嵌入式 Linux進程間通信(十一)――多線程簡介
一、線程簡介
線程有四種:內核線程、輕量級進程、用戶線程、加強版用戶線程
1、內核線程
內核線程就是內核的分身,一個分身可以處理一件特定事情。內核線程的使用是廉價的,唯一使用的資源就是內核棧和上下文切換時保存寄存器的空間。支持多線程的內核叫做多線程內核(Multi-Threads kernel )。
2、輕量級進程LWP
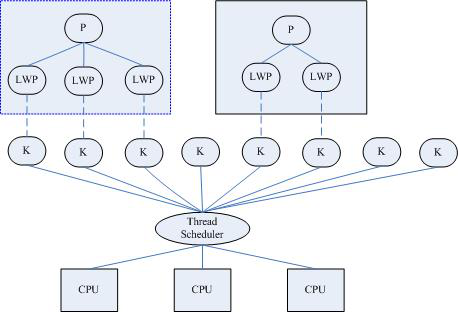
輕量級進程(LWP)是一種由內核支持的用戶線程,是基於內核線程的高級抽象,只有先支持內核線程,才能有輕量級進程LWP。每一個進程有一個或多個 LWP,每個LWP由一個內核線程支持,即一對一線程模型。
每個LWP都與一個特定的內核線程關聯,因此每個LWP都是一個獨立的線程調度單元。即使有一個LWP在系統調用中阻塞,也不會影響整個進程的執行。
輕量級進程具有局限性。首先,大多數LWP的操作,如建立、析構以及同步,都需要進行系統調用。系統調用的代價相對較高:需要在用戶空間和內核空間中切換。其次,每個LWP都需要有一個內核線程支持,因此LWP要消耗內核資源(內核線程的棧空間)。因此一個系統不能支持大量的LWP。
3、用戶線程
輕量級進程LWP雖然本質上屬於用戶線程,但LWP線程庫是建立在內核之上的,LWP的許多操作都要進行系統調用,因此效率不高。用戶線程指的是完全建立在用戶空間的線程庫,用戶線程的建立,同步,銷毀,調度完全在用戶空間完成,不需要內核的幫助。因用戶線程的操作是極其快速的且低消耗的。
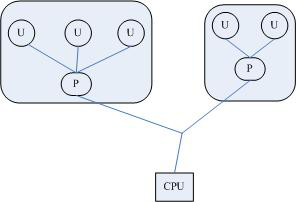
進程中包含線程,用戶線程在用戶空間中實現,即多對一線程模型,其缺點是一個用戶線程如果阻塞在系統調用中,則整個進程都將會阻塞。內核並沒有直接對用戶線程進程調度,內核的調度對象和傳統進程一樣,還是進程本身,內核並不知道用戶線程的存在。用戶線程之間的調度由在用戶空間實現的線程庫實現。
4、加強版用戶線程
加強版用戶線程由用戶線程和輕量級進程融合而成。每個線程可以對應多個輕量級進程,每個輕量級進程可以對應多個線程,即多對多模型。
加強版用戶線程的線程庫繼承了用戶線程,線程庫完全建立在用戶空間中,用戶線程的操作開銷比較低,可以建立任意多需要的用戶線程。操作系統提供了輕量級進程 LWP 作為用戶線程和內核線程之間的橋梁。LWP具有內核線程支持,是內核的調度單元,並且用戶線程的系統調用要通過 LWP ,因此進程中某個用戶線程的阻塞不會影響整個進程的執行。用戶線程庫將建立的用戶線程關聯到 LWP 上, LWP 與用戶線程的數量不一定一致。當內核調度到某個輕量級進程 LWP 上時, LWP 關聯的用戶線程就被執行。
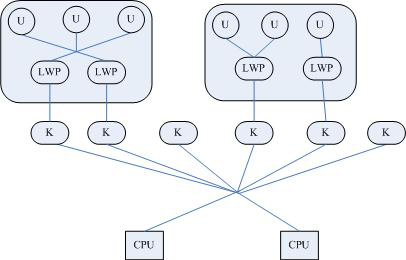
從以上對線程的介紹可知,只有在用戶線程完全由輕量級進程構成時,輕量級進程LWP才是線程。
二、線程的實現
Linux系統中線程的實現是基於pthread線程庫的,pthread在不同的linux kernel版本中是不同的,大體上以linux 2.6為分界,linux 2.6以前的linux版本的線程庫采用的是linux Threads線程庫,linux 2.6開始的linux版本采用NTPL線程庫。
1、LinuxThreads線程的實現
Linux 2.2開始,linux中開始使用LinuxThreads線程庫。在LinuxThreads中,專門為每一個進程構造了一個管理線程,負責處理線程相關的管理工作。當進程第一次調用pthread_create創建一個線程的時候就會創建並啟動管理線程,然後管理線程再來創建用戶請求的線程。在LinuxThreads中,管理線程的棧和用戶線程的棧是分離的,管理線程在進程堆中通過malloc分配一個THREAD_MANAGER_STACK_SIZE字節的區域作為自己的運行棧。
Linux Threads的實現基於核心輕量級進程的"一對一"線程模型,一個線程實體對應一個核心輕量級進程,線程調度交給內核,而線程之間的管理在核外函數庫中實現。
LinuxThreads並不遵守POSIX線程標准。
LinuxThreads線程庫的缺點:
A、LinuxThreads線程庫使用輕量級進程LWP來模擬實現線程,輕量級進程擁有獨立的進程id,在進程調度、信號處理、IO等方面與普通進程一樣。POSIX線程標准規定,同一進程的所有線程應該共享一個進程id和父進程id,因此LinuxThreads線程庫不兼容POSIX線程標准。
B、LinuxThreads的每個線程本質上是一個輕量級線程,對內核來說是一個進程,且沒有實現線程組,信號在內核中是以進程為單位分發的,因此LinuxThreads只能將一個線程(輕量級進程)掛起,而無法掛起整個進程(進程中的所有線程)。
C、LinuxThreads將每個進程的線程最大數目定義為1024,實際線程數受到整個系統的總進程數限制。
D、LinuxThreads線程庫中管理線程負責用戶線程的清理工作,一旦管理線程死亡,用戶線程只能手工清理,而且用戶線程並不知道管理線程的狀態,新的線程創建等請求將無人處理。
E、LinuxThreads中的線程同步是建立在信號基礎上的,通過內核復雜的信號處理機制的同步方式效率較低
2、NPTL線程的實現
LinuxThreads的兼容性問題,嚴重阻礙了Linux上的跨平台應用采用多線程設計,從而使得Linux上的線程應用一直保持在比較低的水平
NPTL(Native POSIX Threading Library)線程的實現模型本質上是基於輕量級進程LWP的,是對LinuxThreads線程實現模型的改進,在linux 2.6以後的版本中NPTL綁定到了GLIBC庫中。基於linux 2.6的改進,NTPL實現了對POSIX的兼容。
NPTL的優點: A、NTPL線程庫沒有使用管理線程,在多處理器系統上具有可伸縮性和同步機制 B、NTPL線程庫兼容POSIX線程標准 C、NPTL線程庫支持ABI(應用程序二進制接口)
三、多線程編程優缺點
優點: 1、無需跨進程邊界
2、程序邏輯和控制方式簡單
3、所有線程可以直接共享內存和變量等
4、線程方式消耗的總資源比進程方式好
缺點: 1、每個線程與主程序共用地址空間,受限於2GB地址空間
2、線程之間的同步和加鎖控制比較麻煩
3、一個線程的崩潰可能影響到整個程序的穩定性
4、到達一定的線程數程度後,即使再增加CPU也無法提高性能
5、線程能夠提高的總性能有限,而且線程數量較大時,線程本身的調度開銷不小
四、線程函數
1、線程創建
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
thread參數是指向線程標識符的指針
attr參數用來設置線程屬性
start_routine參數是線程運行函數的起始地址,為函數指針
arg參數是運行函數的參數。
如果線程創建成功pthread_create函數就會返回0,如果創建線程失敗,返回的是錯誤編號。
pthread_creat函數在創建線程時由內核向新線程傳遞參數,如果需要傳遞多個參數則需要將所有參數組織在一個結構體內,再將結構體的地址作為參數arg傳給新線程。
編譯時需要連接pthread線程庫,即-lpthread
2、線程屬性設置
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy(pthread_attr_t *attr);
線程屬性值不能直接設置,須使用相關函數進行操作,初始化的函數為 pthread_attr_init,pthread_attr_init函數必須在pthread_create函數之前調用。線程屬性對象主要包括是否綁定、是否分離、堆棧地址、堆棧大小、優先級。默認的屬性為非綁定、非分離、缺省1M的堆棧、與父進程同樣級別的優先級。
typedef struct
{
int detachstate; //線程的分離狀態
int schedpolicy; //線程調度策略
struct sched_param schedparam; // 線程的調度參數
int inheritsched; //線程的繼承性
int scope; //線程的作用域
size_t guardsize; //線程棧末尾的警戒緩沖區大小
int stackaddr_set;
void * stackaddr; //線程棧的位置
size_t stacksize; //線程棧的大小
}pthread_attr_t;
A、線程的綁定屬性
線程的綁定和輕進程(LWP:Light Weight Process)有關。輕進程可以理解為內核線程,位於用戶層和系統層之間。系統對線程資源的分配、對線程的控制是通過輕進程來實現的,一個輕進程可以控制一個或多個線程。默認狀況下,啟動多少輕進程、哪些輕進程來控制哪些線程是由系統來控制的,此時線程是非綁定的。線程的綁定屬性就是線程固定的綁定在某一個輕進程之上。由於CPU時間片的調度是面向輕進程的,綁定線程到某一個輕進程可以保證在需要的時候總有一個輕進程可用,同時通過設置線程所綁定的輕進程的優先級和調度級可以使得綁定的線程具有較高的響應速度,滿足諸如實時反應之類的要求。
#include <pthread.h>
int pthread_attr_setscope(pthread_attr_t *attr, int scope);
attr是線程屬性對象的指針 scope是綁定類型,擁有兩個取值:PTHREAD_SCOPE_SYSTEM(綁定的)和PTHREAD_SCOPE_PROCESS(非綁定的) Linux的線程永遠都是綁定的,所以PTHREAD_SCOPE_PROCESS在Linux中不管用,而且會返回ENOTSUP錯誤。PTHREAD_SCOPE_PROCESS出現是為了實現NTPL與POSIX線程標准兼容,NTPL如果運用在其他系統可能會使用到。
B、線程的分離屬性
分離屬性就是讓線程在創建之前就決定線程應該是分離的。如果設置了這個屬性,就沒有必要調用pthread_join或pthread_detach來回收線程資源。
#include <pthread.h>
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
detachstate:PTHREAD_CREATE_DETACHED(分離的)和PTHREAD_CREATE_JOINABLE(可合並的,默認屬性)。
C、線程的調度屬性
線程的調度屬性有三個,分別是:算法、優先級和繼承權。
Linux提供的線程調度算法有三個:輪詢、先進先出和其它。其中輪詢和先進先出調度算法是POSIX標准所規定,而其他則代表采用Linux自己認為更合適的調度算法,所以默認的調度算法就是其它。輪詢和先進先出調度算法都屬於實時調度算法。輪詢指的是時間片輪轉,當線程的時間片用完,系統將重新分配時間片,並將它放置在就緒隊列尾部,保證具有相同優先級的輪詢任務獲得公平的CPU占用時間;先進先出就是先到先服務,一旦線程占用了CPU則 一直運行,直到有更高優先級的線程出現或自己放棄。
設置線程調度算法的函數是pthread_attr_setschedpolicy
#include <pthread.h>
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
policy參數有三個取值:SCHED_RR(輪詢)、SCHED_FIFO(先進先出)和SCHED_OTHER(其它)。
Linux的線程優先級與進程的優先級不一樣,Linux的線程優先級是從1到99的數值,數值越大代表優先級越高,但只有采用SHCED_RR或SCHED_FIFO調度算法時,優先級才有效。對於采用SCHED_OTHER調度算法的線程,其優先級恆為0。
設置線程優先級的接口是pthread_attr_setschedparam
#include <pthread.h>
int pthread_attr_setschedparam(pthread_attr_t *attr,
const struct sched_param *param);
struct sched_param {
int sched_priority; /* Scheduling priority */
};
線程優先級不是隨便就能設置的。首先,進程必須是以root賬號運行的;其次,還需要放棄線程的繼承權。什麼是繼承權呢?就是當創建新的線程時,新線程要繼承父線程(創建者線程)的調度屬性。如果不希望新線程繼承父線程的調度屬性,就要放棄繼承權。
#include <pthread.h>
int pthread_attr_setinheritsched(pthread_attr_t *attr,int inheritsched);inheritsched參數有兩個取值:PTHREAD_INHERIT_SCHED(擁有繼承權)和PTHREAD_EXPLICIT_SCHED(放棄繼承權)。新線程在默認情況下是擁有繼承權。
D、線程的堆棧大小
線程的主函數與程序的主函數main一樣可以擁有局部變量。雖然同一個進程的線程之間是共享內存空間的,但是它的局部變量確並不共享。原因是局部變量存儲在堆棧中,而不同的線程擁有不同的堆棧。Linux系統為每個線程默認分配了8MB的堆棧空間,如果覺得這個空間不夠用,可以通過修改線程的堆棧大小屬性進行擴容。
#include <pthread.h>
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
stacksize參數是堆棧大小,以字節為單位。線程堆棧不能小於16KB,而且盡量按4KB(32位系統)或2MB(64位系統)的整數倍分配,即內存頁面大小的整數倍。修改線程堆棧大小是有風險的。
E、線程的滿棧警戒區
線程是有堆棧的,而且還有大小限制,那麼就一定會出現將堆棧用滿的情況。線程的堆棧用滿是非常危險的事情,這會導致對內核空間的破壞,一旦被有心人 士所利用,後果也不堪設想。為了防治這類事情的發生,Linux為線程堆棧設置了一個滿棧警戒區。滿棧警戒區一般就是一個頁面,屬於線程堆棧的一個擴展區 域。一旦有代碼訪問了這個區域,就會發出SIGSEGV信號進行通知。
雖然滿棧警戒區可以起到安全作用,但是會白白浪費掉內存空間,對於內存緊張的系統會使系統變得很慢。所有就有了關閉這個警戒區的需求。同時,如果我們修改了線程堆棧的大小,那麼系統會認為我們會自己管理堆棧,也會將警戒區取消掉,如果有需要就要開啟它。
#include <pthread.h>
int pthread_attr_setguardsize(pthread_attr_t *attr, size_t guardsize);
guardsize參數是警戒區大小,以字節為單位。與設置線程堆棧大小屬性一樣,盡量按照4KB或2MB的整數倍來分配。當設置警戒區大小為0時,就關閉了這個警戒區。
雖然棧滿警戒區需要浪費掉一點內存,但是能夠極大的提高安全性。一旦修改了線程堆棧的大小,一定要記得同時設置這個警戒區。
3、
線程的數據 線程的最大優點之一是數據的共享性,進程中的所有線程共享進程中的數據段,可以方便的獲得、修改數據。多個不同的線程訪問相同的變量。許多函數是不可重入的,即同時不能運行一個函數的多個拷貝(除非使用不同的數據段)。在函數中聲明的靜態變量常常帶來問題,函數的返回值也會有問題。因為如果返回的是函數內部靜態聲明的空間的地址,則在一個線程調用 該函數得到地址後使用該地址指向的數據時,別的線程可能調用此函數並修改了這一段數據。在進程中共享的變量必須用關鍵字volatile來定義,這是為了 防止編譯器在優化時(如gcc中使用-OX參數)改變它們的使用方式。為了保護變量,我們必須使用信號量、互斥等方法來保證我們對變量的正確使用。
在單線程的程序裡,有兩種基本的數據:全局變量和局部變量。在多線程程序裡,還有第三種數據類型:線程數據(TSD: Thread-Specific Data),在線程內部,各個函數可以象使用全局變量一樣調用線程數據,但線程數據對線程外部的線程是不可見的。
4、
線程的終止 線程的退出方式有三種:
A、線程體函數從啟動線程中返回,return
B、線程被另一個線程終止。
C、線程自行調用pthread_exit退出。pthread_exit可以在退出的時候傳遞一些信息,傳遞的信息可以用pthread_join函數獲得。exit是進程退出,如果在線程函數中調用exit,線程的進程也就會退出。會導致線程所在進程的其他線程退出。取消線程:#include <pthread.h>int pthread_cancel(pthread_t thread); 在別的線程中要終止另一個線程
#include <pthread.h>int pthread_setcancelstate(int state, int *oldstate); 被取消的線程可以設置自己的取消狀態
state參數有:PTHREAD_CANCEL_ENABLE(缺省)和PTHREAD_CANCEL_DISABLE
線程接收到CANCEL信號的缺省處理(即pthread_create()創建線程的缺省狀態)是繼續運行至取消點,也就是說設置一個CANCELED狀態,線程繼續運行,只有運行至Cancelation-point的時候才會退出。
5、
線程的合並和分離 線程的合並:
線程的合並是一種主動回收線程資源的方案。當一個進程或線程調用了針對其它線程的pthread_join函數,就是線程合並。pthread_join函數會阻塞調用進程或線程,直到被合並的線程結束為止。當被合並線程結束,pthread_join函數就會回收線程的資源,並將線程的返回值返回給合並者。
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
線程的分離: 線程分離也是一種線程資源回收機制,使用pthread_detach函數實現線程分離。線程分離是將線程資源的回收工作交由系統自動來完成,就是說當被分離的線程結束之後,系統會自動回收線程的資源。因為線程分離是啟動系統的自動回收機制,那麼程序也就無法獲得被分離線程的返回值。
#include <pthread.h>
int pthread_detach(pthread_t thread);
線程合並和線程分離都是用於回收線程資源的,可以根據不同的業務場景酌情使用。
6、
線程本地存儲 進程內線程之間可以共享內存地址空間,線程之間的數據交換可以非常快捷,但是多個線程訪問共享數據,需要昂貴的同步開銷。C程序庫中的errno是一個全局變量,會保存最後一個系統調用的錯誤代碼。在單線程環境並不會出現什麼問題。在多線程環境,所有線程都會有可能修改errno,很難確定errno代表的到底是哪個系統調用的錯誤代碼,造成非線程安全(Non Thread-Safe)。
為了解決非線程安全問題,引入了線程本地存儲,即 Thread Local Storage,簡稱TLS。利用TLS,errno所反映的就是本線程內最後一個系統調用的錯誤代碼了,也就是線程安全的。int pthread_key_create(pthread_key_t *key, void (*destructor)(void*));
創建一個線程本地存儲區
key參數返回線程本地存儲區的句柄,需要使用一個全局變量保存,以便所有線程都能訪問到。
destructor參數是線程本地數據的回收函數指針
int pthread_key_delete(pthread_key_t key);
用於回收線程本地存儲區。key參數就要回收的存儲區的句柄。
void* pthread_getspecific(pthread_key_t key);
獲取線程本地存儲區的數據
int pthread_setspecific(pthread_key_t key, const void *value);
設置線程本地存儲區的數據。
本文出自 “生命不息,奮斗不止” 博客,轉載請與作者聯系!


