


線程所維護的是運行相關的資源(動態資源),如:運行棧,調度相關的控制信息,待處理的信號集等。
然而,一直以來,linux內核並沒有線程的概念。每一個執行實體都是一個task_struct結構,通常稱之為進程。linux進程是一個執行單元,維護著執行相關的動態資源,同時,它又引用著程序所需的靜態資源。通過系統調用clone創建子進程時,可以有選擇性地讓子進程共享父進程所引用的資源,這樣的子進程通常稱為輕量級進程。linux上的線程就是基於輕量級進程,由用戶態的pthread庫實現的。使用pthread以後,在用戶看來,每一個task_struct就對應一個線程,而一組線程以及它們所共同引用的一組資源就是一個進程。
但是,一組線程並不僅僅是引用同一組資源就夠了,它們還必須被視為一個整體,對此,POSIX標准提出了如下要求:
1、查看進程列表的時候,相關的一組task_struct應當被展現為列表中的一個節點
2、發送給這個“進程”的信號(對應kill系統調用),將被對應的這一組task_struct所共享,並且被其中的任意一個“線程”處理
3、發送給某個“線程”的信號(對應pthread_kill),將只被對應的一個task_struct接收,並且由它自己來處理
4、當“進程”被停止或繼續時(對應SIGSTOP/SIGCONT信號),對應的這一組task_struct狀態將改變
5、當“進程”收到一個致命信號(比如由於段錯誤收到SIGSEGV信號),對應的這一組task_struct將全部退出
6、等等(以上可能不夠全)
linuxthreads
在linux2.6以前,pthread線程庫對應的實現是一個名叫linuxthreads的lib。linuxthreads利用前面提到的輕量級進程來實現線程,但是對於POSIX提出的那些要求,linuxthreads除了第5點以外,都沒有實現(實際上是無能為力):
1、如果運行了A程序,A程序創建了10個線程,那麼在shell下執行ps命令時將看到11個A進程,而不是1個(注意,也不是10個,下面會解釋)
2、不管是kill還是pthread_kill, 信號只能被一個對應的線程所接收
3、SIGSTOP/SIGCONT信號只對一個線程起作用
還好linuxthreads實現了第5點,我認為這一點是最重要的。如果某個線程“掛”了,整個進程還在若無其事地運行著,可能會出現很多的不一致狀態,進程將不是一個整體,而線程也不能稱為線程了。或許這也是為什麼linuxthreads雖然與POSIX的要求差距甚遠,卻能夠存在,並且還被使用了好幾年的原因吧。但是,linuxthreads為了實現這個“第5點”,還是付出了很多代價,並且創造了linuxthreads本身的一大性能瓶頸。
接下來要說說為什麼A程序創建了10個線程,但是ps時卻會出現11個A進程了。因為linuxthreads自動創建了一個管理線程,上面提到的“第5點”就是靠管理線程來實現的。當程序開始運行時,並沒有管理線程存在(因為盡管程序已經鏈接了pthread庫,但是未必會使用多線程)。程序第一次調用pthread_create時,linuxthreads發現管理線程不存在,於是創建這個管理線程,這個管理線程是進程中的第一個線程(主線程)的兒子。然後在pthread_create中,會通過pipe向管理線程發送一個命令,告訴它創建線程,即是說,除主線程外,所有的線程都是由管理線程來創建的,管理線程是它們的父親。於是,當任何一個子線程退出時,管理線程將收到SIGUSER1信號(這是在通過clone創建子線程時指定的)。管理線程在對應的sig_handler中會判斷子線程是否正常退出,如果不是,則殺死所有線程,然後自殺。那麼,主線程怎麼辦呢?主線程是管理線程的父親,其退出時並不會給管理線程發信號,於是,在管理線程的主循環中通過getppid檢查父進程的ID號,如果ID號是1,說明父親已經退出,並把自己托管給了init進程(1號進程),這時候,管理線程也會殺掉所有子線程,然後自殺。
可見, 線程的創建與銷毀都是通過管理線程來完成的,於是管理線程就成了linuxthreads的一個性能瓶頸,創建與銷毀需要一次進程間通信,一次上下文切換之後才能被管理線程執行,並且多個請求會被管理線程串行地執行。
NPTL
到了linux2.6,glibc中有了一種新的pthread線程庫–NPTL(Native POSIX Threading Library)。NPTL實現了前面提到的POSIX的全部5點要求,但是,實際上,與其說是NPTL實現了,不如說是linux內核實現了。在linux2.6中,內核有了線程組的概念,task_struct結構中增加了一個tgid(thread group id)字段。如果這個task是一個“主線程”(即thread group leader),則它的tgid等於pid,若是子線程則tgid等於進程的pid(即主線程的pid)。在clone系統調用中, 傳遞CLONE_THREAD參數就可以把新進程的tgid設置為父進程的tgid(否則新進程的tgid會設為其自身的pid)。類似的XXid在task_struct中還有兩個:task->signal->pgid保存進程組的打頭進程的pid,task->signal->session保存會話的打頭進程的pid。通過這兩個id來關聯進程組和會話。
有了tgid,內核或相關的shell程序就知道某個tast_struct是代表一個進程還是代表一個線程(tgid!=pid就是線程了),也就知道在什麼時候該展現它們,什麼時候不該展現(比如在ps的時候,線程就不要展現了)。而getpid(獲取進程ID)系統調用返回的也是tast_struct中的tgid,而tast_struct中的pid則由gettid系統調用來返回。在執行ps命令的時候不展現子線程,也是有一些問題的。比如程序a.out運行時,創建了一個線程,假設主線程的pid是10001,子線程是10002(它們的tgid都是10001),這時如果你kill 10002,是可以把10001和10002這兩個線程一起殺死的,盡管執行ps命令的時候根本看不到10002這個進程。如果你不知道linux線程背後的故事,肯定會覺得遇到靈異事件了。
為了應付“發送給進程的信號”和“發送給線程的信號”,task_struct裡面維護了兩套signal_pending,一套是線程組共享的,一套是線程獨有的。通過kill發送的信號被放在線程組共享的signal_pending中,可以由任意一個線程來處理;通過pthread_kill發送的信號(pthread_kill是pthread庫的接口,對應的系統調用中tkill)被放在線程獨有的signal_pending中,只能由本線程來處理。當線程停止/繼續, 或者是收到一個致命信號時,內核會將處理動作施加到整個線程組中。
NGPT
說到這裡,也順便提一下NGPT(Next Generation POSIX Threads)。
上面提到的兩種線程庫使用的都是內核級線程(每個線程都對應內核中的一個調度實體),這種模型稱為1:1模型(1個線程對應1個內核級線程),而NGPT則打算實現M:N模型(M個線程對應N個內核級線程),也就是說若干個線程可能是在同一個執行實體上實現的。
線程庫需要在一個內核提供的執行實體上抽象出若干個執行實體,並實現它們之間的調度。這樣被抽象出來的執行實體稱為用戶級線程。大體上,這可以通過為每個用戶級線程分配一個棧,然後通過longjmp的方式進行上下文切換。(百度一下“setjmp/longjmp”,你就知道。也可以查閱《C語言接口與實現》,有一篇專門介紹setjmp和longjmp)但是實際上要處理的細節問題非常之多。目前的NGPT好像並沒有實現所有預期的功能,並且暫時也不准備去實現。
用戶級線程的切換顯然要比內核級線程的切換快一些,前者可能只是一個簡單的長跳轉,而後者則需要保存/裝載寄存器,進入然後退出內核態。(進程切換則還需要切換地址空間等。)
而用戶級線程則不能享受多處理器,因為多個用戶級線程對應到一個內核級線程上,一個內核級線程在同一時刻只能運行在一個處理器上。
不過,M:N的線程模型畢竟提供了這樣一種手段,可以讓不需要並行執行的線程運行在一個內核級線程對應的若干個用戶級線程上,可以節省它們的切換開銷。
據說一些類UNIX系統(如Solaris)已經實現了比較成熟的M:N線程模型,其性能比起linux的線程還是有著一定的優勢的。
進程與線程
為什麼對於大多數合作性任務,多線程比多個獨立的進程更優越呢?這是因為,線程共享相同的內存空間。不同的線程可以存取內存中的同一個變量。所以,程序中的所有線程都可以讀或寫聲明過的全局變量。如果曾用fork() 編寫過重要代碼,就會認識到這個工具的重要性。為什麼呢?雖然fork() 允許創建多個進程,但它還會帶來以下通信問題:如何讓多個進程相互通信,這裡每個進程都有各自獨立的內存空間。對這個問題沒有一個簡單的答案。雖然有許多不同種類的本地IPC (進程間通信),但它們都遇到兩個重要障礙:
雙重壞事: 開銷和復雜性都非好事。如果曾經為了支持 IPC而對程序大動干戈過,那麼您就會真正欣賞線程提供的簡單共享內存機制。由於所有的線程都駐留在同一內存空間,POSIX線程無需進行開銷大而復雜的長距離調用。只要利用簡單的同步機制,程序中所有的線程都可以讀取和修改已有的數據結構。而無需將數據經由文件描述符轉儲或擠入緊窄的共享內存空間。僅此一個原因,就足以讓您考慮應該采用單進程/多線程模式而非多進程/單線程模式。
為什麼要用線程?
與標准 fork()相比,線程帶來的開銷很小。內核無需單獨復制進程的內存空間或文件描述符等等。這就節省了大量的CPU時間,使得線程創建比新進程創建快上十到一百倍。因為這一點,可以大量使用線程而無需太過於擔心帶來的CPU 或內存不足。使用 fork() 時導致的大量 CPU占用也不復存在。這表示只要在程序中有意義,通常就可以創建線程。
當然,和進程一樣,線程將利用多CPU。如果軟件是針對多處理器系統設計的,這就真的是一大特性(如果軟件是開放源碼,則最終可能在不少平台上運行)。特定類型線程程序(尤其是CPU密集型程序)的性能將隨系統中處理器的數目幾乎線性地提高。如果正在編寫CPU非常密集型的程序,則絕對想設法在代碼中使用多線程。一旦掌握了線程編碼,無需使用繁瑣的IPC和其它復雜的通信機制,就能夠以全新和創造性的方法解決編碼難題。所有這些特性配合在一起使得多線程編程更有趣、快速和靈活。
什麼是線程?
- 進程ID,進程群組ID,用戶ID,群組ID
- 環境
- 工作目錄
- 程序指令
- 寄存器
- 棧
- 堆
- 文件描述符
- 信號動作
- 共享庫
- 進程間通信工具(例如消息隊列,管道,信號量,共享內存)
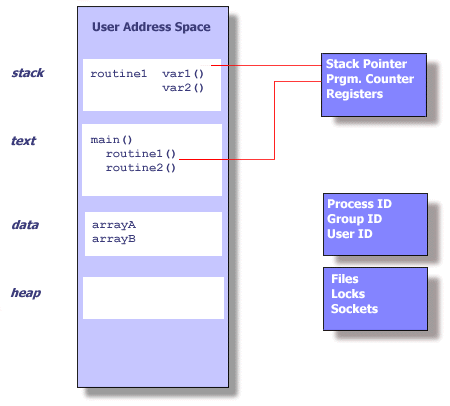
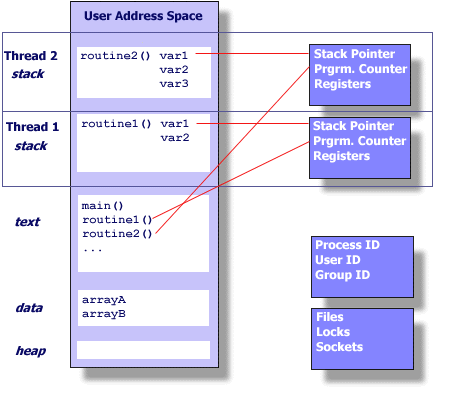
Unix進程 Unix進程內部的線程
- 棧指針
- 寄存器
- 調度屬性(例如規則和優先級)
- 等待序列和阻塞信號
- 線程擁有的數據
- 它生存在進程中,並使用進程資源;
- 擁有它自己獨立的控制流,前提是只要它的父進程還存在,並且OS支持它;
- 它僅僅復制可以使它自己調度的必要的資源;
- 它可能會同其它與之同等獨立的線程分享進程資源;
- 如果父進程死掉那麼它也會死掉——或者類似的事情;
- 它是輕量級的,因為大部分的開支已經在它的進程創建時完成了。
- 一個線程對共享的系統資源做出的改變(例如關閉一個文件)會被所有的其它線程看到;
- 指向同一地址的兩個指針的數據是相同的;
- 對同一塊內存進行讀寫操作是可行的,但需要程序員作明確的同步處理操作。