


在前面,介紹了一種進程間的通信方式:使用信號,我們創建通知事件,並通過它引起響應,但傳遞的信息只是一個信號值。這裡將介紹另一種進程間通信的方式——匿名管道,通過它進程間可以交換更多有用的數據。
一、什麼是管道
如果你使用過Linux的命令,那麼對於管道這個名詞你一定不會感覺到陌生,因為我們通常通過符號“|"來使用管道,但是管理的真正定義是什麼呢?管道是一個進程連接數據流到另一個進程的通道,它通常是用作把一個進程的輸出通過管道連接到另一個進程的輸入。
舉個例子,在shell中輸入命令:ls -l | grep string,我們知道ls命令(其實也是一個進程)會把當前目錄中的文件都列出來,但是它不會直接輸出,而是把本來要輸出到屏幕上的數據通過管道輸出到grep這個進程中,作為grep這個進程的輸入,然後這個進程對輸入的信息進行篩選,把存在string的信息的字符串(以行為單位)打印在屏幕上。
二、使用popen函數
1、popen函數和pclose函數介紹
有靜就有動,有開就有關,與此相同,與popen函數相對應的函數是pclose函數,它們的原型如下:
#include <stdio.h> FILE* popen (const char *command, const char *open_mode); int pclose(FILE *stream_to_close);
poen函數允許一個程序將另一個程序作為新進程來啟動,並可以傳遞數據給它或者通過它接收數據。command是要運行的程序名和相應的參數。open_mode只能是"r(只讀)"和"w(只寫)"的其中之一。注意,popen函數的返回值是一個FILE類型的指針,而Linux把一切都視為文件,也就是說我們可以使用stdio I/O庫中的文件處理函數來對其進行操作。
如果open_mode是"r",主調用程序就可以使用被調用程序的輸出,通過函數返回的FILE指針,就可以能過stdio函數(如fread)來讀取程序的輸出;如果open_mode是"w",主調用程序就可以向被調用程序發送數據,即通過stdio函數(如fwrite)向被調用程序寫數據,而被調用程序就可以在自己的標准輸入中讀取這些數據。
pclose函數用於關閉由popen創建出的關聯文件流。pclose只在popen啟動的進程結束後才返回,如果調用pclose時被調用進程仍在運行,pclose調用將等待該進程結束。它返回關閉的文件流所在進程的退出碼。
2、例子
很多時候,我們根本就不知道輸出數據的長度,為了避免定義一個非常大的數組作為緩沖區,我們可以以塊的方式來發送數據,一次讀取一個塊的數據並發送一個塊的數據,直到把所有的數據都發送完。下面的例子就是采用這種方式的數據讀取和發送方式。源文件名為popen.c,代碼如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
FILE *read_fp = NULL;
FILE *write_fp = NULL;
char buffer[BUFSIZ + 1];
int chars_read = 0;
//初始化緩沖區
memset(buffer, '\0', sizeof(buffer));
//打開ls和grep進程
read_fp = popen("ls -l", "r");
write_fp = popen("grep rwxrwxr-x", "w");
//兩個進程都打開成功
if(read_fp && write_fp)
{
//讀取一個數據塊
chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp);
while(chars_read > 0)
{
buffer[chars_read] = '\0';
//把數據寫入grep進程
fwrite(buffer, sizeof(char), chars_read, write_fp);
//還有數據可讀,循環讀取數據,直到讀完所有數據
chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp);
}
//關閉文件流
pclose(read_fp);
pclose(write_fp);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
運行結果如下:
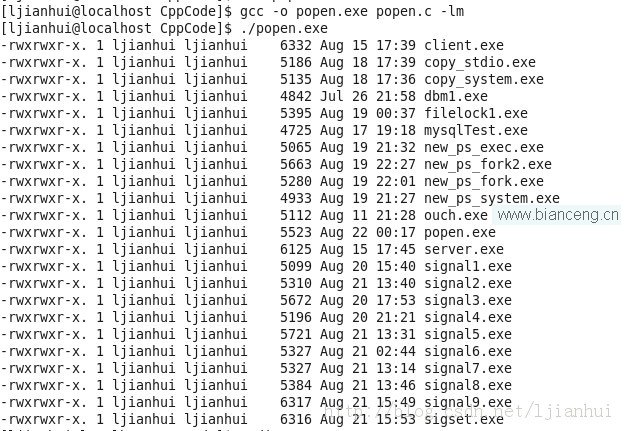
從運行結果來看,達到了信息篩選的目的。程序在進程ls中讀取數據,再把數據發送到進程grep中進行篩選處理,相當於在shell中直接輸入命令:ls -l | grep rwxrwxr-x。
3、popen的實現方式及優缺點
當請求popen調用運行一個程序時,它首先啟動shell,即系統中的sh命令,然後將command字符串作為一個參數傳遞給它。
這樣就帶來了一個優點和一個缺點。優點是:在Linux中所有的參數擴展都是由shell來完成的。所以在啟動程序(command中的命令程序)之前先啟動shell來分析命令字符串,也就可以使各種shell擴展(如通配符)在程序啟動之前就全部完成,這樣我們就可以通過popen啟動非常復雜的shell命令。
而它的缺點就是:對於每個popen調用,不僅要啟動一個被請求的程序,還要啟動一個shell,即每一個popen調用將啟動兩個進程,從效率和資源的角度看,popen函數的調用比正常方式要慢一些。
三、pipe調用
如果說popen是一個高級的函數,pipe則是一個底層的調用。與popen函數不同的是,它在兩個進程之間傳遞數據不需要啟動一個shell來解釋請求命令,同時它還提供對讀寫數據的更多的控制。
pipe函數的原型如下:
#include <unistd.h> int pipe(int file_descriptor[2]);
我們可以看到pipe函數的定義非常特別,該函數在數組中牆上兩個新的文件描述符後返回0,如果返回返回-1,並設置errno來說明失敗原因。
數組中的兩個文件描述符以一種特殊的方式連接起來,數據基於先進先出的原則,寫到file_descriptor[1]的所有數據都可以從file_descriptor[0]讀回來。由於數據基於先進先出的原則,所以讀取的數據和寫入的數據是一致的。
特別提醒:
1、從函數的原型我們可以看到,它跟popen函數的一個重大區別是,popen函數是基於文件流(FILE)工作的,而pipe是基於文件描述符工作的,所以在使用pipe後,數據必須要用底層的read和write調用來讀取和發送。
2、不要用file_descriptor[0]寫數據,也不要用file_descriptor[1]讀數據,其行為未定義的,但在有些系統上可能會返回-1表示調用失敗。數據只能從file_descriptor[0]中讀取,數據也只能寫入到file_descriptor[1],不能倒過來。
例子:
首先,我們在原先的進程中創建一個管道,然後再調用fork創建一個新的進程,最後通過管道在兩個進程之間傳遞數據。源文件名為pipe.c,代碼如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
int data_processed = 0;
int filedes[2];
const char data[] = "Hello pipe!";
char buffer[BUFSIZ + 1];
pid_t pid;
//清空緩沖區
memset(buffer, '\0', sizeof(buffer));
if(pipe(filedes) == 0)
{
//創建管道成功
//通過調用fork創建子進程
pid = fork();
if(pid == -1)
{
fprintf(stderr, "Fork failure");
exit(EXIT_FAILURE);
}
if(pid == 0)
{
//子進程中
//讀取數據
data_processed = read(filedes[0], buffer, BUFSIZ);
printf("Read %d bytes: %s\n", data_processed, buffer);
exit(EXIT_SUCCESS);
}
else
{
//父進程中
//寫數據
data_processed = write(filedes[1], data, strlen(data));
printf("Wrote %d bytes: %s\n", data_processed, data);
//休眠2秒,主要是為了等子進程先結束,這樣做也只是純粹為了輸出好看而已
//父進程其實沒有必要等等子進程結束
sleep(2);
exit(EXIT_SUCCESS);
}
}
exit(EXIT_FAILURE);
}
運行結果為:

可見,子進程讀取了父進程寫到filedes[1]中的數據,如果在父進程中沒有sleep語句,父進程可能在子進程結束前結束,這樣你可能將看到兩個輸入之間有一個命令提示符分隔。
四、把管道用作標准輸入和標准輸出
下面來介紹一種用管道來連接兩個進程的更簡潔方法,我們可以把文件描述符設置為一個已知值,一般是標准輸入0或標准輸出1。這樣做最大的好處是可以調用標准程序,即那些不需要以文件描述符為參數的程序。
為了完成這個工作,我們還需要兩個函數的輔助,它們分別是dup函數或dup2函數,它們的原型如下
#include <unistd.h> int dup(int file_descriptor); int dup2(int file_descriptor_one, int file_descriptor_two);
dup調用創建一個新的文件描述符與作為它的參數的那個已有文件描述符指向同一個文件或管道。對於dup函數而言,新的文件描述總是取最小的可用值。而dup2所創建的新文件描述符或者與int file_descriptor_two相同,或者是第一個大於該參數的可用值。所以當我們首先關閉文件描述符0後調用dup,那麼新的文件描述符將是數字0.
例子
在下面的例子中,首先打開管道,然後fork一個子進程,然後在子進程中,使標准輸入指向讀管道,然後關閉子進程中的讀管道和寫管道,只留下標准輸入,最後調用execlp函數來啟動一個新的進程od,但是od並不知道它的數據來源是管道還是終端。父進程則相對簡單,它首先關閉讀管道,然後在寫管道中寫入數據,再關閉寫管道就完成了它的任務。源文件為pipe2.c,代碼如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
int data_processed = 0;
int pipes[2];
const char data[] = "123";
pid_t pid;
if(pipe(pipes) == 0)
{
pid = fork();
if(pid == -1)
{
fprintf(stderr, "Fork failure!\n");
exit(EXIT_FAILURE);
}
if(pid == 0)
{
//子進程中
//使標准輸入指向fildes[0]
close(0);
dup(pipes[0]);
//關閉pipes[0]和pipes[1],只剩下標准輸入
close(pipes[0]);
close(pipes[1]);
//啟動新進程od
execlp("od", "od", "-c", 0);
exit(EXIT_FAILURE);
}
else
{
//關閉pipes[0],因為父進程不用讀取數據
close(pipes[0]);
data_processed = write(pipes[1], data, strlen(data));
//寫完數據後,關閉pipes[1]
close(pipes[1]);
printf("%d - Wrote %d bytes\n", getpid(), data_processed);
}
}
exit(EXIT_SUCCESS);
}
運行結果為:

從運行結果中可以看出od進程正確地完成了它的任務,與在shell中直接輸入od -c和123的效果一樣。
五、關於管道關閉後的讀操作的討論
現在有這樣一個問題,假如父進程向管道file_pipe[1]寫數據,而子進程在管道file_pipe[0]中讀取數據,當父進程沒有向file_pipe[1]寫數據時,子進程則沒有數據可讀,則子進程會發生什麼呢?再者父進程把file_pipe[1]關閉了,子進程又會有什麼反應呢?
當寫數據的管道沒有關閉,而又沒有數據可讀時,read調用通常會阻塞,但是當寫數據的管道關閉時,read調用將會返回0而不是阻塞。注意,這與讀取一個無效的文件描述符不同,read一個無效的文件描述符返回-1。
六、匿名管道的缺陷
看了這麼多相信大家也知道它的一個缺點,就是通信的進程,它們的關系一定是父子進程的關系,這就使得它的使用受到了一點的限制,但是我們可以使用命名管道來解決這個問題。命名管道將在下一篇文章:Linux進程間通信——使用命名管道中介紹。