


引言
內存子系統中最重要的優化部分並不涉及到實際的優化工作。在對您的系統進行優化之前,必須弄清楚主機系統的實際運行情況。要做到這一點,AIX? 管理員必須知道應該使用何種工具,以及如何對他或她將要捕獲的數據進行分析。再次說明近期發表的一些其他優化文章(請參見 參考資料)中所介紹的內容,您在對系統進行正確地優化之前,必須首先監視主機,無論它是在邏輯分區 (LPAR) 運行還是在自己的物理服務器上運行。您可以使用許多命令來捕獲和分析數據,所以您需要了解這些命令,以及其中的哪個命令最適合於將要進行的工作。在捕獲了相關的數據之後,您需要對結果進行分析。有些問題乍看起來像是一個中央處理單元 (CPU) 的問題,而經過分析之後,可以正確地診斷為內存或 I/O 問題,前提是您使用了合適的工具捕獲數據 ,並且知道如何進行分析工作。僅當正確地完成了這些工作之後,您才可以考慮對系統進行實際的更改。如果醫生不了解您的病史和目前的症狀,就無法診治疾病,同樣地,您也需要在優化子系統之前對其進行診斷。如果在出現 CPU 或者 I/O 瓶頸的情況下,對內存子系統進行優化,這將是毫無幫助的,甚至可能會影響主機的正常運行。
本文將幫助您了解正確地實施診斷工作的重要性。您將看到,性能優化並不僅僅只是進行實際的優化工作。在您將要學習的工具中,有一些是通用的監視工具,所有版本的 UNIX 都提供了這些工具,另外還有一些工具是專門為 AIX 編寫的。有些工具為 AIX Version 5.3 進行了優化,同時還專門為 AIX 5.3 系統開發了一些新的工具。
生成基准數據是非常重要的,這一點無論重申多少次都不為過。不要等到用戶開始抱怨糟糕的性能時,才開始監視您的系統。應該在將服務器投入生產環境中後,盡快地捕獲其中的數據。如果您做到了這一點,那麼您就可以積極主動地進行優化工作,其目標是在用戶指出存在的問題之前找到它。如果您不了解系統正常運行時的相關數據,那麼就無法確定所查看的數據是否表示存在性能問題。所有這些都是適當的性能優化方法中的一部分,有效地捕獲數據,並正確地分析其結果和趨勢。讓我們來進行仔細地研究。
UNIX 通用的內存監視
在這個部分中,我為在所有 UNIX 分發版都可以使用的一些通用 UNIX 工具提供了概述,包括 ps、sar 和 vmstat。其中的大多數工具都允許您快速地對性能問題進行故障排除,但是它們並不適合用於進行歷史趨勢研究和分析。
大多數管理員都不善於使用 ps 命令對可能的內存瓶頸進行故障排除。事實上,許多 UNIX 管理員甚至不知道可以使用 ps 幫助確定內存問題的原因。ps 最常用的功能是查看系統中運行的進程(請參見清單 1)。
清單 1. 使用 ps 查看系統中運行的進程
.
# ps gv | head -n 1; ps gv | egrep -v "RSS" | sort +6b -7 -n -r
PID TTY STAT TIME PGIN SIZE RSS LIM TSIZ TRS %CPU %MEM COMMAND
15256 - A 64:15 755 2572 2888 xx 2356 316 0.9 0.0 /usr/lpp/
22752 - A 0:08 261 1960 1980 32768 465 20 0.0 0.0 dtwm
14654 - A 0:00 324 1932 1932 xx 198 0 0.0 0.0 /usr/sbin
20700 - A 0:07 271 1868 1896 32768 95 28 0.0 0.0 /usr/dt/b
20444 - A 0:03 203 1736 1824 32768 551 88 0.0 0.0 dtfile
17602 - A 0:00 274 948 1644 32768 817 696 0.0 0.0 sendmail:
13218 - A 0:00 74 1620 1620 xx 116 0 0.0 0.0 /usr/sbin
讓我們首先來說明這些列所表示的含義:
內存數據:
avm——您所使用的活動虛擬內存量(單位為 4k 大小的頁面),不包括文件頁面。
fre——內存空閒列表的大小。在大多數情況下,我並不擔心這個值什麼時候變得很小,因為 AIX 總是會充分地使用內存,並且不會像您希望的那樣盡早地釋放內存。這個設置由 vmo 命令的 minfree 參數來確定。歸根結底,分頁的信息更加重要。
pi——從分頁空間調入的頁面。
po——調出到分頁空間的頁面。
CPU 和 I/O:
r——在您指定的時間間隔內,可運行內核線程的平均數量。
b——在您指定的時間間隔內,位於虛擬內存等待隊列中的內核線程的平均數量。如果 r 不大於 b,通常是 CPU 問題的症狀,這可能是由於 I/O 或者內存瓶頸造成的。
us——用戶時間。
sy——系統時間。
id——空閒時間。
wa——等待 I/O。
讓我們回到 vmstat 的輸出,您的系統究竟出現了什麼問題呢?首先是一條免責聲明:請不要根據 vmstat 的簡單輸出結果,向高級管理人員提交詳細的分析和建議采取的優化策略。在正確地診斷出系統中存在的問題之前,您必須完成更多的工作。當您碰到產品性能問題,並且需要立即了解系統的運行狀況時,您應該使用 vmstat,以便您可以警告其他人出現了什麼問題,或者馬上采取合適的措施(如果可以)。
現在,再回到輸出。出現了什麼問題呢?實際上,有好幾處問題。初看起來,您可能認為出現了 CPU 瓶頸,因為系統工作得非常辛苦,幾乎沒有什麼空閒時間。如果您仔細地觀察,那麼將會發現,除了 CPU 忙碌工作之外,還存在其他的問題,例如分頁。從 po 可以看出,出現了大量的頁面調出,這種情況通常會在實際內存缺乏的時候出現。在輸出結果中,甚至空閒列表也降到非常低的程度。其原因可能因為您的空閒列表 (fre) 比 minfree 的阈值(使用 vmo 進行設定的)要低一些。I/O 方面出現了什麼問題呢?當您發現阻塞的進程或者等待 I/O 的值 (wa) 很高時,這通常表示出現了實際的 I/O 問題,可能是等待文件訪問、或者與因為系統缺少內存而引起的分頁相關的 I/O 狀況。在這個示例中,看起來是後面這種情況。您碰到了 VMM 問題,而這些問題可能導致了阻塞的進程和等待 I/O 的狀況。通過優化內存參數、或者執行動態的 LPAR (DLPAR) 操作並向 LPAR 添加更多的 RAM,您可以解決這個問題。
讓我們進行更深入的研究。您可以使用前面介紹過的 ps 命令來嘗試確定影響系統的進程。通常在這種情況下,我會運行 sar 以檢查該問題是否在使用另一種工具進行分析時依然存在。最好是使用多種工具,以便提供進一步的幫助,從而確保診斷結果是正確的。
盡管與其他工具相比,我並不是很喜歡 sar(因為您需要使用許多的標志,並且在診斷問題之前必須輸入許多的命令),但是,它允許您實時地收集數據,並查看所捕獲的數據(使用 sadc)。大多數較早的工具都允許您使用不同的命令。自從有了 UNIX,就有了sar 命令,並且每個人都曾經用過這個命令。使用 -r 標志可以提供一些 VMM 信息(請參見清單 4)。
清單 4. 使用帶 -r 標志的 sar 以獲得 VMM 的信息
# svmon -G
size inuse free pin virtual
memory 1048576 1048416 160 79327 137750
pg space 1048576 524
work pers clnt lpage
pin 79327 0 0 0
in use 137764 910652 0 0
從這個示例中,您可以確定該進程並沒有使用分頁空間。使用前面介紹過的 ps 命令,再加上 svmon,您就可以找出大量消耗內存資源的位置。
讓我們使用一種對用戶來說更加友好的工具,topas。topas 是一種非常優秀的小型性能監視工具,它可以用於許多目的(請參見 圖 1)。
圖 1. topas 工具
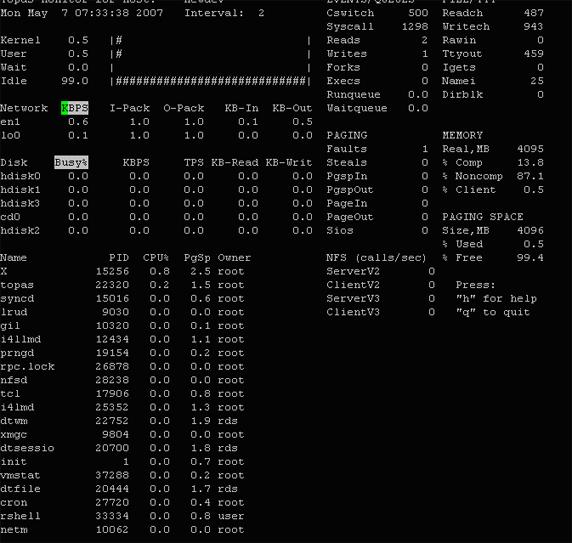
正如您所看到的,運行 topas 將為您提供一個有關進程信息、CPU、I/O 和 VMM 活動的列表。從這個列表中,您可以看到該系統僅使用了很少的分頁空間。我常常使用這個命令快速地進行故障排除,特別是當我希望在屏幕上顯示比 vmstat 更詳細的內容時。我將topas 看作是 vmstat 的圖形化版本。在經過改進之後,現在它可以捕獲數據以進行歷史分析。
procmon 命令又如何呢?它在 AIX Version 5.3 中首次引入,不僅可以提供整體 CPU 性能統計,還允許您對實際運行的進程進行相應的操作。您可能已經了解,可以動態地對一個進程使用 kill 或者 renice 命令,但我敢打賭,您肯定不清楚如何深入地研究有關內存的內容。
盡管我認為人們通常使用這個工具進行 CPU 分析,但是它也為 svmon 提供了很好的掛鉤,以便在緊要關頭為您提供幫助。這個視圖可以為從 procmon 中使用 svmon 實用工具設置相關的選項,它允許您以一種更合適的格式提取信息(請參見圖 2)。
圖 2. 為從 procmon 中使用 svmon 實用工具設置選項
您還可以將 procmon 數據導出到一個文件,這使得它成為一種優秀的數據收集工具。
在所有的性能工具中,我最喜歡的是一種不受支持的 IBM 工具,名為 nmon。它在某些方面與 topas 類似,nmon 收集到的數據可以顯示在屏幕上(類似於 topas)或者通過報告提供(您可以捕獲相關的信息以進行趨勢研究和分析)。這個工具提供了一些其他工具所沒有的功能,它可以在 Microsoft? Excel 電子表格中顯示美觀的圖表,可以將其交給高級管理人員或者其他技術團隊進行更深入地分析。可以使用另一種不受支持的工具,名為 nmon analyzer,它為 nmon 提供了相應的掛鉤。圖 3 顯示了 nmon 分析結果的一個示例。
圖 3. nmon 分析輸出
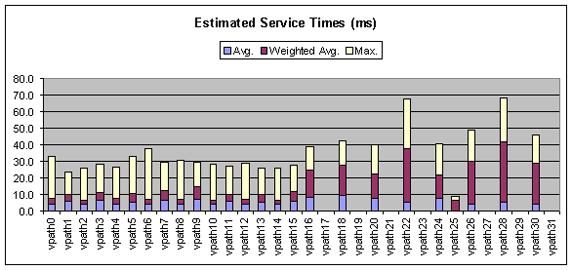
在使用這個工具的過程中,您將看到 nmon 所提供的許多不同類型的視圖,這些視圖可以提供所有關於 CPU、I/O 和內存的使用信息。
總結
在本文中,您了解了可用於捕獲數據以進行內存分析的各種工具。您還學習了如何對存在性能問題的系統進行故障排除,您可以對虛擬內存進行控制。優化工作實際上只是適當的優化方法中的一小部分,對於這一點,重申多少次都不為過。如果不能夠捕獲數據並仔細地、正確地分析您的系統,那麼您所能做的工作就好像是一名醫生根本不對患者進行檢查就胡亂地使用抗生素藥物。
您可以使用許多不同類型的性能監視工具。有些工具可以從命令行中運行,以便快速地檢查系統的運行情況。有些工具更適合於進行長期的趨勢研究和分析。有些工具甚至可以為您提供圖形格式的數據,可以將這些數據交給非技術方面的工作人員。無論您使用哪種工具,都還必須仔細地了解您所查看的信息的真正含義。不要只根據少量的數據樣本,就急於得出結論。另外,不要僅依賴於某一種工具。為了證實您的結論,在進行分析時,您應該至少使用兩種不同的工具。我還簡要地介紹了優化方法和建立系統正常運行時的基准數據的重要性。在您檢查數據並實施優化之後,您必須繼續捕獲數據,並分析所作更改的結果。而且,您應該一次只進行一處更改,這樣才能夠真正地確定每項更改的效果。
返回第一頁:http://www.bianceng.cn/OS/unix/201312/39140.htm