1.O(1)調度器的時間計算公式與CFS調度器
Linux 2.6.23之前普遍采用了O(1)調度器,它是一種基於優先級的時間片調度算法,所謂的O(1)只是它的一些精巧的數據結構使然,在不考慮動態補償/懲罰的情況下,只要優先級確定,那麼時間片就是固定的。2.6.23以後的CFS呢,它是一種基於權重的非時間片調度算法,進程每次執行的時間並不是固定的,而是根據進程數在一個准固定周期內按照其權重比例的時間,依然以時間片為術語,CFS下,進程每次運行的時間與進程的總量有關。
即便在不考慮動態補償/懲罰的前提下,O(1)依然面臨雙斜率問題,為了解釋這個問題,我先給出進程優先級公式:
prio=MAX_RT_PRIO+nice+20
其中,MAX_RT_PRIO為100,nice為-20到19閉區間內的任意整數。接下來時間片的計算體現了雙斜率:
如果prio小於120:time_slice=20*(140-prio)
如果prio大於等於120:time_slice=5*(140-prio)
可見,只要prio確定了,每個進程的時間片也就確定了,以120為分界,高優先級與低優先級的時間片計算是不同的,之所以這樣是為了:既要體現高優先級的優勢,又不過於削弱低優先級。通過O(1)的邏輯,我們可以算出,所有進程必須完成一輪的調度,即每一個進程必須有機會運行一次,因此“一輪調度”的時間隨著進程數量的增加是增加了的。
我們現在看看CFS是怎麼逆轉這個結局的。CFS調度非常簡單,沒有太多的計算公式。依然不考慮動態補償/懲罰,CFS完全按照權重,Linux內核將40個優先級映射了40個權重,為了簡化討論,我假設權重分別為1,1*1.2,1*1.2*1.2,1*1.2*1.2*1.2,....以1.2倍等比例增加,然後定義一個固定的調度周期或以任意一段時間slice內,一個進程運行的時間就是slice*(進程權重/權重和),可見,如果進程數量增加,所有的進程集體平滑變慢,意思是每次運行的時間減少(時間片不再固定),所謂的“完全公平”意味著權值大的進程其虛擬時鐘步進比較慢,權值小的進程其虛擬時鐘步進比較快,CFS在每一個調度點(比如時鐘tick,wake up,fork等)選擇虛擬時鐘最小的進程運行,這是相對於O(1)來講更加平滑的一種方式,因此體現了一種延遲公平,至於吞吐,還是按照權重來的,而權重映射到了優先級。而O(1)更多的是吞吐公平。
總結來講,就是O(1)為每個進程計算固定的時間片,而CFS則是在相同的時間段內計算每個進程運行的時間比例,可見二者基點不同,甚至是完全相反的。
現在,我們給出評價。CFS更加平滑,非常適合交互式進程,因為交互進程是饑餓敏感的,但是它們不經常占有CPU,然而一旦需要CPU,必須馬上讓其予取予求。對於有高吞吐需求的服務進程,CFS並不適合,這種進程的需求是一旦占據CPU,則盡可能讓其運行久一些,固定時間片的O(1)更加適合。按照慣常的分類法,I/O密集型的進程多屬於交互(可能還有存儲類)的,這種進程由I/O驅動,應該滿足其任何時刻的CPU需求,因為它們不會占據太久,然而對於CPU密集型進程,得到CPU的機會應該比I/O密集應用少,因為它們一旦獲得CPU,就要長期占據。總的來講,對於桌面客戶端,CFS更適合,對於服務器,O(1)更加適合。
本文沒有談及另外兩種調度器,也就是Windows調度器以及Linux BFS調度器,前者基於動態優先級提升/恢復,適合桌面應用,後者基於優先級分類O(n)算法,不考慮眾核和NUMA擴展,更適合移動終端。
2.缺頁中斷的Major和Other
所有進程的虛擬地址空間共享一個限量的物理內存,勢必需要按需調頁,這種做法之所以可行是因為每一個時間點,CPU們只需要少量的物理頁面獲得映射。現在的問題是,考慮如果出現缺頁-頁表項中的“存在位”為0,從哪裡獲得新的page。答案很簡單,當然是從代價最小的地方獲取page。
我們此時必須考慮缺頁時所需page的類型,大致可以分為3類:
1).完全的地址缺頁,即該地址曾經沒有映射過物理頁面。
2).該地址曾經映射過頁面,但是被換出到交換空間了。
3).該地址曾經映射的page屬於一個文件系統的文件,但是已經解除了映射。
針對以上3種情況,所謂的“代價最小”擁有不同的策略。
首先看1),這個很簡單,直接從伙伴系統分配page即可,當然分配單獨一個page所付出的代價相當小,因為伙伴系統之上有一個per cpu的page pool,這個pool的分配不需要任何lock。現在我們看看這個代價小是否足夠小,看來是的,但是並不絕對。對於讀操作來講,假設之前有一個page映射於該缺頁虛擬地址,後來解除了映射,我們知道此時該page的部分數據已經cache到了CPU cache line中,當再次需要讀該page但是缺頁時,我們希望獲得原先的那個page,願景是好的,可是我們怎麼追蹤這個page呢?追蹤這個page和缺頁進程的關系的代價是否抵消保持cache熱度的收益呢?事實上,這很難,因為你要考慮到共享內存的情況,這是一個多對一的雙向關系,也就是一個多對多的關系。然而Linux的內存子系統並沒有什麼都不做,而是它基於一種概率行為將釋放到per cpu的page pool的行為分為了cold release和hot release,hot release將page添加到pool的隊頭,反之到隊尾,而per cpu page pool的分配行為是隊頭分配,如果足夠幸運,也許進程可以獲得剛剛被解除映射的那個做過讀操作的page。內核是怎麼保證一個進程是足夠幸運的呢?這個很形而上但卻也實用,內核采用了一個准LRU算法防止了page在進程之間顛簸,局部性保證了在進程內部一個page被訪問後的一段時間內再被訪問的幾率很大。
再看2),內核裡面運行著一個page回收交換的守護內核線程,發現一個不常被訪問要被回收的page是髒page時,內核線程並不是直接啟動IO將其寫入交換空間,而是暫時先將其排入一個swap cache,也就是給了一個page一次不需要IO而被再次使用的機會,做這樣的策略其背後還是局部性原理。當缺頁發生時,首先會在swap cache裡面尋找,如果找到就不需要進行IO了。做這個策略的現實意義是巨大的,在分級存儲原理我們可以知道,內存訪問和磁盤IO的時間差了幾個數量級,所以不到必須要做,是不會刷swap cache到swap分區的。
最後我們看3),和2)類似,但是這個涉及到了filesystem的文件page cache,由radix樹組織,這個樹和page回收是無關的,所謂刷掉一個屬於文件的page指的是僅僅將該page解除頁表項映射,實際上它完全可能還在文件的radix樹中,在發生缺頁的時候,如果在radix樹中找到了該page,那麼只需建立一個映射即可,無需再進行磁盤IO。
綜上,我們可以知道,只要不進行磁盤IO就盡量不要,只要不進行磁盤IO的缺頁處理就是Minor,進行了IO的則是Major,一個名稱而已。如今的內核將Minor進行了細分,但是這並不是重點,因此統一稱為Other。
在此不得不提的是LRU算法,一般而言,幾乎所有的操作系統都采用了准LRU而不是標准的LRU,這是因為標准LRU只是理論上的,實際實現起來不現實,並不是說硬件消耗巨大,更多是因為“它的效果並不比准LRU好甚至更糟糕”,標准的LRU是一個棧式管理系統,空間局部性誠然重要,然而考慮到循環的話,在循環邊界將會面對空間局部性的對立極端,這就是列維長跳!!列維短跳是符合空間局部性的,但是列維長跳是空間局部性的對立。順便說一句,整個人類社會的任何行為都符合列維長跳原則,如果把量變看做列維短跳,那麼質變就是列維長跳,這是根本原則,馬克思說過的。
Linux內核采用雙時鐘二次機會算法模擬了LRU算法,效果非常好。
3.進程地址空間的非線性映射與工作集
Linux內核采用vma來表示進程地址空間中的一段,至於這一段映射了什麼vma自己管理,對上層只是提供地址空間的一段連續的虛擬內存。
一般而言,一個文件的一部分對應一個vma,如果需要映射一個文件的不同部分,就需要不同的vma,如果足夠幸運,這幾個vma可以緊緊挨在一起,但是在兩次映射之間,一些別的映射占據了hole,那麼就不好玩了,因此需要一種針對文件“重新布局”的方式,下面的圖示展示了這個想法:
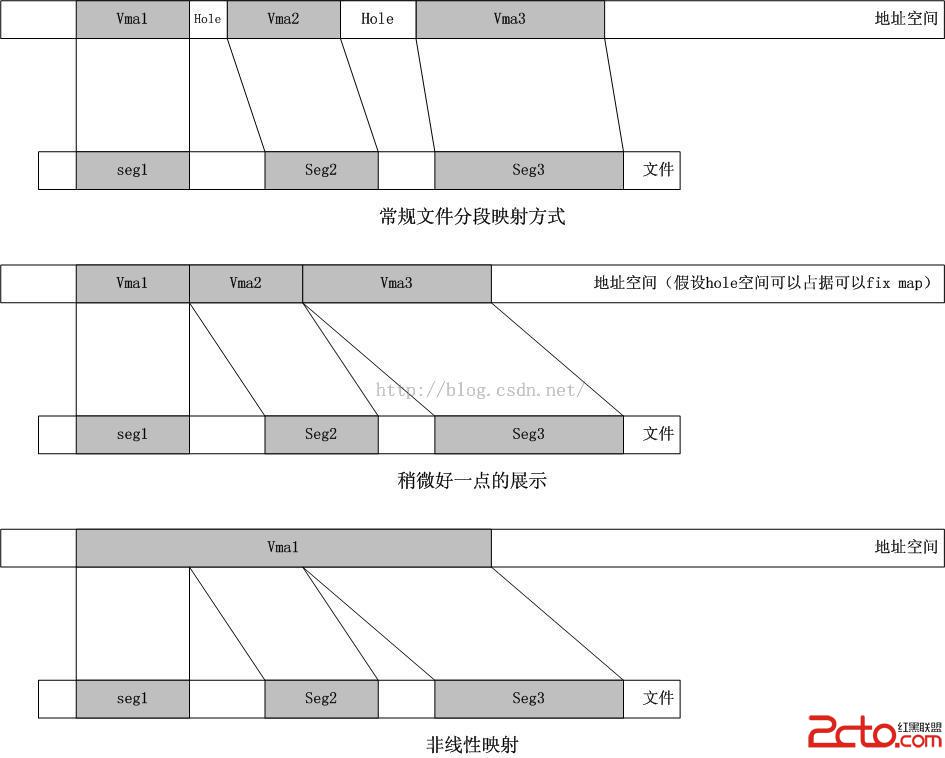
但是僅僅針對文件做這個解釋難免有點不盡興。操作系統中有一個工作集的概念,這個概念也是依托局部性原理。工作集就是將不同的內容映射到一個固定的虛擬地址空間窗口,如果CPU的cache line是依據虛擬地址尋址的,那麼時間空間局部性將會發揮很大的作用,在這個過程中,TLB也會發揮作用。基於虛擬地址的工作集是虛擬地址空間和物理內存之間的真正隔離。
本質上來講,非線性映射並不一定要針對文件,它要做的就是“將不同的內容映射到相同的虛擬地址區段”。


