


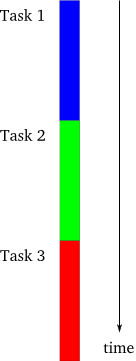
 圖1 同步模型
這是最簡單的編程方式。在一個時刻,只能有一個任務在執行,並且前一個任務結束後一個任務才能開始。如果任務都能按照事先規定好的順序執行,最後一個任務的完成意味著前面所有的任務都已無任何差錯地完成並輸出其可用的結果—這是多麼簡單的邏輯。
圖1 同步模型
這是最簡單的編程方式。在一個時刻,只能有一個任務在執行,並且前一個任務結束後一個任務才能開始。如果任務都能按照事先規定好的順序執行,最後一個任務的完成意味著前面所有的任務都已無任何差錯地完成並輸出其可用的結果—這是多麼簡單的邏輯。下面我們來呈現第二個模型,如圖2所示:

圖2 線程模型
在這個模型中,每個任務都在單獨的線程中完成。這些線程都是由操作系統來管理,若在多處理機、多核處理機的系統中可能會相互獨立的運行,若在單處理機上,則會交錯運行。 關鍵點在於,在線程模式中,具體哪個任務執行由操作系統來處理。但編程人員則只需簡單地認為:它們的指令流是相互獨立且可以並行執行。雖然,從圖示看起來 很簡單,實際上多線程編程是很麻煩的,你想啊,任務之間的要通信就要是線程之間的通信。線程間的通信那不是一般的復雜。什麼郵箱、通道、共享內存、、、
一些程序用多處理機而不是多線程來實現並行運算。雖然具體的編程細節是不同的,但對於我們要研究的模型來說是一樣的。
下面我們來介紹一下異步編程模型,如圖3所示
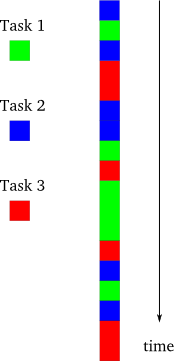
圖3 異步模型
在這個模型中,任務是交錯完成,值得注意的是:這是在單線程的控制下。這要比多線程模型簡單多了,因為編程人員總可以認為只有一個任務在執行,而其它的在停止狀態。雖然在單處理機系統中,線程也是像圖3那樣交替進行。但作為程序員在使用多線程時,仍然需要使用圖2而不是圖3的來思考問題,以防止程序在挪到多處理機的系統上無法正常運行(考慮到兼容性)。間單線程的異步程序不管是在單處理機還是在多處理機上都 能很好的運行。
在異步編程模型與多線程模型之間還有一個不同:在多線程程序中,對於停止某個線程啟動另外一個線程,其決定權並不在程序員手裡而在操作系統那裡,因此,程 序員在編寫程序過程中必須要假設在任何時候一個線程都有可能被停止而啟動另外一個線程。相反,在異步模型中,一個任務要想運行必須顯式放棄當前運行的任務 的控制權。這也是相比多線程模型來說,最簡潔的地方。
值得注意的是:將異步編程模型與同步模型混合在同一個系統中是可以的。但在介紹中的絕大多數時候,我們只研究在單個線程中的異步編程模型。
動機
我 們已經看到異步編程模型之所以比多線程模型簡單在於其單令流與顯式地放棄對任務的控制權而不是被操作系統隨機地停止。但是異步模型要比同步模型復雜得多。 程序員必須將任務組織成序列來交替的小步完成。因此,若其中一個任務用到另外一個任務的輸出,則依賴的任務(即接收輸出的任務)需要被設計成為要接收系列 比特或分片而不是一下全部接收。由於沒有實質上的並行,從我們的圖中可以看出,一個異步程序會花費一個同步程序所需要的時間,可能會由於異步程序的性能問 題而花費更長的時間。
因此,就要問了,為什麼還要使用異步模型呢? 在這兒,我們至少有兩個原因。首先,如果有一到兩個任務需要完成面向人的接口,如果交替執行這些任務,系統在保持對用戶響應的同時在後台執行其它的任務。因此,雖然後台的任務可能不會運行的更快,但這樣的系統可能會歡迎的多。
然而,有一種情況下,異步模型的性能會高於同步模型,有時甚至會非常突出,即在比較短的時間內完成所有的任務。這種情況就是任務被強行等待或阻塞,如圖4所示:
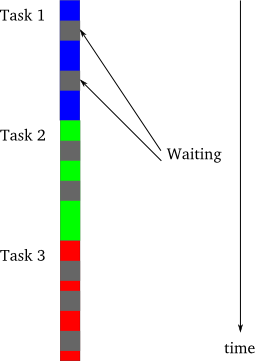
圖4 同步模型中出現阻塞
在圖4中,灰色的部分代表這段時間某個任務被阻塞。為什麼要阻塞一個任務呢?最直接的原因就是等待I/O的完成:傳輸數據或來自某個外部設備。一個典型的CPU處理數據的能力是硬盤或網絡的幾個數量級的倍數。因此,一個需要進行大I/O操作的同步程序需要花費大量的時間等待硬盤或網絡將數據准備好。正是由於這個原因,同步程序也被稱作為阻塞程序。
從圖4中可以看出,一個可阻塞的程序,看起來與圖3描 述的異步程序有點像。這不是個巧合。異步程序背後的最主要的特點就在於,當出現一個任務像在同步程序一樣出現阻塞時,會讓其它可以執行的任務繼續執行,而 不會像同步程序中那樣全部阻塞掉。因此一個異步程序只有在沒有任務可執行時才會出現“阻塞”,這也是為什麼異步程序被稱為非阻塞程序的原因。
任務之間的切換要不是此任務完成,要不就是它被阻塞。由於大量任務可能會被阻塞,異步程序等待的時間少於同步程序而將這些時間用於其它實時工作的處理(如與人打交道的接口),這樣一來,前者的性能必然要高很多。
與同步模型相比,異步模型的優勢在如下情況下會得到發揮:
1.有大量的任務,因此在一個時刻至少有一個任務要運行
2.任務執行大量的I/O操作,這樣同步模型就會在因為任務阻塞而浪費大量的時間
3.任務之間相互獨立,以至於任務內部的交互很少。
這些條件大多在CS模式中的網絡比較繁忙服務器端出現(如WEB服務器)。每個任務代表一個客戶端進行接收請求並回復的I/O操作。客戶的請求(相當於讀操作)都是相互獨立的。因此一個網絡服務是異步模型的典型代表,這也是為什麼twisted是第一個也是最棒的網絡庫。
from:http://blog.sina.com.cn/s/blog_704b6af70100py9n.html