和前面文章的第一部分一樣,這些文字是為了幫別人或者自己理清思路的,而不是所謂的源碼分析,想分析源碼的,還是直接debug源碼最好,看任何文檔以及書都是下策。因此這類幫人理清思路的文章盡可能的記成流水的方式,盡可能的簡單明了。
Linux 2.6+內核的wakeup callback機制
Linux內核通過睡眠隊列來組織所有等待某個事件的task,而wakeup機制則可以異步喚醒整個睡眠隊列上的task,每一個睡眠隊列上的節點都擁有一個callback,wakeup邏輯在喚醒睡眠隊列時,會遍歷該隊列鏈表上的每一個節點,調用每一個節點的callback,如果遍歷過程中遇到某個節點是排他節點,則終止遍歷,不再繼續遍歷後面的節點。總體上的邏輯可以用下面的偽代碼表示:
睡眠等待
define sleep_list;
define wait_entry;
wait_entry.task= current_task;
wait_entry.callback = func1;
if (something_not_ready); then
# 進入阻塞路徑
add_entry_to_list(wait_entry, sleep_list);
go on:
schedule();
if (something_not_ready); then
goto go_on;
endif
del_entry_from_list(wait_entry, sleep_list);
endif
...
喚醒機制
something_ready;
for_each(sleep_list) as wait_entry; do
wait_entry.callback(...);
if(wait_entry.exclusion); then
break;
endif
done
我們只需要狠狠地關注這個callback機制,它能做的事真的不止select/poll/epoll,Linux的AIO也是它來做的,注冊了callback,你幾乎可以讓一個阻塞路徑在被喚醒的時候做任何事情。一般而言,一個callback裡面都是以下的邏輯:
common_callback_func(...)
{
do_something_private;
wakeup_common;
}
其中,do_something_private是wait_entry自己的自定義邏輯,而wakeup_common則是公共邏輯,旨在將該wait_entry的task加入到CPU的就緒task隊列,然後讓CPU去調度它。
現在留個思考,如果實現select/poll,應該在wait_entry的callback上做什麼文章呢?
.....
select/poll的邏輯
要知道,在大多數情況下,要高效處理網絡數據,一個task一般會批量處理多個socket,哪個來了數據就去讀那個,這就意味著要公平對待所有這些socket,你不可能阻塞在任何socket的“數據讀”上,也就是說你不能在阻塞模式下針對任何socket調用recv/recvfrom,這就是多路復用socket的實質性需求。
假設有N個socket被同一個task處理,怎麼完成多路復用邏輯呢?很顯然,我們要等待“數據可讀”這個事件,而不是去等待“實際的數據”!!我們要阻塞在事件上,該事件就是“N個socket中有一個或多個socket上有數據可讀”,也就是說,只要這個阻塞解除,就意味著一定有數據可讀,意味著接下來調用recv/recvform一定不會阻塞!另一方面,這個task要同時排入所有這些socket的sleep_list上,期待任意一個socket只要有數據可讀,都可以喚醒該task。
那麼,select/poll這類多路復用模型的設計就顯而易見了。
select/poll的設計非常簡單,為每一個socket引入一個poll例程,該歷程對於“數據可讀”的判斷如下:
poll()
{
...
if (接收隊列不為空) {
ev |= POLL_IN;
}
...
}
當task調用select/poll的時候,如果沒有數據可讀,task會阻塞,此時它已經排入了所有N個socket的sleep_list,只要有一個socket來了數據,這個task就會被喚醒,接下來的事情就是
for_each_N_socket as sk; do
event.evt = sk.poll(...);
event.sk = sk;
put_event_to_user;
done;
可見,只要有一個socket有數據可讀,整個N個socket就會被遍歷一遍調用一遍poll函數,看看有沒有數據可讀,事實上,當阻塞在select/poll的task被喚醒的時候,它根本不知道具體socket有數據可讀,它只知道這些socket中至少有一個socket有數據可讀,因此它需要遍歷一遍,以示求證,遍歷完成後,用戶態task可以根據返回的結果集來對有事件發生的socket進行讀操作。
可見,select/poll非常原始,如果有100000個socket(誇張嗎?),有一個socket可讀,那麼系統不得不遍歷一遍...因此select只限制了最多可以復用1024個socket,並且在Linux上這是宏控制的。select/poll只是樸素地實現了socket的多路復用,根本不適合大容量網絡服務器的處理場景。其瓶頸在於,不能隨著socket的增多而戰時擴展性。
epoll對wait_entry callback的利用
既然一個wait_entry的callback可以做任意事,那麼能否讓其做的比select/poll場景下的wakeup_common更多呢?
為此,epoll准備了一個鏈表,叫做ready_list,所有處於ready_list中的socket,都是有事件的,對於數據讀而言,都是確實有數據可讀的。epoll的wait_entry的callback要做的就是,將自己自行加入到這個ready_list中去,等待epoll_wait返回的時候,只需要遍歷ready_list即可。epoll_wait睡眠在一個單獨的隊列(single_epoll_waitlist)上,而不是socket的睡眠隊列上。
和select/poll不同的是,使用epoll的task不需要同時排入所有多路復用socket的睡眠隊列,這些socket都擁有自己的隊列,task只需要睡眠在自己的單獨隊列中等待事件即可,每一個socket的wait_entry的callback邏輯為:
epoll_wakecallback(...)
{
add_this_socket_to_ready_list;
wakeup_single_epoll_waitlist;
}
為此,epoll需要一個額外的調用,那就是epoll_ctrl ADD,將一個socket加入到epoll table中,它主要提供一個wakeup callback,將這個socket指定給一個epoll entry,同時會初始化該wait_entry的callback為epoll_wakecallback。整個epoll_wait以及協議棧的wakeup邏輯如下所示:
協議棧喚醒socket的睡眠隊列
1.數據包排入了socket的接收隊列;;
2.喚醒socket的睡眠隊列,即調用各個wait_entry的callback;
3.callback將自己這個socket加入ready_list;
4.喚醒epoll_wait睡眠在的單獨隊列。
自此,epoll_wait繼續前行,遍歷調用ready_list裡面每一個socket的poll歷程,搜集事件。這個過程是例行的,因為這是必不可少的,ready_list裡面每一個socket都有數據可讀,做不了無用功,這是和select/poll的本質區別(select/poll中,即便沒有數據可讀,也要全部遍歷一遍)。
總結一下,epoll邏輯要做以下的例程:
epoll add邏輯
define wait_entry
wait_entry.socket = this_socket;
wait_entry.callback = epoll_wakecallback;
add_entry_to_list(wait_entry, this_socket.sleep_list);
epoll wait邏輯
define single_wait_list
define single_wait_entry
single_wait_entry.callback = wakeup_common;
single_wait_entry.task = current_task;
if (ready_list_is_empty); then
# 進入阻塞路徑
add_entry_to_list(single_wait_entry, single_wait_list);
go on:
schedule();
if (sready_list_is_empty); then
goto go_on;
endif
del_entry_from_list(single_wait_entry, single_wait_list);
endif
for_each_ready_list as sk; do
event.evt = sk.poll(...);
event.sk = sk;
put_event_to_user;
done;
epoll喚醒的邏輯
add_this_socket_to_ready_list;
wakeup_single_wait_list;
綜合以上,可以給出下面的關於epoll的流程圖,可以對比本文第一部分的流程圖做比較
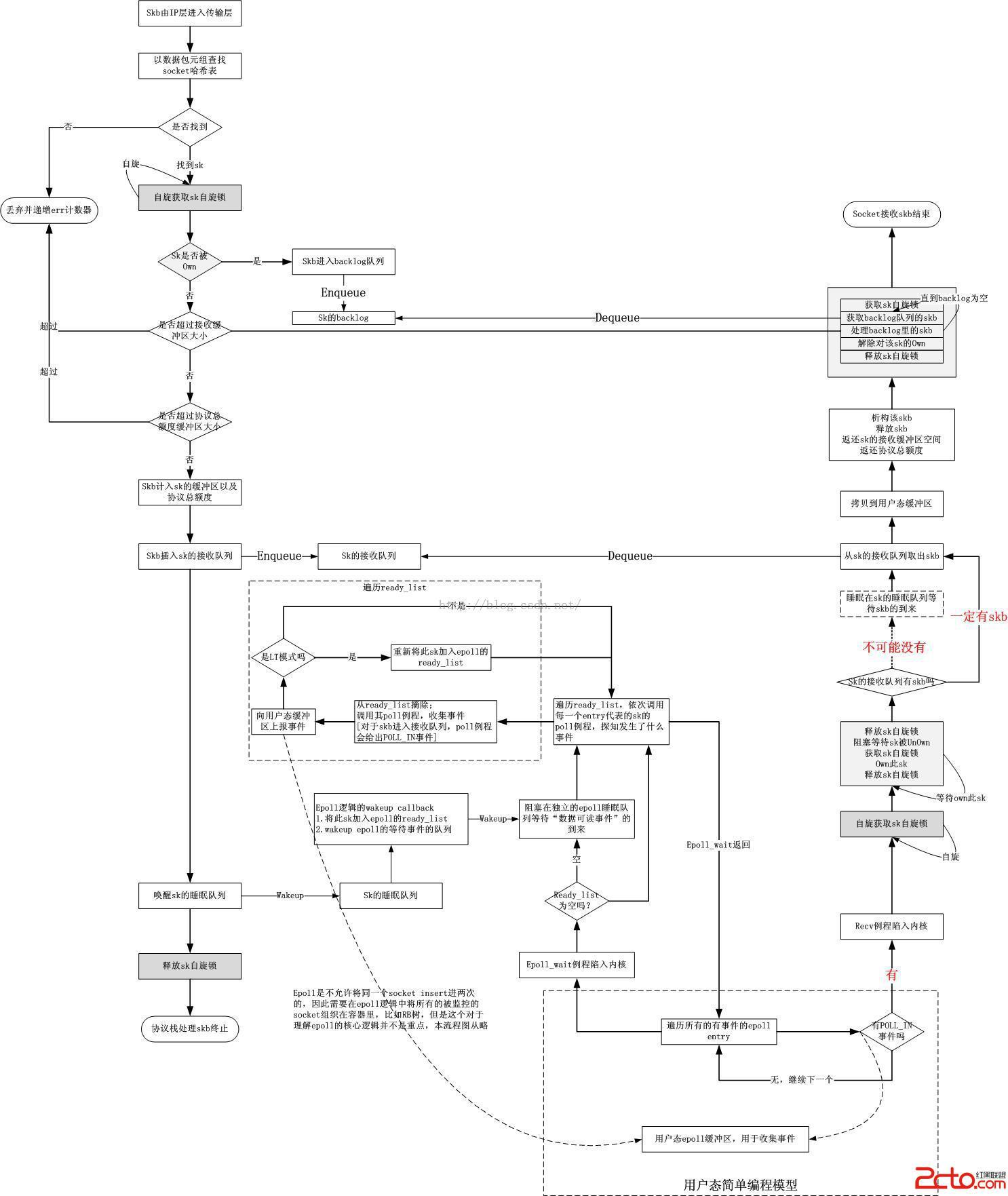
可以看出,epoll和select/poll的本質區別就是,在發生事件的時候,每一個epoll item(也就是socket)都擁有自己單獨的一個wakeup callback,而對於select/poll而言,只有一個!這就意味著epoll中,一個socket發生事件,可以調用其獨立的callback來處理它自身。從宏觀上看,epoll的高效在於分離出了兩類睡眠等待,一個是epoll本身的睡眠等待,它等待的是“任意一個socket發生事件”,即epoll_wait調用返回的條件,它並不適合直接睡眠在socket的睡眠隊列上,如果真要這樣,到底睡誰呢?畢竟那麼多socket...因此它只睡自己。一個socket的睡眠隊列一定要僅僅和它自己相關,因此另一類睡眠等待是每一個socket自身的,它睡眠在自己的隊列上即可。
epoll的ET和LT
是時候提到ET和LT了,最大的爭議在於哪個性能高,而不是到底怎麼用。各種文檔上都說ET高效,但事實上,根本不是這樣,對於實際而言,LT高效的同時,更安全。兩者到底什麼區別呢?
概念上的區別
ET:只有狀態發生變化的時候,才會通知,比如數據緩沖去從無到有的時候(不可讀-可讀),如果緩沖區裡面有數據,便不會一直通知;
LT:只要緩沖區裡面有數據,就會一直通知。
查了很多資料,得到的答案無非就是類似上述的,然而如果看Linux的實現,反而讓人對ET更加迷惑。什麼叫狀態發生變化呢?比如數據接收緩沖區裡面一次性來了10個數據包,對比上述流程圖,很顯然會調用10次的wakeup操作,是不是意味著這個socket要被加入ready_list 10次呢?肯定不是這樣的,第二個數據包到來調用wakeup callback時,發現該socket已經在ready_list了,肯定不會再加了,此時epoll_wait返回,用戶讀取了1個數據包之後,假設程序有bug,便不再讀取了,此時緩沖區裡面還有9個數據包,問題來了,此時如果協議棧再排入一個包,到底是通知還是不通知呢??按照概念理解,不會通知了,因為這不是“狀態的變化”,但是事實上在Linux上你試一下的話,發現是會通知的,因為只要有包排入socket隊列,就會觸發wakeup callback,就會將socket放入ready_list中,對於ET而言,在epoll_wait返回前,socket就已經從ready_list中摘除了。因此,如果在ET模式下,你發現程序阻塞在epoll_wait了,並不能下結論說一定是數據包沒有收完一個原因導致的,也可能是數據包確實沒有收完,但如果此時來一個新的數據包,epoll_wait還是會返回的,雖然這並沒有帶來緩沖去狀態的邊沿變化。
因此,對於緩沖區狀態的變化,不能簡單理解為有和無這麼簡單,而是數據包的到來和不到來。
ET和LT是中斷的概念,如果你把數據包的到來,即插入到socket接收隊列這件事理解成一個中斷事件,所謂的邊沿觸發不就是這個概念嗎?
實現上的區別
在代碼實現的邏輯上,ET和LT實現的區別在於LT一旦有事件則會一直加進ready_list,直到下一次的poll將其移出,然後在探測到感興趣事件後再將其加進ready_list。由poll例程來判斷是否有事件,而不是完全依賴wakeup callback,這是真正意義的poll,即不斷輪詢!也就是說,LT模式是完全輪詢的,每次都會去poll一次,直到poll不到感興趣的事件,才會歇息,此時就只有數據包的到來可以重新依賴wakeup callback將其加入ready_list了。在實現上,從下面的代碼可以看出二者的差異。
epoll_wait
for_each_ready_list_item as entry; do
remove_from_ready_list(entry);
event = entry.poll(...);
if (event) then
put_user;
if (LT) then
# 以下一次poll的結論為結果
add_entry_to_ready_list(entry);
endif
endif
done
性能上的區別
性能的區別主要體現在數據結構的組織以及算法上,對於epoll而言,主要就是鏈表操作和wakeup callback操作,對於ET而言,是wakeup callback將socket加入到ready_list,而對於LT而言,則除了wakeup callback可以將socket加入到ready_list之外,epoll_wait也可以將其為了下一次的poll加入到ready_list,wakeup callback中反而有更少工作量,但這並不是性能差異的根本,性能差異的根本在於鏈表的遍歷,如果有海量的socket采用LT模式,由於每次發生事件後都會再次將其加入ready_list,那麼即便是該socket已經沒有事件了,還是會用一次poll來確認,這額外的一次對於無事件socket沒有意義的遍歷在ET上是沒有的。但是注意,遍歷鏈表的性能消耗只有在鏈表超長時才會體現,你覺得千兒八百的socket就會體現LT的劣勢嗎?誠然,ET確實會減少數據可讀的通知次數,但這事實上並沒有帶來壓倒性的優勢。
LT確實比ET更容易使用,也不容易死鎖,還是建議用LT來正常編程,而不是用ET來偶爾炫技。
編程上的區別
epoll的ET在阻塞模式下,無法識別到隊列空事件,從而只是阻塞在單獨一個socket的Recv而不是所有被監控socket的epoll_wait調用上,雖然不會影響代碼的運行,只要該socket有數據到來便好,但是會影響編程邏輯,這意味著解除了多路復用的武裝,造成大量socket的饑餓,即便有數據了,也沒法讀。當然,對於LT而言,也有類似的問題,但是LT會激進地反饋數據可讀,因此事件不會輕易因為你的編程錯誤而被丟棄。
對於LT而言,由於它會不斷反饋,只要有數據,你想什麼時候讀就可以什麼時候讀,它永遠有“下一次poll”的機會主動探知是否有數據可以繼續讀,即便使用阻塞模式,只要不要跨越阻塞邊界造成其他socket饑餓,讀多少數據均可以,但是對於ET而言,它在通知你的應用程序數據可讀後,雖然新的數據到來還是會通知,但是你並不能控制新的數據一定會來以及什麼時候來,所以你必須讀完所有的數據才能離開,讀完所有的時候意味著你必須可以探知數據為空,因此也就是說,你必須采用非阻塞模式,直到返回EAGIN錯誤。
給出幾個ET模式下的tips
1.隊列緩沖區的大小包括skb結構體本身的長度,230左右
2.ET模式下,wakeup callback中將socket加入ready_list的次數 >= 收到數據包的個數,因此
多個數據報足夠快到達可能只會觸發一次epoll wakeup callback的成功回調,此時只會將socket添加進ready_list一次
=>造成隊列滿
=>後續的大報文加不進去
=>瓶塞效應
=>可以填補緩沖區剩余hole的小報文可以觸發ET模式的epoll_wait返回,如果最小長度就是1,那麼可以發送0長度的包引誘epoll_wait返回
=>但是由於skb結構體的大小是固有大小,以上的引誘不能保證會成功。
3.epoll驚群,可以參考ngx的經驗
4.epoll也可借鑒NAPI關中斷的方案,直到Recv例程返回EAGIN或者發生錯誤,epoll的wakeup callback不再被調用,這意味著只要緩沖區不為空,就算來了新的數據包也不會通知了。
a.只要socket的epoll wakeup callback被調用,禁掉後續的通知;
b.Recv例程在返回EAGIN或者錯誤的時候,開始後續的通知。


