


為什麼要有進程優先級?這似乎不用過多的解釋,畢竟自從多任務操作系統誕生以來,進程執行占用cpu的能力就是一個必須要可以人為控制的事情。因為有的進程相對重要,而有的進程則沒那麼重要。進程優先級起作用的方式從發明以來基本沒有什麼變化,無論是只有一個cpu的時代,還是多核cpu時代,都是通過控制進程占用cpu時間的長短來實現的。就是說在同一個調度周期中,優先級高的進程占用的時間長些,而優先級低的進程占用的短些。從這個角度看,進程優先級其實也跟cgroup的cpu限制一樣,都是一種針對cpu占用的QOS機制。我曾經一直很困惑一點,為什麼已經有了優先級,還要再設計一個針對cpu的 cgroup?得到的答案大概是因為,優先級這個值不能很直觀的反饋出資源分配的比例吧?不過這不重要,實際上從內核目前的進程調度器cfs的角度說,同時實現cpushare方式的cgroup和優先級這兩個機制完全是相同的概念,並不會因為增加一個機制而提高什麼實現成本。既然如此,而cgroup又顯得那麼酷,那麼何樂而不為呢?
再系統上我們最熟悉的優先級設置方式是nice喝renice命令。那麼我們首先解釋一個概念,什麼是:
NICE值
nice值應該是熟悉Linux/UNIX的人很了解的概念了,我們都知它是反應一個進程“優先級”狀態的值,其取值范圍是-20至19,一共40個級別。這個值越小,表示進程”優先級”越高,而值越大“優先級”越低。我們可以通過nice命令來對一個將要執行的命令進行nice值設置,方法是:

這樣我就又打開了一個bash,並且其nice值設置為10,而默認情況下,進程的優先級應該是從父進程繼承來的,這個值一般是0。我們可以通過nice命令直接查看到當前shell的nice值

對比一下正常情況:

推出當前nice值為10的bash,打開一個正常的bash:

另外,使用renice命令可以對一個正在運行的進程進行nice值的調整,我們也可以使用比如top、ps等命令查看進程的nice值,具體方法我就不多說了,大家可以參閱相關manpage。
需要大家注意的是,我在這裡都在使用nice值這一稱謂,而非優先級(priority)這個說法。當然,nice和renice的man手冊中,也說的是priority這個概念,但是要強調一下,請大家真的不要混淆了系統中的這兩個概念,一個是nice值,一個是priority值,他們有著千絲萬縷的關系,但對於當前的Linux系統來說,它們並不是同一個概念。
我們看這個命令:

大家是否真的明白其中PRI列和NI列的具體含義有什麼區別?同樣的,如果是top命令:
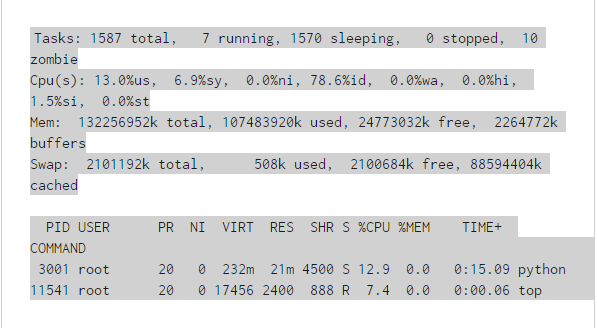
大家是否搞清楚了這其中PR值和NI值的差別?如果沒有,那麼我們可以首先搞清楚什麼是nice值。
nice值雖然不是priority,但是它確實可以影響進程的優先級。在英語中,如果我們形容一個人nice,那一般說明這個人的人緣比較好。什麼樣的人人緣好?往往是謙讓、有禮貌的人。比如,你跟一個nice的人一起去吃午飯,點了兩個一樣的飯,先上了一份後,nice的那位一般都會說:“你先吃你先吃!”,這就是人緣好,這人nice!但是如果另一份上的很晚,那麼這位nice的人就要餓著了。這說明什麼?越nice的人搶占資源的能力就越差,而越不nice的人搶占能力就越強。這就是nice值大小的含義,nice值越低,說明進程越不nice,搶占cpu的能力就越強,優先級就越高。在原來使用O1調度的Linux上,我們還會把nice值叫做靜態優先級,這也基本符合nice值的特點,就是當nice值設定好了之後,除非我們用renice去改它,否則它是不變的。而priority的值在之前內核的O1調度器上表現是會變化的,所以也叫做動態優先級。
優先級和實時進程
簡單了解nice值的概念之後,我們再來看看什麼是priority值,就是ps命令中看到的PRI值或者top命令中看到的PR值。本文為了區分這些概念,以後統一用nice值表示NI值,或者叫做靜態優先級,也就是用nice和renice命令來調整的優先級;而實用priority值表示PRI和PR值,或者叫動態優先級。我們也統一將“優先級”這個詞的概念規定為表示priority值的意思。
在內核中,進程優先級的取值范圍是通過一個宏定義的,這個宏的名稱是MAX_PRIO,它的值為140。而這個值又是由另外兩個值相加組成的,一個是代表nice值取
在內核中,進程優先級的取值范圍是通過一個宏定義的,這個宏的名稱是MAX_PRIO,它的值為140。而這個值又是由另外兩個值相加組成的,一個是代表nice值取值范圍的NICE_WIDTH宏,另一個是代表實時進程(realtime)優先級范圍的MAX_RT_PRIO宏。說白了就是,Linux實際上實現了140個優先級范圍,取值范圍是從0-139,這個值越小,優先級越高。nice值的-20到19,映射到實際的優先級范圍是100-139。新產生進程的默認優先級被定義為:
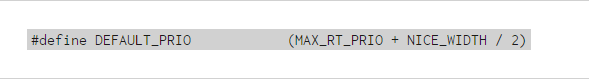
實際上對應的就是nice值的0。正常情況下,任何一個進程的優先級都是這個值,即使我們通過nice和renice命令調整了進程的優先級,它的取值范圍也不會超出100-139的范圍,除非這個進程是一個實時進程,那麼它的優先級取值才會變成0-99這個范圍中的一個。這裡隱含了一個信息,就是說當前的Linux是一種已經支持實時進程的操作系統。
什麼是實時操作系統,我們就不再這裡詳細解釋其含義以及在工業領域的應用了,有興趣的可以參考一下實時操作系統的維基百科。簡單來說,實時操作系統需要保證相關的實時進程在較短的時間內響應,不會有較長的延時,並且要求最小的中斷延時和進程切換延時。對於這樣的需求,一般的進程調度算法,無論是O1還是CFS都是無法滿足的,所以內核在設計的時候,將實時進程單獨映射了100個優先級,這些優先級都要高與正常進程的優先級(nice值),而實時進程的調度算法也不同,它們采用更簡單的調度算法來減少調度開銷。總的來說,Linux系統中運行的進程可以分成兩類:
實時進程
非實時進程
它們的主要區別就是通過優先級來區分的。所有優先級值在0-99范圍內的,都是實時進程,所以這個優先級范圍也可以叫做實時進程優先級,而100-139范圍內的是非實時進程。在系統中可以使用chrt命令來查看、設置一個進程的實時優先級狀態。我們可以先來看一下chrt命令的使用:
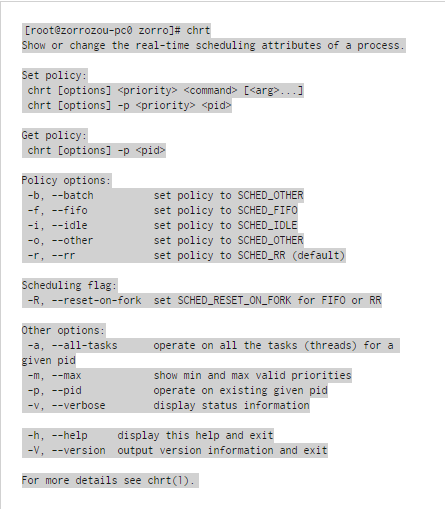
我們先來關注顯示出的Policy options部分,會發現系統給個種進程提供了5種調度策略。但是這裡並沒有說明的是,這五種調度策略是分別給兩種進程用的,對於實時進程可以用的調度策略是:SCHED_FIFO、SCHED_RR,而對於非實時進程則是:SCHED_OTHER、SCHED_OTHER、SCHED_IDLE。
系統的整體優先級策略是:如果系統中存在需要執行的實時進程,則優先執行實時進程。直到實時進程退出或者主動讓出CPU時,才會調度執行非實時進程。實時進程可以指定的優先級范圍為1-99,將一個要執行的程序以實時方式執行的方法為:

可以看到,新打開的bash已經是實時進程,默認調度策略為SCHED_RR,優先級為10。如果想修改調度策略,就加個參數:
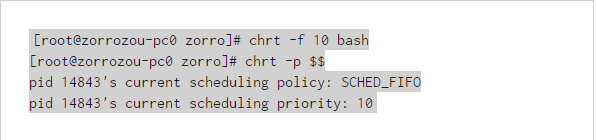
剛才說過,SCHED_RR和SCHED_FIFO都是實時調度策略,只能給實時進程設置。對於所有實時進程來說,優先級高的(就是priority數字小的)進程一定會保證先於優先級低的進程執行。SCHED_RR和SCHED_FIFO的調度策略只有當兩個實時進程的優先級一樣的時候才會發生作用,其區別也是顧名思義:
SCHED_FIFO:以先進先出的隊列方式進行調度,在優先級一樣的情況下,誰先執行的就先調度誰,除非它退出或者主動釋放CPU。
SCHED_RR:以時間片輪轉的方式對相同優先級的多個進程進行處理。時間片長度為100ms。
這就是Linux對於實時進程的優先級和相關調度算法的描述。整體很簡單,也很實用。而相對更麻煩的是非實時進程,它們才是Linux上進程的主要分類。對於非實時進程優先級的處理,我們首先還是要來介紹一下它們相關的調度算法:O1和CFS。
O1調度
O1調度算法是在Linux 2.6開始引入的,到Linux 2.6.23之後內核將調度算法替換成了CFS。雖然O1算法已經不是當前內核所默認使用的調度算法了,但是由於大量線上的服務器可能使用的Linux版本還是老版本,所以我相信很多服務器還是在使用著O1調度器,那麼費一點口舌簡單交代一下這個調度器也是有意義的。這個調度器的名字之所以叫做O1,主要是因為其算法的時間復雜度是O1。
O1調度器仍然是根據經典的時間片分配的思路來進行整體設計的。簡單來說,時間片的思路就是將CPU的執行時間分成一小段一小段的,假如是5ms一段。於是
O1調度器仍然是根據經典的時間片分配的思路來進行整體設計的。簡單來說,時間片的思路就是將CPU的執行時間分成一小段一小段的,假如是5ms一段。於是多個進程如果要“同時”執行,實際上就是每個進程輪流占用5ms的cpu時間,而從1s的時間尺度上看,這些進程就是在“同時”執行的。當然,對於多核系統來說,就是把每個核心都這樣做就行了。而在這種情況下,如何支持優先級呢?實際上就是將時間片分配成大小不等的若干種,優先級高的進程使用大的時間片,優先級小的進程使用小的時間片。這樣在一個周期結速後,優先級大的進程就會占用更多的時間而因此得到特殊待遇。O1算法還有一個比較特殊的地方是,即使是相同的nice值的進程,也會再根據其CPU的占用情況將其分成兩種類型:CPU消耗型和IO消耗性。典型的CPU消耗型的進程的特點是,它總是要一直占用CPU進行運算,分給它的時間片總是會被耗盡之後,程序才可能發生調度。比如常見的各種算數運算程序。而IO消耗型的特點是,它經常時間片沒有耗盡就自己主動先釋放CPU了,比如vi,emacs這樣的編輯器就是典型的IO消耗型進程。
為什麼要這樣區分呢?因為IO消耗型的進程經常是跟人交互的進程,比如shell、編輯器等。當系統中既有這種進程,又有CPU消耗型進程存在,並且其nice值一樣時,假設給它們分的時間片長度是一樣的,都是500ms,那麼人的操作可能會因為CPU消耗型的進程一直占用CPU而變的卡頓。可以想象,當bash在等待人輸入的時候,是不占CPU的,此時CPU消耗的程序會一直運算,假設每次都分到500ms的時間片,此時人在bash上敲入一個字符的時候,那麼bash很可能要等個幾百ms才能給出響應,因為在人敲入字符的時候,別的進程的時間片很可能並沒有耗盡,所以系統不會調度bash程度進行處理。為了提高IO消耗型進程的響應速度,系統將區分這兩類進程,並動態調整CPU消耗的進程將其優先級降低,而IO消耗型的將其優先級變高,以降低CPU消耗進程的時間片的實際長度。已知nice值的范圍是-20-19,其對應priority值的范圍是100-139,對於一個默認nice值為0的進程來說,其初始priority值應該是120,隨著其不斷執行,內核會觀察進程的CPU消耗狀態,並動態調整priority值,可調整的范圍是+-5。就是說,最高其優先級可以呗自動調整到115,最低到125。這也是為什麼nice值叫做靜態優先級而priority值叫做動態優先級的原因。不過這個動態調整的功能在調度器換成CFS之後就不需要了,因為CFS換了另外一種CPU時間分配方式,這個我們後面再說。
再簡單了解了O1算法按時間片分配CPU的思路之後,我們再來結合進程的狀態簡單看看其算法描述。我們都知道進程有5種狀態:
S(Interruptible sleep):可中斷休眠狀態。
D(Uninterruptible sleep):不可中斷休眠狀態。
R(Running or runnable):執行或者在可執行隊列中。
Z(Zombie process):僵屍。
T(Stopped):暫停。
在CPU調度時,主要只關心R狀態進程,因為其他狀態進程並不會被放倒調度隊列中進行調度。調度隊列中的進程一般主要有兩種情況,一種是進程已經被調度到CPU上執行,另一種是進程正在等待被調度。出現這兩種狀態的原因應該好理解,因為需要執行的進程數可能多於硬件的CPU核心數,比如需要執行的進程有8個而CPU核心只有4個,此時cpu滿載的時候,一定會有4個進程處在“等待”狀態,因為此時有另外四個進程正在占用CPU執行。
根據以上情況我們可以理解,系統當下需要同時進行調度處理的進程數(R狀態進程數)和系統CPU的比值,可以一定程度的反應系統的“繁忙”程度。需要調度的進程越多,核心越少,則意味著系統越繁忙。除了進程執行本身需要占用CPU以外,多個進程的調度切換也會讓系統繁忙程度增加的更多。所以,我們往往會發現,R狀態進程數量在增長的情況下,系統的性能表現會下降。系統中可以使用uptime命令查看系統平均負載指數(load average):

其中load average中分別顯示的是1分鐘,5分鐘,15分鐘之內的平均負載指數(可以簡單認為是相映時間范圍內的R狀態進程個數)。但是這個命令顯示的數字是絕對個數,並沒有表示出不同CPU核心數的實際情況。比如,如果我們的1分鐘load average為16,而CPU核心數為32的話,那麼這個系統的其實並不繁忙。但是如果CPU個數是8的話,那可能就意味著比較忙了。但是實際情況往往可能比這更加復雜,比如進程消耗類型也會對這個數字的解讀有影響。總之,這個值的絕對高低並不能直觀的反饋出來當前系統的繁忙程度,還需要根據系統的其它指標綜合考慮。
O1調度器在處理流程上大概是這樣進行調度的: 首先,進程產生(fork)的時候會給一個進程分配一個時間片長度。這個新進程的時間片一般是父進程的一半,
O1調度器在處理流程上大概是這樣進行調度的:
首先,進程產生(fork)的時候會給一個進程分配一個時間片長度。這個新進程的時間片一般是父進程的一半,而父進程也會因此減少它的時間片長度為原來的一半。就是說,如果一個進程產生了子進程,那麼它們將會平分當前時間片長度。比如,如果父進程時間片還剩100ms,那麼一個fork產生一個子進程之後,子進程的時間片是50ms,父進程剩余的時間片是也是50ms。這樣設計的目的是,為了防止進程通過fork的方式讓自己所處理的任務一直有時間片。不過這樣做也會帶來少許的不公平,因為先產生的子進程獲得的時間片將會比後產生的長,第一個子進程分到父進程的一半,那麼第二個子進程就只能分到1/4。對於一個長期工作的進程組來說,這種影響可以忽略,因為第一輪時間片在耗盡後,系統會在給它們分配長度相當的時間片。
針對所有R狀態進程,O1算法使用兩個隊列組織進程,其中一個叫做活動隊列,另一個叫做過期隊列。活動隊列中放的都是時間片未被耗盡的進程,而過期隊列中放時間片被耗盡的進程。
如1所述,新產生的進程都會先獲得一個時間片,進入活動隊列等待調度到CPU執行。而內核會在每個tick間隔期間對正在CPU上執行的進程進行檢查。一般的tick間隔時間就是cpu時鐘中斷間隔,每秒鐘會有1000個,即頻率為1000HZ。每個tick間隔周期主要檢查兩個內容:1、當前正在占用CPU的進程是不是時間片已經耗盡了?2、是不是有更高優先級的進程在活動隊列中等待調度?如果任何一種情況成立,就把則當前進程的執行狀態終止,放到等待隊列中,換當前在等待隊列中優先級最高的那個進程執行。
以上就是O1調度的基本調度思路,當然實際情況是,還要加上SMP(對稱多處理)的邏輯,以滿足多核CPU的需求。目前在我的archlinux上可以用以下命令查看內核HZ的配置:
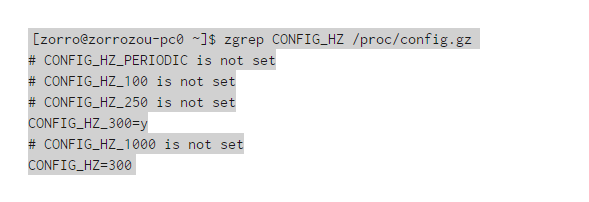
我們發現我當前系統的HZ配置為300,而不是一般情況下的1000。大家也可以思考一下,配置成不同的數字(100、250、300、1000),對系統的性能到底會有什麼影響?
CFS完全公平調度
O1已經是上一代調度器了,由於其對多核、多CPU系統的支持性能並不好,並且內核功能上要加入cgroup等因素,Linux在2.6.23之後開始啟用CFS作為對一般優先級(SCHED_OTHER)進程調度方法。在這個重新設計的調度器中,時間片,動態、靜態優先級以及IO消耗,CPU消耗的概念都不再重要。CFS采用了一種全新的方式,對上述功能進行了比較完善的支持。
其設計的基本思路是,我們想要實現一個對所有進程完全公平的調度器。又是那個老問題:如何做到完全公平?答案跟上一篇IO調度中CFQ的思路類似:如果當前有n個進程需要調度執行,那麼調度器應該再一個比較小的時間范圍內,把這n個進程全都調度執行一遍,並且它們平分cpu時間,這樣就可以做到所有進程的公平調度。那麼這個比較小的時間就是任意一個R狀態進程被調度的最大延時時間,即:任意一個R狀態進程,都一定會在這個時間范圍內被調度相應。這個時間也可以叫做調度周期,其英文名字叫做:sched_latency_ns。進程越多,每個進程在周期內被執行的時間就會被平分的越小。調度器只需要對所有進程維護一個累積占用CPU時間數,就可以衡量出每個進程目前占用的CPU時間總量是不是過大或者過小,這個數字記錄在每個進程的vruntime中。所有待執行進程都以vruntime為key放到一個由紅黑樹組成的隊列中,每次被調度執行的進程,都是這個紅黑樹的最左子樹上的那個進程,即vruntime時間最少的進程,這樣就保證了所有進程的相對公平。
在基本驅動機制上CFS跟O1一樣,每次時鐘中斷來臨的時候,都會進行隊列調度檢查,判斷是否要進程調度。當然還有別的時機需要調度檢查,發生調度的時機可以總結為這樣幾個:
當前進程的狀態轉換時。主要是指當前進程終止退出或者進程休眠的時候。
當前進程主動放棄CPU時。狀態變為sleep也可以理解為主動放棄CPU,但是當前內核給了一個方法,可以使用sched_yield()在不發生狀態切換的情況下主動讓出CPU。
當前進程的vruntime時間大於每個進程的理想占用時間時(delta_exec > ideal_runtime)。這裡的ideal_runtime實際上就是上文說的sched_latency_ns/進程數n。當然這個值並不是一定這樣得出,下文會有更詳細解釋。
當進程從中斷、異常或系統調用返回時,會發生調度檢查。比如時鐘中斷。 CFS的優先級 當然,CFS中還需要支持優先級。在新的體系中,優先級是以時間消
當進程從中斷、異常或系統調用返回時,會發生調度檢查。比如時鐘中斷。
CFS的優先級
當然,CFS中還需要支持優先級。在新的體系中,優先級是以時間消耗(vruntime增長)的快慢來決定的。就是說,對於CFS來說,衡量的時間累積的絕對值都是一樣紀錄在vruntime中的,但是不同優先級的進程時間增長的比率是不同的,高優先級進程時間增長的慢,低優先級時間增長的快。比如,優先級為19的進程,實際占用cpu為1秒,那麼在vruntime中就記錄1s。但是如果是-20優先級的進程,那麼它很可能實際占CPU用10s,在vruntime中才會紀錄1s。CFS真實實現的不同nice值的cpu消耗時間比例在內核中是按照“每差一級cpu占用時間差10%左右”這個原則來設定的。這裡的大概意思是說,如果有兩個nice值為0的進程同時占用cpu,那麼它們應該每人占50%的cpu,如果將其中一個進程的nice值調整為1的話,那麼此時應保證優先級高的進程比低的多占用10%的cpu,就是nice值為0的占55%,nice值為1的占45%。那麼它們占用cpu時間的比例為55:45。這個值的比例約為1.25。就是說,相鄰的兩個nice值之間的cpu占用時間比例的差別應該大約為1.25。根據這個原則,內核對40個nice值做了時間計算比例的對應關系,它在內核中以一個數組存在:
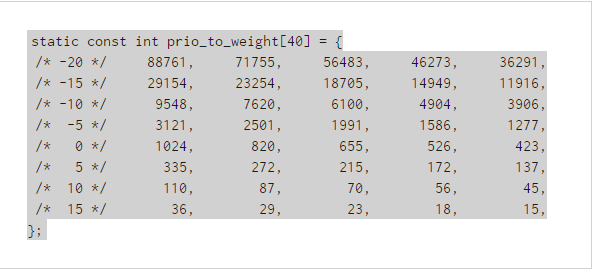
我們看到,實際上nice值的最高優先級和最低優先級的時間比例差距還是很大的,絕不僅僅是例子中的十倍。由此我們也可以推導出每一個nice值級別計算vruntime的公式為:

這個公式的意思是說,在nice值為0的時候(對應的比例值為1024),計算這個進程vruntime的實際增長時間值(delta vruntime)為:CPU占用時間(delta Time)* 1024 / load。在這個公式中load代表當前sched_entity的值,其實就可以理解為需要調度的進程(R狀態進程)個數。load越大,那麼每個進程所能分到的時間就越少。CPU調度是內核中會頻繁進行處理的一個時間,於是上面的delta vruntime的運算會被頻繁計算。除法運算會占用更多的cpu時間,所以內核編程中的一個原則就是,盡可能的不用除法。內核中要用除法的地方,基本都用乘法和位移運算來代替,所以上面這個公式就會變成:

內核中為了方便不同nice值的Inverse(load)的相關計算,對做好了一個跟prio_to_weight數組一一對應的數組,在計算中可以直接拿來使用,減少計算時的CPU消耗:
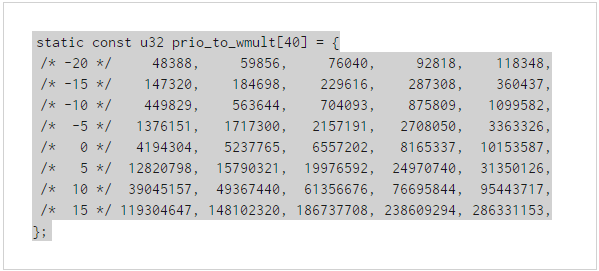
具體計算細節不在這裡細解釋了,有興趣的可以自行閱讀代碼:kernel/shced/fair.c(Linux 4.4)中的__calc_delta()函數實現。
根據CFS的特性,我們知道調度器總是選擇vruntime最小的進程進行調度。那麼如果有兩個進程的初始化vruntime時間一樣時,一個進程被選擇進行調度處理,那麼只要一進行處理,它的vruntime時間就會大於另一個進程,CFS難道要馬上換另一個進程處理麼?出於減少頻繁切換進程所帶來的成本考慮,顯然並不應該這樣。CFS設計了一個sched_min_granularity_ns參數,用來設定進程被調度執行之後的最小CPU占用時間。

一個進程被調度執行後至少要被執行這麼長時間才會發生調度切換。
我們知道無論到少個進程要執行,它們都有一個預期延遲時間,即:sched_latency_ns,系統中可以通過如下命令來查看這個時間:

在這種情況下,如果需要調度的進程個數為n,那麼平均每個進程占用的CPU時間為sched_latency_ns/n。顯然,每個進程實際占用的CPU時間會因為n的增大而減小。但是實現上不可能讓它無限的變小,所以sched_min_granularity_ns的值也限定了每個進程可以獲得的執行時間周期的最小值。當進程很多,導致使用了sched_min_granularity_ns作為最小調度周期時,對應的調度延時也就不在遵循sched_latency_ns的限制,而是以實際的需要調度的進程個數n * sched_min_granularity_ns進行計算。當然,我們也可以把這理解為CFS的”時間片”,不過我們還是要強調,CFS是沒有跟O1類似的“時間片“的概念的,具體區別大家可以自己琢磨一下。
新進程的VRUNTIME值 CFS是通過vruntime最小值來選擇需要調度的進程的,那麼可以想象,在一個已經有多個進程執行了相對較長的系統中,這個隊列中的vrunti
新進程的VRUNTIME值
CFS是通過vruntime最小值來選擇需要調度的進程的,那麼可以想象,在一個已經有多個進程執行了相對較長的系統中,這個隊列中的vruntime時間紀錄的數值都會比較長。如果新產生的進程直接將自己的vruntime值設置為0的話,那麼它將在執行開始的時間內搶占很多的CPU時間,直到自己的vruntime追趕上其他進程後才可能調度其他進程,這種情況顯然是不公平的。所以CFS對每個CPU的執行隊列都維護一個min_vruntime值,這個值紀錄了這個CPU執行隊列中vruntime的最小值,當隊列中出現一個新建的進程時,它的初始化vruntime將不會被設置為0,而是根據min_vruntime的值為基礎來設置。這樣就保證了新建進程的vruntime與老進程的差距在一定范圍內,不會因為vruntime設置為0而在進程開始的時候占用過多的CPU。
新建進程獲得的實際vruntime值跟一些設置有關,比如:
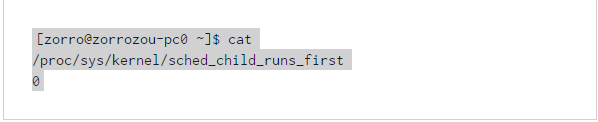
這個文件是fork之後是否讓子進程優先於父進程執行的開關。0為關閉,1為打開。如果這個開關打開,就意味著子進程創建後,保證子進程在父進程之前被調度。另外,在源代碼目錄下的kernel/sched/features.h文件中,還規定了一系列調度器屬性開關。而其中:
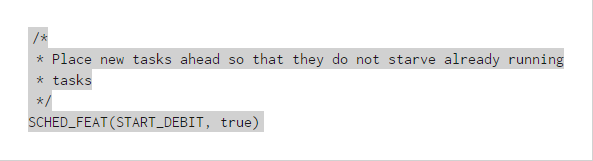
這個參數規定了新進程啟動之後第一次運行會有延時。這意味著新進程的vruntime設置要比默認值大一些,這樣做的目的是防止應用通過不停的fork來盡可能多的獲得執行時間。子進程在創建的時候,vruntime的定義的步驟如下,首先vruntime被設置為min_vruntime。然後判斷START_DEBIT位是否被值為true,如果是則會在min_vruntime的基礎上增大一些,增大的時間實際上就是一個進程的調度延時時間,即上面描述過的calc_delta_fair()函數得到的結果。這個時間設置完畢之後,就檢查sched_child_runs_first開關是否打開,如果打開(值被設置為1),就比較新進程的vruntime和父進程的vruntime哪個更小,並將新進程的vruntime設置為更小的那個值,而父進程的vruntime設置為更大的那個值,以此保證子進程一定在父進程之前被調度。
IO消耗型進程的處理
根據前文,我們知道除了可能會一直占用CPU時間的CPU消耗型進程以外,還有一類叫做IO消耗類型的進程,它們的特點是基本不占用CPU,主要行為是在S狀態等待響應。這類進程典型的是vim,bash等跟人交互的進程,以及一些壓力不大的,使用了多進程(線程)的或select、poll、epoll的網絡代理程序。如果CFS采用默認的策略處理這些程序的話,相比CPU消耗程序來說,這些應用由於絕大多數時間都處在sleep狀態,它們的vruntime時間基本是不變的,一旦它們進入了調度隊列,將會很快被選擇調度執行。對比O1調度算法,這種行為相當於自然的提高了這些IO消耗型進程的優先級,於是就不需要特殊對它們的優先級進行“動態調整”了。
但這樣的默認策略也是有問題的,有時CPU消耗型和IO消耗型進程的區分不是那麼明顯,有些進程可能會等一會,然後調度之後也會長時間占用CPU。這種情況下,如果休眠的時候進程的vruntime保持不變,那麼等到休眠被喚醒之後,這個進程的vruntime時間就可能會比別人小很多,從而導致不公平。所以對於這樣的進程,CFS也會對其進行時間補償。補償方式為,如果進程是從sleep狀態被喚醒的,而且GENTLE_FAIR_SLEEPERS屬性的值為true,則vruntime被設置為sched_latency_ns的一半和當前進程的vruntime值中比較大的那個。sched_latency_ns的值可以在這個文件中進行設置:

因為系統中這種調度補償的存在,IO消耗型的進程總是可以更快的獲得響應速度。這是CFS處理與人交互的進程時的策略,即:通過提高響應速度讓人的操作感受更好。但是有時候也會因為這樣的策略導致整體性能受損。在很多使用了多進程(線程)或select、poll、epoll的網絡代理程序,一般是由多個進程組成的進程組進行工作,典型的如apche、nginx和php-fpm這樣的處理程序。它們往往都是由一個或者多個進程使用nanosleep()進行周期性的檢查是否有新任務,如果有責喚醒一個子進程進行處理,子進程的處理可能會消耗CPU,而父進程則主要是sleep等待喚醒。這個時候,由於系統對sleep進程的補償策略的存在,新喚醒的進程就可能會打斷正在處理的子進程的過程,搶占CPU進行處理。當這種打斷很多很頻繁的時候,CPU處理的過程就會因為頻繁的進程上下文切換而變的很低效,從而使系統整體吞吐量下降。此時我們可以使用開關禁止喚醒搶占的特性。
上面顯示的這個文件的內容就是系統中用來控制kernel/sched/features.h這個文件所列內容的開關文件,其中WAKEUP_PREEMPTION表示:目前的系統狀態是打開sleep喚醒進
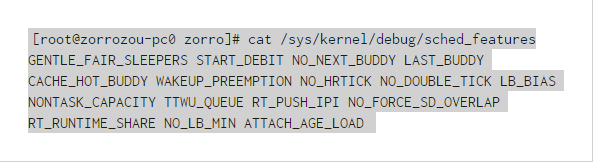
上面顯示的這個文件的內容就是系統中用來控制kernel/sched/features.h這個文件所列內容的開關文件,其中WAKEUP_PREEMPTION表示:目前的系統狀態是打開sleep喚醒進程的搶占屬性的。可以使用如下命令關閉這個屬性:
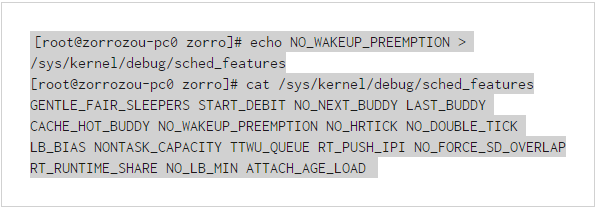
其他相關參數的調整也是類似這樣的方式。其他我沒講到的屬性的含義,大家可以看kernel/sched/features.h文件中的注釋。
系統中還提供了一個sched_wakeup_granularity_ns配置文件,這個文件的值決定了喚醒進程是否可以搶占的一個時間粒度條件。默認CFS的調度策略是,如果喚醒的進程vruntime小於當前正在執行的進程,那麼就會發生喚醒進程搶占的情況。而sched_wakeup_granularity_ns這個參數是說,只有在當前進程的vruntime時間減喚醒進程的vruntime時間所得的差大於sched_wakeup_granularity_ns時,才回發生搶占。就是說sched_wakeup_granularity_ns的值越大,越不容易發生搶占。
CFS和其他調度策略
SCHED_BATCH
在上文中我們說過,CFS調度策略主要是針對chrt命令顯示的SCHED_OTHER范圍的進程,實際上就是一般的非實時進程。我們也已經知道,這樣的一般進程還包括另外兩種:SCHED_BATCH和SCHED_IDLE。在CFS的實現中,集成了對SCHED_BATCH策略的支持,並且其功能和SCHED_OTHER策略幾乎是一致的。唯一的區別在於,如果一個進程被用chrt命令標記成SCHED_OTHER策略的話,CFS將永遠認為這個進程是CPU消耗型的進程,不會對其進行IO消耗進程的時間補償。這樣做的唯一目的是,可以在確認進程是CPU消耗型的進程的前提下,對其盡可能的進行批處理方式調度(batch),以減少進程切換帶來的損耗,提高吞度量。實際上這個策略的作用並不大,內核中真正的處理區別只是在標記為SCHED_BATCH時進程在sched_yield主動讓出cpu的行為發生是不去更新cfs的隊列時間,這樣就讓這些進程在主動讓出CPU的時候(執行sched_yield)不會紀錄其vruntime的更新,從而可以繼續優先被調度到。對於其他行為,並無不同。
SCHED_IDLE
如果一個進程被標記成了SCHED_IDLE策略,調度器將認為這個優先級是很低很低的,比nice值為19的優先級還要低。系統將只在CPU空閒的時候才會對這樣的進程進行調度執行。若果存在多個這樣的進程,它們之間的調度方式跟正常的CFS相同。
SCHED_DEADLINE
最新的Linux內核還實現了一個最新的調度方式叫做SCHED_DEADLINE。跟IO調度類似,這個算法也是要實現一個可以在最終期限到達前讓進程可以調度執行的方法,保證進程不會餓死。目前大多數系統上的chrt還沒給配置接口,暫且不做深入分析。
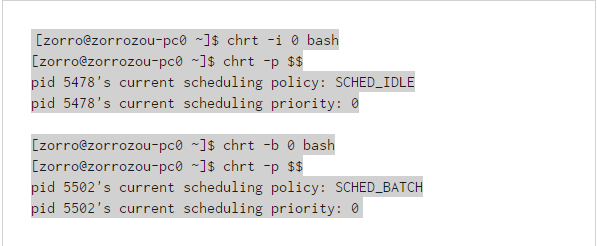
另外要注意的是,SCHED_BATCH和SCHED_IDLE一樣,只能對靜態優先級(即nice值)為0的進程設置。操作命令如下:
多CPU的CFS調度
在上面的敘述中,我們可以認為系統中只有一個CPU,那麼相關的調度隊列只有一個。實際情況是系統是有多核甚至多個CPU的,CFS從一開始就考慮了這種情況,它對每個CPU核心都維護一個調度隊列,這樣每個CPU都對自己的隊列進程調度即可。這也是CFS比O1調度算法更高效的根本原因:每個CPU一個隊列,就可以避免對全局隊列使用大內核鎖,從而提高了並行效率。當然,這樣最直接的影響就是CPU之間的負載可能不均,為了維持CPU之間的負載均衡,CFS要定期對所有CPU進行load balance操作,於是就有可能發生進程在不同CPU的調度隊列上切換的行為。這種操作的過程也需要對相關的CPU隊列進行鎖操作,從而降低了多個運行隊列帶來的並行性。不過總的來說,CFS的並行隊列方式還是要比O1的全局隊列方式要高效。尤其是在CPU核心越來越多的情況下,全局鎖的效率下降顯著增加。
CFS對多個CPU進行負載均衡的行為是idle_balance()函數實現的,這個函數會在CPU空閒的時候由schedule()進行調用,讓空閒的CPU從其他繁忙的CPU隊列中取進程來執行。我們可以通過查看/proc/sched_debug的信息來查看所有CPU的調度隊列狀態信息以及系統中所有進程的調度信息。內容較多,我就不在這裡一一列出了,有興趣的同學可以自己根據相關參考資料(最好的資料就是內核源碼)了解其中顯示的相關內容分別是什麼意思。
在CFS對不同CPU的調度隊列做均衡的時候,可能會將某個進程切換到另一個CPU上執行。此時,CFS會在將這個進程出隊的時候將vruntime減去當前隊列的min_vrunt
在CFS對不同CPU的調度隊列做均衡的時候,可能會將某個進程切換到另一個CPU上執行。此時,CFS會在將這個進程出隊的時候將vruntime減去當前隊列的min_vruntime,其差值作為結果會在入隊另一個隊列的時候再加上所入隊列的min_vruntime,以此來保持隊列切換後CPU隊列的相對公平。
最後
本文的目的是從Linux系統進程的優先級為出發點,通過了解相關的知識點,希望大家對系統的進程調度有個整體的了解。其中我們也對CFS調度算法進行了比較深入的分析。在我的經驗來看,這些知識對我們在觀察系統的狀態和相關優化的時候都是非常有用的。比如在使用top命令的時候,NI和PR值到底是什麼意思?類似的地方還有ps命令中的NI和PRI值、ulimit命令-e和-r參數的區別等等。當然,希望看完本文後,能讓大家對這些命令顯示的了解更加深入。除此之外,我們還會發現,雖然top命令中的PR值和ps -l命令中的PRI值的含義是一樣的,但是在優先級相同的情況下,它們顯示的值確不一樣。那麼你知道為什麼它們顯示會有區別嗎?這個問題的答案留給大家自己去尋找吧。