而來的海量交易以及需要處理於存儲的海量數據。而這一切,成為了新 一代銀行架構從第一天起就不斷研究、解算的命題。
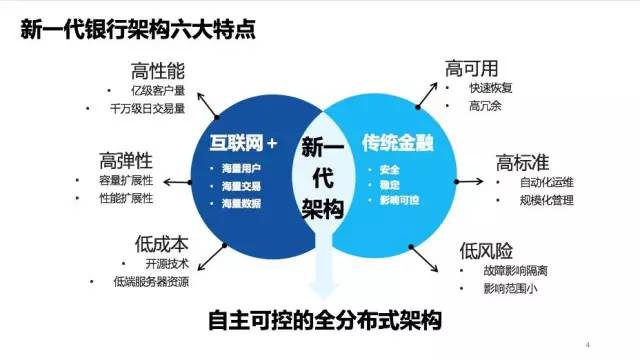
這道命題的答題思路被總結成了8個字“融合創新、平衡互補”。融合什麼?融合互聯網和銀行。互補什麼?以銀行IT的訴求和互聯網技術之間形成互補。簡單來說,新一代需要在做到互聯網行業所擅長的“高性能、高彈性和低成本”的同時,保持傳統金融行業對於“高可用、高標准和低風險”的追求。
之前看到一篇文章,忘記作者是哪位大咖(誠惶誠恐。。。),其中有一段話記憶尤為深刻。在“如何稱為一個合格的架構師”這個章節下,大咖提出了四門必修課,其中一門是“能和稀泥”。這“和稀泥”其實是指一個妥協的過程。而我個人的理解是:架構沒有最好的,最正確的,只有最合適的。按最合適的方式,在最合適的時間點,以最合適的成本獲得一個可能獲得的最好的結果。這個就是架構師要做的。
為什麼說這些呢?因為大家肯定已經看到了,要融合銀行和互聯網,難度不亞於要讓油溶於水。那麼,這裡面很重要的一點就是如何在不同的場景下,對架構設計進行取捨。
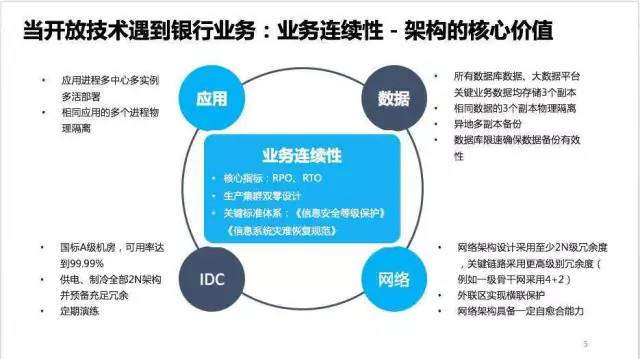
誠然,很多時候的討論都是case by case並且激烈的。但是,一個核心價值逐漸成為主導性因素:業務連續性。首先,它是監管機構懸在所有金融機構頭頂的利劍。其次,它是一個金融機構的信譽所在。業務連續性的兩個主要考核指標:RPO和RTO,一個決定了金融業務的安全性,一個決定了業務的可用性。老百姓不會相信一個動不動丟數據或者動不動因為市政工程就停業務的金融機構。然而,單點的可用性和穩定性往往是XML(重要事情再說一遍:XML指代新一代自主可控技術的主要代表:X86服務器、MySQL數據庫和LINUX操作系統)的短板。
因此,我們圍繞著構成整個架構的4個關鍵底層資源, 做了很多工作來保證業務連續性。在必要的時候,我們會捨棄單點的性能和靈活性,來保證業務連續性。例如,在數據庫網關上進行QPS的限制,將數據庫的負載 在一個合理的范圍,確保分布式數據庫中存儲相同數據的多個副本的多個節點間的數據同步的強一致性。那麼性能怎麼辦呢?一個節點被限制了,那麼通過邏輯將數 據進行分布,用更多的節點來承載業務,聚沙成塔。
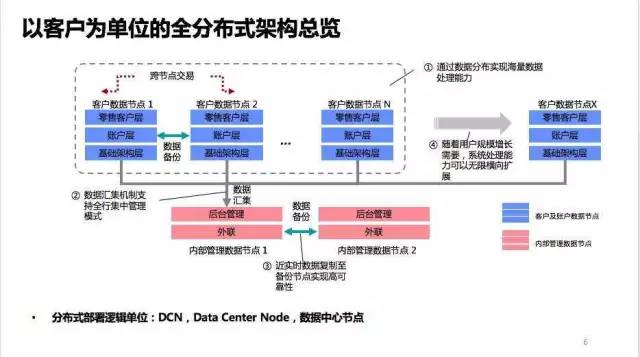
如何聚沙成塔?如何在金融行業構建一個全分布式架構?一種實踐解決方案是以客戶為單位進行數據分布。以我熟悉的銀行業為例,具體來看:將銀行的所有服務功能分成了兩大類:對客戶服務和後台管理服務。所有對客服務的能力,按照分布式架構設計理念,構建了多個服務相同類型客戶的數據中心節點,DCN。每個DCN承載一個獨立的客戶群體,擁有服務這個客群的所有能力以及屬於這個客群的每個客戶的所有數據。
而熟悉銀行業務的老師們可能會指出,很多銀行的關鍵數據是要以整個銀行作為整體來 看的,例如:會計科目的余額、授信額度和理財產品銷售額度等。確實如此,針對處理此類數據的後台管理服務,可以采用集中部署的方式,實現對全行的數據處理 的支撐。分布式架構不適合這樣的業務處理場景。因此,這部分系統可以采用集中部署,通過其他的分布式技術、可無限擴展的計算集群以及可按功能拆分的應用架 構,最終實現對這個節點的加固。
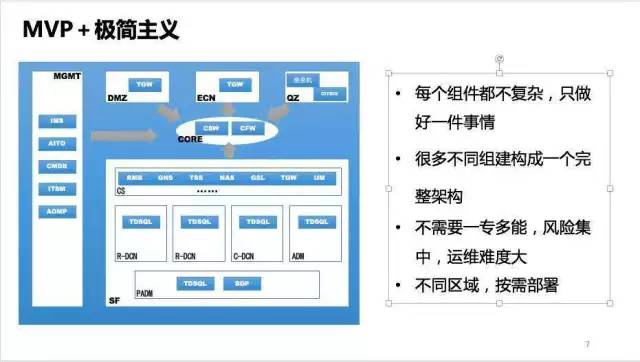
前 面講的是自主可控架構的一種邏輯實現。在技術組建的規劃和選擇上,也有一些特殊的考慮。在我自己的實踐過程中,不知不覺地實踐了MVP(minimum viable product)和極簡主義。之所以說不知不覺,是因為在一開始的時候,我們並沒有明確地提出這兩個觀點作為架構基本法。極簡主義的一些理念在討論中浮現 過,而MVP則並沒有被提及。但是,最後,我們發現,即使是底層架構這種相對較硬,靈活性較差的事物,依然可以通過MVP這種強調快速迭代的方式來規劃建 設。期間有很多挫折,也走了很多彎路。
但恰恰是MVP這種理念,使得我們最終能以較小的代價摸索出一條並無太多可借鑒的架構建設道路。至於極簡主義,則是刻意的讓每個組件只做一件事情,避免使用一個過於復雜,功能過於強大的“平台”。這個架構不能有明顯的“死穴”。其實想想,這個做法更像《失控》裡面描述的“Subsumption Architecture”。
Do simple things first.
Learn to do them flawlessly.
Add new layers of activity over the results of the simple tasks.
Don't change the simple things.
Make the new layers work as flawlessly as the simple.
Repeat, ad infinitum.
這種實踐其實最終和MVP理念渾然一體。
講了這麼多,附上一張對比圖,對比的是傳統IOE架構和新一代的XML架構。圖上的內容很多,這裡就不冗余述。
問題:全文圍繞可控做了精彩論述,但去IOE成本著實不小,如何衡量value?
這個問題非常好,去IOE非常難。做到需要很全面的技術儲備。如果沒有,則從短期來看,投入和成本都非常高。但是,從長遠上看,確實很明顯。單賬戶的一年的IT成本,可以輕松的達到同業的零頭。
問題:想問一下,xml中,對核心賬務部分怎麼處理的?
這個問題貌似和基礎架構關系不大,我試著回答一下哈(之前也做過幾年核心,呵呵)。核心的賬務分成分戶帳和總賬兩部分處理。分戶在每個客戶節點,總賬在後台管理節點。分戶完成余額之後,異步送總賬核心拆分錄和記賬。因為是異步的,所以不怕多打一。
問題:每個DCN承載著獨立的客戶群,這個客戶群是按什麼劃分的?
隨機分布,希望借此達到各個節點的客戶行為基本類似,而不希望因為某些屬性,導致某類客戶過度集中,使得節點的負載差異太大
問題:那張“以客戶為單位的全分布式架構總覽”圖中,客戶端節點1到N之間的“數據備份”是通過什麼技術實現的?備份的頻率?
那 張圖是當前1.0架構的情況:每個節點有一個主節點,一個同城備節點和一個異地備節點,主備間都是異步同步。將要實施完成的2.0架構下,同城將打通成一 個多活集群,但和異地備節點的備份還是異步同步。備份是實時的,異步場景下,同城時延的P95是差不多2-3秒,異地也差不多(多的僅僅網絡傳輸部分,幾 十毫秒吧)。
問題:想問下有沒有遇到架構擴展性不太好的事情,後面怎麼解決?
整 個架構裡面,最硬的是IDC和網絡,這兩部分確實遇到了使用速度遠高於規劃容量的問題。這裡面,IP的規劃上我們吃了些虧,目前IP吃緊,限制了一些更高 虛擬比的應用場景。所以,這塊大家如果做的話,需要充分評估好自己的集群規模,否則一旦投入生產,要加IP就會比較麻煩。
問題:架構合適就好,但是可擴展這個怎麼把控呢?
這個問題非常好,架構基本法裡面會規定橫向擴容和縱向擴容的策略,定期review相關的閥值,有一組數據模型來進行相關的容量管理和規劃。基本上:橫向擴容解決客戶容量問題,縱向擴容解決存量客戶性能問題(性能包括APP服務器的性能,和DB的容量和性能)。
問題:之前的IOE時,項目進度是如何管理,代碼行?功能點?還是其他呢?在新的公司,這方面又是如何管理呢?有什麼相同與不同呢?
個人認為項目管理和架構並沒有太大的關系。過去在IOE架構下的金融機構,一般是比較標准的瀑布式。現在的團隊是敏捷+持續集成,依托一個比較靈活的灰度機制,可以做到核心應用發布常態化,這樣需求就能切分的比較細。(這個可能需要我們的開發團隊的同學來回答會更准確些)
問題:數據中心節點是按照客戶劃分的,但一般金融機構都有自己的業務管理機構,客戶分屬不同的機構,這樣如果按照業務管理機構去做一些事情,就存在跨節點的操作了。不知道微眾銀行存不存在這方面的問題。
業務上不存在分支機構,所以不存在您說的那種場景。但是存在跨節點交易,例如轉賬的收付雙方可能在兩個不同的節點上。這個時候就需要由發起方負責整個事務的一致性(采用的還是之前的說的補償的機制)。
問題:DCN客戶如果是隨機劃分,怎麼做的數據路由(根據用戶什麼值做的路由),算法是一致性哈希麼?是否用過分庫的中間件產品?銀行業務在oralce中有大量的過程,在轉到mysql都進行了剔除了麼?
數 據路由是通過一個客戶定位組件來實現的一個基於內存KV的lookup。然後把節點信息填入消息的報文頭,然後消息總線會完成路由。(一致性哈希算法用在 了對內存KV的分片上,路由本身不需要算法,就是依賴高速查詢來實現)存儲過程必須統統干掉,我們的數據庫不支持。我們的數據庫支持分庫分表。
問題:如果采用XML架構,這裡所說的“每個DCN是隨機分布的”,是采取什麼技術方式實現隨機分布的呢?
邏輯上是在每個客戶注冊的時候,由一個公共組件負責分配她/她到某個節點上,算法也比較簡單:加權的RR。加權主要是為了實現在一些特殊的客戶分流需要,例如:通過特地調低一個節點的權重,使得的它的用戶數比較少,可以用來灰度發布。
問題:去IOE是個困難的過程,但是在去IOE的過度時期怎麼把握新架構系統和老系統的共存?
這個過渡時期確實困難, 異構系統之間因為架構的差異性,只能通過服務化的框架來解藕。並且通過隊列、緩存等機制來實現兩者之間的一個緩沖與保護(柔性設計)。如果做不到這些,問題會很多。在我們的場景下,因為沒有舊系統,所以,我還沒有失業。
原文:http://www.oschina.net/news/71490/future-bank-opensource