


Linux 系統日志
許多有價值的日志文件都是由 Linux 自動地為你創建的。你可以在 /var/log 目錄中找到它們。下面是在一個典型的 Ubuntu 系統中這個目錄的樣子:
一些最為重要的 Linux 系統日志包括:
/var/log/syslog 或 /var/log/messages 存儲所有的全局系統活動數據,包括開機信息。基於 Debian 的系統如 Ubuntu 在 /var/log/syslog 中存儲它們,而基於 RedHat 的系統如 RHEL 或 CentOS 則在 /var/log/messages 中存儲它們。
/var/log/auth.log 或 /var/log/secure 存儲來自可插拔認證模塊(PAM)的日志,包括成功的登錄,失敗的登錄嘗試和認證方式。Ubuntu 和 Debian 在 /var/log/auth.log 中存儲認證信息,而 RedHat 和 CentOS 則在 /var/log/secure 中存儲該信息。
/var/log/kern 存儲內核的錯誤和警告數據,這對於排除與定制內核相關的故障尤為實用。
/var/log/cron 存儲有關 cron 作業的信息。使用這個數據來確保你的 cron 作業正成功地運行著。
Digital Ocean 有一個關於這些文件的完整教程,介紹了 rsyslog 如何在常見的發行版本如 RedHat 和 CentOS 中創建它們。
應用程序也會在這個目錄中寫入日志文件。例如像 Apache,Nginx,MySQL 等常見的服務器程序可以在這個目錄中寫入日志文件。其中一些日志文件由應用程序自己創建,其他的則通過 syslog (具體見下文)來創建。
什麼是 Syslog?
Linux 系統日志文件是如何創建的呢?答案是通過 syslog 守護程序,它在 syslog 套接字 /dev/log 上監聽日志信息,然後將它們寫入適當的日志文件中。
單詞“syslog” 代表幾個意思,並經常被用來簡稱如下的幾個名稱之一:
Syslog 守護進程 — 一個用來接收、處理和發送 syslog 信息的程序。它可以遠程發送 syslog 到一個集中式的服務器或寫入到一個本地文件。常見的例子包括 rsyslogd 和 syslog-ng。在這種使用方式中,人們常說“發送到 syslog”。
Syslog 協議 — 一個指定日志如何通過網絡來傳送的傳輸協議和一個針對 syslog 信息(具體見下文) 的數據格式的定義。它在 RFC-5424 中被正式定義。對於文本日志,標准的端口是 514,對於加密日志,端口是 6514。在這種使用方式中,人們常說“通過 syslog 傳送”。
Syslog 信息 — syslog 格式的日志信息或事件,它包括一個帶有幾個標准字段的消息頭。在這種使用方式中,人們常說“發送 syslog”。
Syslog 信息或事件包括一個帶有幾個標准字段的消息頭,可以使分析和路由更方便。它們包括時間戳、應用程序的名稱、在系統中信息來源的分類或位置、以及事件的優先級。
下面展示的是一個包含 syslog 消息頭的日志信息,它來自於控制著到該系統的遠程登錄的 sshd 守護進程,這個信息描述的是一次失敗的登錄嘗試:
復制代碼代碼如下:
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
Syslog 格式和字段
每條 syslog 信息包含一個帶有字段的信息頭,這些字段是結構化的數據,使得分析和路由事件更加容易。下面是我們使用的用來產生上面的 syslog 例子的格式,你可以將每個值匹配到一個特定的字段的名稱上。
復制代碼代碼如下:
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
下面,你將看到一些在查找或排錯時最常使用的 syslog 字段:
時間戳
時間戳 (上面的例子為 2003-10-11T22:14:15.003Z) 暗示了在系統中發送該信息的時間和日期。這個時間在另一系統上接收該信息時可能會有所不同。上面例子中的時間戳可以分解為:
2003-10-11 年,月,日。
T 為時間戳的必需元素,它將日期和時間分隔開。
22:14:15.003 是 24 小時制的時間,包括進入下一秒的毫秒數(003)。
Z 是一個可選元素,指的是 UTC 時間,除了 Z,這個例子還可以包括一個偏移量,例如 -08:00,這意味著時間從 UTC 偏移 8 小時,即 PST 時間。
主機名
主機名 字段(在上面的例子中對應 server1.com) 指的是主機的名稱或發送信息的系統.
應用名
應用名 字段(在上面的例子中對應 sshd:auth) 指的是發送信息的程序的名稱.
優先級
優先級字段或縮寫為 pri (在上面的例子中對應 ) 告訴我們這個事件有多緊急或多嚴峻。它由兩個數字字段組成:設備字段和緊急性字段。緊急性字段從代表 debug 類事件的數字 7 一直到代表緊急事件的數字 0 。設備字段描述了哪個進程創建了該事件。它從代表內核信息的數字 0 到代表本地應用使用的 23 。
Pri 有兩種輸出方式。第一種是以一個單獨的數字表示,可以這樣計算:先用設備字段的值乘以 8,再加上緊急性字段的值:(設備字段)(8) + (緊急性字段)。第二種是 pri 文本,將以“設備字段.緊急性字段” 的字符串格式輸出。後一種格式更方便閱讀和搜索,但占據更多的存儲空間。
在 Linux 中使用日志來排錯
登錄失敗原因
如果你想檢查你的系統是否安全,你可以在驗證日志中檢查登錄失敗的和登錄成功但可疑的用戶。當有人通過不正當或無效的憑據來登錄時會出現認證失敗,這通常發生在使用 SSH 進行遠程登錄或 su 到本地其他用戶來進行訪問權時。這些是由插入式驗證模塊(PAM)來記錄的。在你的日志中會看到像 Failed password 和 user unknown 這樣的字符串。而成功認證記錄則會包括像 Accepted password 和 session opened 這樣的字符串。
失敗的例子:
復制代碼代碼如下:
pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
Failed password for invalid user hoover from 10.0.2.2 port 4791 ssh2
pam_unix(sshd:auth): check pass; user unknown
PAM service(sshd) ignoring max retries; 6 > 3
成功的例子:
復制代碼代碼如下:
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
pam_unix(sshd:session): session opened for user hoover by (uid=0)
pam_unix(sshd:session): session closed for user hoover
你可以使用 grep 來查找哪些用戶失敗登錄的次數最多。這些都是潛在的攻擊者正在嘗試和訪問失敗的賬戶。這是一個在 ubuntu 系統上的例子。
復制代碼代碼如下:
$ grep "invalid user" /var/log/auth.log | cut -d ' ' -f 10 | sort | uniq -c | sort -nr
23 oracle
18 postgres
17 nagios
10 zabbix
6 test
由於沒有標准格式,所以你需要為每個應用程序的日志使用不同的命令。日志管理系統,可以自動分析日志,將它們有效的歸類,幫助你提取關鍵字,如用戶名。
日志管理系統可以使用自動解析功能從 Linux 日志中提取用戶名。這使你可以看到用戶的信息,並能通過點擊過濾。在下面這個例子中,我們可以看到,root 用戶登錄了 2700 次之多,因為我們篩選的日志僅顯示 root 用戶的嘗試登錄記錄。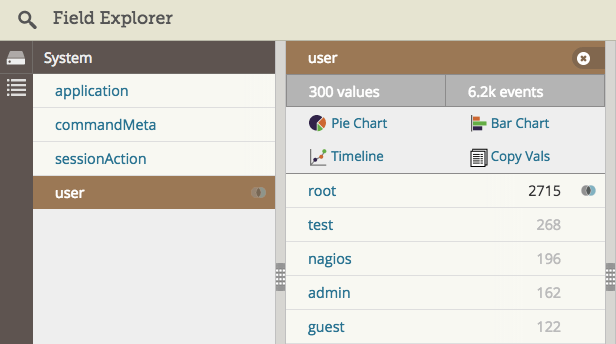
日志管理系統也可以讓你以時間為做坐標軸的圖表來查看,使你更容易發現異常。如果有人在幾分鐘內登錄失敗一次或兩次,它可能是一個真正的用戶而忘記了密碼。但是,如果有幾百個失敗的登錄並且使用的都是不同的用戶名,它更可能是在試圖攻擊系統。在這裡,你可以看到在3月12日,有人試圖登錄 Nagios 幾百次。這顯然不是一個合法的系統用戶。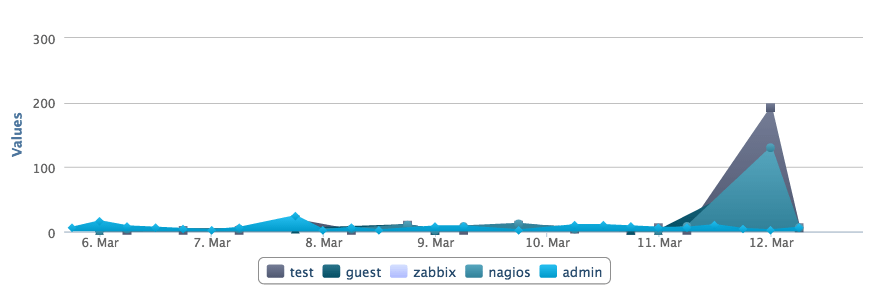
重啟的原因
有時候,一台服務器由於系統崩潰或重啟而宕機。你怎麼知道它何時發生,是誰做的?
關機命令
如果有人手動運行 shutdown 命令,你可以在驗證日志文件中看到它。在這裡,你可以看到,有人從 IP 50.0.134.125 上作為 ubuntu 的用戶遠程登錄了,然後關閉了系統。
復制代碼代碼如下:
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
Mar 19 18:37:09 ip-172-31-11-231 sudo: ubuntu : TTY=pts/1 ; PWD=/home/ubuntu ; USER=root ; COMMAND=/sbin/shutdown -r now
內核初始化
如果你想看看服務器重新啟動的所有原因(包括崩潰),你可以從內核初始化日志中尋找。你需要搜索內核類(kernel)和 cpu 初始化(Initializing)的信息。
復制代碼代碼如下:
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Linux version 3.8.0-44-generic (buildd@tipua) (gcc version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5) ) #66~precise1-Ubuntu SMP Tue Jul 15 04:01:04 UTC 2014 (Ubuntu 3.8.0-44.66~precise1-generic 3.8.13.25)
檢測內存問題
有很多原因可能導致服務器崩潰,但一個常見的原因是內存用盡。
當你系統的內存不足時,進程會被殺死,通常會殺死使用最多資源的進程。當系統使用了所有內存,而新的或現有的進程試圖使用更多的內存時就會出現錯誤。在你的日志文件查找像 Out of Memory 這樣的字符串或類似 kill 這樣的內核警告信息。這些信息表明系統故意殺死進程或應用程序,而不是允許進程崩潰。
例如:
復制代碼代碼如下:
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
[29923450.995084] select 5230 (docker), adj 0, size 708, to kill
你可以使用像 grep 這樣的工具找到這些日志。這個例子是在 ubuntu 中:
復制代碼代碼如下:
$ grep “Out of memory” /var/log/syslog
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
請記住,grep 也要使用內存,所以只是運行 grep 也可能導致內存不足的錯誤。這是另一個你應該中央化存儲日志的原因!
定時任務錯誤日志
cron 守護程序是一個調度器,可以在指定的日期和時間運行進程。如果進程運行失敗或無法完成,那麼 cron 的錯誤出現在你的日志文件中。具體取決於你的發行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 幾個位置找到這個日志。cron 任務失敗原因有很多。通常情況下,問題出在進程中而不是 cron 守護進程本身。
默認情況下,cron 任務的輸出會通過 postfix 發送電子郵件。這是一個顯示了該郵件已經發送的日志。不幸的是,你不能在這裡看到郵件的內容。
復制代碼代碼如下:
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active)
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
你可以考慮將 cron 的標准輸出記錄到日志中,以幫助你定位問題。這是一個你怎樣使用 logger 命令重定向 cron 標准輸出到 syslog的例子。用你的腳本來代替 echo 命令,helloCron 可以設置為任何你想要的應用程序的名字。
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
它創建的日志條目:
復制代碼代碼如下:
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
每個 cron 任務將根據任務的具體類型以及如何輸出數據來記錄不同的日志。
希望在日志中有問題根源的線索,也可以根據需要添加額外的日志記錄。