Sed和AWK入門教程之AWK篇
AWK是一門專門用於文本處理的編程語言.是的,它是編程語言,它的目的僅有文本處理,所以你不能用它寫系統軟件,或者做科學計算(當然,它也能做數學計算),它只能用於文本處理.與sed不同,AWK具有編程語言的特性,有內置函數,有邏輯語句,有輸入輸出語句,其實它看起來很像C語言,只不過所有功能集中於文本處理.
與Sed不同,AWK最強大的功能在於處理結構化的文本,也就是說文本有一定的組織結構的.
命令格式
awk [-F value] [-v var=value] 'program text' [files....]
awk [-F value] [-v var=value] -f program-file [files....]
例如:
[plain]
[alex@alexon:~]$awk '{print}' persons.txt
1011, Alex Perkins, Product, Software Developer
3923, Jimmey Mills, Operation, COO
23934, Kevin Kim, Management, CEO
2321, Chris Paul, UI, Designer
又見cat,呵呵. 更有意義一點的:
[plain]
[alex@alexon:~]$awk -F , -v OFS=: '{print $1, $2, $3, $4}' persons.txt
1011: Alex Perkins: Product: Software Developer
3923: Jimmey Mills: Operation: COO
23934: Kevin Kim: Management: CEO
2321: Chris Paul: UI: Designer
awk能識別文本的結構,還能格式化輸出.
程序的格式
也就是'program text'或者program file中的內容:
BEGIN {actions} /pattern/ {actions} END {actions}
BEGIN是處理文件之前執行的. 中間的叫Body loop.後面的END是處理完結束後執行.
可以用\來實現分行輸入:
BEGIN {action} \
/pattern {action} \
END {action}
如果寫在文件中,則可以像寫C語言那樣寫
program-file.awk:
BEGIN {
actions;
}
/pattern/ {
actions;
}
END {
actions;
}
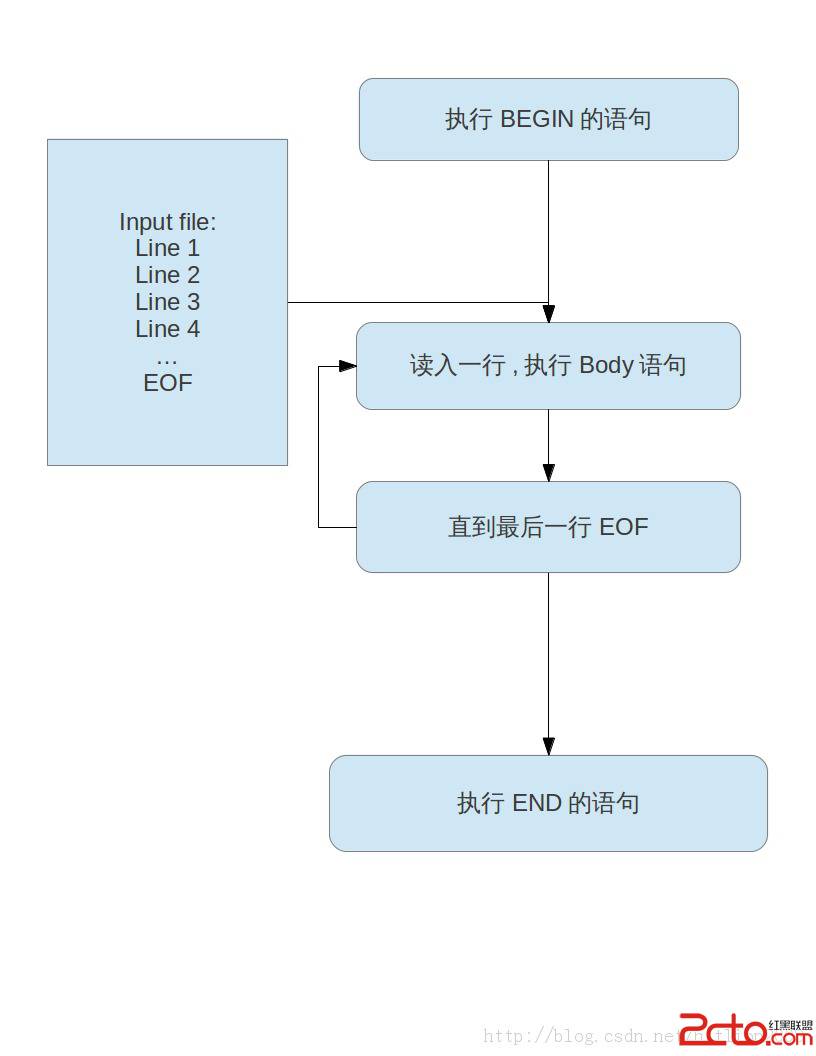
AWK的執行方式,先執行BEGIN段內的內容,然後對文件的每一行,執行body,所有行都處理完後,執行END段.也就是說BEGIN和END都只執行一次,而Body loop要執行很多次,視行數和模式匹配而定,因為要執行多次,所以它叫Body loop.
內置變量
AWK會假定輸入的文本是一個結構化文本,也即是一個表格形式的,每一行是一個記錄(Record),每一列是一個域(Field).AWK讀入時會以結構化方式對文本進行處理,這時就用到了一些內置變量:
FS -- Field Separator 域的分隔符,默認的是以空白符分隔
RS -- Record Separator 記錄的分隔符,默認是以換行符來分隔
FILENAME -- current filename
NF -- Number of Feilds in current record
NR -- Number of Record 輸入的記錄數,相當於行號一樣,多個文件時會接著遞增.
FNR -- File Number of Record 輸入的當前記錄數,每個文件單獨計算
$0 -- the whole record 當前整個記錄
$n -- the nth field of the current record 當前記錄和第n個域
利用這些內置變量,AWK讀入文本後就可以對文本進行處理,以達到分解結構化文本的目的:把輸入變成一個Table形式的結構化信息.
對就的,輸出的時候也有對應的變量來控制輸出的格式:
OFS -- Ouput Field Separator 輸出時的域分隔符
ORS -- Output Record Separator 輸出時的記錄分隔符
語句(actions)
print語句
以字串形式輸出,後面的每個變量都當成是字串.當以逗號分隔時,就用OFS來分隔域,如果以空格分隔時,就以空格來作為OFS:
[plain]
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1,$2,$3,$4}' persons.txt
1011; Alex Perkins; Product; Software Developer
3923; Jimmey Mills; Operation; COO
23934; Kevin Kim; Management; CEO
2321; Chris Paul; UI; Designer
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1 $2 $3 $4}' persons.txt
1011 Alex Perkins Product Software Developer
3923 Jimmey Mills Operation COO
23934 Kevin Kim Management CEO
2321 Chris Paul UI Designer
print不跟參數時,輸出當前的記錄.
printf語句
可以進行與C語言十分類似的格式化輸出.
[plain]
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {printf "%d: ", NR; print $1,$2,$3,$4}' persons.txt
1: 1011; Alex Perkins; Product; Software Developer
2: 3923; Jimmey Mills; Operation; COO
3: 23934; Kevin Kim; Management; CEO
4: 2321; Chris Paul; UI; Designer
程序語言
與C語言十分類似.有運算符,有內置函數,有變量,可以實現十分強大的功能,這部分通常用不到,也不是一篇文章能講的清的,可以參考awk的man文檔或者書籍.推薦<Sed & Awk><Sed and Awk 101 Hacks>
正則表達式
元字符有: ^ $ . [ ] | ( ) * + ?
AWK中的與標准的正則表達式一樣:
位置符:
^ --- 行首
$ ----行尾
. ----任意非換行符'\n'符
\b ---- 一個單詞結尾,單詞定義為一連串的字母或數字,可以單獨放在一端,也可放二端.
限量符
* --- 0或1個或多個
+ --- 1個或多個
? --- 0或1
{m} --- 出現m次
{m,n} --- 出現m次到n次,如{1,5}表示出現1次到5次不等(1,2,3,4,5次)
轉義符
\ --- 可以轉義特殊字符
字符集
[] ---其內的任意字符
[^] --- 匹配任何不在此字符集中的字符
操作符
| ---- 或操作,abc\|123匹配123或者abc
(...) ----組合,形成一個組,主要用於索引
\n ---- 前面第n個組合, /\(123\)\1/ 則匹配123123


