


rsync是unix/linux下同步文件的一個高效算法,它能同步更新兩處計算機的文件與目錄,並適當利用查找文件中的不同塊以減少數據傳輸。rsync中一項與其他大部分類似程序或協定中所未見的重要特性是鏡像是只對有變更的部分進行傳送。rsync可拷貝/顯示目錄屬性,以及拷貝文件,並可選擇性的壓縮以及遞歸拷貝。rsync利用由Andrew Tridgell發明的算法。這裡不介紹其使用方法,只介紹其核心算法。我們可以看到,Unix下的東西,一個命令,一個工具都有很多很精妙的東西,怎麼學也學不完,這就是Unix的文化啊。
本來不想寫這篇文章的,因為原先發現有很多中文blog都說了這個算法,但是看了一下,發現這些中文blog要麼翻譯國外文章翻譯地非常爛,要麼就是介紹這個算法介紹得很亂讓人看不懂,還有錯誤,誤人不淺,所以讓我覺得有必要寫篇rsync算法介紹的文章。(當然,我成文比較倉促,可能會有一些錯誤,請指正)
問題
首先, 我們先來想一下rsync要解決的問題,如果我們要同步的文件只想傳不同的部分,我們就需要對兩邊的文件做diff,但是這兩個問題在兩台不同的機器上,無法做diff。如果我們做diff,就要把一個文件傳到另一台機器上做diff,但這樣一來,我們就傳了整個文件,這與我們只想傳輸不同部的初衷相背。
於是我們就要想一個辦法,讓這兩邊的文件見不到面,但還能知道它們間有什麼不同。這就出現了rsync的算法。
算法
rsync的算法如下:(假設我們同步源文件名為fileSrc,同步目的文件叫fileDst)
1)分塊Checksum算法。首先,我們會把fileDst的文件平均切分成若干個小塊,比如每塊512個字節(最後一塊會小於這個數),然後對每塊計算兩個checksum,
一個叫rolling checksum,是弱checksum,32位的checksum,其使用的是Mark Adler發明的adler-32算法,
另一個是強checksum,128位的,以前用md4,現在用md5 hash算法。
為什麼要這樣?因為若干年前的硬件上跑md4的算法太慢了,所以,我們需要一個快算法來鑒別文件塊的不同,但是弱的adler32算法碰撞概率太高了,所以我們還要引入強的checksum算法以保證兩文件塊是相同的。也就是說,弱的checksum是用來區別不同,而強的是用來確認相同。(checksum的具體公式可能看這篇文章)
2)傳輸算法。同步目標端會把fileDst的一個checksum列表傳給同步源,這個列表裡包括了三個東西,rolling checksum(32bits),md5 checksume(128bits),文件塊編號。
我估計你猜到了同步源機器拿到了這個列表後,會對fileSrc做同樣的checksum,然後和fileDst的checksum做對比,這樣就知道哪些文件塊改變了。
但是,聰明的你一定會有以下兩個疑問:
如果我fileSrc這邊在文件中間加了一個字符,這樣後面的文件塊都會位移一個字符,這樣就完全和fileDst這邊的不一樣了,但理論上來說,我應該只需要傳一個字符就好了。這個怎麼解決?
如果這個checksum列表特別長,而我的兩邊的相同的文件塊可能並不是一樣的順序,那就需要查找,線性的查找起來應該特別慢吧。這個怎麼解決?
很好,讓我們來看一下同步源端的算法。
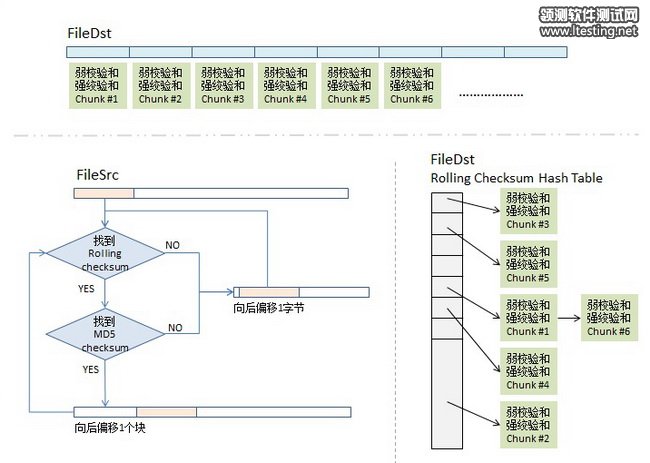
3)checksum查找算法。同步源端拿到fileDst的checksum數組後,會把這個數據存到一個hash table中,用rolling checksum做hash,以便獲得O(1)時間復雜度的查找性能。這個hash table是16bits的,所以,hash table的尺寸是2的16次方,對rolling checksum的hash會被散列到0 – 2^16 – 1中的某個值。(對於hash table,如果你不清楚,請回去看你大學時的數據結構那本教科書)
順便說一下,我在網上看到很多文章說,“要對rolling checksum做排序”(比如這篇和這篇),這兩篇文章都引用並翻譯了原版的這篇文章,但是他們都理解錯了,不是排序,就只是把fileDst的checksum數據,按rolling checksum做存到2^16的hash table中,當然會發生碰撞,把碰撞的做成一個鏈接就好了。這就是原文中所說的第二步。
4)比對算法。這是最關鍵的算法,細節如下:
4.1)取fileSrc的第一個文件塊(我們假設的是512個長度),也就是從fileSrc的第1個字節到第512個字節,取出來後做rolling checksum計算。計算好的值到hash表中查。
4.2)如果查到了,說明發現在fileDst中有潛在相同的文件塊,於是就再比較md5的checksum,因為rolling checksume太弱了,可能發生碰撞。於是還要算md5的128bits的checksum,這樣一來,我們就有 2^-(32+128) = 2^-160的概率發生碰撞,這太小了可以忽略。如果rolling checksum和md5 checksum都相同,這說明在fileDst中有相同的塊,我們需要記下這一塊在fileDst下的文件編號。
4.3)如果fileSrc的rolling checksum 沒有在hash table中找到,那就不用算md5 checksum了。表示這一塊中有不同的信息。總之,只要rolling checksum 或 md5 checksum 其中有一個在fileDst的checksum hash表中找不到匹配項,那麼就會觸發算法對fileSrc的rolling動作。於是,算法會住後step 1個字節,取fileSrc中字節2-513的文件塊要做checksum,go to (4.1) - 現在你明白什麼叫rolling checksum了吧。
4.4)這樣,我們就可以找出fileSrc相鄰兩次匹配中的那些文本字符,這些就是我們要往同步目標端傳的文件內容了。
圖示
怎麼,你沒看懂? 好吧,我送佛送上西,畫個示意圖給你看看(對圖中的東西我就不再解釋了)。
這樣,最終,在同步源這端,我們的rsync算法可能會得到下面這個樣子的一個數據數組,圖中,紅色塊表示在目標端已匹配上,不用傳輸(注:我專門在其中顯示了兩塊chunk #5,相信你會懂的),而白色的地方就是需要傳輸的內容(注意:這些白色的塊是不定長的),這樣,同步源這端把這個數組(白色的就是實際內容,紅色的就放一個標號)壓縮傳到目的端,在目的端的rsync會根據這個表重新生成文件,這樣,同步完成。

最後想說一下,對於某些壓縮文件使用rsync傳輸可能會傳得更多,因為被壓縮後的文件可能會非常的不同。對此,對於gzip和bzip2這樣的命令,記得開啟 rs
最後想說一下,對於某些壓縮文件使用rsync傳輸可能會傳得更多,因為被壓縮後的文件可能會非常的不同。對此,對於gzip和bzip2這樣的命令,記得開啟 “rsyncalbe” 模式。