理解Postgres性能
理解Postgres性能
對於很多應用程序開發人員來說數據庫就是一個黑盒子。在數據進進出出之間,開發人員希望它的時間跨度短點。不用成為DBA,這裡有一些可以為大多數應用程序開發人員所理解的數據來幫助他們理解他們的數據庫表現是否足夠好。這篇文章將會提供一些小提示,幫助你判斷是否你的數據庫的性能降低了程序的性能,以及如果那樣的話你該怎麼做。
理解緩存和緩存命中率
對於大多數應用來說典型的判斷規則是哪部分數據是經常訪問的。同其他一樣都服從80/20法則,就是20%的數據占據著80%的讀,並且有時更高。Postgres它會跟蹤你數據的模式並且還會把經常訪問的數據保存到緩存中。一般來說你希望數據庫能夠有99%的緩存命中率。你可以查看緩存命中率:
SELECT
sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
FROM
pg_statio_user_tables;
我們可以這個在 dataclip上顯示 Heroku Postgres的緩存命中率為99.99%。如果你發現比例低於99%,那麼你可能想要考慮增加數據庫的緩存可用性了,你可以在Heroku Postgres上使用 快速提升數據庫性能 或者在像EC2之類的上使用dump/restore組成一個更大的實例來提升性能。
理解索引用途
其它主要提升性能的方式就是索引了。一些框架會為你的主鍵添加索引,但是如果你在其它字段搜索或者大量的聯接時,你可能需要手動添加那樣的索引了。
索引是最有價值的對於大表更是如此。同時從緩存中訪問數據比從磁盤更快,即使數據在內存中可能會變慢因為Postgres必須要解析成百上千的行來確定這是不是它們曾經已處理過的條件。為了得到在你數據庫中表的索引使用時間百分比並且按照表從大到小順序顯示,你可以執行這樣的語句:
SELECT
relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM
pg_stat_user_tables
WHERE
seq_scan + idx_scan > 0
ORDER BY
n_live_tup DESC;
然而這裡沒有最完美的答案,如果在某些地方訪問超過10,000行數據時命中率在99%左右時,你可以考慮添加索引了。當檢查在哪裡添加索引你應該參照你所運行的查詢類型了。一般來說,你應該在使用其它id來查詢或者你經常要過濾的值如created_at字段的地方添加索引。
專業提示:如果你在產品數據庫中使用CREATE INDEX CONCURRENTLY來添加索引的話,請在後台建立索引以及不要持有表鎖。同時創建索引的局限是它一般會多花2-3倍時間來創建並且不會在事務中執行。即使對於任何大型產品網站,這些取捨對您的最終用戶是值得的。
Heroku Dashboard示例
使用最近訪問Heroku dashboard作為現實世界的示例,我們可以運行這樣的查詢語句以及運行結果:
# SELECT relname, 100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used, n_live_tup rows_in_table FROM pg_stat_user_tables ORDER BY n_live_tup DESC;
relname | percent_of_times_index_used | rows_in_table
---------------------+-----------------------------+---------------
events | 0 | 669917
app_infos_user_info | 0 | 198218
app_infos | 50 | 175640
user_info | 3 | 46718
rollouts | 0 | 34078
favorites | 0 | 3059
schema_migrations | 0 | 2
authorizations | 0 | 0
delayed_jobs | 23 | 0
從這裡我們可以看到events表有接近700,000行被使用了但是卻沒有索引。從這裡你可以研究我的應用以及看出一些所使用的通用查詢語句,一個例子就是把博客推送到你那裡。你可以執行EXPLAIN ANALYZE來看你的execution plan,對於特定的查詢語句的性能來說它可以給你更好的主意。
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; QUERY PLAN
-------------------------------------------------------------------
Seq Scan on events (cost=0.00..63749.03 rows=38 width=688) (actual time=2.538..660.785 rows=89 loops=1)
Filter: (app_info_id = 7559)
Total runtime: 660.885 ms
在給定的順序遍歷所有數據這方面使用索引我們可以得到優化。你可以同時添加索引來阻止鎖定表,並且查看性能怎麼樣:
CREATE INDEX CONCURRENTLY idx_events_app_info_id ON events(app_info_id);
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559;
----------------------------------------------------------------------
Index Scan using idx_events_app_info_id on events (cost=0.00..23.40 rows=38 width=688) (actual time=0.021..0.115 rows=89 loops=1)
Index Cond: (app_info_id = 7559)
Total runtime: 0.200 ms
同時在這單一的查詢語句中我們可以看到明顯的改進,我們可以在 New Relic上檢驗這個結果,並且可以看到使用這個索引以及其它一些索引減少了我們在數據庫上所花的時間。
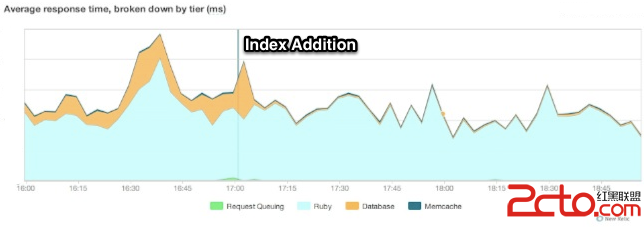
索引緩存命中率
最後兩者結合,如果你對有多少索引在你的緩存中感興趣的話,你可以運行:
SELECT
sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
(sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio
FROM
pg_statio_user_indexes;
一般來說,你應該要求這個達到99%,和你一般緩存命中率一樣。


