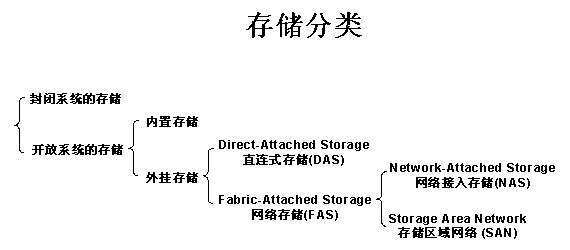
先羅列一些工作中用得比較多的系統檢測工具吧,top、ps、iostat、vmstat、free (-m)、tcpdump...
1.磁盤io相對於內存讀寫是巨慢無比的,數據庫操作也是,所以在一些io密集的程序裡面可以用內存映射、memcached來進行優化
2.就個人理解來描述一下磁盤訪問
cpu訪問文件數據時,先在cpu cache和memory查找,沒找到就通知io子系統去磁盤加載(數據以內存內的形式加載,一個內存頁一般是4kb)(MPF,major page fault)
如果在內存(寫緩存buffer,讀緩存cached)中可以找到就不用有磁盤操作了(MnPF,minor page fault)
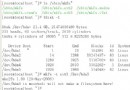
後者速度快多了,所以在頻繁的io操作後內存中有很多空間用於緩存磁盤數據,這時候如果看到free的空間不足並不表示機器真的內存不足,當有內存需求時內核會釋放這些用於磁盤緩存的內存空間,下圖中cached就是緩存所占的空間,內存實際剩余是free+buffers+cached = 117+10+508。但是如果Swap used很多就表示系統內存真的很緊張,使用交換分區的速度很慢,因為它是保存在磁盤上的。
3.內存頁類型:
read page:只讀,包括庫文件之類的
dirty page(write page):寫過需要同步到磁盤的數據,我想在fprintf之後緊接著調用fflush()之類的函數應該可以從這裡寫回磁盤
anonymous page:跟磁盤文件無關,歸某些進程所有,內存不足時這些數據可能掉入Swap
4.計算IOPS(每秒響應的磁盤io次數):
假如磁盤的RPM是10000(RPM,Revolutions Per Minute,每分鐘旋轉圈數)
則,磁盤的RD(Rotational Delay,旋轉半圈的毫秒數)是(1/(10000/(60*1000)))/2=3
加上磁頭的DS(Disk Seek,磁頭尋道的毫秒數)平均是3MS
加上2MS延遲
最終的IOPS是8ms,內核每次的io請求磁盤需要8ms來完成,就是10000RPM的磁盤每秒可以提供大約125次IOPS
根據
5.實際io情況要根據程序來考量,郵件服io數據小而請求頻繁,屬於Random IO,流媒體服務io數據大而請求頻度低,屬於Sequential IO
前者對iops要求比較高,後者對讀寫大量數據能力(KB per request, (rkB/s)/(r/s)或者(wkB/s)/(w/s))要求比較高
當用top或者iostat查看發現iowait比較高時說明有io瓶頸