


sed awk grep
這三個工具都要用到正則表達式,把常用貼出來。
1.行的匹配
[root@mypc /]# sed -n ‘2p’ /etc/passwd 打印出第2行
[root@mypc /]# sed -n ‘1,3p’ /etc/passwd 打印出第1到第3行
[root@mypc /]# sed -n ‘$p’ /etc/passwd 打印出最後一行
[root@mypc /]# sed -n ‘/user/p' /etc/passwd 打印出含有user的行
[root@mypc /]# sed -n ‘/\$/p' /etc/passwd 打印出含有$元字符的行,$為特殊字符,表示最後一行
2.插入文本和附加文本(插入新行)
[root@mypc /]# sed -n ‘/FTP/p’ /etc/passwd 打印出有FTP的行
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@mypc /]# sed ‘/FTP/ a/ 456′ /etc/passwd 在含有FTP的行後面新插入一行,內容為456
[root@mypc /]# sed ‘/FTP/ i/ 123′ /etc/passwd在含有FTP的行前面新插入一行,內容為123
[root@mypc /]# sed ‘/FTP/ i/ “123″‘ /etc/passwd在含有FTP的行前面新插入一行,內容為”123″
[root@mypc /]# sed ‘5 a/ 123′ /etc/passwd 在第5行後插入一新行,內容為123
[root@mypc /]# sed ‘5 i/ “12345″‘ /etc/passwd 在第5行前插入一新行,內容為”12345″
3.刪除文本
[root@mypc /]# sed ‘1d’ /etc/passwd 刪除第1行
[root@mypc /]# sed ‘1,3d’ /etc/passwd 刪除第1至3行
[root@mypc /]# sed ‘/user/d’ /etc/passwd 刪除帶有user的行
4. 替換文本,替換命令用替換模式替換指定模式,格式為:
[ a d d r e s s [,address]] s/ pattern-to-find /replacement-pattern/[g p w n]
[root@mypc /]# sed ’s/user/USER/’ /etc/passwd 將第1個user替換成USER,g表明全局替換
[root@mypc /]# sed ’s/user/USER/g’ /etc/passwd 將所有user替換成USER
[root@mypc /]# sed ’s/user/#user/’ /etc/passwd 將第1個user替換成#user,如用於屏蔽作用
[root@mypc /]# sed ’s/user//’ /etc/passwd 將第1個user替換成空
[root@mypc /]# sed ’s/user/&11111111111111/’ /etc/passwd 如果要附加或修改一個很長的字符串,可以使用( &)命令,&命令保存發現模式以便重新調用它,然後把它放在替換字符串裡面,這裡是把&放前面
[root@mypc /]# sed ’s/user/11111111111111&/’ /etc/passwd 這裡是將&放後面
5. 快速一行命令
下面是一些一行命令集。([ ]表示空格,[ ]表示t a b鍵)
如果使用s e d對文件進行過濾,最好將問題分成幾步,分步執行,且邊執行邊測試結果。
vim
移動光標的方法
h 或 向左箭頭鍵(←)
光標向左移動一個字符
j 或 向下箭頭鍵(↓)
光標向下移動一個字符
k 或 向上箭頭鍵(↑)
光標向上移動一個字符
l 或 向右箭頭鍵(→)
光標向右移動一個字符
如果你將右手放在鍵盤上的話,你會發現 hjkl 是排列在一起的,因此可以使用這四個按鈕來移動光標。 如果想要進行多次移動的話,例如向下移動 30 行,可以使用 "30j" 或 "30↓" 的組合按鍵, 亦即加上想要進行的次數(數字)後,按下動作即可!
[Ctrl] + [f]
屏幕『向下』移動一頁,相當於 [Page Down]按鍵 (常用)
[Ctrl] + [b]
屏幕『向上』移動一頁,相當於 [Page Up] 按鍵 (常用)
[Ctrl] + [d]
屏幕『向下』移動半頁
[Ctrl] + [u]
屏幕『向上』移動半頁
+
光標移動到非空格符的下一列
-
光標移動到非空格符的上一列
n<space>
那個 n 表示『數字』,例如 20 。按下數字後再按空格鍵,光標會向右移動這一行的 n 個字符。例如 20<space> 則光標會向後面移動 20 個字符距離。
0 或功能鍵[Home]
這是數字『 0 』:移動到這一行的最前面字符處 (常用)
$ 或功能鍵[End]
移動到這一行的最後面字符處(常用)
H
光標移動到這個屏幕的最上方那一行的第一個字符
M
光標移動到這個屏幕的中央那一行的第一個字符
L
光標移動到這個屏幕的最下方那一行的第一個字符
G
移動到這個檔案的最後一行(常用)
nG
n 為數字。移動到這個檔案的第 n 行。例如 20G 則會移動到這個檔案的第 20 行(可配合 :set nu)
gg
移動到這個檔案的第一行,相當於 1G 啊! (常用)
n<Enter>
n 為數字。光標向下移動 n 行(常用)
搜尋與取代
/word
向光標之下尋找一個名稱為 word 的字符串。例如要在檔案內搜尋 vbird 這個字符串,就輸入 /vbird 即可! (常用)
?word
向光標之上尋找一個字符串名稱為 word 的字符串。
n
這個 n 是英文按鍵。代表『重復前一個搜尋的動作』。舉例來說, 如果剛剛我們執行 /vbird 去向下搜尋 vbird 這個字符串,則按下 n 後,會向下繼續搜尋下一個名稱為 vbird 的字符串。如果是執行 ?vbird 的話,那麼按下 n 則會向上繼續搜尋名稱為 vbird 的字符串!
N
這個 N 是英文按鍵。與 n 剛好相反,為『反向』進行前一個搜尋動作。 例如 /vbird 後,按下 N 則表示『向上』搜尋 vbird 。
使用 /word 配合 n 及 N 是非常有幫助的!可以讓你重復的找到一些你搜尋的關鍵詞!
:n1,n2s/word1/word2/g
n1 與 n2 為數字。在第 n1 與 n2 行之間尋找 word1 這個字符串,並將該字符串取代為 word2 !舉例來說,在 100 到 200 行之間搜尋 vbird 並取代為 VBIRD 則:
『:100,200s/vbird/VBIRD/g』。(常用)
:1,$s/word1/word2/g
從第一行到最後一行尋找 word1 字符串,並將該字符串取代為 word2 !(常用)
:1,$s/word1/word2/gc
從第一行到最後一行尋找 word1 字符串,並將該字符串取代為 word2 !且在取代前顯示提示字符給用戶確認 (confirm) 是否需要取代!(常用)
刪除、復制與貼上
x, X
在一行字當中,x 為向後刪除一個字符 (相當於 [del] 按鍵), X 為向前刪除一個字符(相當於 [backspace] 亦即是退格鍵) (常用)
nx
n 為數字,連續向後刪除 n 個字符。舉例來說,我要連續刪除 10 個字符, 『10x』。
dd
刪除游標所在的那一整列(常用)
ndd
n 為數字。刪除光標所在的向下 n 列,例如 20dd 則是刪除 20 列 (常用)
d1G
刪除光標所在到第一行的所有數據
dG
刪除光標所在到最後一行的所有數據
d$
刪除游標所在處,到該行的最後一個字符
d0
那個是數字的 0 ,刪除游標所在處,到該行的最前面一個字符
yy
復制游標所在的那一行(常用)
nyy
n 為數字。復制光標所在的向下 n 列,例如 20yy 則是復制 20 列(常用)
y1G
復制游標所在列到第一列的所有數據
yG
復制游標所在列到最後一列的所有數據
y0
復制光標所在的那個字符到該行行首的所有數據
y$
復制光標所在的那個字符到該行行尾的所有數據
p, P
p 為將已復制的數據在光標下一行貼上,P 則為貼在游標上一行! 舉例來說,我目前光標在第 20 行,且已經復制了 10 行數據。則按下 p 後, 那 10 行數據會貼在原本的 20 行之後,亦即由 21 行開始貼。但如果是按下 P 呢? 那麼原本的第 20 行會被推到變成 30 行。 (常用)
J
將光標所在列與下一列的數據結合成同一列
c
重復刪除多個數據,例如向下刪除 10 行,[ 10cj ]
u
復原前一個動作。(常用)
[Ctrl]+r
重做上一個動作。(常用)
這個 u 與 [Ctrl]+r 是很常用的指令!一個是復原,另一個則是重做一次~ 利用這兩個功能按鍵,你的編輯,嘿嘿!很快樂的啦!
.
不要懷疑!這就是小數點!意思是重復前一個動作的意思。 如果你想要重復刪除、重復貼上等等動作,按下小數點『.』就好了! (常用)
進入插入或取代的編輯模式
i, I
進入插入模式(Insert mode):
i 為『從目前光標所在處插入』, I 為『在目前所在行的第一個非空格符處開始插入』。 (常用)
a, A
進入插入模式(Insert mode):
a 為『從目前光標所在的下一個字符處開始插入』, A 為『從光標所在行的最後一個字符處開始插入』。(常用)
o, O
進入插入模式(Insert mode):
這是英文字母 o 的大小寫。o 為『在目前光標所在的下一行處插入新的一行』; O 為在目前光標所在處的上一行插入新的一行!(常用)
r, R
進入取代模式(Replace mode):
r 只會取代光標所在的那一個字符一次;R會一直取代光標所在的文字,直到按下 ESC 為止;(常用)
上面這些按鍵中,在 vi 畫面的左下角處會出現『--INSERT--』或『--REPLACE--』的字樣。 由名稱就知道該動作了吧!!特別注意的是,我們上面也提過了,你想要在檔案裡面輸入字符時, 一定要在左下角處看到 INSERT 或 REPLACE 才能輸入喔!
[Esc]
退出編輯模式,回到一般模式中(常用)
指令列的儲存、離開等指令
:w
將編輯的數據寫入硬盤檔案中(常用)
:w!
若文件屬性為『只讀』時,強制寫入該檔案。不過,到底能不能寫入, 還是跟你對該檔案的檔案權限有關啊!
:q
離開 vi (常用)
:q!
若曾修改過檔案,又不想儲存,使用 ! 為強制離開不儲存檔案。
注意一下啊,那個驚歎號 (!) 在 vi 當中,常常具有『強制』的意思~
:wq
儲存後離開,若為 :wq! 則為強制儲存後離開 (常用)
ZZ
這是大寫的 Z 喔!若檔案沒有更動,則不儲存離開,若檔案已經被更動過,則儲存後離開!
:w [filename]
將編輯的數據儲存成另一個檔案(類似另存新檔)
:r [filename]
在編輯的數據中,讀入另一個檔案的數據。亦即將 『filename』 這個檔案內容加到游標所在行後面
:n1,n2 w [filename]
將 n1 到 n2 的內容儲存成 filename 這個檔案。
:! command
暫時離開 vi 到指令列模式下執行 command 的顯示結果!例如 :! ls /home 即可在 vi 當中察看 /home 底下以 ls 輸出的檔案信息!
vim 環境的變更
:set nu
顯示行號,設定之後,會在每一行的前綴顯示該行的行號
:set nonu
與 set nu 相反,為取消行號!
多窗口情況下的按鍵功能
:sp [filename]
開啟一個新窗口,如果有加 filename, 表示在新窗口開啟一個新檔案,否則表示兩個窗口為同一個檔案內容(同步顯示)。
[ctrl]+w+ j
[ctrl]+w+↓
按鍵的按法是:先按下 [ctrl] 不放, 再按下 w 後放開所有的按鍵,然後再按下 j (或向下箭頭鍵),則光標可移動到下方的窗口。
[ctrl]+w+ k
[ctrl]+w+↑
同上,不過光標移動到上面的窗口。
[ctrl]+w+ q
其實就是 :q 結束離開啦! 舉例來說,如果我想要結束下方的窗口,那麼利用 [ctrl]+w+↓ 移動到下方窗口後,按下 :q 即可離開, 也可以按下 [ctrl]+w+q
vim 的環境設定參數
:set nu
:set nonu
就是設定與取消行號啊!
:set hlsearch
:set nohlsearch
hlsearch 就是 high light search(高亮度搜尋)。 這個就是設定是否將搜尋的字符串反白的設定值。默認值是 hlsearch
:set autoindent
:set noautoindent
是否自動縮排?autoindent 就是自動縮排。
:set backup
是否自動儲存備份檔?一般是 nobackup 的, 如果設定 backup 的話,那麼當你更動任何一個檔案時,則源文件會被另存成一個檔名為 filename~ 的檔案。 舉例來說,我們編輯 hosts ,設定 :set backup ,那麼當更動 hosts 時,在同目錄下,就會產生 hosts~ 文件名的檔案,記錄原始的 hosts 檔案內容
:set ruler
還記得我們提到的右下角的一些狀態欄說明嗎? 這個 ruler 就是在顯示或不顯示該設定值的啦!
:set showmode
這個則是,是否要顯示 --INSERT-- 之類的字眼在左下角的狀態欄。
:set backspace=(012)
一般來說, 如果我們按下 i 進入編輯模式後,可以利用退格鍵 (backspace) 來刪除任意字符的。 但是,某些 distribution 則不許如此。此時,我們就可以透過 backspace 來設定啰~ 當 backspace 為 2 時,就是可以刪除任意值;0 或 1 時,僅可刪除剛剛輸入的字符, 而無法刪除原本就已經存在的文字了!
:set all
顯示目前所有的環境參數設定值。
:set
顯示與系統默認值不同的設定參數, 一般來說就是你有自行變動過的設定參數啦!
:syntax on
:syntax off
是否依據程序相關語法顯示不同顏色? 舉例來說,在編輯一個純文本檔時,如果開頭是以 # 開始,那麼該行就會變成藍色。 如果你懂得寫程序,那麼這個 :syntax on 還會主動的幫你除錯呢!但是, 如果你僅是編寫純文本檔案,要避免顏色對你的屏幕產生的干擾,則可以取消這個設定 。
:set bg=dark
:set bg=light
可用以顯示不同的顏色色調,預設是『 light 』。如果你常常發現批注的字體深藍色實在很不容易看, 那麼這裡可以設定為 dark 喔!試看看,會有不同的樣式呢!
妙招1 交換等號兩邊的內容。
我們在寫代碼的時候難免會遇到左值和右值交換,若是這樣的語句多達百條,痛苦萬分。
sed 's//(.*/) = /(.*/);//2 = /1;/' 注意等號左右各有一個空格,當然這要取決於你的賦值語句。
另一篇:
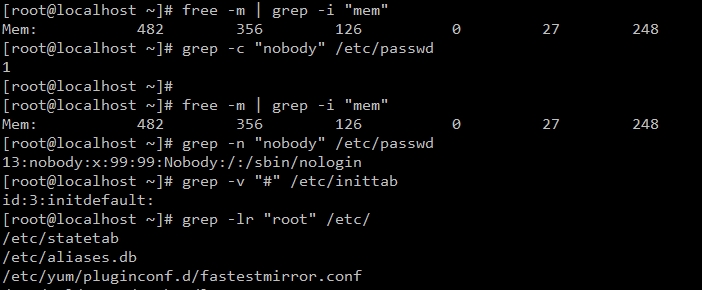
1、grep命令:查找文件裡符合條件的字符串
一種強大的文本搜索工具,它能使用正則表達式搜索文本,並把匹配的行打印出來
語法格式: grep [options]
-i:ignore-case 忽略大小寫差別
-c:count 只打印匹配的總行數,不顯示匹配的內容信息
-n:line-number 在匹配的行前面打印行號
-v:revert-match 反檢索,只顯示不匹配的行
-r:recursion遞歸地,讀取每個文件夾下的所有檔案
-l :不顯示平常一般的輸出結果,只顯示符合的文件名稱
2、awk命令:一個強大的文本處理工具,逐行掃描,從第一行到最後一行
使用語法:awk 'pattern{action}' filename
pattern:正則表達式
action:輸出語法
你可以省略pattern和 action之一,但不能兩者同時省略,當省略pattern時沒有樣式匹配,表示對所有行(記錄)均執行操作,省略action時執行缺省的操作——在標准輸出上顯示。
語法格式:awk [ -F re] [parameter...]
-F re:允許awk更改其字段分隔符
parameter: 該參數幫助為不同的變量賦值
-v:定義變量
-f:指定腳本文件
三種調用方式:
1、awk命令行
2、使用-f選項調用awk程序,例如:awk -f progfile file ,其中progfile是指定一個文本文件
3、利用命令解釋器調用awk程序,需要在awk腳本聲明調用方式,例如:#!/bin/awk -f
命令行方式使用內容過濾:
[root@test ~]# awk '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#顯示分隔符指定列(1列),分隔符默認是空格,$1是顯示分隔符前面一列
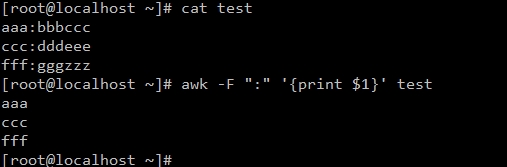
#顯示test文件中匹配123的行
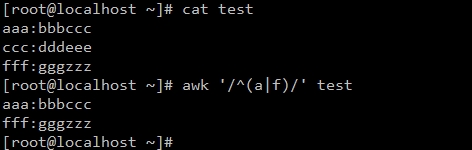
[root@test ~]# awk '/123/ {print $1}' test
#顯示所有以a或f開頭的行
4、sed命令:一種在線編輯器,它一次處理一行內容
處理時,把當前處理的行存儲在臨時緩沖區中,稱為'模式空間'(pattern space),接著用sed命令處理緩沖區中的內容,處理完成後,把緩沖區的內容送往屏幕。接著處理下一行,這樣不斷重復,直到文件末尾。文件內容並沒有改變,除非你使用重定向存儲輸出。
常用參數:
i 插入
s 替換
e 多點編輯
d 刪除
a 追加到行後面
g 全部替換,無g只替換每行第一個
q 退出
#將所有包含aaa替換為jjj
sed 's/aaa/jjj/' test
#把這行注釋去掉,替換文本
sed -i 's/#ServerName www.example.com:80/ ServerName 192.168.0.202:80/g'
將所有包含/var/www/html/替換為/opt/web/,分隔符'/'可以用別的符號代替,比如 ',' '_' '|' 等
sed -i s/\/var\/www\/html/\/opt\/web/' /etc/httpd/conf/httpd.conf
等同於:
sed -i 's_/var/www/html/_/opt/web/_' /etc/httpd/conf/httpd.conf
#插入一行到391行,包括特殊符號'/'
sed -i '391 s/^/AddType application\/x-httpd-php .php.html/' httpd.conf
#只打印第一行數據
sed -n '1p' /etc/passwd
#打印包含root的行,禁止默認輸出
sed -n '/root/p' /etc/passwd
#刪除13行
sed -i '13d' /etc/passwd
#刪除13行到最後一行
sed -i '13,$d' /etc/passwd
#將包含uucp的行刪除
sed -i '/uucp/d' /etc/passwd
5、find命令:查找具有某一特征的文件(例如文件權限、文件屬主、文件長度、文件類型等
用法:find [path] [options] [條件]
Path:查找路徑
Options:選項
例如:
-name:按照文件名查找文件
-mtime:按照文件的更改時間來查找文件,後跟-n、+n來表示多少天內和以前
-user:按照文件屬主來查找文件
-group:按照文件所屬的組來查找文件
-type:查找某一個類型的文件,諸如:b(塊設備)、d(目錄)、l(符號鏈接)、f(普通文件)
-size:根據文件大小來查找文件
#在根目錄查找更改時間在5日以內的文件
find /tmp -mtime -5
#在/var目錄下查找更改時間在3日以前的文件
find /var/ -mtime +3
#查找系統中所有文件長度為0的普通文件,並列出他們的完整路徑
find / -type f -size 0 -exec ls -l {} \;
#查找/var/log目錄中更改時間在7日以前的普通文件,並刪除他們
find /var/log/ -type f -mtime +7 -exec rm {} \;
#找出用戶test擁有的文件,並將他們拷貝到/root/test目錄中
find / -user test -exec cp {} /root/test \;
6、sort命令:對文件中的各行進行排序
sort命令將逐行對文件中的內容進行排序,如果兩行的首字符相同,該命令將繼續比較這兩行的下一字符,如果還相同,將繼續進行比較.
格式:sort [選項] 文件
主要選項:
-r:倒序排序,默認是升序。
-n:按數值大小進行排序
-k:KeyDefinition 指定排序關鍵字。
-t:Character 指定 Character 作為字段分隔符
-d:使用字典順序排序。比較中僅考慮字母、數字和空格
-f:將小寫字母與大寫字母同等對待
-u:去掉重復的行,使文件中的每一行唯一
7、uniq命令:刪除文件中的重復行
文件經過處理後在它的輸出文件中可能會出現重復的行。例如,使用cat命令將兩個文件合並後,再使用sort命令進行排序,就可能出現重復行。這時可以使用uniq命令將這些重復行從輸出文件中刪除,只留下每條記錄的唯一樣本。
格式:uniq [選項] 文件
主要選項:
-c:顯示行號
-d:只顯示重復行。
-u:只顯示文件中不重復的各行。
8、cut命令:顯示文件中每行的指定內容
格式:cut -d 分隔字符 [-cf] fields
-d:後面接的是分隔字符,默認情況下為Tab;
-c:後面接的是第幾個字符
-f:後面接的 是第幾個區塊
#列出/etc/passwd文件中的所有用戶,按照升序排列
cut -d : -f 1 /etc/passwd | sort
#顯示/etc/passwd文件下uid為0的用戶名以及uid。
cut -d : -f 1,3/etc/passwd|grep ':0$'
正則表達式'$'表示以字符結尾,'^'表示以某字符開始。
9、tr命令:從標准輸入刪除或替換字符,可以看為sed簡化軟件
常用選項的tr命令格式為:
-d 刪除字符串1中所有輸入字符。
-s 刪除所有重復出現字符序列,只保留第一個。
#將小寫字符轉換成大寫
tr 'a-z' 'A-Z' < file
#將文件中刪除所有空字符
tr –d ‘\0’< file
#刪除文件中shell字符
cat test | tr -d 'shell'
#將文件中所有abc字符替換efg並另存為新文件
cat test | tr 'abc' 'efg' >new file
10、其他文本處理命令
cat:從頭開始顯示內容,並將所有內容輸出
常用參數,-n顯示輸出的行數編號
tac:從最後一行倒序顯示內容,並將所有內容輸出
head:默認顯示頭10行,-n指定顯示多少行數
tail:默認顯示最後10行,-n指定顯示多少行數,-f實時顯示內容
more:分屏查看文本文件
less:和more類似,但可以往前翻頁
nl:顯示時輸出行號
wc:計算文件的字節數、單詞數和行數
常用參數:-c統計字節數,-l統計行數,-m統計字符數
其他
本文將介紹Linux下使用Shell處理文本時最常用的工具:
find、grep、xargs、sort、uniq、tr、cut、paste、wc、sed、awk;
提供的例子和參數都是最常用和最為實用的;
我對shell腳本使用的原則是命令單行書寫,盡量不要超過2行;
如果有更為復雜的任務需求,還是考慮python吧;
查找txt和pdf文件
find . \( -name "*.txt" -o -name "*.pdf" \) -print
正則方式查找.txt和pdf
find . -regex ".*\(\.txt|\.pdf\)$"
-iregex: 忽略大小寫的正則
否定參數
查找所有非txt文本
find . ! -name "*.txt" -print
指定搜索深度
打印出當前目錄的文件(深度為1)
find . -maxdepth 1 -type f
按類型搜索:
find . -type d -print //只列出所有目錄
-type f 文件 / l 符號鏈接
按時間搜索:
-atime 訪問時間 (單位是天,分鐘單位則是-amin,以下類似)
-mtime 修改時間 (內容被修改)
-ctime 變化時間 (元數據或權限變化)
最近7天被訪問過的所有文件:
find . -atime 7 -type f -print
按大小搜索:
w字 k M G
尋找大於2k的文件
find . -type f -size +2k
按權限查找:
find . -type f -perm 644 -print //找具有可執行權限的所有文件
按用戶查找:
find . -type f -user weber -print// 找用戶weber所擁有的文件
刪除:
刪除當前目錄下所有的swp文件:
find . -type f -name "*.swp" -delete
執行動作(強大的exec)
find . -type f -user root -exec chown weber {} \; //將當前目錄下的所有權變更為weber
注:{}是一個特殊的字符串,對於每一個匹配的文件,{}會被替換成相應的文件名;
eg:將找到的文件全都copy到另一個目錄:
find . -type f -mtime +10 -name "*.txt" -exec cp {} OLD \;
結合多個命令
tips: 如果需要後續執行多個命令,可以將多個命令寫成一個腳本。然後 -exec 調用時執行腳本即可;
-exec ./commands.sh {} \;
默認使用'\n'作為文件的定界符;
-print0 使用'\0'作為文件的定界符,這樣就可以搜索包含空格的文件;
grep match_patten file // 默認訪問匹配行
常用參數
-o 只輸出匹配的文本行 VS -v 只輸出沒有匹配的文本行
-c 統計文件中包含文本的次數
grep -c "text" filename
-n 打印匹配的行號
-i 搜索時忽略大小寫
-l 只打印文件名
在多級目錄中對文本遞歸搜索(程序員搜代碼的最愛):
grep "class" . -R -n
grep -e "class" -e "vitural" file
grep "test" file* -lZ| xargs -0 rm
xargs 能夠將輸入數據轉化為特定命令的命令行參數;這樣,可以配合很多命令來組合使用。比如grep,比如find;
將多行輸出轉化為單行輸出
cat file.txt| xargs
\n 是多行文本間的定界符
將單行轉化為多行輸出
cat single.txt | xargs -n 3
-n:指定每行顯示的字段數
-d 定義定界符 (默認為空格 多行的定界符為 \n)
-n 指定輸出為多行
-I {} 指定替換字符串,這個字符串在xargs擴展時會被替換掉,用於待執行的命令需要多個參數時
eg:
cat file.txt | xargs -I {} ./command.sh -p {} -1
-0:指定\0為輸入定界符
eg:統計程序行數
find source_dir/ -type f -name "*.cpp" -print0 |xargs -0 wc -l
字段說明:
-n 按數字進行排序 VS -d 按字典序進行排序
-r 逆序排序
-k N 指定按第N列排序
eg:
sort -nrk 1 data.txt sort -bd data // 忽略像空格之類的前導空白字符
sort unsort.txt | uniq
sort unsort.txt | uniq -c
sort unsort.txt | uniq -d可指定每行中需要比較的重復內容:-s 開始位置 -w 比較字符數
通用用法
echo 12345 | tr '0-9' '9876543210' //加解密轉換,替換對應字符 cat text| tr '\t' ' ' //制表符轉空格
tr刪除字符
cat file | tr -d '0-9' // 刪除所有數字
-c 求補集
cat file | tr -c '0-9' //獲取文件中所有數字 cat file | tr -d -c '0-9 \n' //刪除非數字數據
tr壓縮字符
tr -s 壓縮文本中出現的重復字符;最常用於壓縮多余的空格
cat file | tr -s ' '
字符類
tr中可用各種字符類:
alnum:字母和數字
alpha:字母
digit:數字
space:空白字符
lower:小寫
upper:大寫
cntrl:控制(非可打印)字符
print:可打印字符
使用方法:tr [:class:] [:class:]
eg: tr '[:lower:]' '[:upper:]'
cut -f2,4 filename
cut -f3 --complement filename
cat -f2 -d";" filename
cut -c1-5 file //打印第一到5個字符 cut -c-2 file //打印前2個字符
將兩個文本按列拼接到一起;
cat file1 1 2 cat file2 colin book paste file1 file2 1 colin 2 book
默認的定界符是制表符,可以用-d指明定界符
paste file1 file2 -d ","
1,colin
2,book
wc -l file // 統計行數
wc -w file // 統計單詞數
wc -c file // 統計字符數
seg 's/text/replace_text/' file //替換每一行的第一處匹配的text
全局替換
seg 's/text/replace_text/g' file
默認替換後,輸出替換後的內容,如果需要直接替換原文件,使用-i:
seg -i 's/text/repalce_text/g' file
移除空白行:
sed '/^$/d' file
變量轉換
已匹配的字符串通過標記&來引用.
echo this is en example | seg 's/\w+/[&]/g' $>[this] [is] [en] [example]
子串匹配標記
第一個匹配的括號內容使用標記 \1 來引用
sed 's/hello\([0-9]\)/\1/'
雙引號求值
sed通常用單引號來引用;也可使用雙引號,使用雙引號後,雙引號會對表達式求值:
sed 's/$var/HLLOE/'
當使用雙引號時,我們可以在sed樣式和替換字符串中指定變量;
eg: p=patten r=replaced echo "line con a patten" | sed "s/$p/$r/g" $>line con a replaced
其它示例
字符串插入字符:將文本中每行內容(PEKSHA) 轉換為 PEK/SHA
sed 's/^.\{3\}/&\//g' file
awk腳本結構
awk ' BEGIN{ statements } statements2 END{ statements } '
工作方式
1.執行begin中語句塊;
2.從文件或stdin中讀入一行,然後執行statements2,重復這個過程,直到文件全部被讀取完畢;
3.執行end語句塊;
使用不帶參數的print時,會打印當前行;
echo -e "line1\nline2" | awk 'BEGIN{print "start"} {print } END{ print "End" }'
print 以逗號分割時,參數以空格定界;
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \
print var1, var2 , var3; }'
$>v1 V2 v3
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \
print var1"-"var2"-"var3; }'
$>v1-V2-v3
NR:表示記錄數量,在執行過程中對應當前行號;
NF:表示字段數量,在執行過程總對應當前行的字段數;
$0:這個變量包含執行過程中當前行的文本內容;
$1:第一個字段的文本內容;
$2:第二個字段的文本內容;
echo -e "line1 f2 f3\n line2 \n line 3" | awk '{print NR":"$0"-"$1"-"$2}'
awk '{print $2, $3}' file
統計文件的行數:
awk ' END {print NR}' file
累加每一行的第一個字段:
echo -e "1\n 2\n 3\n 4\n" | awk 'BEGIN{num = 0 ;
print "begin";} {sum += $1;} END {print "=="; print sum }'
var=1000
echo | awk '{print vara}' vara=$var # 輸入來自stdin
awk '{print vara}' vara=$var file # 輸入來自文件
awk 'NR < 5' #行號小於5
awk 'NR==1,NR==4 {print}' file #行號等於1和4的打印出來
awk '/linux/' #包含linux文本的行(可以用正則表達式來指定,超級強大)
awk '!/linux/' #不包含linux文本的行
使用-F來設置定界符(默認為空格)
awk -F: '{print $NF}' /etc/passwd
使用getline,將外部shell命令的輸出讀入到變量cmdout中;
echo | awk '{"grep root /etc/passwd" | getline cmdout; print cmdout }'
for(i=0;i<10;i++){print $i;}
for(i in array){print array[i];}
eg:
以逆序的形式打印行:(tac命令的實現)
seq 9| \
awk '{lifo[NR] = $0; lno=NR} \
END{ for(;lno>-1;lno--){print lifo[lno];}
} '
head:
awk 'NR<=10{print}' filename
tail:
awk '{buffer[NR%10] = $0;} END{for(i=0;i<11;i++){ \
print buffer[i %10]} } ' filename
ls -lrt | awk '{print $6}'
ls -lrt | cut -f6
seq 100| awk 'NR==4,NR==6{print}'
awk '/start_pattern/, /end_pattern/' filenameeg:
seq 100 | awk '/13/,/15/' cat /etc/passwd| awk '/mai.*mail/,/news.*news/'
index(string,search_string):返回search_string在string中出現的位置
sub(regex,replacement_str,string):將正則匹配到的第一處內容替換為replacement_str;
match(regex,string):檢查正則表達式是否能夠匹配字符串;
length(string):返回字符串長度
echo | awk '{"grep root /etc/passwd" | getline cmdout; print length(cmdout) }'
printf 類似c語言中的printf,對輸出進行格式化
eg:
seq 10 | awk '{printf "->%4s\n", $1}'
while 循環法
while read line; do echo $line; done < file.txt 改成子shell: cat file.txt | (while read line;do echo $line;done)
awk法:
cat file.txt| awk '{print}'
for word in $line; do echo $word; done
${string:start_pos:num_of_chars}:從字符串中提取一個字符;(bash文本切片)
${#word}:返回變量word的長度
for((i=0;i<${#word};i++))
do
echo ${word:i:1);
done
本文為《linux Shell腳本攻略》的讀書筆記,文中主要內容和示例來自於
《linux
Shell腳本攻略》;