


hadoop的偽分布式模式配置與安裝
上次對hadoop單機模式中已經介紹了hadoop的基本安裝,本次將講解hadoop的偽分布式模式進行對hadoop的基本模擬部署。
安裝軟件:
系統:Linux 2.6.32-358.el6.x86_64
JDK:jdk-7u7-linux-i586.tar.gz
Hadoop版本:hadoop-0.20.2-cdh3u4.tar.gz
硬件環境:
三台主機:分別為
gdy192 192.168.61.192
gdy194 192.168.61.194
gdy195 192.168.61.195
本次部署模型為:
gdy192上部署:NameNode和JobTracker
gdy194上部署:SecondaryNameNode
gdy195上部署:DateNode TaskTracker
首先配置三台主機的hosts文件,以便之後不用ip而直接用別名進行相互訪問
首先在gdy192上配置一份信息。
[root@gdy192 /]#vim /etc/hosts

wq保存退出
將已經配置好的文件分別拷貝一份到其他兩台主機上
拷貝文件到gdy194上
[root@gdy192 ~]#scp /etc/hosts root@gdy194:/etc/
輸入gdy194的root密碼
拷貝成功。
去gdy194上查看/etc/hosts驗證是否是叫我們剛才修改的文件
[root@gdy194 /]#cat /etc/hosts

可以看到拷貝成功。
同樣再次拷貝一份到gdy195
在gdy192上輸入:
[root@gdy192 ~]#scp /etc/hosts root@gdy195:/etc/

這裡就不驗證了。
在gdy192上創建jDK和Hadoop的安裝目錄gd
[root@gdy192 /]#mkdir /usr/gd/ -pv

在gdy194上創建JDK和Hadoop的安裝目錄gd

在gdy195上創建JDK和Hadoop的安裝目錄gd

分別在gdy192,gdy194,gdy195上創建hduser用戶並設置密碼
在gdy192上
[root@gdy192 /]#useradd hduser
[root@gdy192 /]#passwd hduser

在gdy194上
[root@gdy194 /]#useradd hduser
[root@gdy194 /]#passwd hduser

在gdy195上
[root@gdy195 /]#useradd hduser
[root@gdy195 /]#passwd hduser

將之前准備好的軟件包拷貝到gdy192上,
如下圖是我已經拷貝好的文件
將這兩個文件解壓到之前創建的目錄/usr/gd/下面
[root@gdy192ftpftp]# tar -xf jdk-7u7-linux-i586.tar.gz -C /usr/gd/
[root@gdy192ftpftp]# tar -xf hadoop-0.20.2-cdh3u4.tar.gz -C /usr/gd/

使用ls /usr/gd/可以查看解壓後的文件
為jdk和hadoop創建軟鏈接在/usr/gd目錄下面
[root@gdy192ftpftp]# ln -s /usr/gd/jdk1.7.0_07/ /usr/gd/java
[root@gdy192ftpftp]# ln -s /usr/gd/hadoop-0.20.2-cdh3u4/ /usr/gd/hadoop
[root@gdy192ftpftp]# ll /usr/gd/

配置java和hadoop的環境變量
配置java的環境變量
[root@gdy192 /]#vim /etc/profile.d/java.sh

添加如下信息:
JAVA_HOME=/usr/gd/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOMEPATH

wq保存退出
配置hadoop的環境變量
[root@gdy192 /]#vim /etc/profile.d/hadoop.sh

添加如下信息:
HADOOP_HOME=/usr/gd/hadoop
PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_HOMEPATH

wq保存退出
使用scp分別將這兩個文件拷貝到gdy194和gdy195機器上的/etc/profile.d/目錄下面。
拷貝到gdy194上
[root@gdy192 /]#scp /etc/profile.d/java.sh root@gdy194:/etc/profile.d/
[root@gdy192 /]#scp /etc/profile.d/hadoop.sh root@gdy194:/etc/profile.d/

拷貝到gdy195上
[root@gdy192 /]#scp /etc/profile.d/java.sh root@gdy195:/etc/profile.d/
[root@gdy192 /]#scp /etc/profile.d/hadoop.sh root@gdy195:/etc/profile.d/

修改/usr/gd/目錄下的所有文件的屬主和屬組為hduser
[root@gdy192 /]#chown -R hduser.hduser /usr/gd

在gdy192上切換到hduser用戶下面
[root@gdy192 /]#su – hduser
使用ssh-keygen和ssh-copy-id為gdy192能無密碼直接訪問gdy194和gdy195下的hduser用戶
命令:
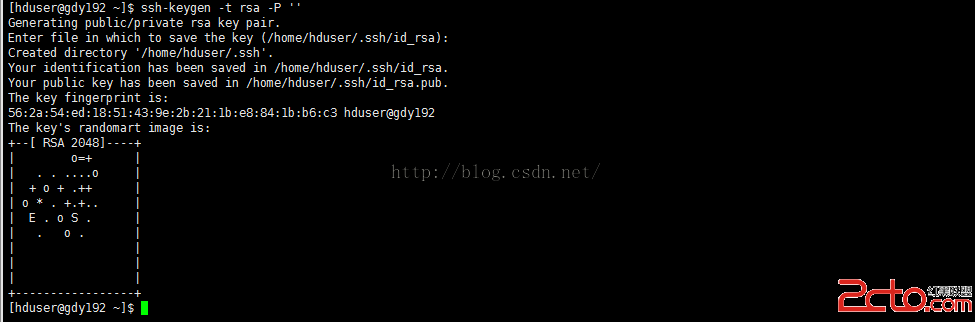
先制作秘鑰文件
[hduser@gdy192 ~]$ssh-keygen -t rsa -P ''

回車
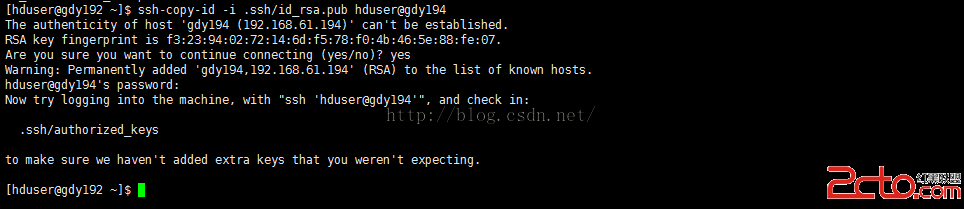
使用ssh-copy-id拷貝生成的公秘到gdy194機器上的hduser下,使gdy192能無密碼訪問gdy194
[hduser@gdy192 ~]$ssh-copy-id -i .ssh/id_rsa.pub hduser@gdy194

輸入yes

輸入gdy194上的hduser的用戶密碼
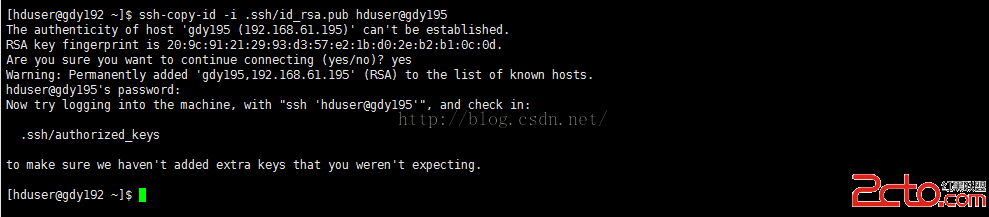
使用ssh-copy-id拷貝生成的公秘到gdy195機器上的hduser下,使gdy192能無密碼訪問gdy195
[hduser@gdy192 ~]$ssh-copy-id -i .ssh/id_rsa.pub hduser@gdy195
使用ssh-copy-id拷貝生成的公秘到gdy192機器上的hduser下,使gdy192能無密碼訪問gdy192
注意:即使是hadoop中使用的是ip進行調度訪問,即使是訪問自己的機器,如果不配置無密碼訪問,訪問時,一樣需要輸入密碼。這裡和之前配置hadoop單機模式時一樣。需要配置無密碼訪問。
[hduser@gdy192 ~]$ssh-copy-id -i .ssh/id_rsa.pub hduser@gdy192

驗證gdy192是否已經不用輸密碼自己訪問gdy194
[hduser@gdy192 ~]$ssh gdy194 'date'
能不需要輸入密碼就顯示gdy194上的日期,則證明配置成功。
驗證gdy192是否已經不用輸密碼自己訪問gdy195
[hduser@gdy192 ~]$ssh gdy195 'date'
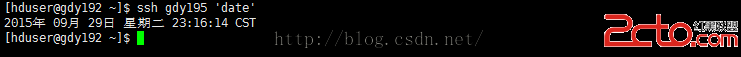
驗證gdy192是否已經不用輸入訪問自己gdy192
[hduser@gdy192 ~]$ssh gdy192 'date'

查看三台機器上的系統世界是否一樣
[hduser@gdy192 ~]$ssh gdy194 'date';ssh gdy195 'date';ssh gdy192 'date'
同步三個節點上的時間:
注意:這裡由於hadoop沒有權限修改時間,需要配置root能無密碼訪問gdy194和gdy195,gdy192。然後在統一設定時間。或者你自己設計其他方法保證時間同步。不過,時間同步在正在部署的環境上是必須要有的。如果這步你不配置,對於本次的hadoop偽分布式模式也沒有多大影響。不過建議還是配置下。
配置代碼如下。
[hduser@gdy192 ~]$exit
先退出hduser用戶
[root@gdy192 /]#cd ~
進入root用戶的家目錄
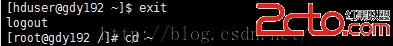
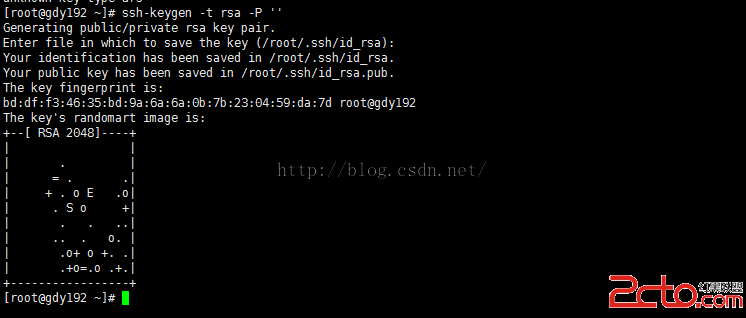
制作秘鑰文件
[root@gdy192 ~]#ssh-keygen -t rsa -P ''
拷貝秘鑰文件到gdy194,gdy195
[root@gdy192 ~]# ssh-copy-id -i.ssh/id_rsa.pub root@gdy194
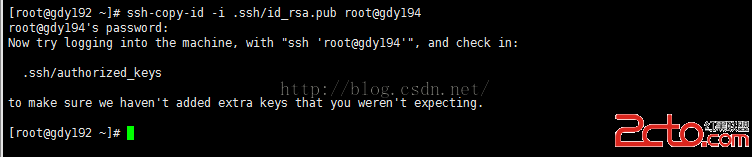
[root@gdy192 ~]#ssh-copy-id -i .ssh/id_rsa.pub root@gdy195

由於root自己訪問自己,每次都需要確認一次yes,所以用root用戶配置無密碼訪問自己沒有用。再說這裡的配置只是為了完成三台電腦的時間同步。
先檢查三台電腦的時間:
[root@gdy192 ~]#ssh gdy194 'date';ssh gdy195 'date';date

將三台電腦的時間設為同一時間:
[root@gdy192 ~]#ssh gdy194 'date 0929235415';ssh gdy195 'date 0929235415';date 0929235415

再次查看時間
[root@gdy192 ~]#ssh gdy194 'date';ssh gdy195 'date';date

可以看到這裡的時間就已經同步了。
用gdy192切換到hduser用戶下
[root@gdy192 ~]#su - hduser
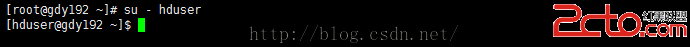
再來查看三台電腦的時間:
[hduser@gdy192 ~]$ssh gdy194 'date';ssh gdy195 'date';ssh gdy192 date

接下來就要開始配置hadoop的配置文件了
進程hadoop的文件目錄裡面
[hduser@gdy192hadoop]$ cd /usr/gd/hadoop/conf/
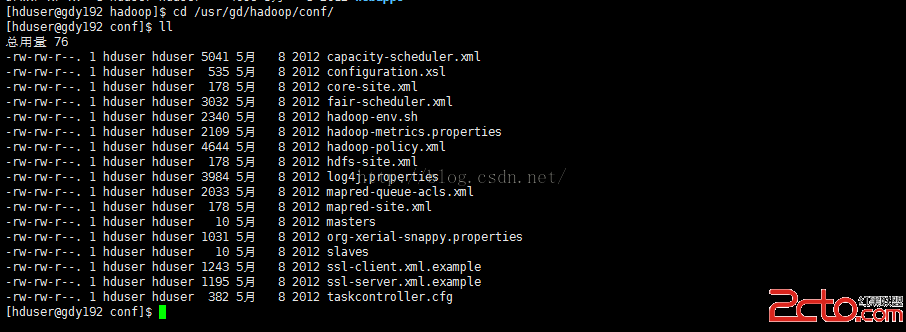
由於在hadoop單機模式配置裡面已經對重要文件做個解釋。這裡不再重復解釋,詳情請見日志《hadoop的單機模式配置與安裝》
編輯masters文件
[hduser@gdy192conf]$ vim masters
將原來的localhost修改為gdy194

wq保存退出
注意:在上面就已經說明gdy194是用來做SecondaryNameNode的名稱節點的。
而masters就是配置第二名稱節點的。
編輯slaves文件
[hduser@gdy192conf]$ vim slaves
將原來的localhost修改為gdy195

wq保存退出
同樣這裡定義的是數據節點。
編輯文件core-site.xml
[hduser@gdy192conf]$ vim core-site.xml
在
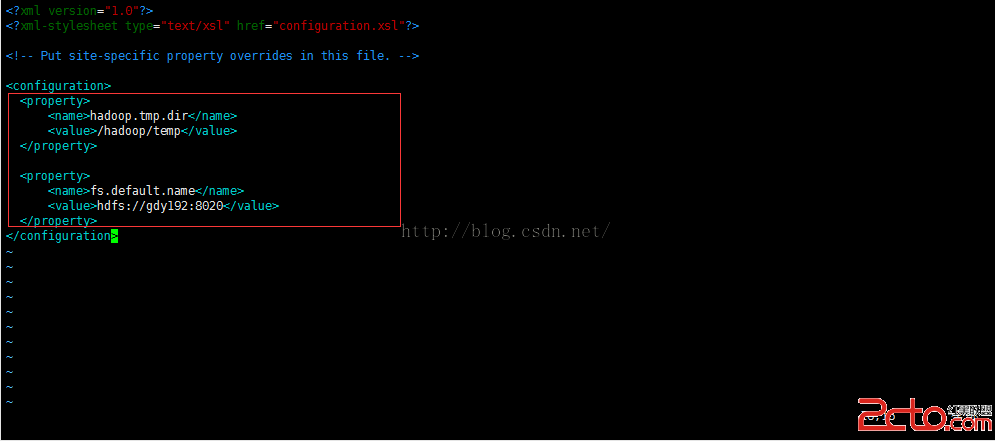
wq保存退出
注意:這裡的fs.default.name定義的是主節點。由於每個節點上配置文件都一樣,所以這裡要使用ip或者別名來定義主節點的位置。
由於這裡定義了一個hadoop的緩存文件目錄,所以我們需要在三台電腦上分別創建這個緩存文件目錄。
切換到root用戶。
[hduser@gdy192conf]$ su – root

創建/hadoop目錄
[root@gdy192 ~]#mkdir /hadoop/
修改hadoop目錄的屬主和屬主為hduser,讓hduser能在這個目錄下有寫權限。
[root@gdy192 ~]#chown -R hduser.hduser /hadoop
同樣在gdy194和gdy195上創建一個這樣的目錄,並賦予hadoop權限。
在gdy194上
[root@gdy194 /]#mkdir /hadoop
[root@gdy194 /]#chown -R hduser.hduser /hadoop
在gdy195上
[root@gdy195 /]#mkdir hadoop
[root@gdy195 /]#chown -R hduser.hduser /hadoop
使用gdy192
退出當前用戶,返回之前的hduser用戶
[root@gdy192 ~]#exit

注意:這裡由於剛剛是直接登錄,所以現在能退出返回到之前的hduser用戶和hduser操作的目錄下面。
編輯文件 mapred-site.xml
[root@gdy192conf]# vim mapred-site.xml
在
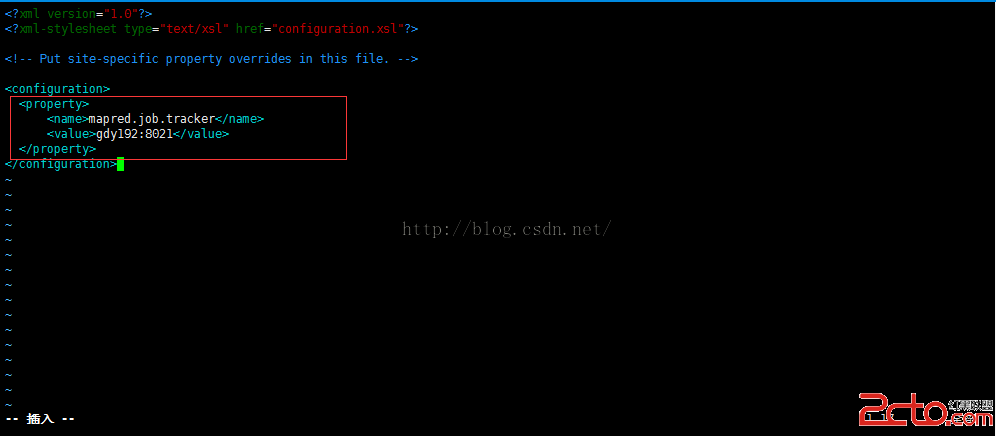
wq保存退出
同樣,由於這裡定義的是JobTracker,而我們上部署就已經說明gdy192上存放jobTracker
所以這裡在單機模式下的localhost就要改成ip或者是ip別名。
編輯文件:hdfs-site.xml
[root@gdy192conf]# vim hdfs-site.xml
在
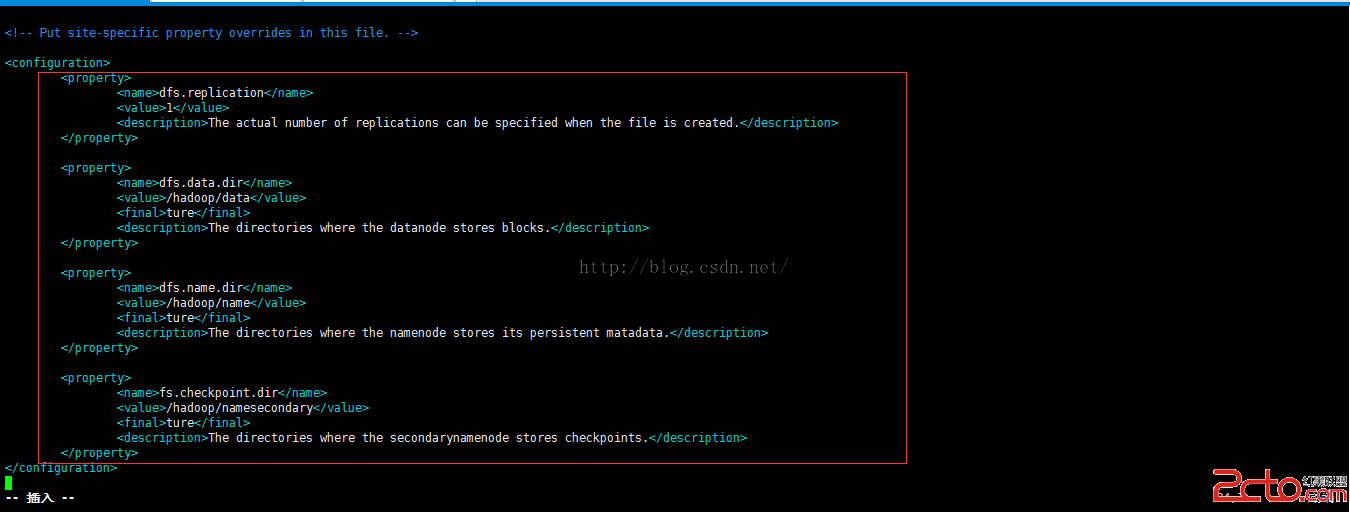
wq保存退出
注意:這裡是跟想象的定義了hadoop中其他目錄的位置,如果這裡不定義,將會默認使用core-site.xml文件裡面定義的默認緩存目錄。
到這裡hadoop的配置文件就已經配置完成了。
接下來分別在gdy194上和gdy195上解壓jdk-7u7-linux-i586.tar.gz和hadoop-0.20.2-cdh3u4.tar.gz軟件包到/etc/gd/文件夾下面。並分別創建連接文件。(向上面之前操作一樣)
這由於重復操作。不再做解釋。
接下來拷貝剛剛在gdy192上已經配置好的文件到gdy194和gdy195的對應位置。
方法如下:
在gdy192上使用root用戶
拷貝文件到gdy194和gdy195上
[hduser@gdy192hadoop]$ scp /usr/gd/hadoop/conf/* gdy194:/usr/gd/hadoop/conf/
[hduser@gdy192 hadoop]$ scp /usr/gd/hadoop/conf/*gdy195:/usr/gd/hadoop/conf/
在gdy194和gdy195上分別使用root用戶給予/usr/gd/hadoop文件夾賦予hduser用戶權限。
在gdy194上
[root@gdy194 /]#chown hduser.hduser /usr/gd/ -R
[root@gdy194 /]#ll /usr/gd/

在gdy195上
[root@gdy195 /]#chown hduser.hduser /usr/gd/ -R
[root@gdy195 /]#ll /usr/gd/

到這裡hadoop的偽分布式模式已經全部配置完成。
啟動hadoop偽分布式模式
使用gdy192主機。重新登錄root用戶
切換到hduser用戶

格式化hadoop的文件系統HDFS
[hduser@gdy192 ~]$hadoop namenode -format
啟動hadoop
[hduser@gdy192 ~]$start-all.sh

這裡已經看到gdy192上成功啟動了NameNode和JobTracker兩個節點
查看gdy194上是否已經成功啟動SecondaryNameNode
[hduser@gdy192 ~]$ssh gdy194 'jps'

看到已經成功啟動
查看gdy195上是否已經成功啟動DataNode和TaskTracker
[hduser@gdy192 ~]$ssh gdy195 'jps'
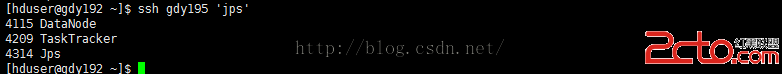
到這裡已經看到都成功啟動
使用
[hduser@gdy192 ~]$netstat –nlpt
可以查看hadoop的端口
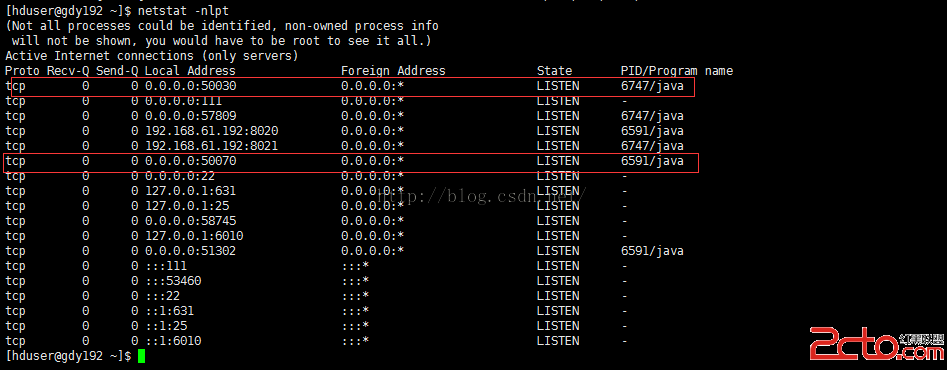
其中50030端口為hadoop的對外web網址端口。可以查看hadoop的MapReduce作業的相關信息
50070為hadoop的Namenode節點信息。
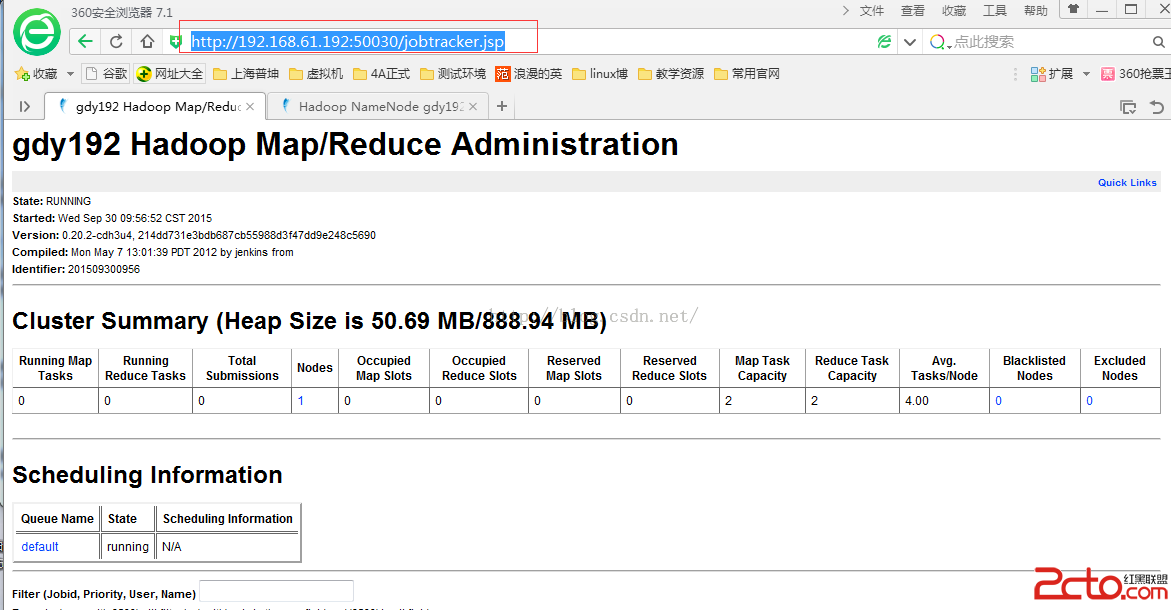
查看hadoop的MapReduce作業信息
可以在浏覽器上訪問:http://192.168.61.192:50030/jobtracker.jsp
如下圖:
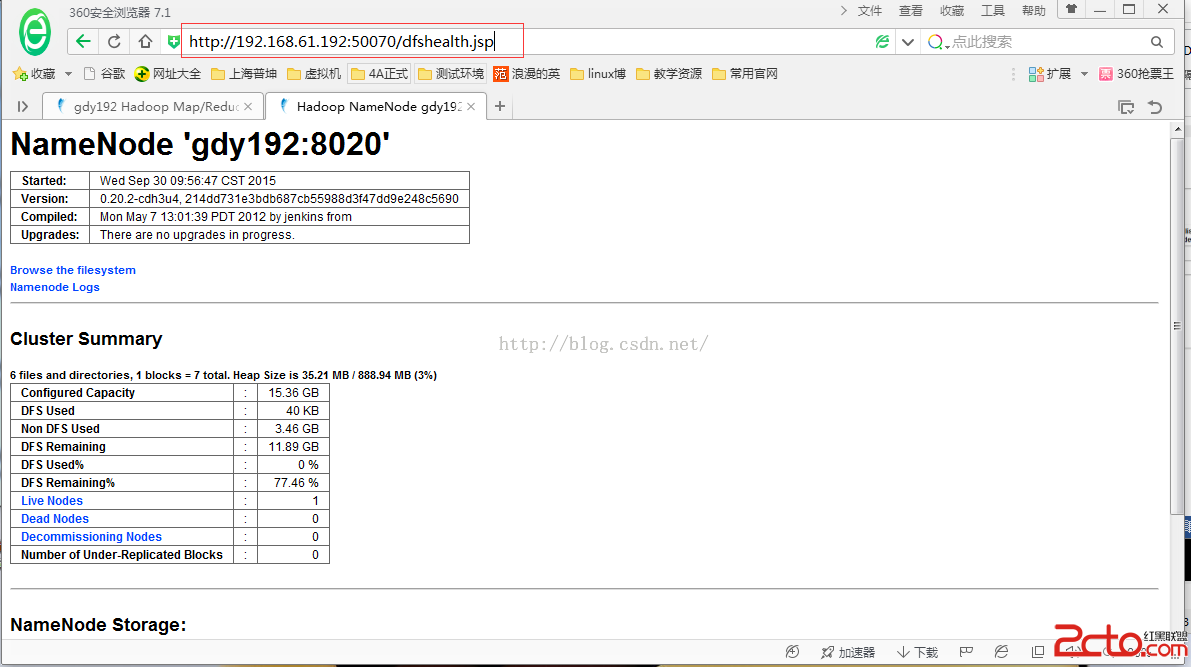
查看hadoop的NameNode節點信息
可以在浏覽器上訪問:http://192.168.61.192:50070/dfshealth.jsp
如下圖:
由於SecondaryNameNode部署在gdy194上。
查看gdy194上的Hadoop的進程端口信息。
[hduser@gdy192 ~]$ssh gdy194 'netstat -nlpt'
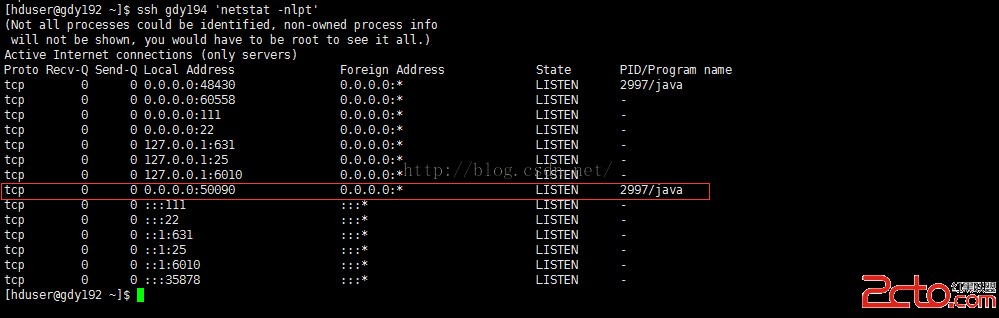
其中50090端口為hadoop的SecondaryNameNode的web對外端口
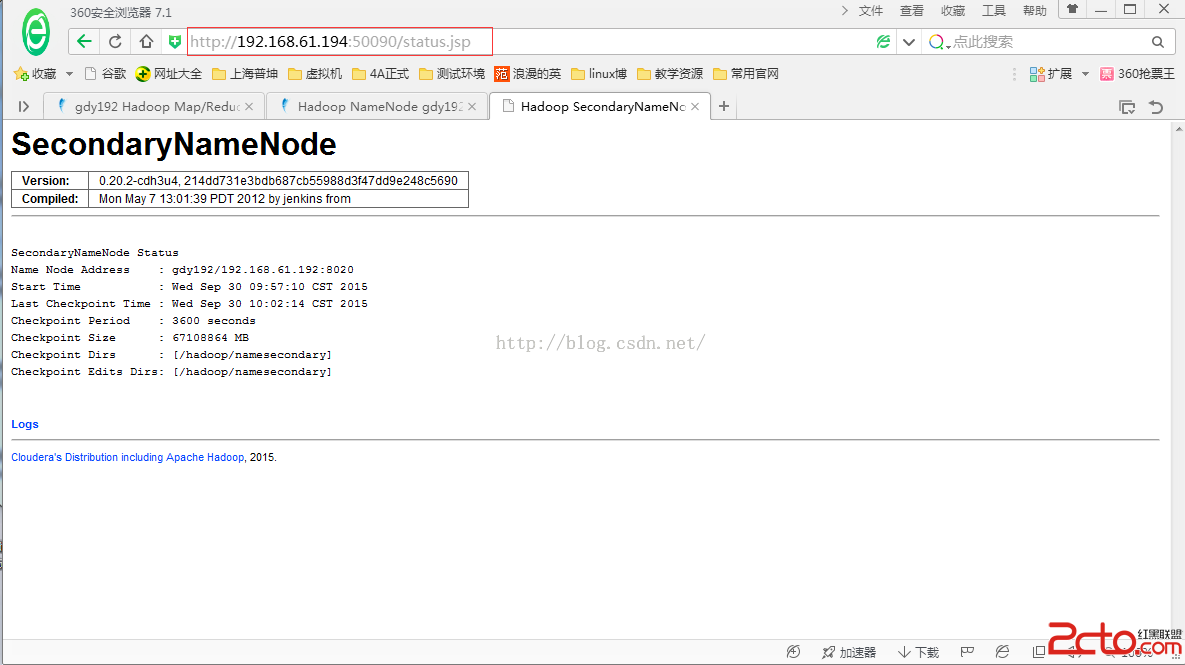
可以使用:http://192.168.61.194:50090/status.jsp
來訪問SecondaryNameNode的對外web端口。
同樣,由於DataNode和TaskTracker部署在gdy195上。
在gdy192上查看gdy195上的端口信息
[hduser@gdy192 ~]$ssh gdy195 'netstat -nlpt'
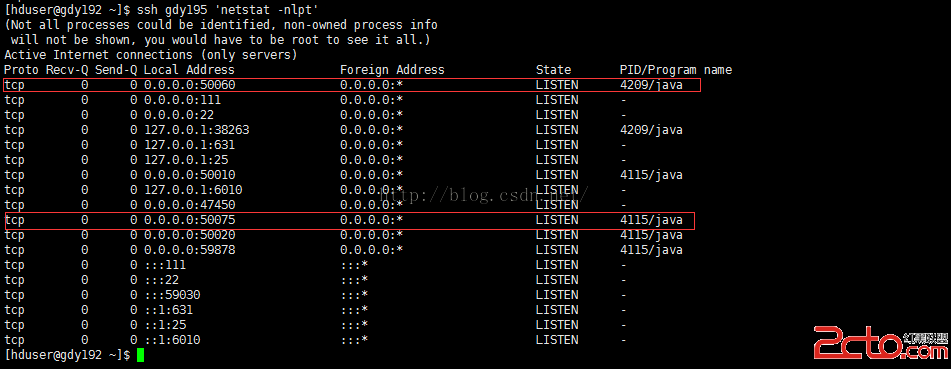
50060為hadoop的TaskTracker的節點信息
50075為hadoop的DateNoe的節點信息
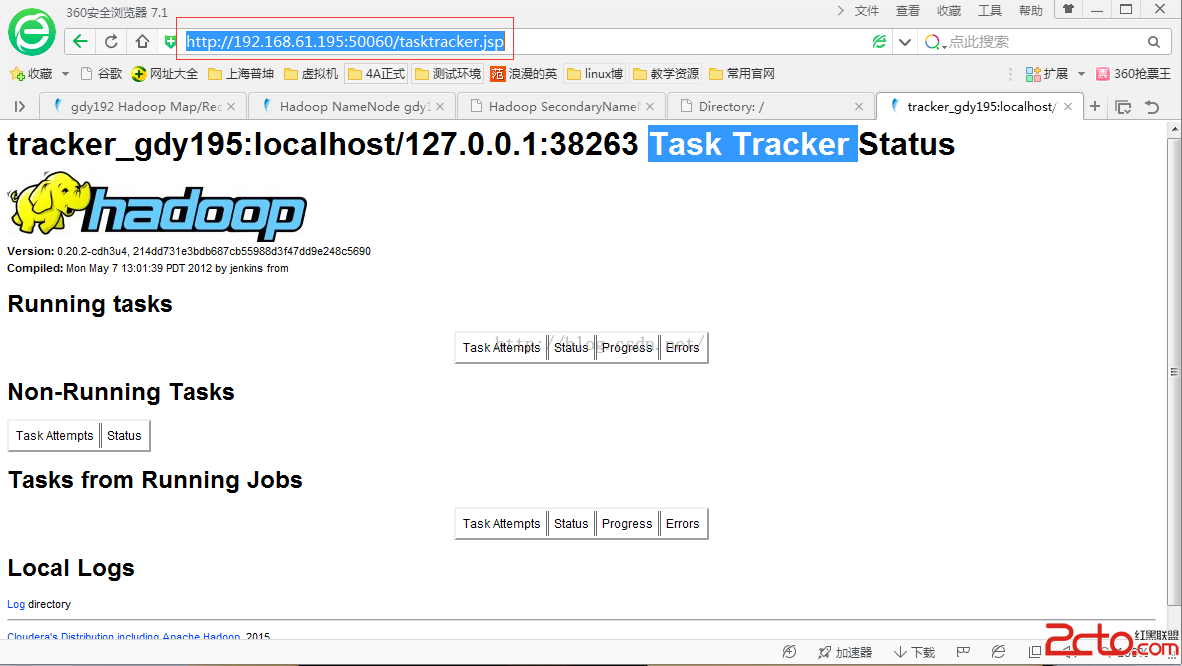
分別通過以下地址可訪問:
http://192.168.61.195:50075/
http://192.168.61.195:50060/tasktracker.jsp
注意:在實際部署中以上web的訪問端口前的ip地址為你實際部署的ip地址,這裡我是按照我自己部署的ip地址列舉出來的。
在hadoop上做一次hadoop的單詞統計
使用機器gdy192
在hadoop的DNSF文件系統上新建一個text文件夾

查看已經建立好的文件夾
[hduser@gdy192 ~]$hadoop fs -ls /

上傳一個系統文件到test文件夾下
[hduser@gdy192 ~]$hadoop fs -put /etc/hosts /test

查看已經上傳的文件
[hduser@gdy192 ~]$hadoop fs -ls /test

對hadoop目錄中的test所有文件做單詞統計,統計結果輸出在word文件夾下
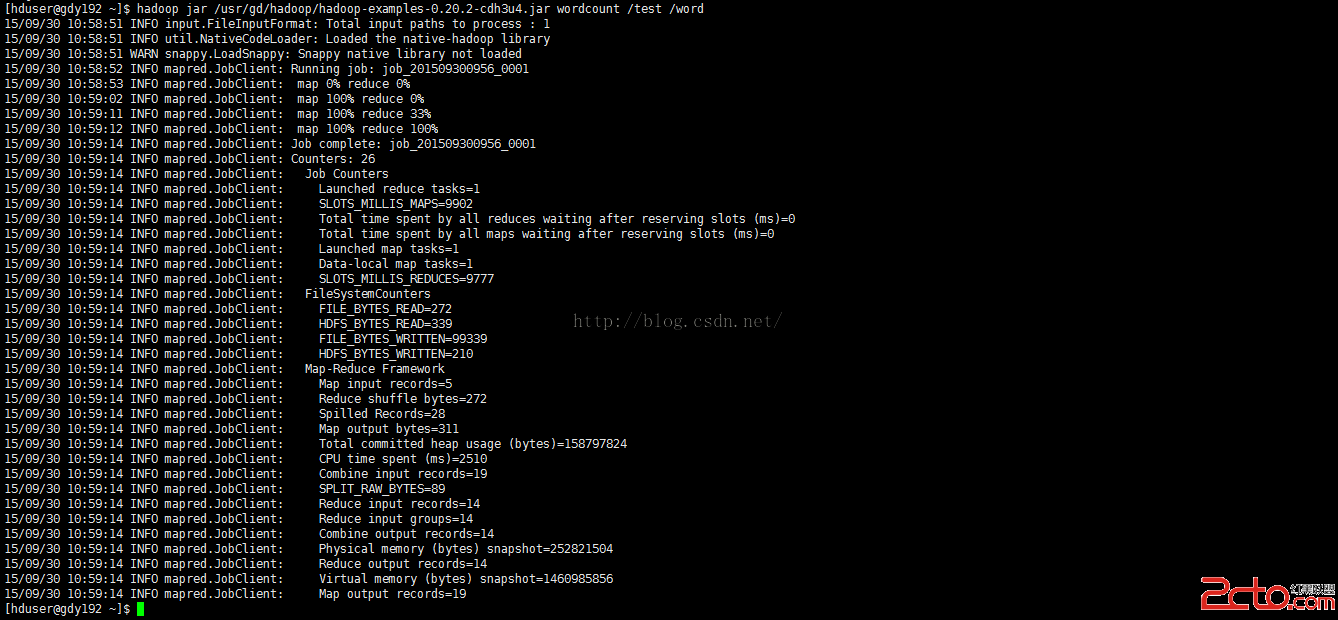
[hduser@gdy192 ~]$hadoop jar /usr/gd/hadoop/hadoop-examples-0.20.2-cdh3u4.jar wordcount /test /word
在這個過程中可以通過
http://192.168.61.192:50030/jobtracker.jsp來查看作業進行的情況。
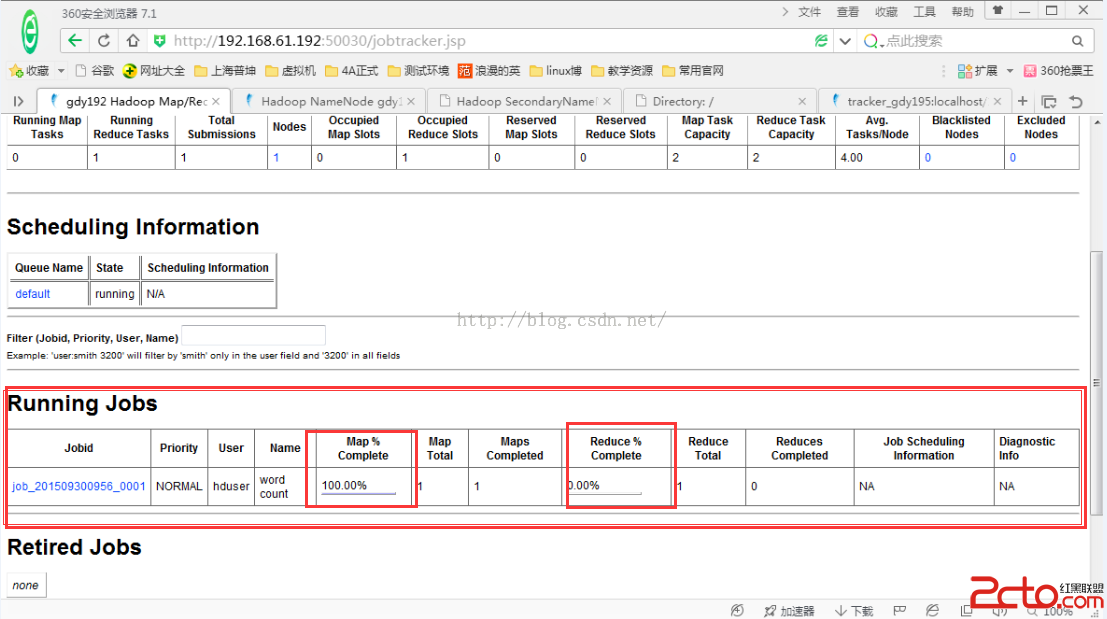
下圖就是剛剛執行的作業完成後的顯示
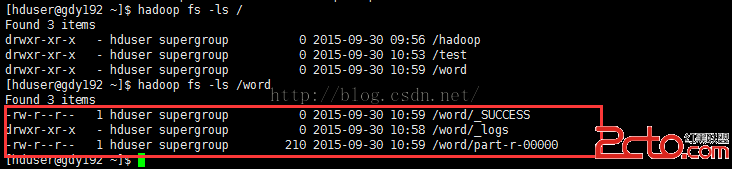
查看單詞統計結果輸出目錄
[hduser@gdy192 ~]$hadoop fs -ls /word
查看結果輸出文件part-r-00000可以看到剛才對test目錄下的文件做單詞統計的統計結果
[hduser@gdy192 ~]$hadoop fs -cat /word/part-r-00000
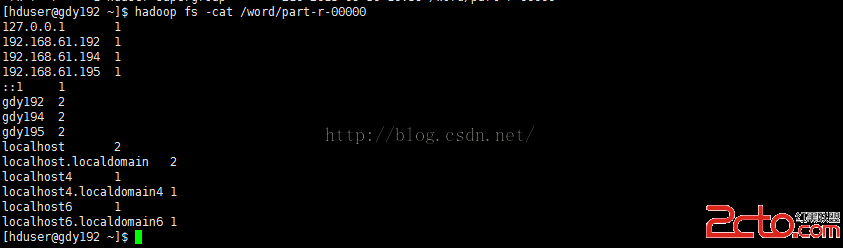
這就是剛才統計的的統計結果。
到本文檔位置hadoop的單機模式和hadoop的偽分布模式安裝和部署就已經完成了。
其實hadoop的單獨安裝後一般都會再安裝hbase來原理hadoop。這樣好方便存儲數據,和管理。對於在hadoop的單機模式上怎麼部署hbase和在hadoop的偽分布式模式下如何部署hbase。將在之後陸續公布。