


Memcached是一個知名的,簡單的,全內存的緩存方案。這篇文章描述了facebook是如何使用memcached來構建和擴展一個分布式的key-value存儲 來為世界上最大的社交網站服務的。我們的系統每秒要處理幾十億的請求,同時存儲了幾萬億的數據項,可以給全世界超過10億的用戶提供豐富體驗。
以下特點大大影響了我們的設計。第一,用戶閱讀的內容比他們創建的要多一個數量級,這種行為(讀寫的特點)所產生工作負載,顯然讓緩存可以發揮很大的優 勢。第二,我們是從多個來源讀取數據的,比如MySQL數據庫、HDFS設備和後台服務,這種多樣性要求一個靈活的緩存策略,能夠從各個獨立的源中儲存數 據。
MemCached提供了一組簡單的操作(set、get和delete),使它在一個大規模的分布式系統中成為注目的基礎組件。開源版本提供了單機內存 哈希表,在本文中,我們從這個開源版本開始,討論我們是怎麼使用這個基礎組件,使它變得更有效,並用它來建一個可以處理每秒數十億請求的分布式的鍵-值儲 存系統。接下來,我們用“memcached”來指代它的源碼或者它運行的二進制實例,用“memcache”來指代由每個實例構成的分布式系統。
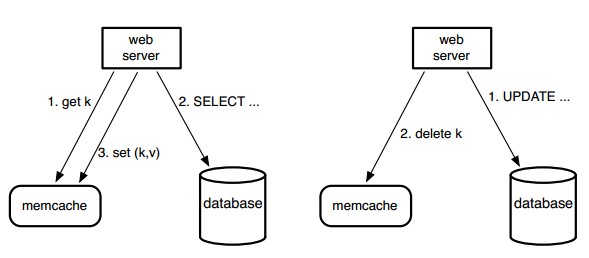
圖1:Memcache作為填補需求的旁路緩存系統。左半圖說明了WEB服務器讀取緩存時命中失敗的讀取路徑,右半圖說明其寫路徑。
查詢緩存:我們依賴於memcache來減輕讀取數據庫 的負擔。特別的,我們使用memcache作為填補需求的旁路緩存系統,如圖1。當一個Web服務器需要數據時,首先通過一個字符串的鍵在 memcache中請求,如果沒有找到,它會從數據庫或者從後台服務中檢索,再使用該鍵把結果存回memcache中。對於寫的請求,Web服務器發送 SQL語句到數據庫,接著發送刪除請求到memcache,使舊的緩存數據失效。因為刪除是冪等運算,所以我們使用刪除緩存的方式,而不是更新緩存。
在應對MySQL數據庫繁重的查詢通信的眾多方法中,我們選擇了memcache,在有限的資源與時間限制下,這是最好的選擇。此外,緩存層與持久層分離,讓我們可以在工作負載發生變化時快速地調整。
通用緩存:我們同樣讓memcache成為一個更加通用 的鍵-值儲存系統。比如說,工程師們使用memcache保存復雜的機器學習算法的中間結果,這些結果能被很多其它應用程序所使用。它只需要我們付出很少 的努力,就可以讓新增的服務利用現有的正在使用的基礎設施,而無需調整、優化、調配和維護大型的服務器群。
正如memcached沒有提供服務器到服務器的協同,它僅僅是運行在單機上的一個內存哈希表。接下來我們描述我們是如何基於memcached構建一個分布式鍵值儲存系統,以勝任在Facebook的工作負載下的操作。
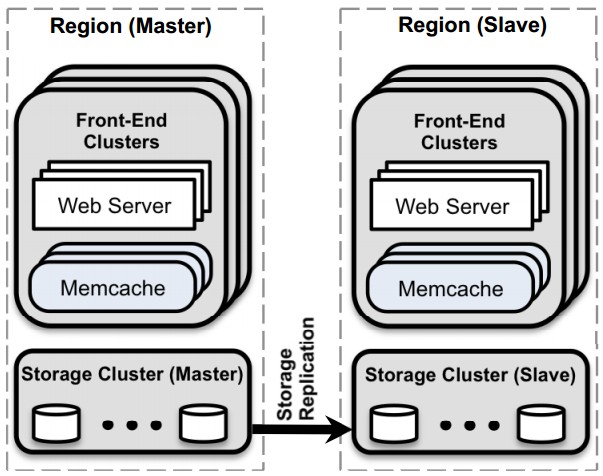
圖2:整體架構
論文的結構主要描述了在三種不同的規模下出現的問題。當我們擁有第一個服務器集群時,頻繁的讀負載和廣泛的輸出是我們最大的擔心。當有必要擴展到多個前端 集群時,我們解決了集群間的數據備份問題。最後,我們描述了一種機制,這種機制讓我們可以在全世界伸展集群的同時提供平滑的用戶體驗。不論在什麼尺度上, 容錯性和操作復雜性總是很重要的。我們展示了重要的數據參考,這些數據指引我們做出了最終的設計決定,讀者如需獲得更多細節性的分析,請參看 Atikoglu et al.[8]的工作。提綱挈領的解釋參看圖2,這是最終的架構,我們將並置集群組織起來,形成一個群體(region),指定一個主群體 (master),由主群體提供數據流讓非主群體保持數據同步。
在系統的發展中,我們將這兩個重大的設計目標放在首位:
1. 只有已經對用戶或者我們的運維產生影響的問題,才值得改變。我們極少考慮范圍有限的優化。
2. 對陳舊數據的瞬態讀取,其概率和響應度類似,都將作為參數來調整。我們會暴露輕度陳舊的數據以便後台存儲和高強度負載絕緣。
不論緩存是否命中,memcache的響應時間都是影響總響應時間的重要因素。單個的網頁請求一般包含數百個memcache讀請求。如一個較火的頁面平均需要從memcache中獲取521個不同的資源。
為了減少數據庫等的負擔,我們准備了緩存集群,每個集群都由數百台memcache服務器組成。資源個體經hash後 存於不同的memcache服務器中。因此,web服務器必須請求多台memcache服務器,才能滿足用戶的請求。由此導致在很短的時間裡每個web服 務器都要和所有的memcache服務器溝通。這種所有對所有的連接模式會導致潮湧堵塞(incast congestion)或者某台服務器不幸成為瓶頸。實時備份可以緩解這種狀況,但一般又會引起巨大的內存浪費。客戶端使用UDP和TCP協議與memcached服務器通訊。我們依賴UDP來使請求的延遲和開銷縮減。因為UDP是無連接的,web服務器中的每個線 程都被允許直接與memcached服務器通信,通過mcrouter,不需要創建與維護連接因而減少了開銷。UDP實現了檢測出丟失的或失序接收(通過 序列號)的包,並在客戶端將它們作為異常處理。它沒有提供任何試圖恢復的機制。在我們的基礎架構中,我們發現這個決定很實際。在峰值負載條件 下,memcache客戶端觀察到0.25%的請求會被丟棄。其中大約80%是由於延遲或丟失包,其余的是由於失序的交付。客戶端將異常作為緩存不命中處 理,但是web服務器在查詢出數據以後,會跳過插入條目到memcached,以便避免對可能超載的網絡會服務器增添額外的負載。
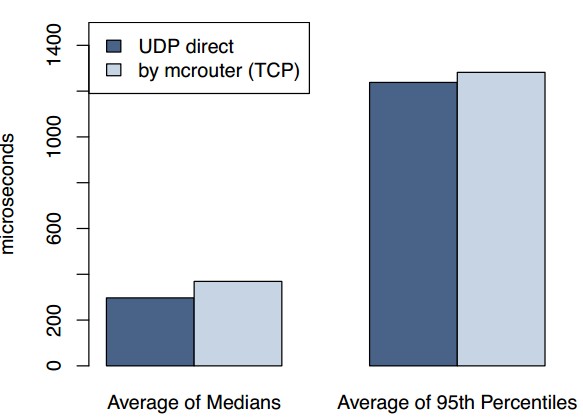
圖 3: 經過mcrouter以後 UDP, TCP得到的延遲
為了可靠性,客戶端通過同一個web服務器上運行的mcrouter實例,在TCP協議之上運行set與delete操作。對我們需要確認狀態變化(更新和刪除)的操作,TCP避免了UDP實現中增加重試機制的必要。
Web服務器依賴很高程度的並行性與超量提交來獲得高吞吐量。如果不采用由mcrouter合並的某種形式的連接,打開TCP連接需要的大量內存將使得在 每個web線程與memcached服務器之間打開連接變得尤其代價昂貴。通過減少高吞吐量TCP連接對網絡,CPU和內存資源的需求,合並這些連接的方 式增強了服務器的效率。圖3顯示了生產環境中web服務器在平均的,中級的,以及百分之95的條件下,在UDP和通過經由TCP的mcrouter機制下 獲得關鍵字的延遲。在所有情形,與這些平均值的標准差小於1%。正如數據所示,依賴UDP能有20%的延遲縮減來對請求提供服務。
================= =======================
1 百分之95的頁面抓取的是1,740項目。
2 百分之95情形是每個請求有95個關鍵字。
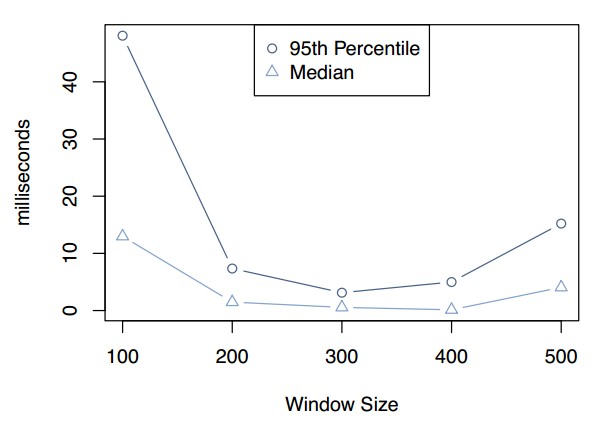
Incast擁塞:memcache客戶端實現流量控制機制限制incast擁塞。當一個客戶端請求大量的主鍵時,如果所有應答同時達到,那麼這些應答可 以淹沒一些組件,例如:機架和集群交換機。因此客戶端使用滑動窗口機制[11]來控制未處理請求的數量。當客戶端收到一個應答的時候,那麼下一個請求就可 以發送了。與TCP的擁塞控制類似,滑動窗口的大小隨著成功的請求緩慢的增長,當一個請求沒有應答的時候就縮小。這個窗口應用於所有的memcache請 求,而不關心目的地址;然而TCP窗口僅僅應用於單獨的數據流。
我們引入了一個稱為租約(leases)的新機制來解決兩個問題:過時設置(stale sets)和驚群(thundering herds)。當web服務器更新一個在緩存中不是最新版本的值的時候,一次過時設置就發生了。當對memcache的並發更新重新排序的時候,這種情況 是會發生的。當某個特定的主鍵被大量頻繁的讀寫,那麼一次驚群就發生了。因為寫操作反復地使最近設置的值失效,那麼讀操作將會默認地使用更耗時的方式。我 們的租約機制解決了這兩個問題。
[譯者注:此處的leases與Cary G. Gray的leases不一樣,不要混淆。]
直觀地,當這個客戶端發生緩存不命中時,memcached實例給客戶端一個租約,將數據設置到緩存中。租約是一個64bit的令牌,與客戶端初始請求的 主鍵綁定。當設值到緩存中時,客戶端提供這個租約令牌。通過這個租約令牌,memcached可以驗證和判斷是否這個數據應該被存儲,由此仲裁並發寫操 作。如果因為收到了對這個數據項的刪除請求,memcached使這個租約令牌失效,那麼驗證操作將會失敗。租約阻止過時設置的方法類似於load- link/store-conditional操作。
對租約的輕微改動也可以緩和驚群這個問題。每個memcached服務器調節返回令牌的速率。默認情況,我們配置服務器對於每個主鍵每10秒鐘返回一個令 牌。當在10秒鐘之內有請求,一個特殊的通知將會告訴客戶端稍等一下。通常,擁有租約的客戶端將會在幾個毫秒的時間內成功設置數據。因此,當等待客戶端重 試的時候,數據經常已經在緩存中了。
為了說明這一點,我們針對容易造成驚群的主鍵集合收集了一個星期的緩存不命中的記錄。如果沒有租約機制,所有的緩存不命中都會造成數據庫查詢率的峰值—— 17K/s。使用租約機制的時候,數據庫查詢率的峰值是1.3K/s。因為我們依據峰值負載准備數據庫,所有租約機制提供了顯著的效率增益。
過期值:當使用租約機制的時候,我們可以最小化某些特定用例下的應用等待時間。我們可以通過鑒別返回稍微過期 數據可以接受的情況進一步減少等待時間。當一個主鍵被刪除的時候,對應的值轉移到一個保存最近刪除項的數據結構中,在被清楚之前將會存活很短的時間。一個 get請求可能返回一個租約,或者是一個標記為已過時的數據。應用可以使用過時的數據繼續轉發處理,而不需要等待從數據庫讀取的最新數據。經驗告訴我們因 為緩存數據趨向於單調遞增的數據庫快照,大部分應用可以在對數據不做改變的情況下使用過時數據。
[譯者注:工作集定義為在一個特定的時間段內一個進程所需要的內存]
3.2.3 池內的復制(replication)
在某些池內,我們使用復制(replication)來改善延遲和memcached服務器的效率。當(1)應用常規地同時讀取很多主鍵,(2)整個數據 集集合可以放到一或兩個memcached服務器中,(3)請求率非常高,超出了單台服務器的處理能力的時候,我們選擇復制池內的一類主鍵。
比起進一步劃分主鍵空間,我們更傾向於在實例內進行復制。考慮一個包含100個數據項的memcached服務器,具有對每秒500K請求進行處理的能 力。每一個請求查找100個主鍵。在memcached中每個請求查詢100個主鍵與查詢1個主鍵之間開銷的差值是很小的。為了擴展系統來處理1M請求/ 秒,假如我們增加了第二台服務器,將主鍵平均分配到兩台服務器上。現在客戶端需要將每個包含100個主鍵的請求分割為兩個並行的包含50個主鍵的請求。結 果兩台服務器都仍然不得不處理每秒1M的請求。然後,如果我們復制所以100個主鍵到兩台服務器,一個包含100個主鍵的客戶端請求可以被發送到任意副本 (replica)。這樣將每台服務器的負載降到了每秒500K個請求。每一個客戶端依據自己的IP地址來選擇副本。這種方法需要向所以的副本分發失效消 息來維護一致性。
3.3 故障處理
無法從memcache中讀取數據將會導致後端服務負載激增,這會導致進一步的連鎖故障。有兩個尺度的故障我們必須解決:(1)由於網絡或服務器故障,少 量的主機無法接入,(2)影響到集群內相當大比例服務器的廣泛停機事件。如果整個的集群不得不離線,我們轉移用戶的web請求到別的集群,這樣將會有效地 遷移memcache所有的負載。
對於小范圍的停機,我們依賴一個自動化修復系統[3]。這些操作不是即時的,需要花費幾分鐘。這麼長的持續時間足夠引發前面提到的連鎖故障,因此我們引入 了一個機制進一步將後端服務從故障中隔離開來。我們專門准備了少量稱作Gutter的機器來接管少量故障服務器的責任。在一個集群中,Gutter的數量 大約為memcached服務器的1%。
當memcached客戶端對它的get請求收不到回應的時候,這個客戶端就假設服務器已經發生故障了,然後向特定的Gutter池再次發送請求。如果第 二個請求沒有命中,那麼客戶端將會在查詢數據庫之後將適當的鍵-值對插入Gutter機器。在Gutter中的條目會很快過期以避免Gutter失效。 Gutter以提供稍微過時的數據為代價來限制後端服務的負載。
注意,這樣的設計與客戶端在剩下的memcached服務器重新分配主鍵的方法不同。由於頻繁存取的主鍵分布不均勻,那樣的方法會有連鎖故障的風險。例 如,一個單獨的主鍵占服務器請求的20%。承擔這個頻繁存取的主鍵的服務器也會過載。通過將負載分流到閒置的服務器,我們減少了這樣的風險。
通常來說,每個失敗的請求都會導致對後端儲存的一次存取,潛在地將會使後端過載。使用Gutter存儲這些結果,很大部分失敗被轉移到對gutter池的 存取,因此減少了後端存儲的負載。在實踐中,這個系統每天減少99%的客戶端可見的失敗率,將10%-25%的失敗轉化為緩存命中。如果一台 memcached服務器整個發生故障,在4分鐘之內,gutter池的命中率將會普遍增加到35%,經常會接近50%。因此對於由於故障或者小范圍網絡 事故造成的一些memcached服務器不可達的情況,Gutter將會保護後端存儲免於流量激增。
4 Region之內:復制(Replication)
隨著需求的增長,購買更多的web服務器和memcached服務器來擴展集群是誘惑人的。但是幼稚地擴展系統並不能解決所有問題。隨著更多的web服務 器加入來處理增長的用戶流量,高請求率的數據項只會變的更流行。隨著memcached服務器的增加,Incast擁塞也會變的更嚴重。因此我們將web 服務器和memcached服務器分割為多個前端集群。這些集群與包含數據庫的存儲集群一起統稱為region。region架構同樣也考慮到更小的故障 域和易控制的網絡配置。我們用數據的復制來換取更獨立的故障域、易控制的網絡配置和incast擁塞的減少。
這一章分析了分享同一個存儲集群的多個前端集群的影響。特別地,我們說明了允許數據跨集群復制的影響,以及不允許復制潛在的內存效率。
4.1 region內的失效
在region中,存儲集群保存數據的權威版本,為了滿足用戶的需求就需要將數據復制到前端集群。存儲集群負責使緩存數據失效來保持前端集群與權威版本的 一致性。做為一個優化,當web服務器修改數據後,它也會向所在的集群發送失效命令,提供針對單用戶請求的讀後寫語義,這樣可以減少本機緩存的存在時間。
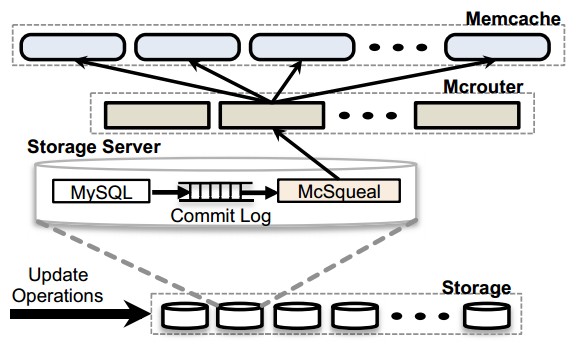
圖6:失效流水線 展示那些需要經過守護進程(mcsqueal)刪除的主鍵
修改權威數據的SQL語句被改進為包含事務提交後需要使失效的對應的memcache主鍵[7]。我們在所有的數據庫上部署了失效守護進程(稱作 mcsqueal)。每個守護進程檢查數據庫提交的SQL語句,提取任意的刪除命令,並且將刪除命令廣播到region內所有的前端集群。圖6展示了這個 方法。我們發現大部分發出的失效命令並不會造成刪除數據的操作,實際上,所有發出的刪除命令只有4%導致實際的緩存數據失效。

表1: 集群復制或region復制的決定性因素
[譯者注:動態重啟(rolling restart)是賽車比賽中的一個術語。看看F1比賽就會有個直觀的概念,比賽的時候經常會出現安全車領著賽車跑兩圈,當安全車離開後出現綠旗,這就是一次rolling start]
4.2 Region池
每個集群依照混合的用戶請求獨立地緩存數據。如果用戶請求被隨機的路由到所有可獲得的前端集群,那麼所有前端服務器緩存的數據將會大致上一樣。這就允許我 們離線維護某個集群,而不會導致緩存命中率下降。過度復制數據會使內存沒有效率,特別是對很大的、很少存取的數據項。通過使多個前端集群分享同一個 memcached服務器集合,我們就可以減少副本的數量。我們稱此為region池。
跨集群邊界通信會導致更大的延遲。另外,我們的集群間可獲得帶寬比集群內的少40%。復制用更多的memcached服務器換取更少的集群間帶寬,低延遲 和更好的容錯。對於某一些數據,放棄副本的好處,每個region一個拷貝,從成本上來說更有效率。擴展memcache的一個主要挑戰是決定某主鍵是應 該跨前端集群復制,還是每個region一個副本。當region池發生故障時,Gutter也會被使用。
表1總結了我們應用中具有巨大價值的兩類項目。我們將B類型的數據移到region池,對於A類型的不做改變。注意,客戶端存取B類型數據的頻率比A類型 數據低一個數量級。B類型數據的低存取率使它成為region池的主要候選者,因為這樣的數據不會對集群間帶寬造成不利的影響。B類型數據也會占有每個集 群wildcard池25%的空間,所以區域化提供了顯著的存儲效率。然而在A類型的數據項的大小是B類型的兩倍,而且存取更頻繁,所以從region的 角度考慮,不會將它們放在region池中。目前將數據遷移到region池的依據是基於存取率、數據大小和存取用戶數的人工的啟發式方法。
4.3 冷集群熱身
由於存在的集群發生故障或者進行定期的維護,我們增加新的集群上線,此時緩存命中率會很低,這樣會削弱隔離後端服務的能力。一個稱作冷集群熱身(Cold Cluster Warmup)的系統可以緩和這種情況,這個系統使“冷集群”(也就是具有空緩存的前端集群)中的客戶端從“熱集群”(也就是具有正常緩存命中率的集群) 中檢索數據而不是從持久化存儲。這利用到了前面提到的跨前端集群的數據復制。使用這個系統可以使冷集群在幾個小時恢復到滿負載工作能力而不是幾天。
必須注意避免由於競爭條件引發的不一致。例如,如果冷集群中的一個客戶端對數據庫做了更新,另外一個客戶端在熱集群收到失效命令之前檢索到過時數據,這個 數據項在冷集群中將會不一致。memcached的刪除命令支持非零的拖延時間,也就是在指定的拖延時間內拒絕添加操作。默認情況下,冷集群中所有的刪除 命令都有兩秒鐘的拖延時間。當在冷集群中發生緩存不命中時,客戶端向熱集群重新發送請求,然後將結果添加到冷集群中。如果添加失敗就表明數據庫中有更新的 數據,因此客戶端將會重新從數據庫讀數據。刪除命令延遲兩秒鐘以上在理論上來說也是有可能的,但是對於大部分的情況並不會超過兩秒鐘。冷集群熱身運營上的 效益遠遠超過少數緩存不一致所帶來的成本。一旦冷集群的命中率趨於穩定,我們就將冷集群熱身系統關掉,同時效益也就減少了。
將數據中心分布到廣泛的地理位置具有很多優勢。第一,將web服務器靠近終端用戶可以極大地較少延遲。第二,地理位置多元化可以緩解自然災害和大規模電力 故障的影響。第三,新的位置可以提供更便宜的電力和其它經濟上的誘因。我們通過部署多個region來獲得這些優勢。每個region包含一個存儲集群和 多個前端集群。我們指定一個region持有主數據庫,別的region包含只讀的副本;我們依賴MySQL的復制機制來保持副本數據庫與主數據庫的同 步。基於這樣的設計,web服務器無論訪問本地memcached服務器還是本地數據庫副本的延遲都很低。當擴展到多region的時候,維護 memcache和持久化存儲的數據一致性成了主要的技術挑戰。這些挑戰源於一個問題:副本數據庫可能滯後於主數據庫。
在一致性和性能平衡的廣泛范圍上,我們的系統僅僅表示一個點。一致性模型已經演進了很多年來滿足站點擴展的需求。在實踐上一致性模型是可以構建的,並且不 會犧牲高性能的需求。系統管理的大容量數據隱含著任何增加網絡和存儲需求的細小改動都有重大的成本。大部分提供嚴格語義的想法都很少走出設計階段,因為它 們實在是過分的昂貴。與專門針對存在的用例而定制的系統不同,memcache和Facebook是一起開發的。這就允許應用工程師和系統工程師可以一起 工作來設計一個模型,這個模型對於應用工程師來說是易於理解的、高效的,而且足夠的簡單來實現可靠的擴展。我們提供了盡力而為的最終一致性,但是強調性能 和可用性。因此在實踐上這個系統工作的非常好,而且我們找到了一個可以接受的平衡點。
從主region寫:前面我們提到在我們的系統中是通過存儲集群的守護進程來實現數據失效的,這樣的設計對多 region架構的設計具有重要的影響。特別的,這樣的設計可以避免一個競爭情況,也就是在數據從主region復制過來之前失效命令先到達了。考慮一下 這種情況,主region中的一個web服務器已經完成對數據庫的修改,尋求使現在過時的數據失效。在主region中發送失效命令是安全的。然而,讓副 本region中的web服務器發送失效命令可能是不成熟的,因為對主數據庫的改動可能還沒有傳播到副本數據庫。接下來對副本region的數據查詢將會 與數據庫復制產生競爭,因此增加了將過時數據設置到memcache中的概率。歷史上,在擴展到多個region之後,我們實現了mcsqueal。
從非主region寫:現在考慮當復制滯後非常大的時候,用戶從非主region更新數據。如果他最近的改動丟失了,那麼下一個請求將會導致混亂。之後當復制流完成之後才允許從副本數據庫讀取數據並緩存。如果沒有這個保障,後續請求將會導致副本中的過時數據被讀取並且緩存。
我們使用遠程標記(remote marker)機制來最小化讀取過時數據的概率。出現標記就表明本地副本數據庫中的數據可能是過時的,所以查詢應該重定向到主region。當web服務器想要更新主鍵為k的數據,那麼服務器(1)在region中設置遠程標記 r k,(2)向主數據庫執行寫操作,並且在SQL語句中嵌入應該失效的k和 r k,(3)在本集群刪除k。對於主鍵k的後續請求,web服務器找不到緩存數據,然後就檢查 r k是否存在,如果存在就將請求定向到主region,否則定向到本地region。在這種情況下,我們用緩存不命中時附加的延遲來換取讀取過時數據概率的下降。
我們通過使用region池來實現遠程標記。注意,當對於同一個主鍵並發修改的時候,一個操作可能刪除遠程標記,而這個標記應該為另外一個正在執行的操作 保留,如果出現這種情況,我們的機制就可能返回過時的信息。有一點是需要特別說明的,我們對遠程標記memcache的使用以一種微妙的方式違反了緩存結 果。做為緩存,刪除或移除主鍵都是安全的;它可能會引起更多的數據庫負載,但是不會削弱一致性。相反,遠程標記的出現可以幫助區分是否非主數據庫擁有過時 數據。在實踐上,我們發現移除遠程標記和並發修改的情況都很少。
運行上的考慮:跨region通信是非常耗時的,因為數據不得不穿過很大的地理距離(比如穿過合眾國大陸)。通過分享數據庫復制刪除流的通信信道,我們在低帶寬連接情況下獲得了網絡效率。
上述4.1章提到的管理刪除的系統也部署在了副本region,通過副本數據庫廣播刪除命令到memcached服務器。當下流組件沒有反應時,數據庫和 mcrouter暫存刪除命令。任何組件的故障和延遲都會導致讀取過時數據概率的增加。一旦下流組件重新可獲得了,暫存的刪除命令將會重新發送。當發現問 題時,代替的方案是讓集群下線或者是使前端集群的數據失效。這些方法比起所獲得的工作負荷上的好處將會導致更多的混亂。
多對多的通信模式隱含著單獨的服務器將會成為集群的瓶頸。這章將會講述性能調優和memcached內存效率的提高,這有利於集群更好的擴展。提升單個服務器緩存的性能是一個活躍的研究領域[9,10,28,25]。
我們開始使用具有固定大小哈希表的單線程memcached。第一批主要的優化是:(1)允許哈希表自動擴展來避免查找時間漂移到O(n),(2)通過一 個全局鎖來保護多數據結構使得服務器多線程化,(3)賦予每個線程獨立的UDP端口來減少發送副本和稍後傳播中斷處理開銷的爭用。前兩個優化都貢獻給了開 源社區。下述章節將會探索還沒在開源版本出現的進一步優化。
我們的實驗主機擁有一顆2.67GHz(12核、12超線程)的Intel Xeon CPU(X5650),一個Intel 82574L千兆以太網控制器和12GB內存。生產服務器具有更多的內存。更多的細節之前已經公開過[4]。性能測試設備包含15個生成memcache 流量的客戶端和一台具有24線程的memcached服務器。客戶端和服務器放在同一個機架,之間通過千兆以太網連接。這些測試測量兩分鐘持續負載 memcached反應的延遲。
[譯者注:X5650好像是6核的]
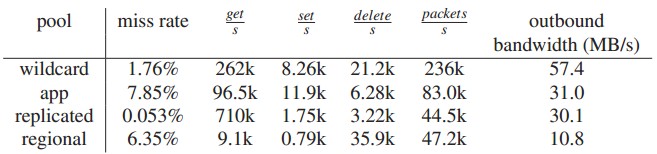
獲取的性能:我們首先研究將原有的多線程單鎖的實現 替換為細粒度鎖的效益。在發送包含10個主鍵的memcached請求的之前,我們預先填充了擁有32byte值的緩存數據,然後我們測量命中的性能。圖 7展示了對不同版本的memcached持續的亞毫秒級平均返回時間的最大請求率。第一組柱狀圖是實現細粒度鎖之前的memcached,第二組是我們當 前的memcached,最後一組是開源版本1.4.10,這個版本獨立實現了一個我們的鎖策略的更粗粒度的版本。
使用細粒度的鎖使得請求命中的峰值從每秒600K到達了1.8M提升了3倍。不命中的性能也從每秒2.7M提升到了4.5M。因為返回值需要構建和傳輸,而不命中對於整個多請求僅需要一個表明所有主鍵不命中的靜態回應(END),所以命中的情況更耗時。
我們也研究了使用UDP代替TCP的性能影響。圖8展示了對於單主鍵獲取和10個主鍵獲取平均持續延遲小於一毫秒的請求峰值。我們發現UDP實現的性能在單主鍵獲取情況下超出TCP實現13%,在10主鍵獲取的情況下超出8%。
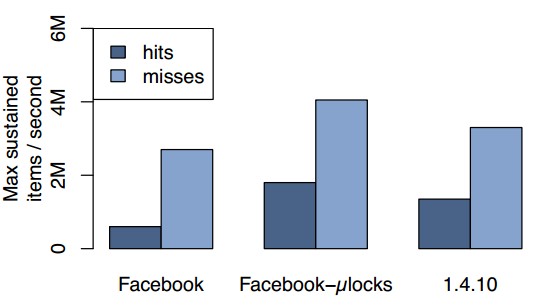
圖7:對不同memcached版本多獲取命中和不命中的性能比較
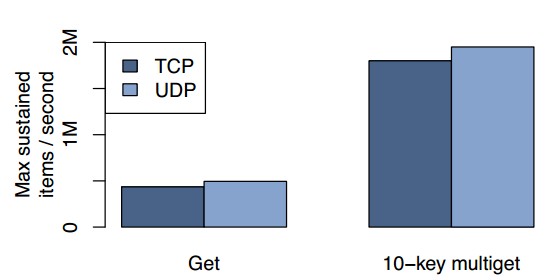
圖8:對TCP和UDP單主鍵請求和10主鍵請求獲取命中的性能比較
因為多主鍵獲取在單個請求比單主鍵獲取多打包了很多數據,所以它們使用了更少的包完成了同樣的事情。圖8展示了10個主鍵獲取比單主鍵獲取有接近4倍的性能提升。
memcached使用一個slab分配器來管理內存。這個分配器將內存組織為slab類,每類包含預分配的均勻大小的內存塊。memcached將數據 項存儲到可以適應數據項元數據、鍵和值大小的最小可能性的slab類。slab類從64byte開始,以1.07為因子指數性增加到1MB,以4byte 對齊3。每個slab類維護一個可獲得內存塊的空閒列表,當它的空閒列表是空的,那麼就從1MB slab中請求更多內存。一旦memcached服務器再也不能分配空閒內存,通過移除slab類中最近最少使用(LRU)的數據項來存儲新的數據項。當 工作負載改變時,原有分配給每個slab類的內存可能不再足夠,這樣將會導致低命中率。
================= =======================
3 對頁取數據的量位於第95百分位的是1740個數據項。這個擴展的因子確保我們同時擁有64byte和128byte,這樣更有利於利用硬件緩存線。
我們實現了一個適應性的分配器,這個分配器將會周期性的重新平衡slab分配來適應當前的工作負載。如果slab類正在移除數據項,而且如果下一個將要被 移除的數據項比其它slab類中的最近最少使用的數據項的最近使用時間至少近20%,那麼就說明這個slab類需要更多內存。如果找到了一個這樣的 slab類,那麼就將存儲最近最少使用數據項的slab釋放,然後轉移到needy類。注意,開源社區已經獨立實現了一個類似的平衡跨slab類移除率的 分配器,然而我們的算法關注平衡所有類中最久數據項的時長。平衡時長比調整移除率對整台服務器單個全局最近最少使用(LRU)移除策略提供了更好的近似, 而且調整移除率深受接入模式的影響。
因為memcached支持過期時間,條目在它們過期之後仍可以駐留在內存中。 當條目被請求時或者當它們到達LRU的尾端時,Memcached會通過檢查過期時間來延時剔除這些條目。 盡管在一般情況下很有效,但是這種模式允許那 些偶爾活躍一下的短期鍵值占據內存空間,直到它們到達LRU的尾部。
所以我們引入一種混合模式,對多數鍵值使用延時剔除,而對過期的短期鍵值則立即剔除。我們根據短期條目的過期時間把它們放入一個由鏈接表構成的環形緩存區 (花費幾秒編入索引直到過期) – 我們稱之為臨時條目緩存區。每一秒鐘,該緩存的頭部數據格裡的所有條目都會被剔除,然後頭部向前移動一格。當我們給一個頻繁使用的鍵值集合(它們對應條目 的壽命很短)設置一個短超期時間後, 該鍵值集合使用的memcache緩沖池的比例從6%下降到0.3%,而沒有影響到命中率。
6.4 軟件升級
升級、bug修復、臨時診斷或性能測試都需要頻繁的軟件變更。一個memcached服務器能夠在幾小時內達到 90% 的命中率峰值。接下來,可能會耗費12小時來進行memcached服務器升級,這將要求我們謹慎管理數據庫負載。我們修改了memcached,使用 System V 共享內存區來存儲緩存值和主數據結構,以便在軟件升級過程中數據仍能夠保持可用,進而最小化損失。
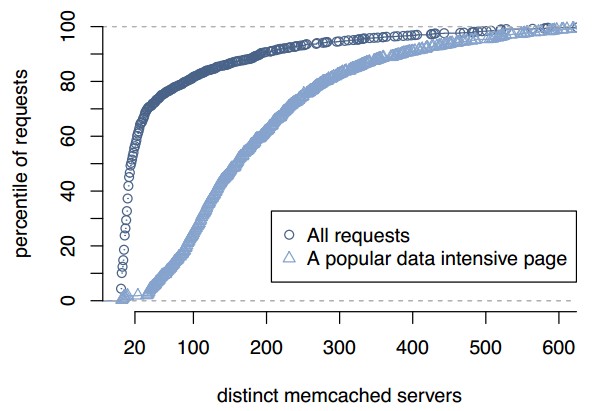
圖 9: 不同數量memcached服務器的訪問數累積分布圖
現在我們用從生產環境中運行服務器上所獲得的數據來描述memcache的負載。
我們收集了小比例用戶請求的所有memcache操作,然後討論了扇出(fanout)、響應大小和我們工作負載的延遲特征。
扇出:圖 9展示了當web服務器回應一個頁面請求時需要聯系的memcahced服務器數量的分布。由圖可見,56%的頁面請求聯系少於20台memcached 服務器。按照傳輸量來說,用戶請求傾向於請求小數量的緩存數據。然而這個分布存在一個長尾。這張圖也展示了對於流行頁面的請求分布,這樣的頁面可以更好的 展示出多對多的通信模式。大部分這樣的請求將會接入超過100台獨立的服務器;接入幾百台memcached服務器也不是少數。
響應大小:圖 10展示了對memcache請求的響應大小。中位數(135byte)與平均數(954byte)之間的差值隱含著緩存項的大小存在很大差異。另外,在 近似200byte和600byte處有三個不同的峰值。大的數據項傾向於存儲數據列表,而小的數據項傾向於存儲單個內容塊。
延遲:我們測量從memcache請求數據的往返延遲, 這個延遲包含了請求路由和接收回復的成本、網絡傳輸時間和反序列化和解壓縮的成本。通過7天的統計,請求延遲的中位數是333微秒,位於第75百分位的是 475微秒,位於第95百分位的是1.135毫秒。空閒web服務器端到端延遲的中位數是178微秒,位於第75百分位的是219微秒,位於第95百分位 的是374微秒。在第95百分位上延遲的巨大差異是由處理數據量大的回應和等待可運行線程調度引起的,這些在3.1章已經討論過了。
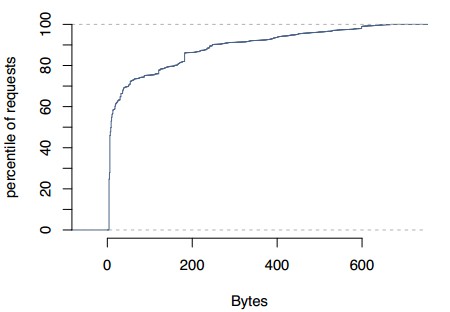
圖10:讀取數據大小的累積分布
現在我們討論四個memcache池的測量。這些池分別是wildcard(默認池),app(專門設定給特定應用的池),給存取頻繁的數據的 replicated pool,給很少存取的數據的regional pool。在每個池中,我們每四分鐘收集一次平均的統計,表2展示了一個月的統計周期的最大平均值。這些數據近似於那些池的峰值負載。這張表顯示了對於不 同的池,get、set和delete操作的頻率存在很大差異。表3展示了每個池響應大小的分布。這些不同的特征激發了我們分隔不同工作負載的欲望。
就像在3.2.3章討論過的那樣,我們在池內復制數據,使用批處理的優勢來處理高請求率。我們觀察到,replicated pool具有最高的get操作率(差不多是第二高的2.7倍),最高的字節比包的比率,盡管該池有最小的數據項大小。這些觀察數據與我們設計的期望一致, 我們就是想利用復制和批處理來實現更好的性能。在app池,更高的數據抖動自然而然將會導致更高的不命中率。這個池傾向於將數據保存幾個小時,然後就會被 新的數據踢出。在regional pool中的數據傾向於是較大的而且不頻繁被存取的,就像表中的的請求率和數據大小分布展示的那樣。
我們發現,在確定暴露過期數據的概率上,失效的及時性是一個關鍵因素。為了監控該生命值,我們從百萬次刪除操作中取樣一次並記錄刪除命令發出的時間。隨 後,我們定期地為該樣本查詢所有前端集群中memcache的內容,如果刪除命令將一個字段設定為無效時,該字段仍然緩存,則記錄一個錯誤。
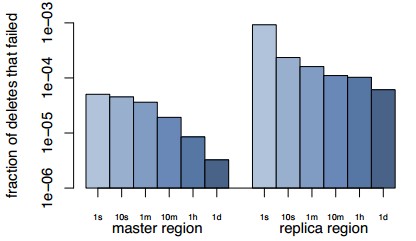
圖11:刪除的管線的延時
在圖11中,我們使用這種監控機制來統計30天的失效延遲。我們將數據分為兩組:(1)刪除操作由主region中的web服務器發起,並被發送到主 region中的一個memcached服務器,(2)刪除操作從副本region發起,並且發送到另外一個副本region。由統計數據可以見,當參數 操作的發起地和目的地都是在主region的時候,成功率非常的高,一秒鐘內就可以達到四個九的可靠性,一小時之後就可以達到五個九。當刪除操作的發起地 和目的地都不在主region的時候,一秒鐘內的可靠性下降到了三個九,十分鐘內才達到四個九。按照我們的經驗,當幾秒鐘之後失效操作不成功,最可能的原 因是第一次嘗試失敗,接下來的重試將會解決這個問題。
一些其他的大型網站已經意識到key-value存儲的應用。DeCandia 等[12]構建了高可用的key-value存儲系統(Dynamo),已經亞馬遜網站應用服務中大量使用。相比較,Dynamo主要著眼於優化高負荷狀 況下的寫操作,而我們系統的負荷主要是大量的讀操作。類似的有,LinkedIn 使用Voldemort[5],由Dynamo衍生而出。其他被大量使用的key-value存儲方案包括Github,digg和Blizzard使用 Redis[6];Twitter[33]和Zynga使用memcahed。Lakshmanet等[1]開發了Cassandra,一個基於模式的分 布式key-value數據庫。然而我們更趨向於使用和擴展memcached,主要是由於其簡單的設計。
我們的工作是擴展memecached使其在分布式數據架構下工作。Gribble等[19]構建了一個早期版本的key-value存儲系統用於 Internet擴展服務。Ousterhout等[29]也構建了一個大規模內存key-value存儲系統。與這些方案不同,memcache不保證 持久性。我們利用其它的系統來解決數據存儲的持久性問題。
表2:各類型的平均超過7天的memcache程序池流量圖

表 3: 各類型程序池關鍵詞大小分布(k)
Ports等[31]提供了一個用於管理事任務數據庫查詢結果緩存的類庫。我們需要的是一個更靈活的緩存措略。我們利用最近和過期讀優先措略用來研究高 性能系統下緩存一致性和讀操作。Ghandeharizadeh和Yap等研究也提出了一個公式,解決基於時間標記而不是確定的版本號過期集合的問題。
雖然軟路由易於定制和編程,但是相比較硬路由其效率更低。Dobresuet等[13]利用多處理器、多存儲控制器,多隊列網絡接口和批處理的方式在通用服務器上研究了這些問題。利用這些技術實現微路由來保持進一步的工作。Twitter也獨立開發了一個類似微路由的memcache代理[32]。
在Coda[35]中,Satyanarayanan等展示了如何把由於不連貫的操作導致的數據集分歧恢復一致。Glendenninget等[17] 利用槓桿作用Paxos公式[24]和加權因子[16]構建了Scatter,一個線性語義攪動的非貢獻哈希表。
TAO[37]是facebook 的另一個嚴重依賴緩存的系統,主要用戶保證大數據量查詢時能保持低延遲。TAO和memcache有兩方面的重大不同。(1),TAO由一個圖形模型實現,在模型中每一個節點由一個固定長度的持久標識符(64位整數)來標識。(2)TAO 有一個編碼規范,把它的圖形模型映射到持久存儲,並且對持久層負責。其他大量的組件,比如我們的客戶類庫和微路由,都可以在兩個系統中通用。