


一、什麼是文件
在講述文件操作之前,我們首先要知道什麼是文件。看到這個問題你可能會感覺到可笑,因為對於用過計算機的人來說,文件是最簡單不過的概念了,例如一個文本是一個文件,一個work文檔是一個文件等。但是在Linux中,文件的概念還遠不止於這些,在Linux中,一切(或幾乎一切)都是文件。文件包括很多的內容,例如:大家知道的普通文件是文件,目錄也是一個文件,設備也是一個文件,管道也是一個文件等等。對於目錄、設備這些的操作也可以完全等同於對純文本文件的操作,這也是Linux非常成功的特性之一吧。
二、系統調用
1、文件描述符
文件描述符是一些小數值,你可以通過它們訪問的打開的文件設備,而有多少文件描述符可用取決於系統的配置情況。但是當一個程序開始運行時,它一般會有3個已經打開的文件描述符,就是
0:標准輸入
1:標准輸出
2:標准錯誤
那些數學(即0、1、2)就是文件描述符,因為在Linux上一切都是文件,所以標准輸入(stdin),標准輸出(stdout)和標准錯誤(stderr)也可看作文件來對待。
2、系統調用常用函數
A、open系統調用
open函數的原型為:
int open(const char *path, int oflags);
int open(const char *path, int oflags, mode_t mode);
path,是包括路徑的完整文件名,oflags是文件訪問模式(即是什麼方式打開文件,只讀、只寫還是可讀並可寫等),mode用於設定文件的訪問權限。具體的可選參數,可以自己查看手冊頁,這裡不一一詳述。
open建立了一條到文件或設備的訪問路徑,如果調用成功,返回一個可以被read、write等其他系統調用的函數使用的文件描述符,而且這個文件描述是唯一的,不與任何其他運行中的進程共享,在失敗時返回-1,並設置全局變量errno來指明失明的原因。
B、write系統調用
write函數的原型為:
size_t write(int fildes, const void *buf, size_t nbytes);
write的作用是把緩沖區buf的前nbytes個字節寫入到文件描述符fildes關聯的文件中,返回實際寫入的字節數。返回0表示沒有寫入任何數據,返回-1表示調用中出現了錯誤,錯誤代碼保存在errno中。
注:fildes一定要是在open調用中返回的創建的文件描述符,或者是0、1、2等標准輸入、輸出或標准錯誤。
C、read系統調用
read函數的原型為:
size_t read(int fildes, void *buf, size_t nbytes);
read系統調用的作用是從與文件描述符相關的文件裡讀入nbytes個字節的數據,並把它們放到數據區buf中,返回讀入的字節數,失敗時返回-1。
D、close系統調用
close調用的函數原型為:
int close(int fildes);
close函數的作用是終於文件描述符fildes一其對應的文件之間的關聯。
E、例子
說了這麼多,我就給出一個完整的例子吧,就是從一個數據文件(裡面有1M個‘0’字符)逐個復制到別一個文件。文件名為copy_system.c,代碼如下:
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
char c = '\0';
int in = -1, out = -1;
//以只讀方式打開數據文件
in = open("Data.txt", O_RDONLY);
//以只寫方式創建文件,如果文件不存在就創建一個新的文件
//文件屬主具有讀和寫的權限
out = open("copy_system.out.txt", O_WRONLY|O_CREAT, S_IRUSR|S_IWUSR);
while(read(in, &c, 1) == 1)//讀一個字節的數據
write(out, &c, 1);//寫一個字節的數據
//關閉文件描述符
close(in);
close(out);
return 0;
}
三、標准I/O庫
有過C編程經歷的人都會知道stdio頭文件,它就是C語言的標准IO庫,在標准IO庫中,與底層文件描述符相對應的是流,它被實現為指向結構FILE的指針。IO庫的函數有很多,為了與前面的內容對應,這裡還是只講與前面四個函數相對應的函數,其他的函數,你可以查一查手冊頁。
A、fopen庫函數
fopen庫函數的原型為:
FILE* fopen(const char *filename, const char *mode);
它與底層系統調用open類似,成功時返回一個非空指針。失敗時返回NULL。
B、fread庫函數
fread庫函數的原型為:
size_t fread(void *ptr, size_t size, size_t nitems, FILE *stream);
它與底層調用read相似,其作用是從stream讀取nitems個長度為size的數據到ptr所指向的緩沖區中。返回值是成功讀到緩沖區中的記錄個數。
注:stream為用fopen函數返回的文件結構指針。
C、fwrite庫函數
fwrite庫函數的原型:
size_t fwrite(const void *ptr, size_t size, size_t nitems, FILE *stream);
它與底層調用write相似,其作用是從ptr指向的緩沖區中讀取nitems個長度為size到數據,並把它們寫到stream所對應的文件中。
D、fclose庫函數
fclose庫函數的原型為:
int fclose(FILE *stream);
它與系統調用close相似,其作用是關閉指定的文件流stream。
例子
同樣地,下面是前一個例子的另一個實現版本,它實現的功能與先前的例子一樣,不過使用的是標准I/O庫,而不是系統調用,文件名為copy_stdio.c代碼如下:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int c = 0;
FILE *pfin = NULL;
FILE *pfout = NULL;
//以只讀方式打開數據文件
pfin = fopen("Data.txt", "r");
//以只寫方式打開復制的新文件
pfout = fopen("copy_stdio.out.txt", "w");
while(fread(&c, sizeof(char), 1, pfin))//讀數據
fwrite(&c, sizeof(char), 1, pfout);//寫數據
//關閉文件流
fclose(pfin);
fclose(pfout);
return 0;
}
當然這裡你也可以用其他的庫函數來完成工作,如:用fgetc代替fread,用fputc代替fwrite等。
四、文件描述符和文件流的關系
每個文件流都對應一個底層文件描述符,你可以把底層輸入輸出操作與高層文件流操作混合使用,但是一般不要這樣做,因為數據緩沖的後果難以預料。我們可以通過調用fileno函數(原型為:int fileno(FILE *stream))來確定文件流使用的底層文件描述符,它返回指向文件流的文件描述符。相反地,你可以通過調用函數fdopen(原型為FILE* fdopen(int fildes, const char* mode))來在一個已經打開的文件描述符上創建一個新的文件流,mode參數與fopen函數的完全一樣,同時它必須符合該文件在最初打開時所設定的訪問模式。
但是在Linux下的編程,系統調用用得比較多一些,因為很多時候系統調用能提供更多的靈活性和更加強大的功能,有些操作是一定要使用系統調用,例如,創建文件讀寫鎖時就一定要使用系統調用。
五、系統調用與標准I/O的性能比較
就拿本例子中的代碼來比較,兩個例子編譯後生成的可執行文件的文件名分別為:copy_system.exe和copy_stdio.exe,在Linux下用time命令來測試其運行時間如下:
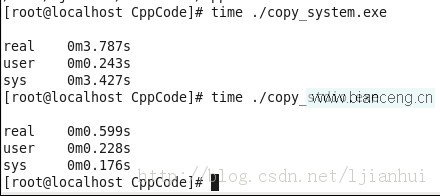
從測試結果可以看出,系統調用的效率比庫函數要低很多。為什麼呢?
因為使用系統調用會影響系統的性能。與函數調用相比,系統調用時,Linux必須從運行用戶代碼切換到執行內核代碼,然後再返回用戶代碼,所以系統調用的開銷要比普通函數調用大一些。然而也是有辦法減少這種開銷的,就是在程序中盡量減少系統調用的的次數,並且讓每次系統調用完成盡量多的工作。
而庫函數為什麼做同樣的事情效率卻會高這麼多呢?這是因為庫函數在數據滿足數據塊長度(或buffer長度)要求時才安排執行底層系統調用,從而減少了系統調用的次數,也讓每次的系統調用做了盡量多的事情,所以效率就比較高。
六、提高系統調用的簡單方法舉例
用回每一個例子(coy_system.c)的代碼,略加修改就能提高我們的效率,例如一次讀1024個字節,修改後保存文件名為copy_system2.c,代碼如下:
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
char buff[1024];
int in = -1, out = -1;
int nread = 0;
in = open("Data.txt", O_RDONLY);
out = open("copy_system2.out.txt", O_WRONLY|O_CREAT, S_IRUSR|S_IWUSR);
//一次讀寫1024個字節
while((nread = read(in, buff, sizeof(buff))) > 0)
write(out, buff, nread);
close(in);
close(out);
return 0;
}
生成的可執行文件為copy_system2.exe,使用time命令查看其執行時間,如下:
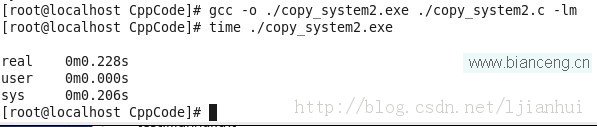
比較下可以看出,其性能改善了一個數量級,其效率甚至比用庫函數一個一個字符復制來來得高效,至少在我的機子上是這樣。