與網絡數據包的發送不同,網絡收包是異步的的,因為你不確定誰會在什麼時候突然發一個網絡包給你,因此這個網絡收包邏輯其實包含兩件事:
1.數據包到來後的通知
2.收到通知並從數據包中獲取數據
這兩件事發生在協議棧的兩端,即網卡/協議棧邊界以及協議棧/應用邊界:
網卡
/協議棧邊界:網卡通知數據包到來,中斷協議棧收包;
協議棧棧/應用邊界:協議棧將數據包填充socket隊列,通知應用程序有數據可讀,應用程序負責接收數據。
本文就來介紹一下關於這兩個邊界的這兩件事是怎麼一個細節,關乎網卡中斷,NAPI,網卡poll,select/poll/epoll等細節,並假設你已經大約懂了這些。
網卡/協議棧邊界的事件
網卡在數據包到來的時候會觸發中斷,然後協議棧就知道了數據包到來事件,接下來怎麼收包完全取決於協議棧本身,這就是網卡中斷處理程序的任務,當然,也可以不采用中斷的方式,而是采用一個單獨的線程不斷輪詢網卡是否有數據包的到來,但是這種方式過於消耗CPU,做過多的無用功,因此基本被棄用,像這種異步事件,基本都是采用中斷通知的方案。綜合整個收包邏輯,大致可以分為以下兩種方式
a.每個數據包到來即中斷CPU,由CPU調度中斷處理程序進行收包處理,收包邏輯又分為上半部和下半部,核心的協議棧處理邏輯在下半部完成。
b.數據包到來,中斷CPU,CPU調度中斷處理程序並且關閉中斷響應,調度下半部不斷輪詢網卡,收包完畢或者達到一個閥值後,重新開啟中斷。
其中的方式a在數據包持續快速到達的時候會造成很大的性能損害,因此這種情況下一般采用方式b,這也是Linux NAPI采用的方式。
關於網卡/協議棧邊界所發生的事件,不想再說更多了,因為這會涉及到很多硬件的細節,比如你在NAPI方式下關了中斷後,網卡內部是怎麼緩存數據包的,另外考慮到多核處理器的情形,是不是可以將一個網卡收到的數據包中斷到不同的CPU核心呢?那麼這就涉及到了多隊列網卡的問題,而這些都不是一個普通的內核程序員所能駕馭的,你要了解更多的與廠商相關的東西,比如Intel的各種規范,各種讓人看到暈的手冊...
協議棧/socket邊界事件
因此,為了更容易理解,我決定在另一個邊界,即協議棧棧/應用邊界來描述同樣的事情,而這些基本都是內核程序員甚至應用程序員所感興趣的領域了,為了使後面的討論更容易進行,我將這個協議棧棧/應用邊界重命名為協議棧/socket邊界,socket隔離了協議棧和應用程序,它就是一個接口,對於協議棧,它可以代表應用程序,對於應用程序,它可以代表協議棧,當數據包到來的時候,會發生如下的事情:
1).協議棧將數據包放入socket的接收緩沖區隊列,並通知持有該socket的應用程序;
2).CPU調度持有該socket的應用程序,將數據包從接收緩沖區隊列中取出,收包完畢。
總體的示意圖如下
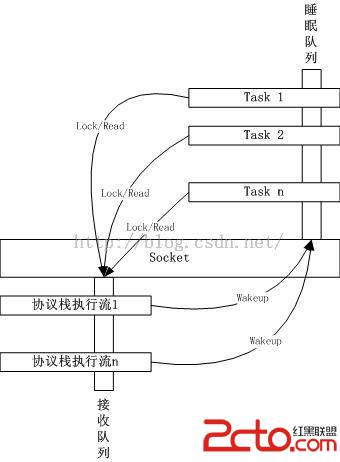
socket要素
如上圖所示,每一個socket的收包邏輯都包含以下兩個要素
接收隊列
協議棧處理完畢的數據包要排入到的隊列,應用程序被喚醒後要從該隊列中讀取數據。
睡眠隊列
與該socket相關的應用程序如果沒有數據可讀,可以在這個隊列上睡眠,一旦協議棧將數據包排入socket的接收隊列,將喚醒該睡眠隊列上的進程或者線程。
一把socket鎖
在有執行流操作socket的元數據的時候,必須鎖定socket,注意,接收隊列和睡眠隊列並不需要該鎖來保護,該鎖所保護的是類似socket緩沖區大小修改,TCP按序接收之類的事情。
這個模型非常簡單且直接,和網卡中斷CPU通知網絡上有數據包到來需要處理一樣,協議棧通過這種方式通知應用程序有數據可讀,在繼續討論細節以及select/poll/epoll之前,先說兩個無關的事,後面就不再說了,只是因為它們相關,所以只是提一下而已,不會占用大量篇幅。
1.驚群與排他喚醒
類似TCP accpet邏輯這樣,對於大型web服務器而言,基本上都是有多個進程或者線程同時在一個Listen socket上進行accept,如果協議棧將一個客戶端socket排入了accept隊列,是將這些線程全部喚醒還是只喚醒一個呢?如果是全部喚醒,很顯然,只有一個線程會搶到這個socket,其它的線程搶奪失敗後繼續睡眠,可以說是被白白喚醒了,這就是經典的TCP驚群,因此產生了一種排他式的喚醒,也就是說只喚醒睡眠隊列上的第一個線程,然後退出wakeup邏輯,不再喚醒後面的線程,這就避免了驚群。
這個話題在網上的討論早就已經汗牛充棟,但是仔細想一下就會發現排他喚醒依然有問題,它會大大降低效率。
為什麼這麼說呢?因為協議棧的喚醒操作和應用程序的實際Accept操作之間是完全異步的,除非在協議棧喚醒應用程序的時候,應用程序恰好阻塞在Accept上,任何人都不能保證當時應用程序在干什麼。舉一個簡單的例子,在多核系統上,協議棧方面同時來了多個請求,而且也恰恰有多個線程等待在睡眠隊列上,如果能讓這多個協議棧執行流同時喚醒這多個線程該有多好,但是由於一個socket只有一個Accept隊列,因此對於該隊列的排他喚醒機制基本上將這個暢想給打回去了,唯一一個accpet隊列的排入/取出的帶鎖操作讓整個流程串行化了,完全喪失了多核並行的優勢,因此REUSEPORT以及基於此的FastTCP就出現了。(今天周末,仔細研究了Linux kernel 4.4版本帶來的更新,真的讓人眼前一亮啊,後面我會單獨寫一篇文章來描述)
2.REUSEPORT與多隊列
起初在了解到google的reuseport之前,我個人也做過一個類似的patch,當時的想法正是來自於與多隊列網卡的類比,既然一塊網卡可以中斷多個CPU,一個socket上的數據可讀事件為什麼不能中斷多個應用程序呢?然而socket API早就已經固定死了,這對我的想法造成了打擊,因為一個socket就是一個文件描述符,表示一個五元組(非connect UDP的socket以及Listen tcp除外!),協議棧的事件恰恰只跟一個五元組相關...因此為了讓想法可行,只能在socket API之外做文章,那就是允許多個socket綁定同樣的IP地址/源端口對,然後按照源IP地址/端口對的HASH值來區分流量的路由,這個想法本人也實現了,其實跟多隊列網卡是一個思想,完全一致的。多隊列網卡不也是按照不同五元組(或者N元組?咱不較真兒)的HASH值來中斷不同的CPU核心的嗎?仔細想想當時的這個移植太TMD帥了,然而看到google的reuseport patch就覺得自己做了無用功,重新造了輪子...於是就想解決Accept單隊列的問題,既然已經多核時代了,為什麼不在每個CPU核心上保持一個accept隊列呢?應用程序的調度讓schedule子系統去考慮吧...這次沒有犯傻,於是看到了新浪的FastTCP方案。
當然,如果REUSEPORT的基於源IP/源端口對的hash計算,直接避免了將同一個流“中斷”到不同的socket的接收隊列上。
好了,插曲已經說完,接下來該細節了。
接收隊列的管理
接收隊列的管理其實非常簡單,就是一個skb鏈表,協議棧將skb插入到鏈表的時候先lock住隊列本身,然後插入skb,然後喚醒socket睡眠隊列上的線程,接著線程加鎖獲取socket接收隊列上skb的數據,就是這麼簡單。
起碼在2.6.8的內核上就是這麼搞的。後來的版本都是這個基礎版本的優化版本,先後經歷了兩次的優化。
接收路徑優化1:引入backlog隊列
考慮到復雜的細節,比如根據收到的數據修改socket緩沖區大小時,應用程序在調用recv例程時需要對整個socket進行鎖定,在復雜的多核CPU環境中,有多個應用程序可能會操作同一個socket,有多個協議棧執行流也可能會往同一個socket接收緩沖區排入skb[詳情請參考《多核心Linux內核路徑優化的不二法門之-多核心平台TCP優化》],因此鎖的粒度范圍自然就變成了socket本身。在應用程序持有socket的時候,協議棧由於可能會在軟中斷上下文運行,是不可睡眠等待的,為了使得協議棧執行流不至於因此而自旋阻塞,引入了一個backlog隊列,協議棧在應用程序持有socket的時候,只需要將skb排入backlog隊列就可以返回了,那麼這個backlog隊列最終由誰來處理呢?
誰找的事誰來處理!當初就是因為應用程序lock住了socket而使得協議棧不得不將skb排入backlog,那麼在應用程序release socket的時候,就會將backlog隊列裡面的skb放入接收隊列中去,模擬協議棧將skb入隊並喚醒操作。
引入backlog隊列後,單一的接收隊列變成了一個兩階段的接力隊列,類似流水線作業那樣。這樣無論如何協議棧都不用阻塞等待,協議棧如果不能馬上將skb排入接收隊列,那麼這件事就由socket鎖定者自己來完成,等到它放棄鎖定的時候這件事即可進行。操作例程如下:
協議棧排隊skb---
獲取socket自旋鎖
應用程序占有socket的時候:將skb排入backlog隊列
應用程序未占有socket的時候:將skb排入接收隊列,喚醒接收隊列
釋放socket自旋鎖
應用程序接收數據---
獲取socket自旋鎖
阻塞占用socket
釋放socket自旋鎖
讀取數據:由於已經獨占了socket,可以放心地將接收隊列skb的內容拷貝到用戶態
獲取socket自旋鎖
將backlog隊列的skb排入接收隊列(這其實本該由協議棧完成的,但是由於應用程序占有socket而被延後到了此刻),喚醒睡眠隊列
釋放socket自旋鎖
可以看到,所謂的socket鎖,並不是一把簡單的自旋鎖,而是在不同的路徑有不同的鎖定方式,總之,只要能保證socket的元數據受到保護,方案都是合理的,於是我們看到這是一個兩層鎖的模型。
兩層鎖定的lock框架
啰嗦了這麼多,其實我們可以把上面最後的那個序列總結成一個更為抽象通用的模式,在某些場景下可以套用。現在就描述一下這個模式。
參與者類別:NON-Sleep-不可睡眠類,Sleep-可睡眠類
參與者數量:NON-Sleep多個,Sleep類多個
競爭者:NON-Sleep類之間,Sleep類之間,NON-Sleep類和Sleep類之間
數據結構:
X-被鎖定實體
X.LOCK-自旋鎖,用於鎖定不可睡眠路徑以及保護標記鎖
X.FLAG-標記鎖,用來鎖定可睡眠路徑
X.sleeplist-等待獲得標記鎖的task隊列
NON-Sleep類的鎖定/解鎖邏輯:
spin_lock(X.LOCK);
if(X.FLAG == 1) {
//add something todo to backlog
delay_func(...);
} else {
//do it directly
direct_func(...);
}
spin_unlock(X.LOCK);
Sleep類的鎖定/解鎖邏輯:
spin_lock(X.LOCK);
do {
if (X.FLAG == 0) {
break;
}
for (;;) {
ready_to_wait(X.sleeplist);
spin_unlock(X.lock);
wait();
spin_lock(X.lock);
if (X.FLAG == 0) {
break;
}
}
} while(0);
X.FLAG = 1;
spin_unlock(X.LOCK);
do_something(...);
spin_lock(X.LOCK)
if (have_delayed_work) {
do {
fetch_delayed_work(...);
direct_func(...);
} while(have_delayed_work);
}
X.FLAG = 0;
wakeup(X.sleeplist);
spin_unlock(X.LOCK);
對於socket收包邏輯,其實就是將skb插入接收隊列並喚醒socket的睡眠隊列填充到上述的direct_func中即可,同時delay_func的任務就是將skb插入到backlog隊列。
該抽象出來的模型基本就是一個兩層鎖邏輯,自旋鎖在可睡眠路徑僅僅用來保護標記位,可睡眠路徑使用標記位來鎖定而不是使用自旋鎖本身,標記位的修改被自旋鎖保護,這個非常快的修改操作代替了慢速的業務邏輯處理路徑(比如socket收包...)的完全鎖定,這樣就大大減少了競態帶來的CPU時間的自旋開銷。近期我在實際的一個場景中就采用了這個模型,非常不錯,效果也真的還好,因此特意抽象出了上述的代碼。
引入這個兩層鎖解放了不可睡眠路徑的操作,使其在可睡眠路徑的task占有一個socket期間仍然可以將數據包排入到backlog隊列而不是等待可睡眠路徑task解鎖,然而有的時候可睡眠路徑上的邏輯也不是那麼慢,如果它不慢,甚至很快,鎖定時間很短,那麼是不是就可以直接跟不可睡眠路徑去爭搶自旋鎖了呢?這正是引入可睡眠路徑fast lock的契機。
接收路徑優化2:引入fast lock
進程/線程上下文中的socket處理邏輯在滿足下列情況的前提下可以直接與內核協議棧競爭該socket的自旋鎖:
a.處理臨界區非常小
b.當前沒有其它進程/線程上下文中的socket處理邏輯正在處理這個socket。
滿足以上條件的,說明這是一個單純的環境,競爭者地位對等。那麼很顯然的一個問題就是誰來處理backlog隊列的問題,這個問題其實不是問題,因為這種情況下backlog就用不到了,操作backlog必須持有自旋鎖,socket在fast lock期間也是持有自旋鎖的,兩個路徑完全互斥!因此上述條件a就極其重要,如果在臨界區內出現了大的延遲,會造成協議棧路徑過度自旋!新的fast lock框架如下:
Sleep類的fast鎖定/解鎖邏輯:
fast = 0;
spin_lock(X.LOCK)
do {
if (X.FLAG == 0) {
fast = 0;
break;
}
for (;;) {
ready_to_wait(X.sleeplist);
spin_unlock(X.LOCK);
wait();
spin_lock(X.LOCK);
if (X.FLAG == 0) {
break;
}
}
X.FLAG = 1;
spin_unlock(X.LOCK);
} while(0);
do_something_very_small(...);
do {
if (fast == 1) {
break;
}
spin_lock(X.LOCK);
if (have_delayed_work) {
do {
fetch_delayed_work(...);
direct_func(...);
} while(have_delayed_work);
}
X.FLAG = 0;
wakeup(X.sleeplist);
} while(0);
spin_unlock(X.LOCK);
之所以上述代碼那麼復雜而不是僅僅的spin_lock/spin_unlock,是因為如果X.FLAG為1,說明該socket已經在處理了,比如阻塞等待。
以上就是在協議棧/socket邊界上的異步流程的隊列和鎖的總體架構,總結一下,包含5個要素:
a=socket的接收隊列
b=socket的睡眠隊列
c=socket的backlog隊列
d=socket的自旋鎖
e=socket的占有標記
這5者之間執行以下的流程:
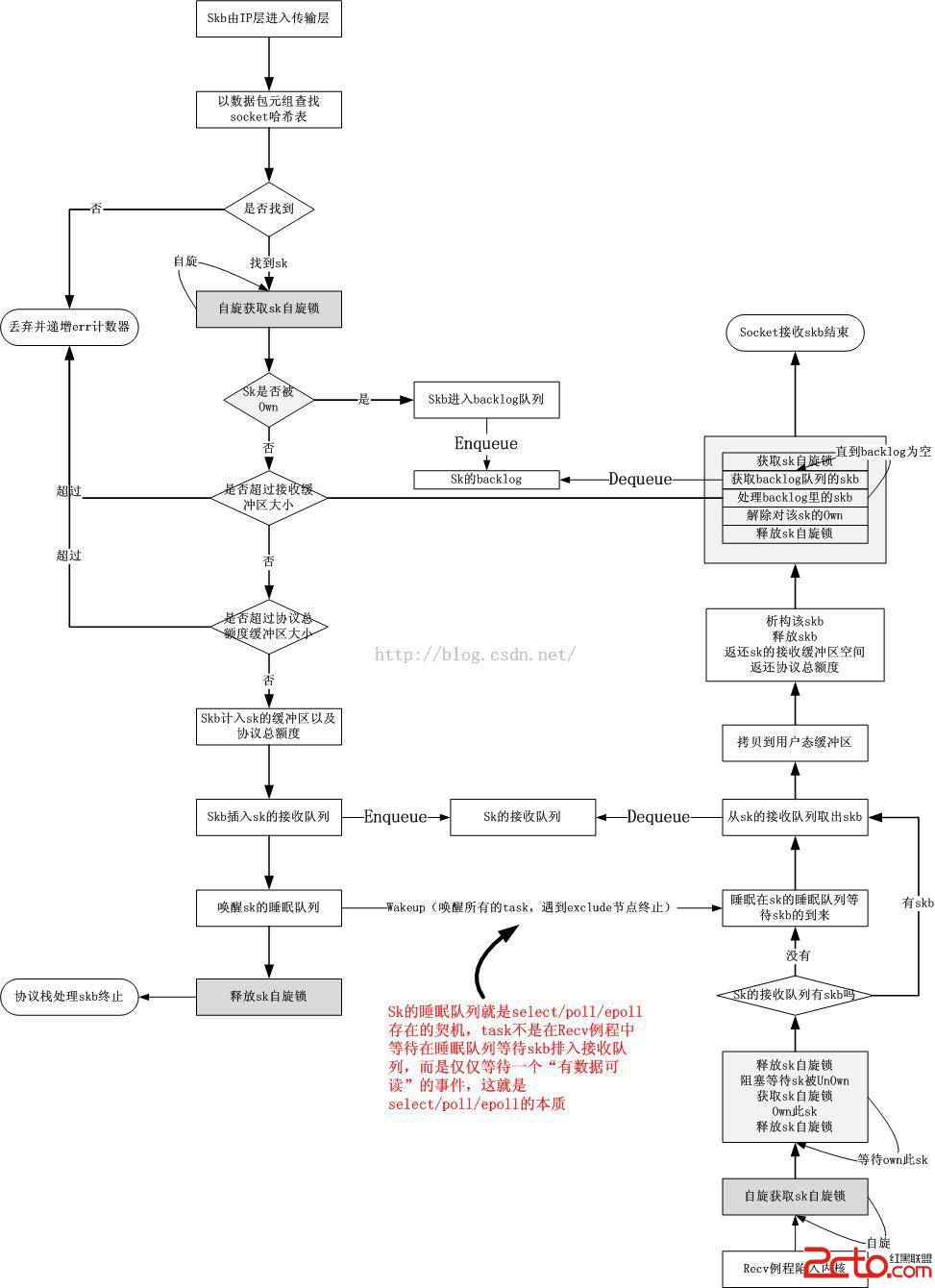
有了這個框架,協議棧和socket之間就可以安全異步地進行網絡數據的交接了,如果你仔細看,並且對Linux 2.6內核的wakeup機制有足夠的了解,且有一定的解耦合的思想,我想應該可以知道select/poll/epoll是怎樣一種工作機制了。關於這個我想在本文的第二部分描述,我覺得,只要對基礎概念有足夠的理解且可以融會貫通,很多東西都是可以僅僅靠想而推導出來的。
下面,我們可以在以上這個框架內讓skb參與進來了。
接力傳遞的skb
在Linux的協議棧實現中,skb表示一個數據包,一個skb可以屬於一個socket或者協議棧,但不能同時屬於兩者,一個skb屬於協議棧指的是它不和任何一個socket相關聯,它僅對協議棧本身負責,如果一個skb屬於一個socket,就意味著它已經和一個socket進行了綁定,所有的關於它的操作,都要由該socket負責。
Linux為skb提供了一個destructor析構回調函數,每當skb被賦予新的屬主的時候會調用前一個屬主的析構函數,並被指定一個新的析構函數,我們比較關注的是skb從協議棧到socket的這最後一棒,在將skb排入到socket接收隊列之前,會調用下面的函數:
static inline void skb_set_owner_r(struct sk_buff *skb, struct sock *sk)
{
skb_orphan(skb);
skb->sk = sk;
skb->destructor = sock_rfree;
atomic_add(skb->truesize, &sk->sk_rmem_alloc);
sk_mem_charge(sk, skb->truesize);
}
其中skb_orphan主要是回調了前一個屬主賦予該skb的析構函數,然後為其指定一個新的析構回調函數sock_rfree。在skb_set_owner_r調用完成後,該skb就正式進入socket的接收隊列了:
skb_set_owner_r(skb, sk);
/* Cache the SKB length before we tack it onto the receive
* queue. Once it is added it no longer belongs to us and
* may be freed by other threads of control pulling packets
* from the queue.
*/
skb_len = skb->len;
skb_queue_tail(&sk->sk_receive_queue, skb);
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_data_ready(sk, skb_len);
最後通過調用sk_data_ready來通知睡眠在socket睡眠隊列上的task數據已經被排入接收隊列,其實就是一個wakeup操作,然後協議棧就返回。很顯然,接下來關於該skb的所有處理均在進程/線程上下文中進行了,等到skb的數據被取出後,這個skb不會返回給協議棧,而是由進程/線程自行釋放,因此在其destructor回調函數sock_rfree中,主要做的就是把緩沖區空間還給系統,主要做兩件事:
1.該socket已分配的內存減去該skb占據的空間
sk->sk_rmem_alloc = sk->sk_rmem_alloc - skb->truesize;
2.該socket預分配的空間加上該skb占據的空間
sk->sk_forward_alloc = sk->sk_forward_alloc + skb->truesize;
協議數據包內存用量的統計和限制
內核協議棧僅僅是內核的一個子系統,且其數據來自本機之外,數據來源並不受控,很容易受到DDos攻擊,因此有必要限制一個協議的總體內存用量,比如所有的TCP連接只能用10M的內存這類,Linux內核起初僅僅針對TCP做統計,後來也加入了針對UDP的統計限制,在配置上體現為幾個sysctl參數:
net.ipv4.tcp_mem = 18978 25306 37956
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_mem = 18978 25306 37956
....
以上的每一項三個值中,含義如下:
第一個值mem[0]:表示正常值,凡是內存用量低於這個值時,都正常;
第二個值mem[1]:警告值,凡是高於這個值,就要著手緊縮方案了;
第三個值mem[2]:不可逾越的界限,高於這個值,說明內存使用已經超限了,數據要丟棄了。
注意,這些配置值是針對單獨協議的,而sockopt中配置的recvbuff配置的是針對單獨一條連接的緩沖區大小限制,兩者是不同的。內核在處理這個協議限額的時候,為了避免頻繁檢測,采用了預分配機制,第一次即便只是來了一個1byte的包,也會為其透支一個頁面的內存限額,這裡並沒有實際進行內存分配,因為實際的內存分配在skb生成以及IP分片重組的時候就已經確定了,這裡只是將這些值累加起來,檢測一下是否超過限額而已,因此這裡的邏輯僅僅是一個加減乘除的過程,除了計算過程消耗的CPU之外,並沒有消耗其它的機器資源。
計算方法如下
proto.memory_allocated:每一個協議一個,表示當前該協議在內核socket緩沖區裡面一共已經使用了多少內存存放skb;
sk.sk_forward_alloc:每一個socket一個,表示當前預分配給該socket的內存剩余用量,可以用來存放skb;
skb.truesize:該skb結構體本身的大小以及其數據大小的總和;
skb即將進入socket的接收隊列前夕的累加例程:
ok = 0;
if (skb.truesize < sk.sk_forward_alloc) {
ok = 1;
goto addload;
}
pages = how_many_pages(skb.truesize);
tmp = atomic_add(proto.memory_allocated, pages*page_size);
if (tmp < mem[0]) {
ok = 1;
正常;
}
if (tmp > mem[1]) {
ok = 2;
吃緊;
}
if (tmp > mem[2]) {
超限;
}
if (ok == 2) {
if (do_something(proto)) {
ok = 1;
}
}
addload:
if (ok == 1) {
sk.sk_forward_alloc = sk.sk_forward_alloc - skb.truesize;
proto.memory_allocated = tmp;
} else {
drop skb;
}
skb被socket釋放時調用析構函數時期的sk.sk_forward_alloc延展:
sk.sk_forward_alloc = sk.sk_forward_alloc + skb.truesize;
協議緩沖區回收時期(會在釋放skb或者過期刪除skb時調用):
if (sk.sk_forward_alloc > page_size) {
pages = sk.sk_forward_alloc調整到整頁面數;
prot.memory_allocated = prot.memory_allocated - pages*page_size;
}
這個邏輯可以在sk_rmem_schedule等sk_mem_XXX函數中看個究竟。
本文的第一部分到此已經結束,第二部分將著重描述select,poll,epoll的邏輯。


