


三年多前,我在騰訊負責的活動運營系統,因為業務流量規模的數倍增長,系統出現了各種各樣的異常,當時,作為開發的我,7*24小時地沒日沒夜處理告警,周末和凌晨也經常上線,疲於奔命。後來,當時的老領導對我說:你不能總扮演一個“救火隊長”的角色, 要嘗試從系統整體層面思考產生問題的根本原因,然後推進解決。我幡然醒悟,“火”是永遠救不完的,讓系統能夠自動”滅火”,才是解決問題的正確方向。簡而言之,系統的異常不能總是依賴於“人”去恢復,讓系統本身具備“容錯”能力,才是根本解決之道。三年多過去了,我仍然負責著這個系統,而它也已經從一個日請求百萬級的小Web系統,逐步成長為一個高峰日請求達到8億規模的平台級系統,走過一段令人難忘的技術歷程。
容錯其實是系統健壯性的重要指標之一,而本文會主要聚焦於“容錯”能力的實踐,希望對做技術的同學有所啟發和幫助。
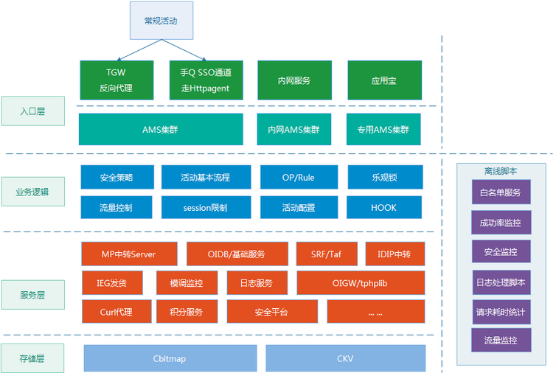
(備注:QQ會員活動運營平台,後面統一簡稱AMS)

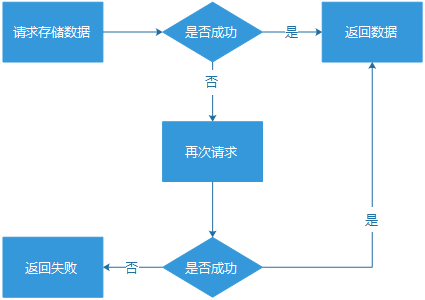
簡單重試,要使用在恰當的場景。或者,主動計算服務成功率,成功率過低,就直接不做重試行為,避免帶來過高的流量沖擊。
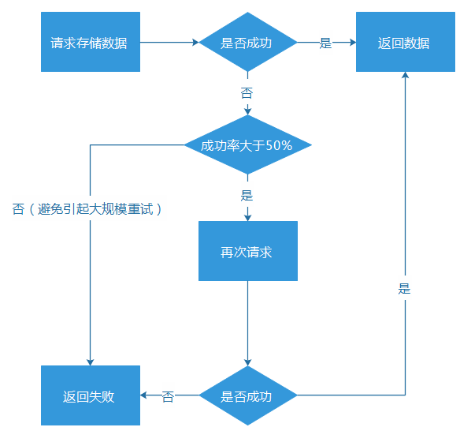
 這種重試的機制,看似比較可用,而實際上也存在一些問題:
這種重試的機制,看似比較可用,而實際上也存在一些問題:
(1) 通常會存在“資源浪費”的問題。因為備份服務系統,很可能長期處於閒置狀態,只有在主服務異常的時候,它的資源才會被比較充分地使用。不過,如果對於核心的服務業務(例如核心數據、營收相關)進行類似的部署,雖然會增加一些機器成本和預算,但這個付出通常也是物有所值的。
(2) 觸發重試機制,對於用戶的請求來說,耗時必然增加。主服務請求失敗,然後再到備份服務請求,這個環節的請求耗時就至少翻倍增長,假設主服務出現連接(connect)超時,那麼耗時就更是大幅度增加。一個服務在正常狀態下,獲取數據也許只要50ms,而服務的超時時間通常會設置到500-1000ms,甚至更多,一旦出現超時重試的場景,請求耗時必然大幅度增長,很可能會比較嚴重地影響用戶體驗。
(3) 主備服務一起陷入異常。如果是因為流量過大問題導致主服務異常,那麼備份服務很可能也會承受不住這種級別的流量而掛掉。
重試的容錯機制,在AMS上有使用,但是相對比較少,因為我們認為主備服務,還是不足夠可靠。
(2) 支持平行擴容。遇到大流量場景,支持加機器擴容。
(3) 自動剔除異常機器。在我們的路由服務,發現某個服務的機器異常的時候(成功率低於50%),就會自動剔除該機器,後續,會發出試探性的請求,確認等它恢復正常之後,再重新加回到服務機器組。
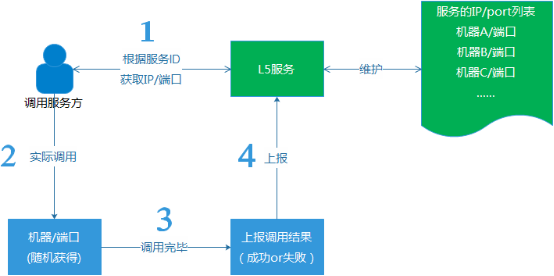 例如,假如一組服務下擁有服務機器四台(ABCD),假設A機器的服務因為某種未知原因,完全不可用了,這個時候L5服務會主動將A機器自動從服務組裡剔除,只保留BCD三台機器對外提供服務。而在後續,假如A機器從異常中恢復了,那麼L5再主動將機器A加回來,最後,又變成ABCD四台機器對外提供服務。
例如,假如一組服務下擁有服務機器四台(ABCD),假設A機器的服務因為某種未知原因,完全不可用了,這個時候L5服務會主動將A機器自動從服務組裡剔除,只保留BCD三台機器對外提供服務。而在後續,假如A機器從異常中恢復了,那麼L5再主動將機器A加回來,最後,又變成ABCD四台機器對外提供服務。
在過去的3年裡,我們逐步將AMS內的服務,漸漸從寫死IP列表或者主備狀態的服務,全部升級和優化為L5模式的服務,慢慢實現了AMS後端服務的自我容錯能力。至少,我們已經比較少遇到,再因為某一台機器的軟件或者硬件故障,而不得不人工介入處理的情況。我們也慢慢地從疲於奔命地處理告警的苦難中,被解放出來。
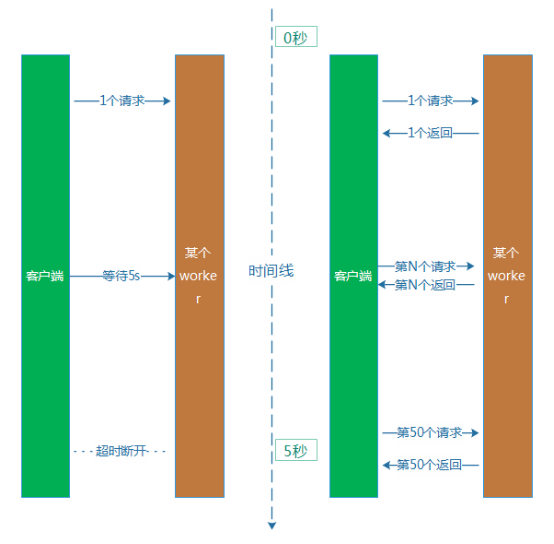 算上網絡通信和其他環節的耗時,用戶就等待了超過5s時間,最後卻獲得一個異常的結果,用戶的心情通常是崩潰的。
算上網絡通信和其他環節的耗時,用戶就等待了超過5s時間,最後卻獲得一個異常的結果,用戶的心情通常是崩潰的。
解決這個問題的方式,就是設置一個合理的超時時間。例如,回到上面的的例子,平均處理耗時是100ms,那麼我們不如將超時時間從5s下調到500ms。從直觀上看,它就解決了吞吐率下降和用戶等待過長的問題。然而,這樣做本身又比較容易帶來新的問題,就是會引起服務的成功率下降。因為平均耗時是100ms,但是,部分業務請求本身耗時比較長,耗時超過500ms也比較多。例如,某個請求服務端耗時600ms才處理完畢,然後這個時候,客戶端認為等待超過500ms,已經斷開了連接。處理耗時比較長的這類型業務請求會受到比較明顯的影響。
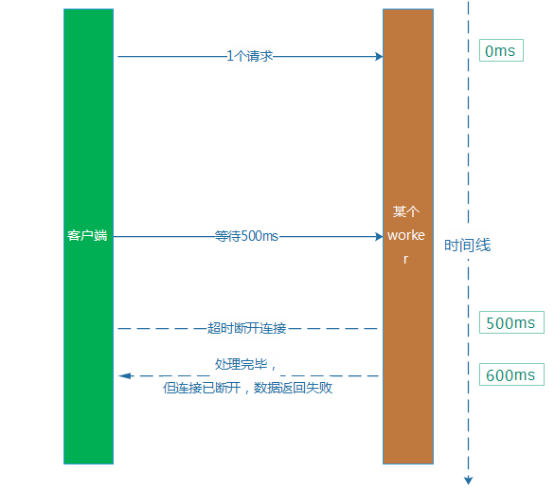
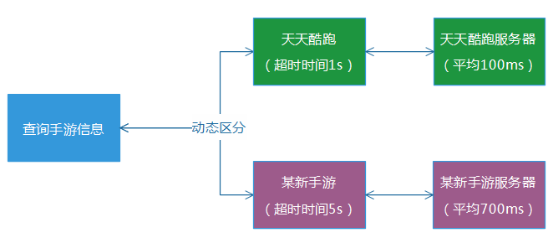
(1) 快慢分離
根據實際的業務維度,區分對待地給各個業務服務配置不同的超時時間,同時,最好也將它們的部署服務也分離出來。例如,天天酷跑的查詢服務耗時通常為100ms,那麼超時時間我們就設置為1s,某新手游的查詢服務通常耗時為700ms,那麼我們就設置為5s。這樣的話,整體系統的成功率,就不會受到比較大的影響。
 (2) 解決同步阻塞等待
(2) 解決同步阻塞等待
“快慢分離”可以改善系統的同步等待問題,但是,對於某些耗時本來就比較長的服務而言,系統的進程/線程資源仍然在同步等待過程中,無法響應其他新的請求,只能阻塞等待,它的資源仍然是被占據,系統的整體吞吐率仍然被大幅度拉低。
解決的思路,當然是利用I/O多路復用,通過異步回調的方式,解決同步等待過程中的資源浪費。AMS的一些核心服務,采用的就是“協程”(又叫“微線程”,簡單的說,常規異步程序代碼裡嵌套比較多層的函數回調,編寫復雜。而協程則提供了一種類似寫同步代碼的方式,來寫異步回調程序),以解決同步等待的問題。異步處理的簡單描述,就是當進程遇到I/O網絡阻塞時,就保留現場,立刻切換去處理下一個業務請求,進程不會因為某個網絡等待而停止處理業務,進而,系統吞吐率即使遇到網絡等待時間過長的場景,通常都能保持在比較高的水平。
值得補充一點的是,異步處理只是解決系統的吞吐率問題,對於用戶的體驗問題,並不會有改善,用戶需要等待的時間並不會減少。
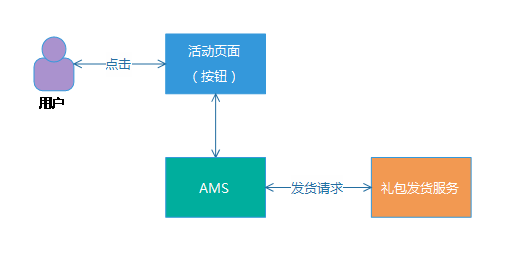
(1) 發貨等待超時,發貨服務執行發貨失敗。這種場景,問題不大,後續用戶重新點擊領取按鈕,就可以觸發下一次重新發貨。
(2) 發貨等待超時,發貨服務實際在更晚的時候執行發貨成功,我們稱之為“超時成功”。比較麻煩的場景,則是每次都是發貨超時,而實際上都發貨成功,如果系統設計不當,有可能導致用戶可以無限領取禮包,最終造成活動運營事故。
第二種場景,給我們帶來了比較麻煩的問題,如果處理不當,用戶再次點擊,就觸發第多次“額外”發貨。
例如,我們假設某個發貨服務超時時間設置為6s,用戶點擊按鈕,我們的AMS收到請求後,請求發貨服務發貨,等待6s後,無響應,我們給用戶提示“領取失敗”,而實際上發貨服務卻在第8秒執行發貨成功,禮包到了用戶的賬戶上。而用戶看見“領取失敗”,則又再次點擊按鈕,最終導致“額外”多發一個禮包給到這個用戶。
例子的時序和流程圖大致如下:
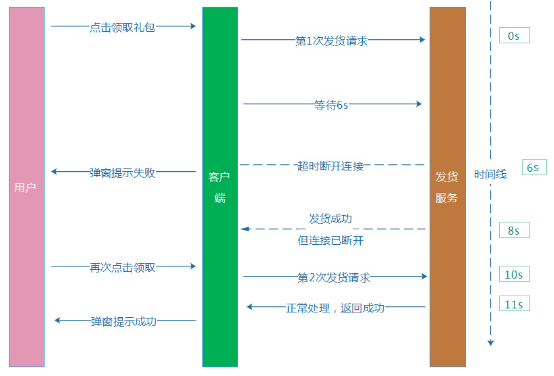 這裡就提到了防重入,簡單的說,就是如何確認不管用戶點擊多少次這個領取按鈕,我們都確保結果只有一種預期結果,就是只會給用戶發一次禮包,而不引起重復發貨。我們的AMS活動運營平台一年上線的活動超過4000個,涉及數以萬計的各種類型、不同業務系統的禮包發貨,業務通信場景比較復雜。針對不同的業務場景,我們做了不同的解決方案:
這裡就提到了防重入,簡單的說,就是如何確認不管用戶點擊多少次這個領取按鈕,我們都確保結果只有一種預期結果,就是只會給用戶發一次禮包,而不引起重復發貨。我們的AMS活動運營平台一年上線的活動超過4000個,涉及數以萬計的各種類型、不同業務系統的禮包發貨,業務通信場景比較復雜。針對不同的業務場景,我們做了不同的解決方案:
(1) 業務層面限制,設置禮包單用戶限量。在發貨服務器的源頭,設置好一個用戶僅能最多獲得1個禮包,直接避免重復發放。但是,這種業務限制,並非每個業務場景都通用的,只限於內部具備該限制能力的業務發貨系統,並且,有一些禮包本身就可以多次領取的,就不適用了。
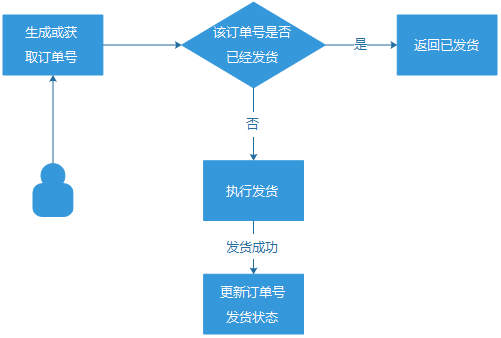
(2) 訂單號機制。用戶的每一次符合資格的發貨請求,都生成一個訂單號與之對應,通過它來確保1個訂單號,只發貨1次。這個方案雖然比較完善,但是,它是依賴於發貨服務方配合做“訂單號發貨狀態更新“的,而我們的發貨業務方眾多,並非每一個都能支持”訂單號更新“的場景。
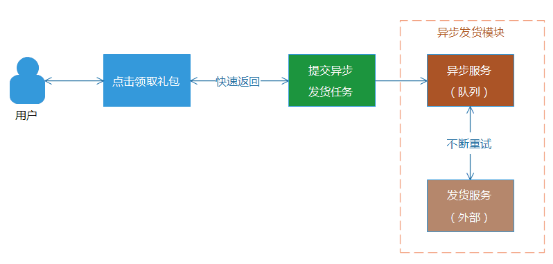
 (3) 自動重試的異步發貨模式。用戶點擊領取禮包按鈕後,Web端直接返回成功,並且提示禮包在30分鐘內到賬。對於後台,則將該發貨錄入到發貨隊列或者存儲中,等待發貨服務異步發貨。因為是異步處理,可以多次執行發貨重試操作,直到發貨成功為止。同時,異步發貨是可以設置一個比較長的超時等待時間,通常不會出現“超時成功”的場景,並且對於前端響應來說,不需要等待後台發貨狀態的返回。但是,這種模式,會給用戶帶來比較不好的體驗,就是沒有實時反饋,無法立刻告訴用戶,禮包是否到賬。
(3) 自動重試的異步發貨模式。用戶點擊領取禮包按鈕後,Web端直接返回成功,並且提示禮包在30分鐘內到賬。對於後台,則將該發貨錄入到發貨隊列或者存儲中,等待發貨服務異步發貨。因為是異步處理,可以多次執行發貨重試操作,直到發貨成功為止。同時,異步發貨是可以設置一個比較長的超時等待時間,通常不會出現“超時成功”的場景,並且對於前端響應來說,不需要等待後台發貨狀態的返回。但是,這種模式,會給用戶帶來比較不好的體驗,就是沒有實時反饋,無法立刻告訴用戶,禮包是否到賬。
 通常一個發貨服務如果出現異常,大多數情況,在connect步驟就是失敗或者超時,而如果一個請求走到等待回包(read)時超時,那麼發貨服務另外一邊就有可能發生了“超時但發貨成功”的場景。這個時候,我們將read超時的發生次數記錄起來,然後提供了一個配置限制次數的能力。假如設置為2次,那麼當一個用戶第一次領取禮包,遇到read超時,我們就允許它重試,當還遇到第二次read超時,就達到我們之前設置的閥值2,我們就認為它可能發貨成功,拒絕用戶的第三次領取請求。
通常一個發貨服務如果出現異常,大多數情況,在connect步驟就是失敗或者超時,而如果一個請求走到等待回包(read)時超時,那麼發貨服務另外一邊就有可能發生了“超時但發貨成功”的場景。這個時候,我們將read超時的發生次數記錄起來,然後提供了一個配置限制次數的能力。假如設置為2次,那麼當一個用戶第一次領取禮包,遇到read超時,我們就允許它重試,當還遇到第二次read超時,就達到我們之前設置的閥值2,我們就認為它可能發貨成功,拒絕用戶的第三次領取請求。
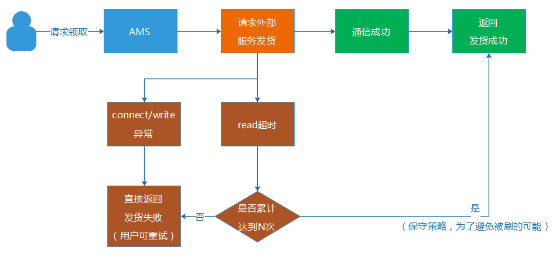 這種做法,假設發貨服務真的出現很多超時成功,那麼用戶也最多只能刷到2次禮包(次數可配置),而避免發生禮包無限制被刷的場景。但是,這種方案並不完全可靠,謹慎使用。
這種做法,假設發貨服務真的出現很多超時成功,那麼用戶也最多只能刷到2次禮包(次數可配置),而避免發生禮包無限制被刷的場景。但是,這種方案並不完全可靠,謹慎使用。
在發貨場景,還會涉及分布式場景下的CAP(一致性、可用性、分區容錯性)問題,不過,我們的系統並非是一個電商服務,大部分的發貨並沒有強烈的一致性要求。因此,總體而言,我們是弱化了一致性問題(核心服務,通過異步重試的方式,達到最終一致性),以追求可用性和分區容錯性的保證。
例如,2015年下半年,我們就將其中一個核心的存儲數據,從1個分離為3個。
 這樣做帶來了很多好處:
這樣做帶來了很多好處:
(1) 原來主存儲的壓力被分流。
(2) 穩定性更高,不再是其中一個出問題,影響整個大的模塊。
(3) 存儲之間是彼此物理隔離的,即使服務器硬件故障,也不會相互影響。
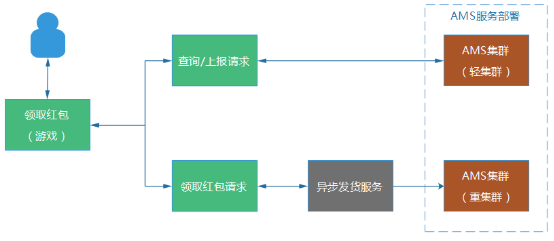
輕重分離的這個部署方式,可以給我們帶來一些好處:
(1) 查詢集群即使出問題,也不會影響發貨集群,保證用戶核心功能正常。
(2) 兩邊的機器和部署的服務基本一致,在緊急的情況下,兩邊的集群可以相互支援和切換,起到容災的效果。
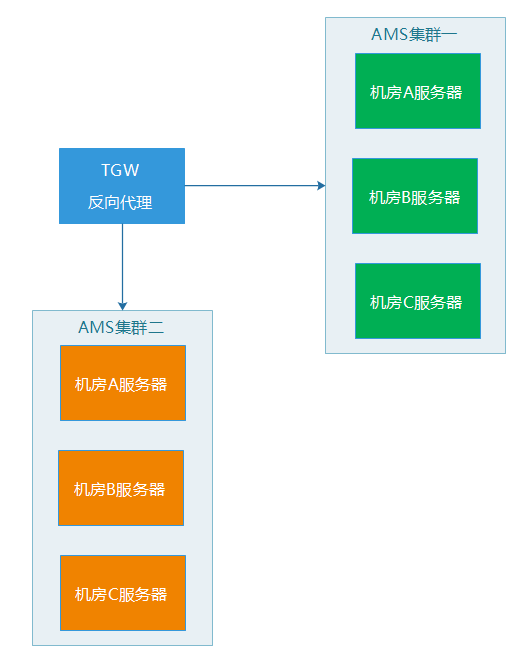
(3) 每個集群裡的機器,都是跨機房部署,例如,服務器都是分布在ABC三個機房,假設B機房整個網絡故障了,反向代理服務會將無法接受服務的B機房機器剔除,然後,剩下AC機房的服務器仍然可以正常為外界提供服務。
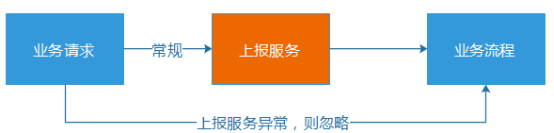
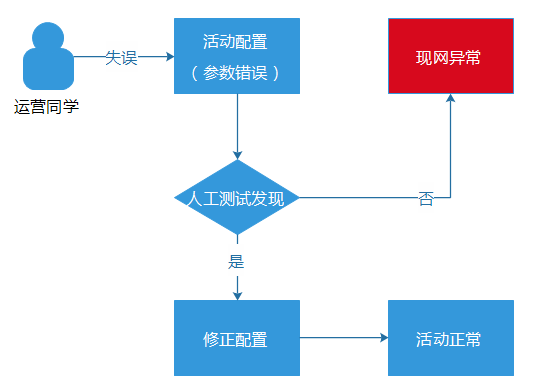
例如,某個運營同學看錯禮包發放的日限量,將原本只允許1天放量100個禮包的資源,錯誤地配置為每天放量200個。這種錯誤是測試同學比較難測試出來的,等到活動真正上線,禮包發放到101個的時候,就報錯了,因為資源池當天已經沒有資源了。雖然,我們的業務告警系統能夠快速捕獲到這個異常(每10分鐘為一個周期,從十多個維度,監控和計算各個活動的成功率、流量波動等等數據),但是,對於騰訊的用戶量級來說,即使只影響十多分鐘,也可以影響成千上萬的用戶,對於大規模流量的推廣活動,甚至可以影響數十萬用戶了。這樣的話,就很容易就造成嚴重的“現網事故”。
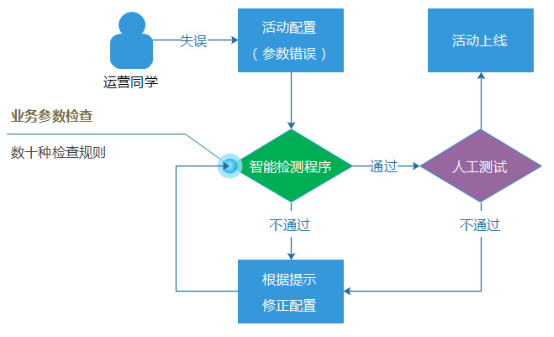
 完善的監控系統能夠及時發現問題,防止影響面的進一步擴大和失控,但是,它並不能杜絕現網問題的發生。而真正的根治之法,當然是從起源的地方杜絕這種場景的出現,回到上面“日限量配置錯誤”的例子場景中,用戶在內部管理端發布活動配置時,就直接提示運營同學,這個配置規則是不對的。
完善的監控系統能夠及時發現問題,防止影響面的進一步擴大和失控,但是,它並不能杜絕現網問題的發生。而真正的根治之法,當然是從起源的地方杜絕這種場景的出現,回到上面“日限量配置錯誤”的例子場景中,用戶在內部管理端發布活動配置時,就直接提示運營同學,這個配置規則是不對的。
在業界,因為配置參數錯誤而導致的現網重大事故的例子,可以說是多不勝數,“配置參數問題”幾乎可以說是一個業界難題,對於解決或者緩解這種錯誤的發生,並沒有放之四海而皆准的方法,更多的是需要根據具體業務和系統場景,亦步亦趨地逐步建設配套的檢查機制程序或者腳本。
因此,我們建設了一套強大並且智能的配置檢查系統,裡面集合了數十種業務的搭配檢查規則,並且檢查規則的數目一直都在增加。這裡規則包括檢查禮包日限量之類比較簡單的規則,也有檢查各種關聯配置參數、相對比較復雜的業務邏輯規則。
 另外一方面,流程的執行不能通過“口頭約定”,也應該固化為平台程序的一部分,例如,活動上線之前,我們要求負責活動的同事需要驗證一下“禮包領取邏輯”,也就是真實的去領取一次禮包。然而,這只是一個“口頭約定”,實際上並不具備強制執行力,如果這位同事因為活動的禮包過多,而漏過其中一個禮包的驗證流程,這種事情也的確偶爾會發生,這個也算是“人的失誤”的另外一種場景。
另外一方面,流程的執行不能通過“口頭約定”,也應該固化為平台程序的一部分,例如,活動上線之前,我們要求負責活動的同事需要驗證一下“禮包領取邏輯”,也就是真實的去領取一次禮包。然而,這只是一個“口頭約定”,實際上並不具備強制執行力,如果這位同事因為活動的禮包過多,而漏過其中一個禮包的驗證流程,這種事情也的確偶爾會發生,這個也算是“人的失誤”的另外一種場景。
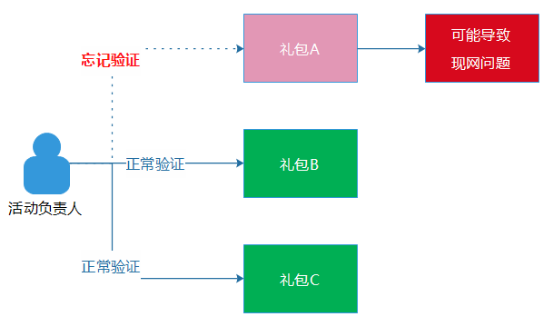 為了解決問題,這個流程在我們AMS的內部管理端中,是通過程序去保證的,確保這位同事的QQ號碼的確領取過全部的禮包。做法其實挺簡單的,就是讓負責活動的同事設置一個驗證活動的QQ號碼,然後,程序在發貨活動時,程序會自動檢查每一個子活動項目中,是否有這個QQ號碼的活動參與記錄。如果都有參與記錄,則說明這位同事完整地領取了全部禮包。同時,其他模塊的驗證和測試,我們也都采用程序和平台來保證,而不是通過“口頭約定”。
為了解決問題,這個流程在我們AMS的內部管理端中,是通過程序去保證的,確保這位同事的QQ號碼的確領取過全部的禮包。做法其實挺簡單的,就是讓負責活動的同事設置一個驗證活動的QQ號碼,然後,程序在發貨活動時,程序會自動檢查每一個子活動項目中,是否有這個QQ號碼的活動參與記錄。如果都有參與記錄,則說明這位同事完整地領取了全部禮包。同時,其他模塊的驗證和測試,我們也都采用程序和平台來保證,而不是通過“口頭約定”。
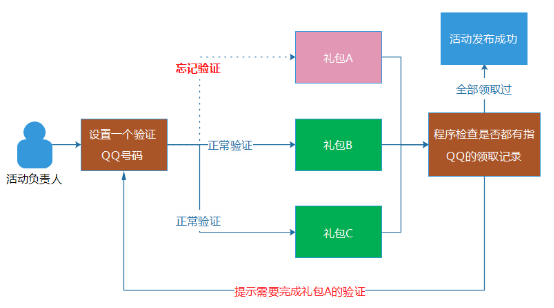 通過程序和系統對業務邏輯和流程的保證,盡可能防止“人的失誤”。
通過程序和系統對業務邏輯和流程的保證,盡可能防止“人的失誤”。
這種業務配置檢查程序,除了可以減少問題的發生,實際上也減輕了測試和驗證活動的工作,可以起到節省人力的效果。不過,業務配置檢查規則的建設並不簡單,邏輯往往比較復雜,因為要防止誤殺。