淺談linux性能調優之三:分區格式化之前的考慮
有這麼一種特殊情況可能在生產環境下發生:系統的某個ext3文件分區,當用戶往此分區上寫文件時,提示磁盤空間已滿,但用df -h命令查 看時發現此分區磁盤使用量是60%,請分析出現這種情況是由什麼導致的,答案是inode已經耗盡!
為什麼呢 ?
給出一個ext*文件系統的結構圖
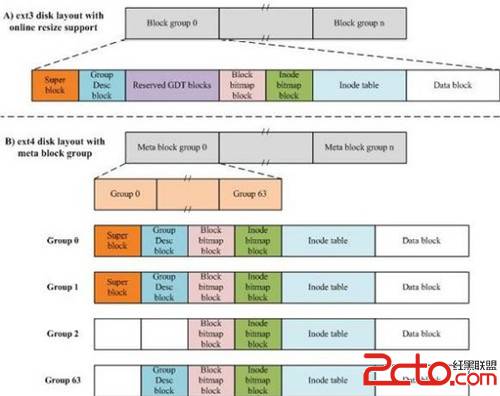
在Linux中進行格式化必須考慮Block與inode,Block還好理解,它是磁盤可以記錄的最小單位,是由數個扇區組成,所以大小通常為n*512Bytes,例如4K。 那麼inode是什麼呢 ? Block是記錄文件內容的區域,inode則是記錄該文件的屬性及其放置在哪個Block之內的信息。每個inode分別記錄一個檔案的屬性與這個檔案分布在哪些datablock上(也就是我們說的指針,有的地方也叫索引編號)。
具體如下:
● inode 編號 ● 用來識別文件類型,以及用於 stat C 函數的模式信息 ● 文件的鏈接數目 ● 屬主的 UID ● 最近一次訪問的時間 ● 屬主的組 ID(GID) ● 文件的大小 ● 文件所使用的磁盤塊的實際數目 ● 最近一次修改的時間 ● 最近一次更改的時間
小結:inode兩個功能:記錄檔案屬性和指針所以,每個文件都會占用一個inode。當Linux系統要查找某個文件時,它會先搜索inode table找到這個文件的屬性及數據存放地點,然後再查找數據存放的Block進而將數據取出。一個分區被格式化為一個文件系統之後,基本上它一定會有inode table與數據區域兩大塊,一個用來記錄文件的屬性信息與該文件存放的Block塊,一個用來記錄文件的內容。
一個邏輯上的概念: 一個block對應一個inode嗎? 答案是否定的,一個大文件雖然占用很多的block,但是只使用了一個inode
測試1: 我添加磁盤並劃分分區,/dev/sdb5,6,7各100M 並指定block大小分別是1k,2k,4k格式化時得到結構inode數量都是28000多 (-b)
結論:inode和block沒有直接關系!網上有一種說說“block越大,inode越小的說法”顯然錯誤
測試2: 我使用-i 選項格式化 (-i bytes-per-inode
Specify the bytes/inode ratio. mke2fs creates an inode for every bytes-per-inode bytes of space on the disk. The larger the bytes-per-inode ratio, the fewer inodes will be created. This value generally shouldn’t be smaller than the blocksize of the filesystem, since in that case more inodes would be made than can ever be used. Be warned that it is not possible to expand the number of inodes on a filesystem after it is created, so be careful deciding the correct value for this parameter.
)
結論:指定i越小,inode越大,注意這還是和block沒關系!只是用戶自定義inode數量而已!
注意:一個文件占用一個inode,但是至少占用一個block,不管block數量有多大,1K,2K,4K,文件小於blocksize時,占用一個block,此block的剩余空間別的文件無法使用!若文件大於blocksize時,直接使用多個block
於是,就有了最終結論:(當然這裡不是細算!)
分區總量/block大小 >= inode數 ------ > 能創建的文件數量的最大值 = inode數
分區總量/block大小 < inode數 --------> 能創建的文件數量的最大值 = 分區總量/block大小的數量個文件
若分區是提供給給大文件應用,一般不做考慮
相反,若分區是提供給小文件應用,則一定要自己計算並格式化,以免inode耗盡,磁盤分區卻未使用完
*******************************************************************************
測試1數據:
[root@desktop132 ~]# mkfs.ext3 -b 1024 /dev/sdb5
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
28112 inodes, 112392 blocks
5619 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
[root@desktop132 ~]# mkfs.ext3 -b 2048 /dev/sdb6
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=2048 (log=1)
Fragment size=2048 (log=1)
Stride=0 blocks, Stripe width=0 blocks
28160 inodes, 56210 blocks
2810 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=57671680
4 block groups
16384 blocks per group, 16384 fragments per group
7040 inodes per group
Superblock backups stored on blocks:
16384, 49152
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
[root@desktop132 ~]# mkfs.ext3 -b 4096 /dev/sdb7
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
28128 inodes, 28105 blocks
1405 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=29360128
1 block group
32768 blocks per group, 32768 fragments per group
28128 inodes per group
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done
*******************************************************************************
*******************************************************************************
測試2數據:
[root@desktop132 ~]# mkfs.ext3 -i 1024 /dev/sdb5
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
112448 inodes, 112392 blocks
5619 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
8032 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 31 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@desktop132 ~]# mkfs.ext3 -i 2048 /dev/sdb6
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
56224 inodes, 112420 blocks
5621 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
4016 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 35 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@desktop132 ~]# mkfs.ext3 -i 4096 /dev/sdb7
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
28112 inodes, 112420 blocks
5621 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 37 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
*******************************************************************************


