


查找文件中使用的單詞的頻率是一件很有意思的事情,下面,我們利用 關聯數組,awk,sed,grep 等不 同的方式來解決問題。
首先,我們需要一個測試用的文本,保存名為 word.txt
內容如 下:
Word used this counting this
接下來需要編寫Shell腳本程序,如下所示:
#!/bin/bash
#Name: word_freq.sh
#Description: Find out frequency of words in a file
if [ $# -ne 1 ];
then
echo "Usage: $0 filename";
exit -1
fi
filename=$1
egrep -o "\b[[:alpha:]]+\b" $filename | \
awk '{ count[$0]++ } END{ printf("%-14s%s\n","Word","Count") ; \
for(ind in count) { printf("%-14s%d\n",ind,count[ind]); } }'
工作原理介紹:
1.egrep -o "\b[[:alpha:]]+\b" $filename 用來只輸出單詞,用 -o 選項打印出由換行符分割的匹配字符序列,這樣我們就可以在每行中列出一個單詞
2.\b 是單詞邊界標記符。[:alpha:] 是表示字母的字符類
3.awk命令用來避免對每一個單詞進行迭代
下面給出運行的截圖:
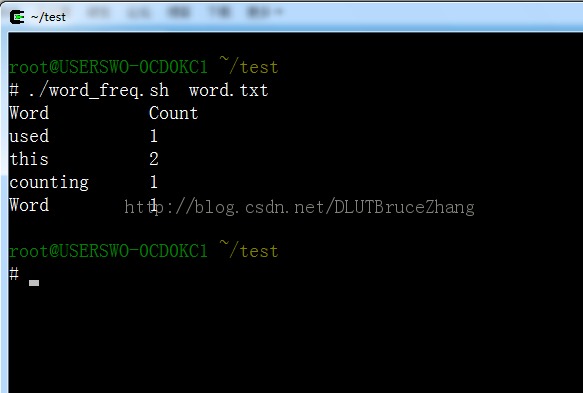
關於awk命令請 參考博主的其他博客。