1. 下載ubuntu14.04 i386
地址:http://old-releases.ubuntu.com/releases/14.04.1/
2. 安裝JDK
地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2.1.解壓安裝
我們把JDK安裝到這個路徑:/jdk 或/usr/lib/jvm
如果沒有這個目錄(第一次當然沒有),我們就新建一個目錄
sudo mkdir /jdk
建立好了以後,我們來到剛才下載好的壓縮包的目錄,解壓到我們剛才新建的文件夾裡面去,並且修改好名字方便我們管理
sudo tar -zxvf jdk-8u91-linux-i586.gz -C /jdk
// sudo mv jdk1.7.0_05/jdk7
2.2.配置環境變量
Vim ~/.bashrc
在打開的文件的末尾添加
exportJAVA_HOME=/jdk1.8.0_91
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
exportPATH=${JAVA_HOME}/bin:$PATH
保存退出,然後輸入下面的命令來使之生效
source ~/.bashrc
2.3配置環境變量
sudo gedit /etc/profile
exportJAVA_HOME=/jdk1.8.0_91
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
exportPATH=${JAVA_HOME}/bin:$PATH
3.在Ubuntu下創建hadoop用戶組和用戶
1.創建hadoop用戶組;
1.sudoaddgrouphadoop
2.創建hadoop用戶;
1.sudoadduser-ingrouphadoophadoop
3.給hadoop用戶添加權限,打開/etc/sudoers文件;
1.sudogedit/etc/sudoers
在root ALL=(ALL:ALL)ALL下添加hadoopALL=(ALL:ALL) ALL.
4.1 sudoapt-getinstallsshopenssh-server
4.2 建立ssh無密碼登錄本機
切換到hadoop用戶,執行以下命令:
1.su-hadoop
ssh生成密鑰有rsa和dsa兩種生成方式,默認情況下采用rsa方式。
1.創建ssh-key,,這裡我們采用rsa方式;
1.ssh-keygen-trsa-P""(注:回車後會在~/.ssh/下生成兩個文件:id_rsa和id_rsa.pub這兩個文件是成對出現的)
2.進入~/.ssh/目錄下,將id_rsa.pub追加到authorized_keys授權文件中,開始是沒有authorized_keys文件的;
1.cd~/.ssh
2.catid_rsa.pub>>authorized_keys(完成後就可以無密碼登錄本機了。)
3.登錄localhost;
1.sshlocalhost
4.執行退出命令;
1.exit
5.安裝Hadoop
sudo tar -xzvf hadoop-2.6.0.tar.gz-C /usr/local/hadoop
cd /usr/local/ sudo mv ./hadoop-2.6.0/ ./hadoop # 將文件夾名改為hadoop sudo chown -R hadoop ./hadoopHadoop 解壓後即可使用。輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本信息:
cd /usr/local/hadoop ./bin/hadoop version6.嘗試運行自帶例子
cd /usr/local/hadoop mkdir ./input cp ./etc/hadoop/*.xml ./input # 將配置文件作為輸入文件 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' cat ./output/* # 查看運行結果 刪除目錄 sudo rm –r output7.Hadoop偽分布式配置
Hadoop 可以在單節點上以偽分布式的方式運行,Hadoop 進程以分離的 Java 進程來運行,節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的文件。
Hadoop 的配置文件位於 /usr/local/hadoop/etc/hadoop/ 中,偽分布式需要修改2個配置文件core-site.xml和hdfs-site.xml。Hadoop的配置文件是 xml 格式,每個配置以聲明property 的 name 和 value 的方式來實現。
修改配置文件core-site.xml(通過 gedit 編輯會比較方便:gedit./etc/hadoop/core-site.xml),將當中的
修改為下面配置:
1.
2.
3.hadoop.tmp.dir
4.file:/usr/local/hadoop/tmp
5.Abase for other temporary directories.
6.
7.
8.fs.defaultFS
9.hdfs://localhost:9000
10.
11.
同樣的,修改配置文件hdfs-site.xml:
1.
2.
3.dfs.replication
4.1
5.
6.
7.dfs.namenode.name.dir
8.file:/usr/local/hadoop/tmp/dfs/name
9.
10.
11.dfs.datanode.data.dir
12.file:/usr/local/hadoop/tmp/dfs/data
13.
14.
Hadoop配置文件說明
Hadoop 的運行方式是由配置文件決定的(運行 Hadoop 時會讀取配置文件),因此如果需要從偽分布式模式切換回非分布式模式,需要刪除 core-site.xml 中的配置項。
此外,偽分布式雖然只需要配置 fs.defaultFS 和 dfs.replication 就可以運行(官方教程如此),不過若沒有配置 hadoop.tmp.dir 參數,則默認使用的臨時目錄為 /tmp/hadoo-hadoop,而這個目錄在重啟時有可能被系統清理掉,導致必須重新執行 format 才行。所以我們進行了設置,同時也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否則在接下來的步驟中可能會出錯。
配置完成後,執行 NameNode 的格式化:
1. ./bin/hdfs namenode -format
成功的話,會看到 “successfully formatted” 和“Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯。
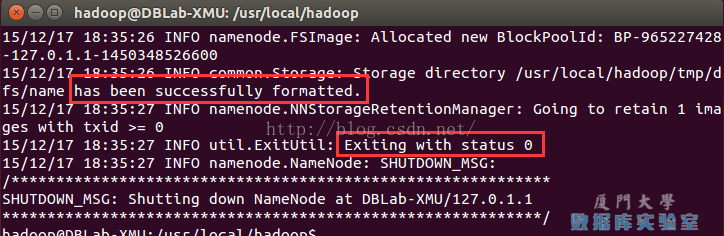
執行namenode格式化
如果在這一步時提示Error:JAVA_HOME is not set and could not be found.的錯誤,則說明之前設置JAVA_HOME 環境變量那邊就沒設置好,請按教程先設置好JAVA_HOME 變量,否則後面的過程都是進行不下去的。
接著開啟 NameNode 和 DataNode 守護進程。
1../sbin/start-dfs.sh #start-dfs.sh是個完整的可執行文件,中間沒有空格
Shell 命令
若出現如下SSH提示,輸入yes即可。
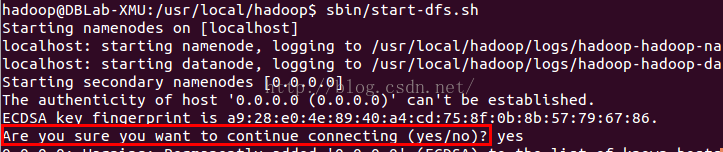
啟動Hadoop時的SSH提示
啟動時可能會出現如下 WARN 提示:WARNutil.NativeCodeLoader: Unable to load native-hadoop library for your platform…using builtin-java classes where applicable WARN 提示可以忽略,並不會影響正常使用。
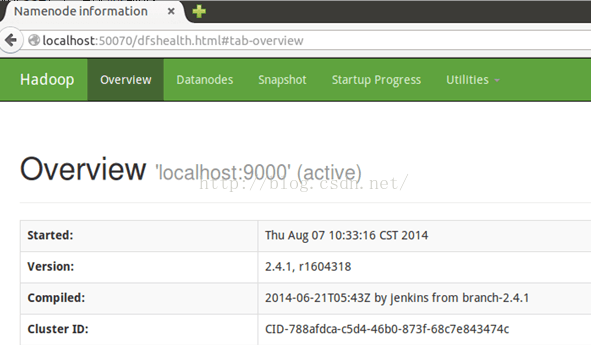
成功啟動後,可以訪問Web 界面http://localhost:50070查看 NameNode 和 Datanode 信息,還可以在線查看 HDFS 中的文件。