


VIOS Health Advisor 工具是 VIOS2.2.2.1 自帶的,無需單獨安裝。它通過對 VIOS 系統進行一段時間(最少 10 分鐘,最多 1 個小時)的監控後,為 VIOS 提供整體的系統健康報告,並且可以對 VIOS 系統存在的性能瓶頸進行分析,給出解決性能問題的建議。
任何長時間運行的監控工具都是有開銷的,VIOS Health Advisor 也不例外,但 VIOS Performance Advisor 對系統資源的消耗比較低。如果系統非常繁忙的時候,如物理 CPU 空閒低於 0.2 Core,那麼此時不建議的收集 Health Advisor 信息,但是可以收集 nmon 信息,然後用 Health Advisor 進行分析。如果在系統繁忙的情況下依然收集 Health Advisor 信息的話,由於工具不會主動搶占應用所用的 CPU 資源,看到的結果將是執行命令沒有返回值,命令等待系統空閒,才能最終生成報告。
VIOS 2.2.2.1 Health Advisor 工具性能監控
Health Advisor 工具命令,需要在 VIOS 環境下執行,命令行是 part(Performance Analysis & Reporting Tool)。執行語法具體如下:
$ part
usage: part {-i INTERVAL | -f FILENAME} [-t LEVEL] [--help|-?]
-i <minutes> interval can range between 10-60
-f <file> any nmon recording
-t <level> 1 - Basic logging, 2 - Detailed logging
-? usage message
-i 參數設置監控的時間,范圍是 10 分鐘到 1 個小時。
-f 參數是為了分析 nmon 的結果,參數後面加生成的 nmon 文件。
-t 參數為為了設置分析的詳細程度,默認情況下命令收集的信息就是 Detailed logging 級別。
首先試驗分區 VIOS 的 profile 文件配置:
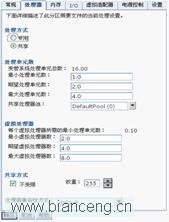
初始條件下,系統沒有壓力,收集 10 分鐘系統性能數據。
$ part -i 10part: Reports are successfully generated in 730-13-vios1_121203_01_09_19.tar
10 分鐘後,命令執行完畢。將.tar 壓縮包獲取到 windows 機器上,解壓縮,然後用浏覽區打開文件:vios_advisor_report.xml
關注頁面中的 CPU 部分信息:
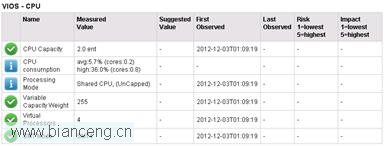
在上圖中的幾種圖標中,白色打鉤圖標表示此項正常,無需調整。
白色歎號圖標需要注意,即 Informative。Risk 和 Impact 項級別都是 5 最高,1 最低。
由於此次測試時 CPU 沒有什麼壓力,因此有關 CPU 的指標中,“Suggested Value”一列數值均為空,無需調整。
接下來,利用 ncpu 命令,輪詢給 CPU 發壓力,然後用 VIOS Performance Advisor 收集 10 分鐘的信息:
分區有 16 個邏輯 CPU,啟動 15 個 ncpu 進程:
# ./ncpu -p 15 ./ncpu - processes=15 snooze=0% hibernate=0 secs forever # lparstat 1 System configuration: type=Shared mode=Uncapped smt=4 lcpu=16 mem=4096MB psize=8 ent=2.00 %user %sys %wait %idle physc %entc lbusy app vcsw phint ----- ----- ------ ------ ----- ----- ------ --- ----- ----- 0.0 0.3 0.0 99.7 0.01 0.7 0.0 7.99 588 0 0.0 0.3 0.0 99.7 0.01 0.7 0.0 7.99 652 0 95.6 0.1 0.0 4.3 3.63 181.7 82.6 4.21 1389 0 99.9 0.1 0.0 0.0 4.00 199.9 100.0 4.00 1599 0 99.9 0.1 0.0 0.0 4.00 199.9 100.0 4.00 1599 0
利用 lparstat 命令,觀察“physc”一列數值,初始物理 CPU 是 0.01,啟動 ncpu 進程以後,分區將獲取到 4 個物理 CPU。這是因為分區為 uncapped 分區,期望虛擬處理器數數值為 4。
利用 topas 對 CPU 利用率進行查看:
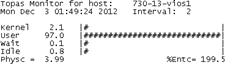
讀者如對此點如有疑慮,請參照本作者在 developerworks 網站發表的文章《虛擬化環境下 CPU 利用率的監控與探究》。
打開收集 10 分鐘的文件,觀察 CPU 部分內容:
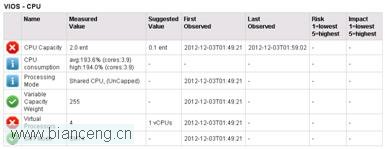
從上圖也可以看出,“CPU Consumption”裡取的數值,與 lparstat 命令中“%entc ”數值相同。
在監控的這段時間內,CPU 利用率接近 100%,而測試過程中,分區自動獲取到得物理 CPU 的數量是 4。工具建議將“CPU Capacity”設置為 0.1,“Virtual Processors”設置為 1。
按照工具建議,修改 VIOS 分區 profile 文件,然後重新激活分區:
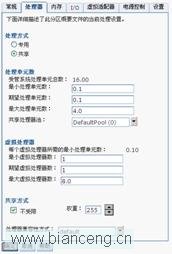
再次進行同樣的壓力測試,並且收集 10 分鐘性能信息:
# ./ncpu -p 15
./ncpu - processes=15 snooze=0% hibernate=0 secs forever
# lparstat 1
System configuration: type=Shared mode=Uncapped smt=4 lcpu=4 mem=4096MB psize=8 ent=0.10
%user %sys %wait %idle physc %entc lbusy app vcsw phint
----- ----- ------ ------ ----- ----- ------ --- ----- -----
0.3 5.1 0.0 94.6 0.01 12.2 0.0 7.99 443 0
0.1 4.3 0.0 95.6 0.01 9.3 0.0 7.99 369 0
0.7 5.8 0.2 93.3 0.01 12.8 2.7 7.83 421 0
0.2 4.7 0.0 95.1 0.01 10.8 0.0 7.99 442 0
0.6 5.9 0.0 93.5 0.01 13.4 0.0 7.99 482 0
0.1 5.2 0.0 94.6 0.01 11.7 0.2 7.99 516 0
0.2 5.2 0.0 94.5 0.01 12.0 0.5 7.99 503 0
0.1 4.7 0.0 95.2 0.01 10.4 0.2 7.99 466 0
92.8 1.3 0.0 5.9 0.44 444.9 40.1 7.51 392 0
99.7 0.3 0.0 0.0 1.00 1001.4 100.0 7.00 399 0
99.7 0.3 0.0 0.0 1.00 999.2 100.0 7.00 404 0
99.7 0.3 0.0 0.0 1.00 999.3 100.0 7.00 399 0
查看 topas 中 CPU 利用率的信息:
查看收集好的性能信息中的 CPU 部分:
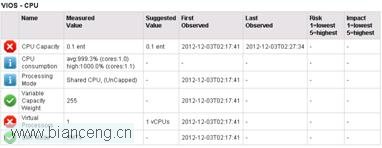
可以看到在當前情況下,分區設置的物理 CPU 和虛擬 CPU 數值與工具建議的數值一致。而在相同 CPU 壓力工具、相同 CPU 壓力的情況下(./ncpu -p 15),按照工具建議的數值設置後,VIOS 沒有發生掛起,而且 CPU 利用率相似,從這點上看,通過優化 CPU 調度,達到了節省物理 CPU 資源的目的。
在初始情況下,觀察內存的表現:
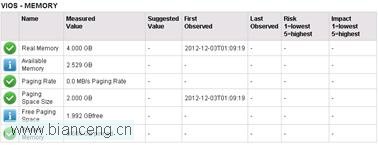
內存比較空閒,內存相關參數無需調整。可以用 nmon 查看內存利用率,得到的數值與工具中看到的結果是一致的:
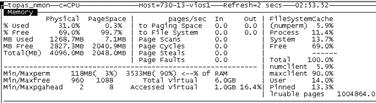
為了模擬消耗內存,在 AIX 系統中創建一個 ramdisk:
# mkramdisk 2200M/dev/rramdisk0
再用 nmon 查看內存,系統剩余物理內存已經大幅降低:
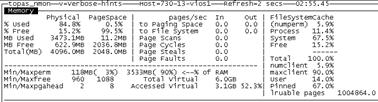
使用 VIOS Health Advisor 工具,收集 10 分鐘性能數據後,查看內存部分描述:
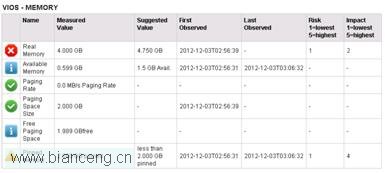
在上圖中,歎號圖標表示告警,打叉圖標表示嚴重告警。都需要注意。
工具建議將系統的物理內存增加到 4.75GB,這樣系統就可以有足夠的可用內存。
用鼠標點擊第一項“Real Memory”,可以看到修改建議的描述:
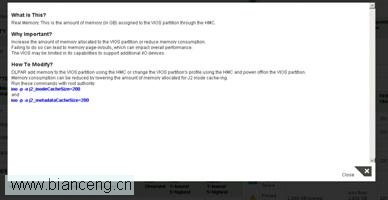
工具的建議是:
可以通過 DLPAR 增加分區的內存。
修改分區 profile 內存設置,然後重新激活分區,從而達到增加分區物理內存的目的。
降低 JFS2 所占內存的比重。
我們暫時不用 DLPAR 和修改分區 profile 的方法,先通過 ioo 的命令降低 JFS2 所占物理內存的比重,然後看一下效果是否明顯:
# ioo -p -o j2_inodeCacheSize=200
Setting j2_inodeCacheSize to 200 in nextboot file
Setting j2_inodeCacheSize to 200
# ioo -p -o j2_metadataCacheSize=200
Setting j2_metadataCacheSize to 200 in nextboot file
Setting j2_metadataCacheSize to 200
從下面結果可以看出,修改已經成功:
# ioo -a |grep -i j2_inodeCacheSize
j2_inodeCacheSize = 200
# ioo -a |grep -i j2_metadataCacheSize
j2_metadataCacheSize = 200
然後,再用 nmon 進行查看:
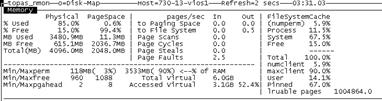
上圖的結果中,剩余物理內存與之前類似。
用工具收集性能數據,關注內存部分表現,與之前無異。證明 ioo 修改參數的方法無明顯效果。
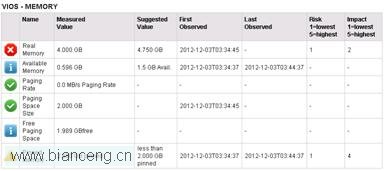
接下來,用 DLPAR,將分區的內存修改為 4.75GB,然後使用 nmon 進行查看,發現剩余物理內存已經增加:
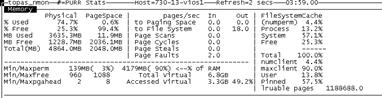
再次收集性能信息 10 分鐘,觀察內存表現:
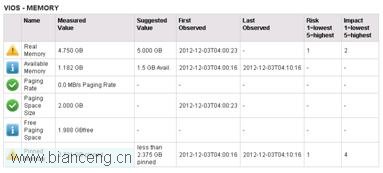
從上圖可以看出,之前的嚴重告警已經消除,嚴重告警降級為一般告警,建議繼續增加物理內存到 5GB。按照建議,使用 DLPAR,將物理內存增加到 5GB:
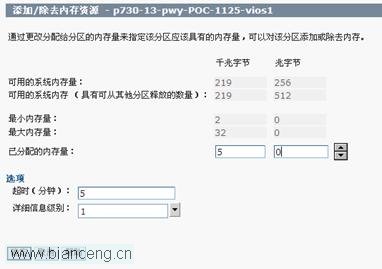
使用 nmon 進行內存查看:
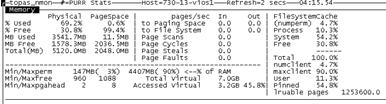
再次收集性能數據 10 分鐘,觀察內存部分描述:
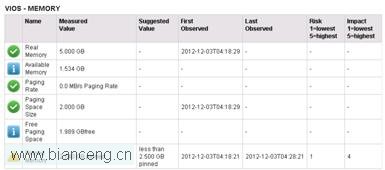
從上圖可以看出,之前“Real Memory”項告警已經完全消除。
對於另外一項 information 級別的告警“Pinned Memory”,用鼠標點開,查看描述:

工具的建議是:
1.通過 DLPAR 增加分區的內存。
2.修改分區 profile 內存設置,然後重新激活分區,從而達到增加分區物理內存的目的。
3.查看系統參數%maxpin,進行適當調整。
4.降低 JFS2 所占內存的比重。
# vmo -a |grep -i maxpin%
maxpin% = 80
可以看到,maxpin%的數值目前為 80%,將 maxpin%的數值降低到 60%,然後進行查看:
# vmo -o maxpin%=60
Setting maxpin% to 60
Nmon 查看內存使用率,可以看到 Pinned 的數值依然是 54.8%,沒有什麼效果。
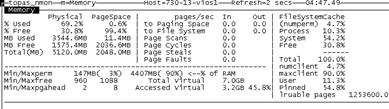
因此,這種情況下,比較有效果的方法:
檢查應用,查看是否存在內存洩露或者是否可以釋放內存。
增加物理內存。
選擇使用 DLPAR 為分區增加 2GB 物理內存,利用 nmon 進行查看:
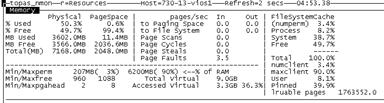
從上圖可以看出,pinned 內存比率已經下降很多。
再次收集性能信息,關注內存部分表現:
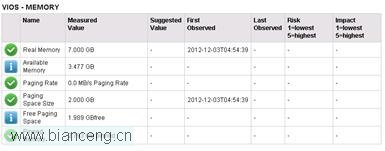
所有信息顯示均為正常。這樣,內存調整已經完成。
在初始情況下,磁盤沒有壓力,IOPS 和吞吐量都很低:

接下來,使用 dd if 命令給磁盤 hdisk6 發壓力,使其繁忙程度達到 100%:
# dd if=/dev/rhdisk1 of=/dev/null &
# iostat 1
Disks: % tm_act Kbps tps Kb_read Kb_wrtn
hdisk6 100.0 404090.0 1034.0 404090 0
cd0 0.0 0.0 0.0 0 0
用 VIOS Health Advisor 收集 10 分鐘系統性能數據,觀察磁盤 I/O 部分:
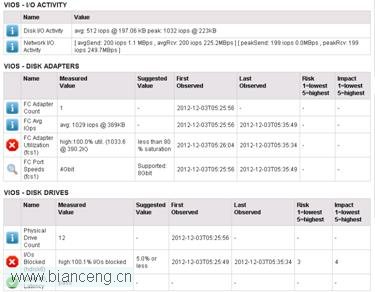
從上圖可以看出,嚴重告警級別的信息有兩個:“FC Adapter Utilization”和“I/Os Blocked”
鼠標點擊“FC Adapter Utilization (fcs1)”項,查看工具建議的方法:

工具建議的方法:使用更多的 HBA 卡端口,以便 I/O 負載均衡,從而降低 HBA 卡的利用率。
由於之前對 hdisk6 施加了較大的 I/O 壓力,因此磁盤利用率長時間為 100%,造成 I/O block。點擊“ I/Os Blocked (hdisk6)”這一項,查看建議:

工具建議的方法是:
1.盡量做到 I/O 負載均衡
2.調整磁盤 queue_depth 參數。
利用命令進行磁盤 I/O 隊列:
# iostat -DRTl 1
從上圖可以看出,磁盤 hdisk6 中的 I/O 數量很多,因此對於目前的 I/O 表現,調整 queue_depth 能夠起到一定的作用,但是能較大程度改善當前 I/O 性能改善的方法是使 I/O 負載均衡。
關於磁盤 I/O 性能調優的內容,請參照本作者在 developerworks 發表的文章《AIX 下磁盤 I/O 性能分析》
需要注意的是,目前 VIOS2.2.1 版本中自帶的 part 命令不能收集網絡方面的性能信息,在 2013 年新版本的工具中,將會加入對網絡監控的功能模塊。因此,在現有條件下,如果需要對網絡進行監控,可以從下載工具 VIOS Performance Advisor 工具。
VIOS Performance Advisor 與 VIOS Health Advisor 工具功能類似,也可以提供對 VIOS CPU、內存、磁盤 I/O 的監控。Health Advisor 在 VIOS2.2.2.1 中自帶,在此版本之前的 VIOS 中,如果想實現類似的功能,就需要下載使用 Performance Advisor 工具。從實驗效果來看,在 CPU、內存、磁盤 I/O 的監控效果以及建議方法的准確性來看,Health Advisor 的效果要好一些。
VIOS Performance Advisor 下載網址
http://www.ibm.com/developerworks/wikis/pages/viewpageattachments.action?pageId=172359709
工具下載完以後,將壓縮包上傳到 VIOS 系統中,對 zip 包進行解壓縮:
# unzip vios_advisor.zip
壓縮包解壓縮成一個新的目錄,增加目錄中文件的可執行權限:
在解壓縮出的文件中,vios_advisor 文件即為執行程序,最少監控時間為 5 分鐘,最大監控時間為 24 小時,推薦監控時間為 30 分鐘。
查看本欄目更多精彩內容:http://www.bianceng.cn/OS/unix/
利用 ftp 腳本向 VIOS 發網絡壓力,然後通過 VIOS Performance Advisor 收集 5 分鐘性能信息:
[root@atsnfs:/]cat 1.sh echo start at 'date's ftp -n 172.16.$1<<! user root time4fun bin prom put "|dd if=/dev/zero bs=$2 count=100000" /dev/null bye ! echo end at 'date' [root@atsnfs:/]sh 1.sh $1 14.40 $2 15000& [1] 36372660 [root@atsnfs:/]start at dates Interactive mode off.
監控 5 分鐘 VIOS 性能:
# ./vios_advisor 5
並使用使用 topas 查看 VIOS 的網絡流量:
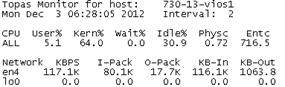
vios_advisor 命令執行完畢後,會生成報告文件,此時將整個目錄 ftp 下來,用浏覽器打開目錄中的 vios_advisor.xml 文件即可。關注報告中的網絡部分內容:
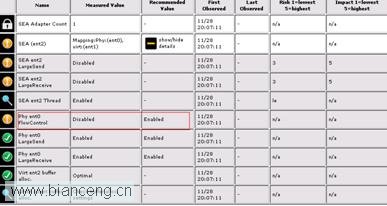
報告建議將物理網卡 FlowControl 參數設置為 Enable,點開詳細描述,裡面不僅介紹了 FlowControl 的作用,也給出了修改 FlowControl 的具體方法:

在系統中進行查看:
# lsattr -El ent0 |grep -i flow
flow_ctrl no Request Transmit and Receive Flow Control True
直接修改參數,會報錯:
# chdev -l ent2-a flow_ctrl=yes
Method error (/usr/lib/methods/chgent):
0514-062 Cannot perform the requested function because the
specified device is busy.
修改時,加上-P 參數:
# chdev -l ent0 -a flow_ctrl=yes -P
ent0 changed
然後重啟系統使變更生效:
#shutdown -Fr 0
VIOS 啟動以後,參數變更已經生效:
# lsattr -El ent0 |grep -i flow
flow_ctrl yes Request Transmit and Receive Flow Control True
關於磁盤 I/O 性能調優的內容,請參照本作者在 developerworks 發表的文章《Power740 服務器 IVE 網卡 etherchannlel 配置步驟與性能評估》
利用 Performance Advisor 工具分析 nmon 結果
VIOS Health Advisor 的 part 命令還有一個比較好的功能,就是可以分析生成的 nmon 報告。
例如,我們有多個服務器的 nmon 報告,逐一用 Nmon analyzer 分析,然後再逐一去查看比較麻煩,可以使用 part 工具,先大致快速了解這些服務器的運行情況,對於存在性能問題的服務器,再查看 nmon 進行具體的分析。
利用 VIOS 上現有的收集好的 nmon 進行測試:
使用 part 命令進行分析:
$ part -f 730-13-vios1_121203_0505.nmon
part: Reports are successfully generated in 730-13-vios1_121203_0505.tar
$
下載 730-13-vios1_121203_0505.tar 壓縮包,解壓縮後用浏覽器打開 xml 文件,就可以比較清晰地查看系統整體性能數據了。
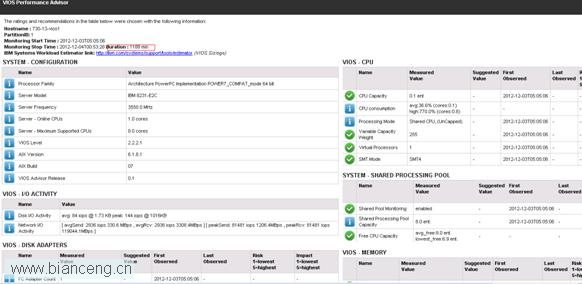
在傳統物理 LPAR 中,我們監控系統的性能指標相對比較容易。隨著 PowerVM 虛擬化使用越來越廣,在虛擬化環境下的性能監控要復雜得多。因此,VIOS Health Advisor 作為新版本 VIOS 自帶的工具,它可以定期監控 VIOS 的健康狀況和性能表現,並且可以分析任何 AIX 系統生成的 nmon 報告,這將大大減少運維人員的工作量,這對於 IBM 的客戶是十分有意義的。後續隨著 VIOS 版本的更新,這個工具的功能也將越來越全面,越來越強大。