


Slave 端:
REDIS_REPL_NONE
REDIS_REPL_CONNECT
REDIS_REPL_CONNECTED
Master端:
REDIS_REPL_WAIT_BGSAVE_START
REDIS_REPL_WAIT_BGSAVE_END
REDIS_REPL_SEND_BULK
REDIS_REPL_ONLINE
整個狀態機流程過程如下:
整個復制過程完成,流程如下圖所示:
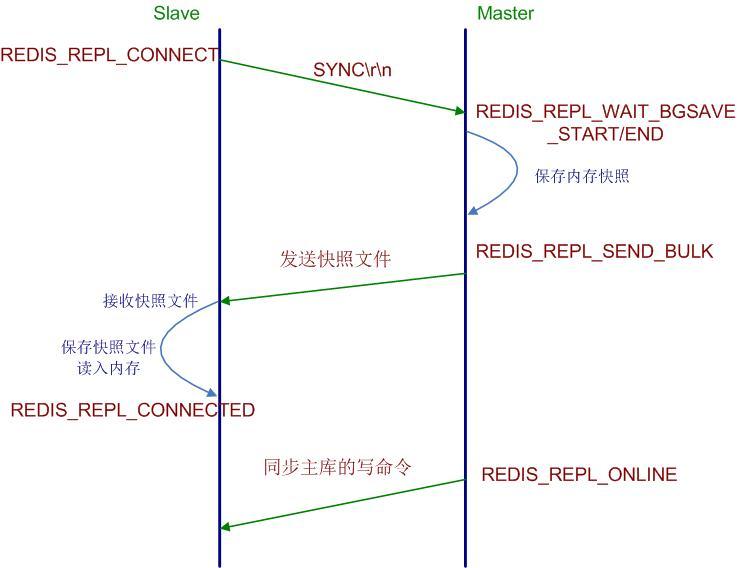
從上面的流程可以看出,Slave從庫在連接Master主庫時,Master會進行內存快照,然後把整個快照文件發給Slave,也就是沒有象MySQL那樣有復制位置的概念,即無增量復制,這會給整個集群搭建帶來非常多的問題。
比如一台線上正在運行的Master主庫配置了一台從庫進行簡單讀寫分離,這時Slave由於網絡或者其它原因與Master斷開了連接,那麼當 Slave進行重新連接時,需要重新獲取整個Master的內存快照,Slave所有數據跟著全部清除,然後重新建立整個內存表,一方面Slave恢復的 時間會非常慢,另一方面也會給主庫帶來壓力。
所以基於上述原因,如果你的Redis集群需要主從復制,那麼最好事先配置好所有的從庫,避免中途再去增加從庫。
在我們分析過了Redis的復制與持久化功能後,我們不難得出一個結論,實際上Redis目前發布的版本還都是一個單機版的思路,主要的問題集中在,持久化方式不夠成熟,復制機制存在比較大的缺陷,這時我們又開始重新思考Redis的定位:Cache還是Storage?
如果作為Cache的話,似乎除了有些非常特殊的業務場景,必須要使用Redis的某種數據結構之外,我們使用Memcached可能更合適,畢竟Memcached無論客戶端包和服務器本身更久經考驗。
如果是作為存儲Storage的話,我們面臨的最大的問題是無論是持久化還是復制都沒有辦法解決Redis單點問題,即一台Redis掛掉了,沒有太好的辦法能夠快速的恢復,通常幾十G的持久化數據,Redis重啟加載需要幾個小時的時間,而復制又有缺陷,如何解決呢?
既然Redis的復制功能有缺陷,那麼我們不妨放棄Redis本身提供的復制功能,我們可以采用主動復制的方式來搭建我們的集群環境。
所謂主動復制是指由業務端或者通過代理中間件對Redis存儲的數據進行雙寫或多寫,通過數據的多份存儲來達到與復制相同的目的,主動復制不僅限於 用在Redis集群上,目前很多公司采用主動復制的技術來解決MySQL主從之間復制的延遲問題,比如Twitter還專門開發了用於復制和分區的中間件 gizzard(https://github.com/twitter/gizzard) 。
主動復制雖然解決了被動復制的延遲問題,但也帶來了新的問題,就是數據的一致性問題,數據寫2次或多次,如何保證多份數據的一致性呢?如果你的應用 對數據一致性要求不高,允許最終一致性的話,那麼通常簡單的解決方案是可以通過時間戳或者vector clock等方式,讓客戶端同時取到多份數據並進行校驗,如果你的應用對數據一致性要求非常高,那麼就需要引入一些復雜的一致性算法比如Paxos來保證 數據的一致性,但是寫入性能也會相應下降很多。
通過主動復制,數據多份存儲我們也就不再擔心Redis單點故障的問題了,如果一組Redis集群掛掉,我們可以讓業務快速切換到另一組Redis上,降低業務風險。
通過主動復制我們解決了Redis單點故障問題,那麼還有一個重要的問題需要解決:容量規劃與在線擴容問題。
我們前面分析過Redis的適用場景是全部數據存儲在內存中,而內存容量有限,那麼首先需要根據業務數據量進行初步的容量規劃,比如你的業務數據需 要100G存儲空間,假設服務器內存是48G,那麼根據上一篇我們討論的Redis磁盤IO的問題,我們大約需要3~4台服務器來存儲。這個實際是對現有 業務情況所做的一個容量規劃,假如業務增長很快,很快就會發現當前的容量已經不夠了,Redis裡面存儲的數據很快就會超過物理內存大小,那麼如何進行 Redis的在線擴容呢?
Redis的作者提出了一種叫做presharding的方案來解決動態擴容和數據分區的問題,實際就是在同一台機器上部署多個Redis實例的方式,當容量不夠時將多個實例拆分到不同的機器上,這樣實際就達到了擴容的效果。
拆分過程如下:
以上拆分流程是Redis作者提出的一個平滑遷移的過程,不過該拆分方法還是很依賴Redis本身的復制功能的,如果主庫快照數據文件過大,這個復制的過程也會很久,同時會給主庫帶來壓力。所以做這個拆分的過程最好選擇為業務訪問低峰時段進行。
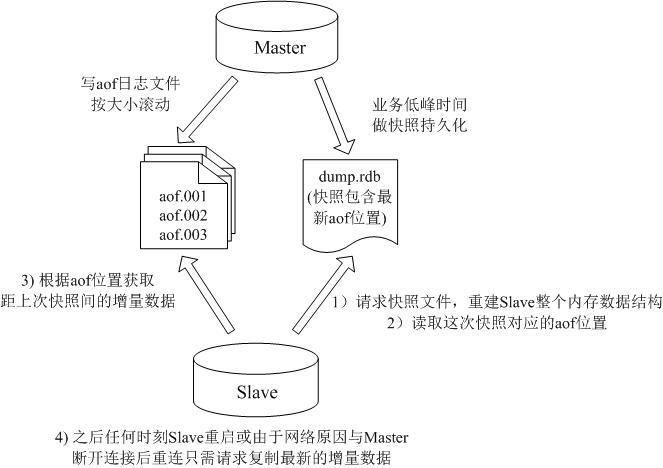
我們線上的系統使用了我們自己改進版的Redis,主要解決了Redis沒有增量復制的缺陷,能夠完成類似Mysql Binlog那樣可以通過從庫請求日志位置進行增量復制。
我們的持久化方案是首先寫Redis的AOF文件,並對這個AOF文件按文件大小進行自動分割滾動,同時關閉Redis的Rewrite命令,然後 會在業務低峰時間進行內存快照存儲,並把當前的AOF文件位置一起寫入到快照文件中,這樣我們可以使快照文件與AOF文件的位置保持一致性,這樣我們得到 了系統某一時刻的內存快照,並且同時也能知道這一時刻對應的AOF文件的位置,那麼當從庫發送同步命令時,我們首先會把快照文件發送給從庫,然後從庫會取 出該快照文件中存儲的AOF文件位置,並將該位置發給主庫,主庫會隨後發送該位置之後的所有命令,以後的復制就都是這個位置之後的增量信息了。
目前大部分互聯網公司使用MySQL作為數據的主要持久化存儲,那麼如何讓Redis與MySQL很好的結合在一起呢?我們主要使用了一種基於MySQL作為主庫,Redis作為高速數據查詢從庫的異構讀寫分離的方案。
為此我們專門開發了自己的MySQL復制工具,可以方便的實時同步MySQL中的數據到Redis上。
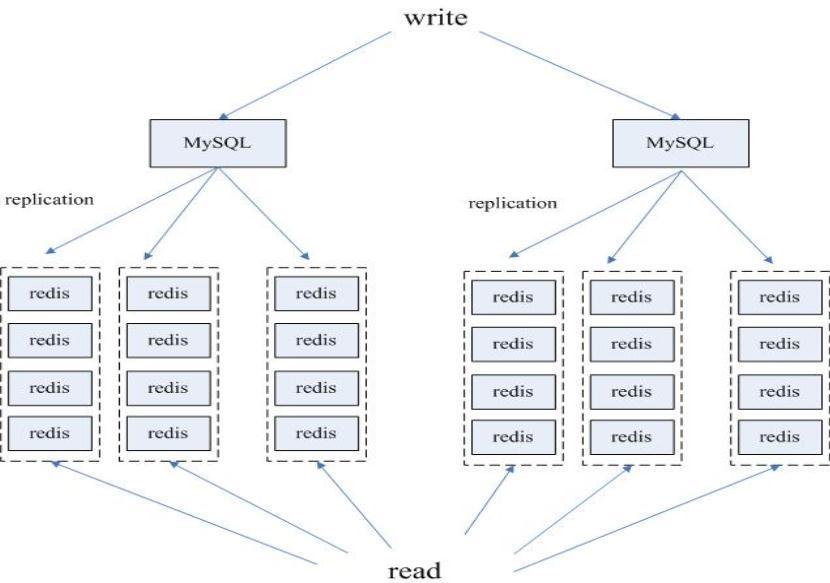
(MySQL-Redis 異構讀寫分離)
總結: