動機
TCMalloc要比glibc 2.3的malloc(可以從一個叫作ptmalloc2的獨立庫獲得)和其他我測試過的malloc都快。ptmalloc在一台2.8GHz的P4機 器上(對於小對象)執行一次malloc及free大約需要300納秒。而TCMalloc的版本同樣的操作大約只需要50納秒。malloc版本的速度 是至關重要的,因為如果malloc不夠快,應用程序的作者就很有可能在malloc之上寫一個自己的自由列表。這就可能導致額外的代碼復雜度,以及更多 的內存占用――除非作者本身非常仔細地劃分自由列表的大小並經常從自由列表中清除空閒的對象。
TCMalloc也減少了多線程程序中的鎖爭用情況。對於小對象,幾乎已經達到了零爭用。對於大對象,TCMalloc嘗試使用粒度較好和有效的自旋鎖。 ptmalloc同樣是通過使用每線程各自的場地來減少鎖爭用,但是ptmalloc2使用每線程場地有一個很大的問題。在ptmalloc2中,內存可 能會從一個場地移動到另一個。這有可能導致大量空間被浪費。例如,在一個Google的應用中,第一階段可能會為其URL標准化的數據結構分配大約 300MB內存。當第一階段結束後,第二階段將從同樣的地址空間開始。如果第二個階段被安排到了一個與第一階段什?用的場地不同的場地,這個階段不會復用 任何第一階段留下的的內存,並會給地址空間添加另外一個300MB。類似的內存爆炸問題也可以在其他的應用中看到。
TCMalloc的另一個好處是小對象的空間最優表現形式。例如,分配N個8字節對象可能要使用大約8N * 1.01字節的空間。即,多用百分之一的空間。而ptmalloc2中每個對象都使用了一個四字節的頭,(我認為)並將最終的尺寸規整為8字節的倍數,最 後使用了16N字節。
使用
要使用TCMalloc,只要將tcmalloc通過“-ltcmalloc”鏈接器標志接入你的應用即可。
你也可以通過使用LD_PRELOAD在不是你自己編譯的應用中使用tcmalloc:
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"
LD_PRELOAD比較討巧,我們也不十分推薦這種用法。
TCMalloc還包含了一個堆檢查器以及一個堆測量器。
如果你更想鏈接不包含堆測量器和檢查器的TCMalloc版本(比如可能為了減少靜態二進制文件的大小),你可以接入
libtcmalloc_minimal。
概覽
TCMalloc給每個線程分配了一個線程局部緩存。小分配可以直接由線程局部緩存來滿足。需要的話,會將對象從中央數據結構移動到線程局部緩存中,同時定期的垃圾收集將用於把內存從線程局部緩存遷移回中央數據結構中。
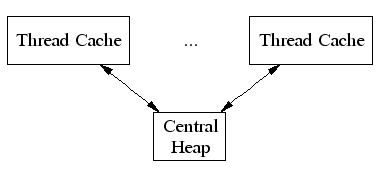
TCMalloc將尺寸小於<=
32K的對象(“小”對象)和大對象區分開來。大對象直接使用頁級分配器(一個頁是一個4K的對齊內存區域)從中央堆直接分配。即,一個大對象總是頁對齊的並占據了整數個數的頁。
連續的一些頁面可以被分割為一系列小對象,而他們的大小都相同。例如,一個連續的頁面(4K)可以被劃分為32個128字節的對象。
小對象的分配
每個小對象的大小都會被映射到170個可分配的尺寸類別中的一個。例如,在分配961到1024字節時,都會歸整為1024字節。尺寸類別這樣隔 開:較小的尺寸相差8字節,較大的尺寸相差16字節,再大一點的尺寸差32字節,如此類推。最大的間隔(對於尺寸 >= ~2K的)是256字節。
一個線程緩存對每個尺寸類都包含了一個自由對象的單向鏈表。
當分配一個小對象時:
-
我們將其大小映射到對應的尺寸類中。
-
查找當前線程的線程緩存中相應的自由列表。
-
如果自由列表不空,那麼從移除列表的第一個對象並返回它。當按照這個快速通道時,TCMalloc不會獲取任何鎖。這就可以極大提高分配的速度,因為鎖/解鎖操作在一個2.8GHz Xeon上大約需要100納秒的時間。
如果自由列表為空:
-
從該尺寸類別的中央自由列表(中央自由列表是被所有線程共享的)取得一連串對象。
-
將他們放入線程局部的自由列表。
-
將新獲取的對象中的一個返回給應用程序。
如果中央自由列表也為空:(1) 我們從中央頁分配器分配了一連串頁面。(2) 將他們分割成該尺寸類的一系列對象。(4) 像前面一樣,將部分對象移入線程局部的自由列表中。
大對象的分配
一個大對象的尺寸(> 32K)會被除以一個頁面尺寸(4K)並取整(大於結果的最小整數),同時是由中央頁面堆來處理的。中央頁面堆又是一個自由列表的陣列。對於
i < 256而言,第
k個條目是一個由
k個頁面組成的自由列表。第
256個條目則是一個包含了長度
>= 256個頁面的自由列表:
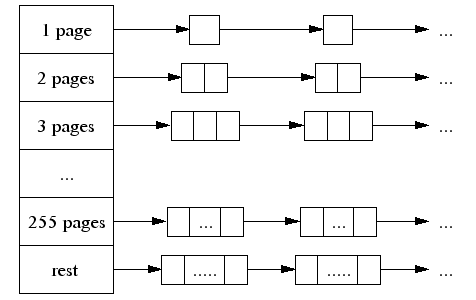
k個頁面的一次分配通過在第k個自由列表中查找來完成。如果該自由列表為空,那麼我們則在下一個自由列表中查找,如此繼續。最終,如果必要的話,我們將在 最 後一個自由列表中查找。如果這個動作也失敗了,我們將向系統獲取內存(使用sbrk、mmap或者通過在/dev/mem中進行映射)。
如果k個頁面的一次分配行為由連續的長度> k的頁面滿足了,剩下的連續頁面將被重新插回到頁面堆的對應的自由列表中。
跨度(Span)
TCMalloc 管理的堆由一系列頁面組成。連續的頁面由一個“跨度”(Span)對象來表示。一個跨度可以是已被分配或者是自由的。如果是自由的,跨度則會是一個頁面堆 鏈表中的一個條目。如果已被分配,它會是一個已經被傳遞給應用程序的大對象,或者是一個已經被分割成一系列小對象的一個頁面。如果是被分割成小對象的,對 象的尺寸類別會被記錄在跨度中。
由頁面號索引的中央數組可以用於找到某個頁面所屬的跨度。例如,下面的跨度a占據了2個頁面,跨度b占據了1個頁面,跨度c占據了5個頁面最後跨度d占據了3個頁面。
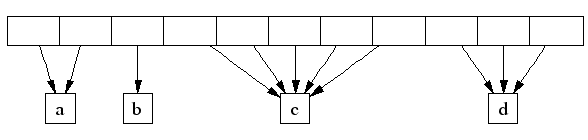
在一個32位的地址空間中,中央陣列由一個2層的基數樹來表示,其中根包含了32個條目,每個葉包含了 215個條目(一個32為地址空間包含了 220個 4K 頁面,所以這裡樹的第一層則是用25整除220個頁面)。這就導致了中央陣列的初始內存使用需要128KB空間(215*4字節),看上去還是可以接受的。
在64位機器上,我們將使用一個3層的基數樹。
解除分配
當一個對象被解除分配時,我們先計算他的頁面號並在中央陣列中查找對應的跨度對象。該跨度會告訴我們該對象是大是小,如果它是小對象的話尺寸類別是 什麼。如果是小對象的話,我們將其插入到當前線程的線程緩存中對應的自由列表中。如果線程緩存現在超過了某個預定的大小(默認為2MB),我們便運行垃圾 收集器將未使用的對象從線程緩存中移入中央自由列表。
如果該對象是大對象的話,跨度會告訴我們該對象覆蓋的頁面的范圍。假設該范圍是[p,q]。我們還會查找頁面p-1和頁面q+1對應的跨度。如果這兩個相鄰的跨度中有任何一個是自由的,我們將他們和[p,q]的跨度接合起來。最後跨度會被插入到頁面堆中合適的自由列表中。
小對象的中央自由列表
就像前面提過的一樣,我們為每一個尺寸類別設置了一個中央自由列表。每個中央自由列表由兩層數據結構來組成:一系列跨度和每個跨度一個自由對象的鏈表。
通過從某個跨度中移除第一個條目來從中央自由列表分配一個對象。(如果所有的跨度裡只有空鏈表,那麼首先從中央頁面堆中分配一個尺寸合適的跨度。)
一個對象可以通過將其添加到他包含的跨度的鏈表中來返回到中央自由列表中。如果鏈表長度現在等於跨度中所有小對象的數量,那麼該跨度就是完全自由的了,就會被返回到頁面堆中。
線程緩存的垃圾收集
某個線程緩存當緩存中所有對象的總共大小超過2MB的時候,會對他進行垃圾收集。垃圾收集阈值會自動根據線程數量的增加而減少,這樣就不會因為程序有大量線程而過度浪費內存。
我們會遍歷緩存中所有的自由列表並且將一定數量的對象從自由列表移到對於得中央列表中。
從某個自由列表中移除的對象的數量是通過使用一個每列表的低水位線L 來確定的。L記錄了自上一次垃圾收集以來列表最短的長度。注意,在上一次的垃圾收集中我們可能只是將列表縮短了L個對象而沒有對中央列表進行任何額外訪 問。我們利用這個過去的歷史作為對未來訪問的預測器並將L/2個對象從線程緩存自由列表中移到相應的中央自由列表中。這個算法有個很好的特性是,如果某個 線程不再使用某個特定的尺寸時,該尺寸的所有對象都會很快從線程緩存被移到中央自由列表,然後可以被其他緩存利用。
性能備注
PTMalloc2單元測試
PTMalloc2包(現在已經是glibc的一部分了)包含了一個單元測試程序t-test1.c。它會產生一定數量的線程並在每個線程中進行一系列分配和解除分配;線程之間沒有任何通信除了在內存分配器中同步。
t- test1(放在tests/tcmalloc/中,編譯為ptmalloc_unittest1) 用一系列不同的線程數量(1~20)和最大分配尺寸(64B~32KB)運行。這些測試運行在一個2.4GHz 雙核心Xeon的RedHat 9系統上,並啟用了超線程技術, 使用了
Linux glibc-2.3.2,每個測試中進行一百萬次操作。在每個案例中,一次正常運行,一次使用LD_PRELOAD=libtcmalloc.so。
下面的圖像顯示了TCMalloc對比PTMalloc2在不同的衡量指標下的性能。首先,現實每秒全部操作(百萬)以及最大分配尺寸,針對不同數量的線程。用來生產這些圖像的原始數據(time工具的輸出)可以在t-test1.times.txt中找到。
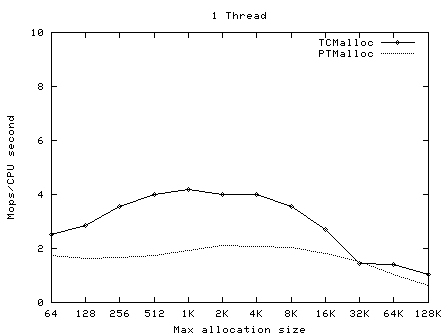
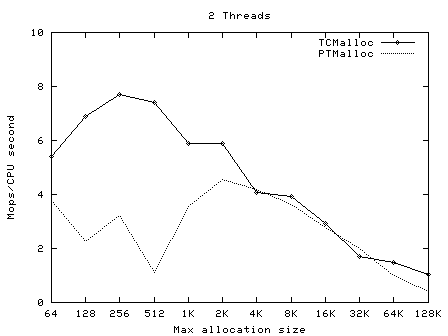
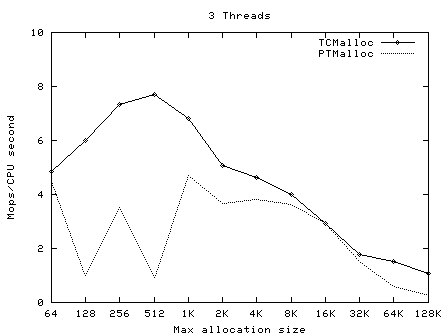
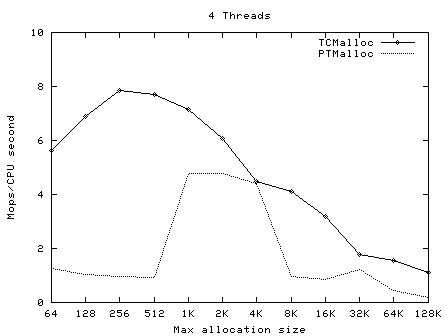
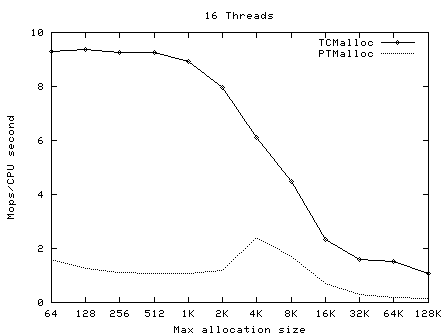
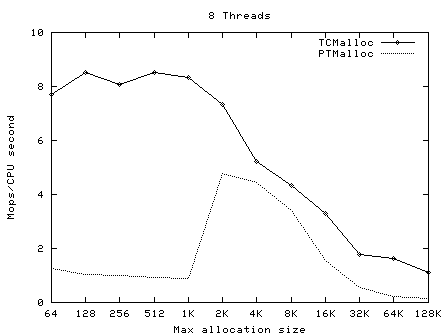
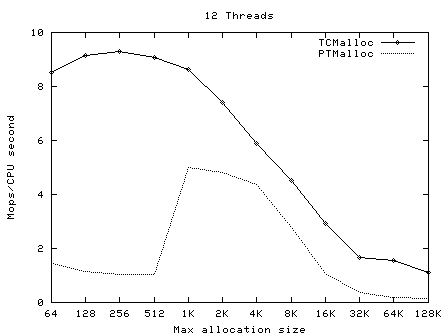
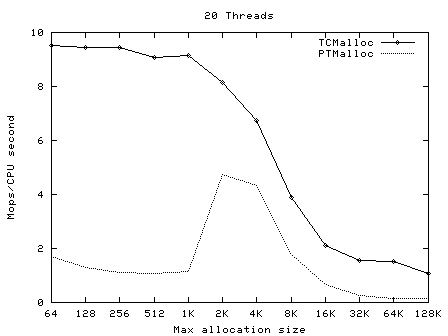
這次我們再一次看到TCMalloc要比PTMalloc2更連續也更高效。對於<32K的最大分配尺寸,TCMalloc在大線程數的情況 下典型地達到了CPU時間每秒約0.5~1百萬操作,同時PTMalloc通常達到了CPU時間每秒約0.5~1百萬,還有很多情況下要比這個數字小很 多。在32K最大分配尺寸之上,TCMalloc下降到了每CPU時間秒1~1.5百萬操作,同時PTMalloc對於大線程數降到幾乎只有零(也就是, 使用PTMalloc,在高度多線程的情況下,很多CPU時間被浪費在輪流等待鎖定上了)。
轉自:http://shiningray.cn/tcmalloc-thread-caching-malloc.html


