


下的 VFS 文件系統機制。
1. 摘要
本文闡述 Linux 中的文件系統部分,源代碼來自基於 IA32 的 2.4.20 內核。總體上說 Linux 下的文件系統主要可分為三大塊:一是上層的文件系統的系統調用,
二是虛擬文件系統 VFS(Virtual Filesystem Switch),三是掛載到 VFS 中的各實際文件系統,例如 ext2,jffs 等。本文側重於通過具體的代碼分析來解釋 Linux
內核中 VFS 的內在機制,在這過程中會涉及到上層文件系統調用和下層實際文件系統的如何掛載。文章試圖從一個比較高的角度來解釋 Linux 下的 VFS 文件
系統機制,所以在敘述中更側重於整個模塊的主脈絡,而不拘泥於細節,同時配有若干張插圖,以幫助讀者理解。
相對來說,VFS 部分的代碼比較繁瑣復雜,希望讀者在閱讀完本文之後,能對 Linux 下的 VFS 整體運作機制有個清楚的理解。建議讀者在閱讀本文前,
先嘗試著自己閱讀一下文件系統的源代碼,以便建立起 Linux 下文件系統最基本的概念,比如至少應熟悉 super block, dentry, inode,vfsmount 等數據結構所
表示的意義,這樣再來閱讀本文以便加深理解。
Linux 都首先要在內存當中構造一棵 VFS 的目錄樹(在 Linux 的源代碼裡稱之為 namespace),實際上便是在內存中建立相應的數據結構。VFS 目
錄樹在 Linux 的文件系統模塊中是個很重要的概念,希望讀者不要將其與實際文件系統目錄樹混淆,在筆者看來,VFS 中的各目錄其主要用途是
用來提供實際文件系統的掛載點,當然在 VFS 中也會涉及到文件級的操作,本文不闡述這種情況。下文提到目錄樹或目錄,如果不特別說明,
均指 VFS 的目錄樹或目錄。圖 1 是一種可能的目錄樹在內存中的影像:
圖 1:VFS 目錄樹結構
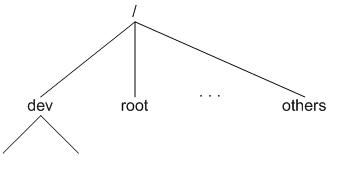
並不意味著它們一定要存在於某種特定的存儲設備上。比如在筆者的 Linux 機器下就注冊有 "rootfs"、"proc"、"ext2"、"sockfs" 等十幾種文件系統。
struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*read_super) (struct super_block *, void *, int);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
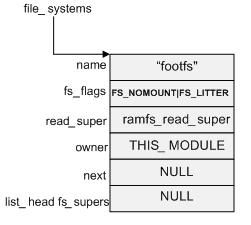
};注冊過程實際上將表示各實際文件系統的 struct file_system_type 數據結構的實例化,然後形成一個鏈表,內核中用一個名為 file_systems 的全局變量來指向該鏈表的表頭。
本土文件系統,那麼 rootfs 文件系統則是 VFS 存在的基礎。一般文件系統的注冊都是通過 module_init 宏以及 do_initcalls() 函數來完成(讀者可通過
閱讀module_init 宏的聲明及 arch\i386\vmlinux.lds 文件來理解這一過程),但是 rootfs 的注冊卻是通過 init_rootfs() 這一初始化函數來完成,這意味
著 rootfs 的注冊過程是 Linux 內核初始化階段不可分割的一部分。
init_rootfs() 通過調用 register_filesystem(&rootfs_fs_type) 函數來完成 rootfs 文件系統注冊的,其中rootfs_fs_type 定義如下:
struct file_system_type rootfs_fs_type = { \
name: "rootfs", \
read_super: ramfs_read_super, \
fs_flags: FS_NOMOUNT|FS_LITTER, \
owner: THIS_MODULE, \
}注冊之後的 file_systems 鏈表結構如下圖2所示:圖 2: file_systems 鏈表結構
錄 "/" 的具體過程。構造根目錄的代碼是在 init_mount_tree() 函數 (fs\namespace.c) 中。
首先,init_mount_tree() 函數會調用 do_kern_mount("rootfs", 0, "rootfs", NULL) 來掛載前面已經注冊了的 rootfs 文件系統。這看起來似乎有點奇怪,
因為根據前面的說法,似乎是應該先有掛載目錄,然後再在其上掛載相應的文件系統,然而此時 VFS 似乎並沒有建立其根目錄。沒關系,這是因
為這裡我們調用的是 do_kern_mount(),這個函數內部自然會創建我們最關心也是最關鍵的根目錄(在 Linux 中,目錄對應的數據結構是 struct dentry)。
在這個場景裡,do_kern_mount() 做的工作主要是:
1)調用 alloc_vfsmnt() 函數在內存裡申請了一塊該類型的內存空間(struct vfsmount *mnt),並初始化其部分成員變量。
2) 調用 get_sb_nodev() 函數在內存中分配一個超級塊結構 (struct super_block) sb,並初始化其部分成員變量,將成員 s_instances 插入到
rootfs 文件系統類型結構中的 fs_supers 指向的雙向鏈表中。
3) 通過 rootfs 文件系統中的 read_super 函數指針調用 ramfs_read_super() 函數。還記得當初注冊rootfs 文件系統時,其成員 read_super 指針指向了 ramfs_read_super() 函數,參見圖2.
4) ramfs_read_super() 函數調用 ramfs_get_inode() 在內存中分配了一個 inode 結構 (struct inode) inode,並初始化其部分成員變量,其中比較重要
的有 i_op、i_fop 和 i_sb:
inode->i_op = &ramfs_dir_inode_operations; inode->i_fop = &dcache_dir_ops; inode->i_sb = sb;這使得將來通過文件系統調用對 VFS 發起的文件操作等指令將被 rootfs 文件系統中相應的函數接口所接管。
圖3
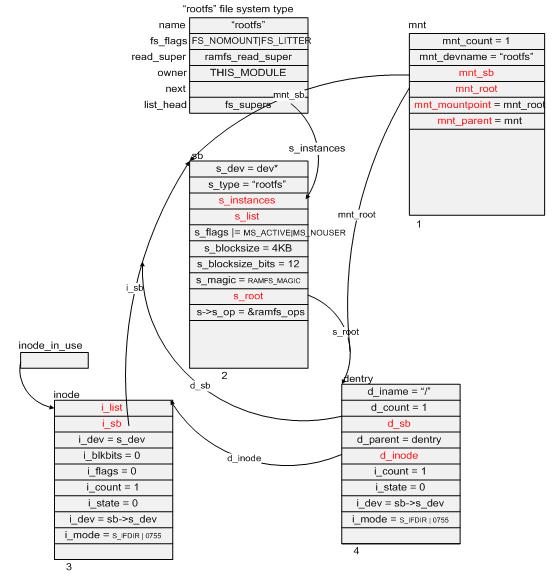 5) ramfs_read_super() 函數在分配和初始化了 inode 結構之後,會調用 d_alloc_root() 函數來為 VFS的目錄樹建立起關鍵的根目錄 (struct dentry)dentry,
5) ramfs_read_super() 函數在分配和初始化了 inode 結構之後,會調用 d_alloc_root() 函數來為 VFS的目錄樹建立起關鍵的根目錄 (struct dentry)dentry,
並將 dentry 中的 d_sb 指針指向 sb,d_inode 指針指向 inode。
6) 將 mnt 中的 mnt_sb 指針指向 sb,mnt_root 和 mnt_mountpoint 指針指向 dentry,而 mnt_parent指針則指向自身。
這樣,當 do_kern_mount() 函數返回時,以上分配出來的各數據結構和 rootfs 文件系統的關系將如上圖 3 所示。圖中 mnt、sb、inode、dentry 結構塊
下方的數字表示它們在內存裡被分配的先後順序。限於篇幅的原因,各結構中只給出了部分成員變量,讀者可以對照源代碼根據圖中所示按圖索骥,
以加深理解。
最後,init_mount_tree() 函數會為系統最開始的進程(即 init_task 進程)准備它的進程數據塊中的namespace 域,主要目的是將 do_kern_mount() 函
數中建立的 mnt 和 dentry 信息記錄在了 init_task 進程的進程數據塊中,這樣所有以後從 init_task 進程 fork 出來的進程也都先天地繼承了這一信
息,在後面用sys_mkdir 在 VFS 中創建一個目錄的過程中,我們可以看到這裡為什麼要這樣做。為進程建立 namespace 的主要代碼如下:
namespace = kmalloc(sizeof(*namespace), GFP_KERNEL);
list_add(&mnt->mnt_list, &namespace->list); //mnt is returned by do_kern_mount()
namespace->root = mnt;
init_task.namespace = namespace;
for_each_task(p) {
get_namespace(namespace);
p->namespace = namespace;
}
set_fs_pwd(current->fs, namespace->root, namespace->root->mnt_root);
set_fs_root(current->fs, namespace->root, namespace->root->mnt_root);該段代碼的最後兩行便是將 do_kern_mount() 函數中建立的 mnt 和 dentry 信息記錄在了當前進程的 fs結構中。以上講了一大堆數據結構的來歷,其實最終目的不過是要在內存中建立一顆 VFS 目錄樹而已,更確切地說, init_mount_tree() 這個函數為 VFS
建立了根目錄 "/",而一旦有了根,那麼這棵數就可以發展壯大,比如可以通過系統調用 sys_mkdir 在這棵樹上建立新的葉子節點等,所以系統
設計者又將 rootfs 文件系統掛載到了這棵樹的根目錄上。關於 rootfs 這個文件系統,讀者如果看一下前面圖 2 中它的file_system_type 結構,
會發現它的一個成員函數指針 read_super 指向的是 ramfs_read_super,單從這個函數名稱中的 ramfs,讀者大概能猜測出這個文件所涉及的文
件操作都是針對內存中的數據對象,事實上也的確如此。從另一個角度而言,因為 VFS 本身就是內存中的一個數據對象,所以在其上的操作僅
限於內存,那也是非常合乎邏輯的事。在接下來的章節中,我們會用一個具體的例子來討論如何利用 rootfs所提供的函樹為 VFS 增加一個新的
目錄節點。
VFS 中各目錄的主要用途是為以後掛載文件系統提供掛載點。所以真正的文件操作還是要通過掛載後的文件系統提供的功能接口來進行。
要在 VFS 中建立一個新的目錄,首先我們得對該目錄進行搜索,搜索的目的是找到將要建立的目錄其父目錄的相關信息,因為"皮之不存,毛將
焉附"。比如要建立目錄 /home/ricard,那麼首先必須沿目錄路徑進行逐層搜索,本例中先從根目錄找起,然後在根目錄下找到目錄 home,然後
再往下,便是要新建的目錄名 ricard,那麼前面講得要先對目錄搜索,在該例中便是要找到 ricard 這個新目錄的父目錄,也就是 home 目錄所對
應的信息。
當然,如果搜索的過程中發現錯誤,比如要建目錄的父目錄並不存在,或者當前進程並無相應的權限等等,這種情況系統必然會調用相關過程
進行處理,對於此種情況,本文略過不提。
Linux 下用系統調用 sys_mkdir 來在 VFS 目錄樹中增加新的節點。同時為配合路徑搜索,引入了下面一個數據結構:
struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;
unsigned int flags;
int last_type;
};這個數據結構在路徑搜索的過程中用來記錄相關信息,起著類似"路標"的作用。其中前兩項中的 dentry記錄的是要建目錄的父目錄的信息,mnt 成員接下來會解釋到。後三項記錄的是所查找路徑的最後一個節點(即待建目錄或文件)的信息。 現在為建立目錄 "/dev" 而調用
sys_mkdir("/dev", 0700),其中參數 0700 我們不去管它,它只是限定將要建立的目錄的某種模式。sys_mkdir 函數首先調用 path_lookup("/dev", LOOKUP_PARENT, &nd);來對路徑進行查找,其中 nd 為 struct nameidata nd 聲明的變量。在接下來的敘述中,因為函數調用關系的繁瑣,
為了突出過程主線,將不再嚴格按照函數的調用關系來進行描述。
path_lookup 發現 "/dev" 是以 "/" 開頭,所以它從當前進程的根目錄開始往下查找,具體代碼如下:
nd->mnt = mntget(current->fs->rootmnt); nd->dentry = dget(current->fs->root);記得在 init_mount_tree() 函數的後半段曾經將新建立的 VFS 根目錄相關信息記錄在了 init_task 進程的進程數據塊中,那麼在這個場景裡,
nd->mnt 便指向了圖 3 中 mnt 變量,nd->dentry 便指向了圖 3 中的 dentry 變量。
然後調用函數 path_walk 接著往下查找,找到最後通過變量 nd 返回的信息是 nd.last.name="dev",nd.last.len=3,nd.last_type=LAST_NORM,
至於 nd 中 mnt 和 dentry 成員,在這個場景裡還是前面設置的值,並無變化。這樣一圈下來,只是用 nd 記錄下相關信息,實際的目錄建立工
作並沒有真正展開,但是前面所做的工作卻為接下來建立新的節點收集了必要的信息。
好,到此為止真正建立新目錄節點的工作將會展開,這是由函數 lookup_create 來完成的,調用這個函數時會傳入兩個參數:
lookup_create(&nd, 1);其中參數 nd 便是前面提到的變量,參數1表明要建立一個新目錄。
這裡的大體過程是:新分配了一個 struct dentry 結構的內存空間,用於記錄 dev 目錄所對應的信息,該dentry 結構將會掛接到其父目錄中,
也就是圖 3 中 "/" 目錄對應的 dentry 結構中,由鏈表實現這一關系。接下來會再分配一個 struct inode 結構。Inode 中的 i_sb 和 dentry 中
的 d_sb 分別都指向圖 3 中的 sb,這樣看來,在同一文件系統下建立新的目錄時並不需要重新分配一個超級塊結構,因為畢竟它們都屬於
同一文件系統,因此一個文件系統只對應一個超級塊。
這樣,當調用 sys_mkdir 成功地在 VFS 的目錄樹中新建立一個目錄 "/dev" 之後,在圖 3 的基礎上,新的數據結構之間的關系便如圖 4 所示。
圖 4 中顏色較深的兩個矩形塊 new_inode 和 new_entry 便是在sys_mkdir() 函數中新分配的內存結構,至於圖中的 mnt,sb,dentry,inode 等結構,
仍為圖 3 中相應的數據結構,其相互之間的鏈接關系不變(圖中為避免過多的鏈接曲線,忽略了一些鏈接關系,如 mnt 和 sb,dentry之間的鏈接,
讀者可在圖 3 的基礎上參看圖 4)。
需要強調一點的是,既然 rootfs 文件系統被 mount 到了 VFS 樹上,那麼它在 sys_mkdir 的過程中必然會參與進來,事實上在整個過程中,
rootfs 文件系統中的 ramfs_mkdir、ramfs_lookup 等函數都曾被調用過。
圖 4: 在 VFS 樹中新建一目錄 "dev"
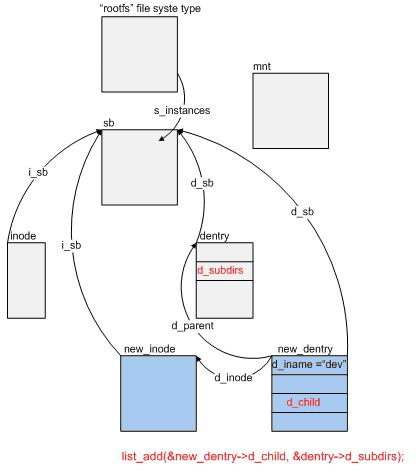
這一過程可簡單描述為:將某一設備(dev_name)上某一文件系統(file_system_type)安裝到VFS目錄樹上的某一安裝點(dir_name)。它要解決的
問題是:將對 VFS 目錄樹中某一目錄的操作轉化為具體安裝到其上的實際文件系統的對應操作。比如說,如果將 hda2 上的根文件系統(假設
文件系統類型為 ext2)安裝到了前一節中新建立的 "/dev" 目錄上(此時,"/dev" 目錄就成為了安裝點),那麼安裝成功之後應達到這樣的目的,
即:對 VFS 文件系統的 "/dev" 目錄執行 "ls" 指令,該條指令應能列出 hda2 上 ext2 文件系統的根目錄下所有的目錄和文件。很顯然,這裡的
關鍵是如何將對 VFS 樹中 "/dev" 的目錄操作指令轉化為安裝在其上的 ext2 這一實際文件系統中的相應指令。所以,接下來的敘述將抓住如何轉
化這一核心問題。在敘述之前,讀者不妨自己設想一下 Linux 系統會如何解決這一問題。記住:對目錄或文件的操作將最終由目錄或文件所
對應的 inode 結構中的 i_op 和 i_fop 所指向的函數表中對應的函數來執行。所以,不管最終解決方案如何,都可以設想必然要通過將對 "/dev"
目錄所對應的 inode 中 i_op 和 i_fop 的調用轉換到 hda2 上根文件系統 ext2 中根目錄所對應的 inode 中 i_op 和 i_fop 的操作。
初始過程由 sys_mount() 系統調用函數發起,該函數原型聲明如下:
asmlinkage long sys_mount(char * dev_name, char * dir_name, char * type, unsigned long flags, void * data);其中,參數 char *type 為標識將要安裝的文件系統類型字符串,對於 ext2 文件系統而言,就是"ext2"。參數 flags 為安裝時的模式標識數,和接
下來的 data 參數一樣,本文不將其做為重點。
為了幫助讀者更好地理解這一過程,筆者用一個具體的例子來說明:我們准備將來自主硬盤第 2 分區(hda2)上的 ext2 文件系統安裝到前面創建
的 "/dev" 目錄中。那麼對於 sys_mount() 函數的調用便具體為:
sys_mount("hda2","/dev ","ext2",…);該函數在將這些來自用戶內存空間(user space)的參數拷貝到內核空間後,便調用 do_mount() 函數開始真正的安裝文件系統的工作。同樣,為了便於敘述和講清楚主流程,接下來的說明將不嚴格按照具體的函數調用細節來進行。
do_mount() 函數會首先調用 path_lookup() 函數來得到安裝點的相關信息,如同創建目錄過程中敘述的那樣,該安裝點的信息最終記錄在 struct
nameidata 類型的一個變量當中,為敘述方便,記該變量為nd。在本例中當 path_lookup() 函數返回時,nd 中記錄的信息如下:nd.entry =
new_entry; nd.mnt = mnt; 這裡的變量如圖 3 和 4 中所示。
然後,do_mount() 函數會根據調用參數 flags 來決定調用以下四個函數之一:do_remount()、 do_loopback()、do_move_mount()、do_add_mount()。
在我們當前的例子中,系統會調用 do_add_mount() 函數來向 VFS 樹中安裝點 "/dev " 安裝一個實際的文件系統。在 do_add_mount() 中,主要
完成了兩件重要事情:一是獲得一個新的安裝區域塊,二是將該新的安裝區域塊加入了安裝系統鏈表。它們分別是調用 do_kern_mount() 函數和
graft_tree() 函數來完成的。這裡的描述可能有點抽象,諸如安裝區域塊、安裝系統鏈表等,不過不用著急,因為它們都是筆者自己定義出來的概
念,等一下到後面會有專門的圖表解釋,到時便會清楚。
do_kern_mount() 函數要做的事情,便是建立一新的安裝區域塊,具體的內容在前面的章節 VFS 目錄樹的建立中已經敘述過,這裡不再贅述。
graft_tree() 函數要做的事情便是將 do_kern_mount() 函數返回的一 struct vfsmount 類型的變量加入到安裝系統鏈表中,同時 graft_tree() 還要將
新分配的 struct vfsmount 類型的變量加入到一個hash表中,其目的我們將會在以後看到。
這樣,當 do_kern_mount() 函數返回時,在圖 4 的基礎上,新的數據結構間的關系將如圖 5 所示。其中,紅圈區域裡面的數據結構便是被稱做安
裝區域塊的東西,其中不妨稱 e2_mnt 為安裝區域塊的指針,藍色箭頭曲線即構成了所謂的安裝系統鏈表。
在把這些函數調用後形成的數據結構關系理清楚之後,讓我們回到本章節開始提到的問題,即將 ext2 文件系統安裝到了 "/dev " 上之後,對該目
錄上的操作如何轉化為對 ext2 文件系統相應的操作。從圖 5上看到,對 sys_mount() 函數的調用並沒有直接改變 "/dev " 目錄所對應的 inode
(即圖中的 new_inode變量)結構中的 i_op 和 i_fop 指針,而且 "/dev " 所對應的 dentry(即圖中的 new_dentry 變量)結構仍然在 VFS 的目錄樹中
,並沒有被從其中隱藏起來,相應地,來自 hda2 上的 ext2 文件系統的根目錄所對應的 e2_entry 也不是如當初筆者所想象地那樣將 VFS 目錄
樹中的 new_dentry 取而代之,那麼這之間的轉化到底是如何實現的呢?
請讀者注意下面的這段代碼:
while (d_mountpoint(dentry) && __follow_down(&nd->mnt, &dentry));這段代碼在 link_path_walk() 函數中被調用,而 link_path_walk() 最終又會被 path_lookup() 函數調用,如果讀者閱讀過 Linux 關於文件系統部分
的代碼,應該知道 path_lookup() 函數在整個 Linux 繁瑣的文件系統代碼中屬於一個重要的基礎性的函數。簡單說來,這個函數用於解析文件路
徑名,這裡的文件路徑名和我們平時在應用程序中所涉及到的概念相同,比如在 Linux 的應用程序中 open 或 read 一個文件 /home/windfly.cs 時,
這裡的 /home/windfly.cs 就是文件路徑名,path_lookup() 函數的責任就是對文件路徑名中進行搜索,直到找到目標文件所屬目錄所對應的 dentry
或者目標直接就是一個目錄,筆者不想在有限的篇幅裡詳細解釋這個函數,讀者只要記住 path_lookup() 會返回一個目標目錄即可。
上面的代碼非常地不起眼,以至於初次閱讀文件系統的代碼時經常會忽略掉它,但是前文所提到從 VFS 的操作到實際文件系統操作的轉化卻是由
它完成的,對 VFS 中實現的文件系統的安裝可謂功不可沒。現在讓我們仔細剖析一下該段代碼: d_mountpoint(dentry) 的作用很簡單,它只是
返回 dentry 中 d_mounted 成員變量的值。這裡的dentry 仍然還是 VFS 目錄樹上的東西。如果 VFS 目錄樹上某個目錄被安裝過一次,那麼該
值為 1。對VFS 中的一個目錄可進行多次安裝,後面會有例子說明這種情況。在我們的例子中,"/dev" 所對應的new_dentry 中 d_mounted=1,
所以 while 循環中第一個條件滿足。下面再來看__follow_down(&nd->mnt, &dentry)代
圖 5:安裝 ext2 類型根文件系統到 "/dev " 目錄上
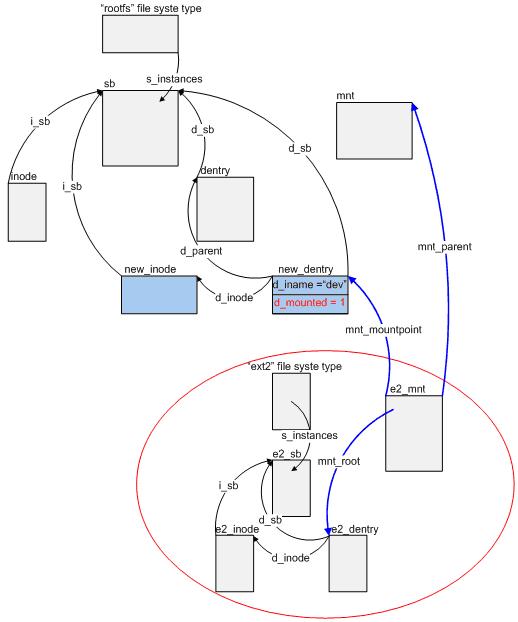 碼做了什麼?到此我們應該記住,這裡 nd 中的 dentry 成員就是圖 5 中的 new_dentry,nd 中的 mnt成員就是圖 5 中的 mnt,所以我們現在可以把 __follow_down(&nd->mnt, &dentry) 改寫成__follow_down(&mnt, &new_dentry),接下來我們將 __follow_down() 函數的代碼改寫(只是去處掉一些
碼做了什麼?到此我們應該記住,這裡 nd 中的 dentry 成員就是圖 5 中的 new_dentry,nd 中的 mnt成員就是圖 5 中的 mnt,所以我們現在可以把 __follow_down(&nd->mnt, &dentry) 改寫成__follow_down(&mnt, &new_dentry),接下來我們將 __follow_down() 函數的代碼改寫(只是去處掉一些
不太相關的代碼,並且為了便於說明,在部分代碼行前加上了序號)如下:
static inline int __follow_down(struct vfsmount **mnt, struct dentry **dentry)
{
struct vfsmount *mounted;
[1] mounted = lookup_mnt(*mnt, *dentry);
if (mounted) {
[2] *mnt = mounted;
[3] *dentry = mounted->mnt_root;
return 1;
}
return 0;
}代碼行[1]中的 lookup_mnt() 函數用於查找一個 VFS 目錄樹下某一目錄最近一次被 mount 時的安裝區域塊的指針,在本例中最終會返回圖 5 中的 e2_mnt。至於查找的原理,這裡粗略地描述一下。記得當我們在安裝 ext2 文件系統到 "/dev" 時,在後期會調用 graft_tree() 函數,在這個函
數裡會把圖 5 中的安裝區域塊指針 e2_mnt 掛到一 hash 表(Linux 2.4.20源代碼中稱之為 mount_hashtable)中的某一項,而該項的鍵值就是由被
安裝點所對應的 dentry(本例中為 new_dentry)和 mount(本例中為 mnt)所共同產生,所以自然地,當我們知道 VFS 樹中某一 dentry 被安裝過
(該 dentry 變成為一安裝點),而要去查找其最近一次被安裝的安裝區域塊指針時,同樣由該安裝點所對應的 dentry 和 mount 來產生一鍵值,以
此值去索引 mount_hashtable,自然可找到該安裝點對應的安裝區域塊指針形成的鏈表的頭指針,然後遍歷該鏈表,當發現某一安裝區域塊指針,
記為 p,滿足以下條件時:
(p->mnt_parent == mnt && p->mnt_mountpoint == dentry)P 便為該安裝點所對應的安裝區域塊指針。當找到該指針後,便將 nd 中的 mnt 成員換成該安裝區域塊指針,同時將 nd 中的 dentry 成員換成安
裝區域塊中的 dentry 指針。在我們的例子中,e2_mnt->mnt_root成員指向 e2_dentry,也就是 ext2 文件系統的 "/" 目錄。這樣,當 path_lookup()
函數搜索到 "/dev"時,nd 中的 dentry 成員為 e2_dentry,而不再是原來的 new_dentry,同時 mnt 成員被換成 e2_mnt,轉化便在不知不覺中完成了。
現在考慮一下對某一安裝點多次安裝的情況,同樣作為例子,我們假設在 "/dev" 上安裝完一個 ext2文件系統後,再在其上安裝一個 ntfs 文件系統。
在安裝之前,同樣會對安裝點所在的路徑調用path_lookup() 函數進行搜索,但是這次由於在 "/dev" 目錄上已經安裝過了 ext2 文件系統,所以搜索
到最後,由 nd 返回的信息是:nd.dentry = e2_dentry, nd.mnt = e2_mnt。由此可見,在第二次安裝時,安裝點已經由 dentry 變成了 e2_dentry。
接下來,同樣地,系統會再分配一個安裝區域塊,假設該安裝區域塊的指針為 ntfs_mnt,區域塊中的 dentry 為 ntfs_dentry。ntfs_mnt 的父指針
指向了e2_mnt,mnfs_mnt 中的 mnt_root 指向了代表 ntfs 文件系統根目錄的 ntfs_dentry。然後,系統通過 e2_dentry和 e2_mnt 來生成一個新的
hash 鍵值,利用該值作為索引,將 ntfs_mnt 加入到 mount_hashtable 中,同時將 e2_dentry 中的成員 d_mounted 值設定為 1。這樣,安裝過程
便告結束。
讀者可能已經知道,對同一安裝點上的最近一次安裝會隱藏起前面的若干次安裝,下面我們通過上述的例子解釋一下該過程:
在先後將 ext2 和 ntfs 文件系統安裝到 "/dev" 目錄之後,我們再調用 path_lookup() 函數來對"/dev" 進行搜索,函數首先找到 VFS 目錄樹下的安裝
點 "/dev" 所對應的 dentry 和 mnt,此時它發現dentry 成員中的 d_mounted 為 1,於是它知道已經有文件系統安裝到了該 dentry 上,於是它通過
dentry 和 mnt 來生成一個 hash 值,通過該值來對 mount_hashtable 進行搜索,根據安裝過程,它應該能找到 e2_mnt 指針並返回之,同時原先的
dentry 也已經被替換成 e2_dentry。回頭再看一下前面已經提到的下列代碼: while (d_mountpoint(dentry) && __follow_down(&nd->mnt, &dentry));
當第一次循環結束後, nd->mnt 已經是 e2_mnt,而 dentry 則變成 e2_dentry。此時由於 e2_dentry 中的成員 d_mounted 值為 1,所以 while 循環的
第一個條件滿足,要繼續調用 __follow_down() 函數,這個函數前面已經剖析過,當它返回後 nd->mnt 變成了 ntfs_mnt,dentry 則變成了 ntfs_dentry。
由於此時 ntfs_dentry 沒有被安裝過其他文件,所以它的成員 d_mounted 應該為 0,循環結束。對 "/dev" 發起的 path_lookup() 函數最終返回了 ntfs
文件系統根目錄所對應的 dentry。這就是為什麼 "/dev" 本身和安裝在其上的 ext2 都被隱藏的原因。如果此時對 "/dev" 目錄進行一個 ls 命令,將返
回安裝上去的 ntfs 文件系統根目錄下所有的文件和目錄。
是一樣的。
這個過程大致是:首先要確定待安裝的 ext2 文件系統的來源,其次是確定 ext2 文件系統在 VFS中的安裝點,然後便是具體的安裝過程。
關於第一問題,Linux 2.4.20 的內核另有一大堆的代碼去解決,限於篇幅,筆者不想在這裡去具體說明這個過程,大概記住它是要解決到哪裡去
找要安裝的文件系統的就可以了,這裡我們不妨就認為要安裝的根文件系統就來自於主硬盤的第一分區 hda1.
關於第二個問題,Linux 2.4.20 的內核把來自於 hda1 上 ext2 文件系統安裝到了 VFS 目錄樹中的"/root" 目錄上。其實,把 ext2 文件系統安裝到
VFS 目錄樹下的哪個安裝點並不重要(VFS 的根目錄除外),只要是這個安裝點在 VFS 樹中是存在的,並且內核對它沒有另外的用途。如果讀者
喜歡,盡可以自己在 VFS 中創建一個 "/Windows" 目錄,然後將 ext2 文件系統安裝上去作為將來用戶進程的根目錄,沒有什麼不可以的。問題的
關鍵是要將進程的根目錄和當前工作目錄設定好,因為畢竟只用用戶進程才去關心現實的文件系統,要知道筆者的這篇稿子可是要存到硬盤上去的。
在 Linux 下,設定一個進程的當前工作目錄是通過系統調用 sys_chdir() 進行的。初始化期間,Linux 在將 hda1 上的 ext2 文件系統安裝到了 "/root"
上後,通過調用 sys_chdir("/root") 將當前進程,也就是 init_task 進程的當前工作目錄(pwd)設定為 ext2 文件系統的根目錄。記住此時 init_task進
程的根目錄仍然是圖 3 中的 dentry,也就是 VFS 樹的根目錄,這顯然是不行的,因為以後 Linux 世界中的所有進程都由這個 init_task 進程派生出
來,無一例外地要繼承該進程的根目錄,如果是這樣,意味著用戶進程從根目錄搜索某一目錄時,實際上是從 VFS 的根目錄開始的,而事實上卻
是從 ext2 的根文件開始搜索的。這個矛盾的解決是靠了在調用完 mount_root() 函數後,系統調用的下面兩個函數:
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot(".");其主要作用便是將 init_task 進程的根目錄轉化成安裝上去的 ext2 文件系統的根目錄。有興趣的讀者可以自行去研究這一過程。所以在用戶空間下,更多地情況是只能見到 VFS 這棵大樹的一葉,而且還是被安裝過文件系統了的,實際上對用戶空間來說還是不可見。我想,
VFS 更多地被內核用來實現自己的功能,並以系統調用的方式提供過用戶進程使用,至於在其上實現的不同文件系統的安裝,也只是其中的一
個功能罷了。
須要能越過文件系統這一關。當然閱讀其源代碼便是其中最好的方法,本文試圖給那些已經嘗試著去閱讀,但是目前尚有困惑的讀者畫一張 VFS 文
件系統的草圖,希望能對讀者有些許啟發。但是想在如此有限的篇幅裡去闡述清楚 Linux 中整個文件系統的來龍去脈,是根本不現實的。而且本文也
只是側重於剖析 VFS 的機制,對於象具體的文件讀寫,為提高效率而引入的各種 buffer,hash 等內容以及文件系統的安全性方面,都沒有提到。
畢竟,本文只想幫助讀者理清一個大體的脈絡,最終的理解與領悟,還得靠讀者自己去潛心研究源代碼。最後,對本文相關的任何問題或建議,
都歡迎用 email 和筆者聯系。
(http://www.ibm.com/developerworks/cn/linux/l-vfs/)