0.聲明:
0).關於來源
昨天就答應皮鞋廠老板了,只是昨晚心情太復雜,本文沒有趕出來,今天在飛機上寫下了剩余的...
1).關於Linux原生代碼
本文假設讀者已經對Linux的TCP實現源碼有了足夠清晰的理解,因此不會大量篇幅分析Linux內核關於TCP的源代碼,比如tcp_v4_rcv的流程之類的。
2).關於我的優化代碼
由於涉及到很多復雜的因素,本文不提供完整的可編譯的優化源碼(整個源碼並非我一人完成,在未經同伙同意之前,我不敢擅作主張,但是想法是我的,所以我能展示的只是原理以及我負責的那部分代碼)。
3).關於TCP協議
本文不談TCP協議本身以及其細節(細節請參考RFC以及各類論文,比如各種流控,擁控算法之類的),僅包含的內容是TCP協議之外的框架實現的優化。
1.Linux的TCP實現
1.1.Linux的TCP實現在協議層面分為兩個部分
1).連接握手處理
TCP首先會通過三次握手建立一個連接,然後就可以傳輸數據了。TCP規范並沒有指定任何的實現方式,當前的socket規范只是其中一種而已。Linux實現了BSD socket規范。
在Linux中,TCP的連接處理和數據傳輸處理在代碼層面是合並在一起的。
2).數據傳輸處理
這個比較簡單,略。
1.2.Linux的TCP在系統架構方面分為兩個部分
1).軟中斷協議棧處理
Linux內核在軟中斷環境中進行協議棧的處理,在這個處理流程的最上方,會有3個分支:直接將skb復制到用戶緩沖區,簡單將skb排入到prequeue隊列,簡單將skb排入backlog隊列。
2).用戶進程處理
Linux的socket API的處理是在用戶進程上下文中進行的。通過1.1節,我們知道由於代碼層面上這些都是合並在一起的,因此一個socket會被各種執行流操作,直觀的考慮,這需要大量鎖的開銷。
1.3.連接處理的總體框圖
我給出一個連接處理總體框圖,其中紅線表示發生競爭的地方,而正是這些地方阻止了TCP連接的並行處理,圖示如下:
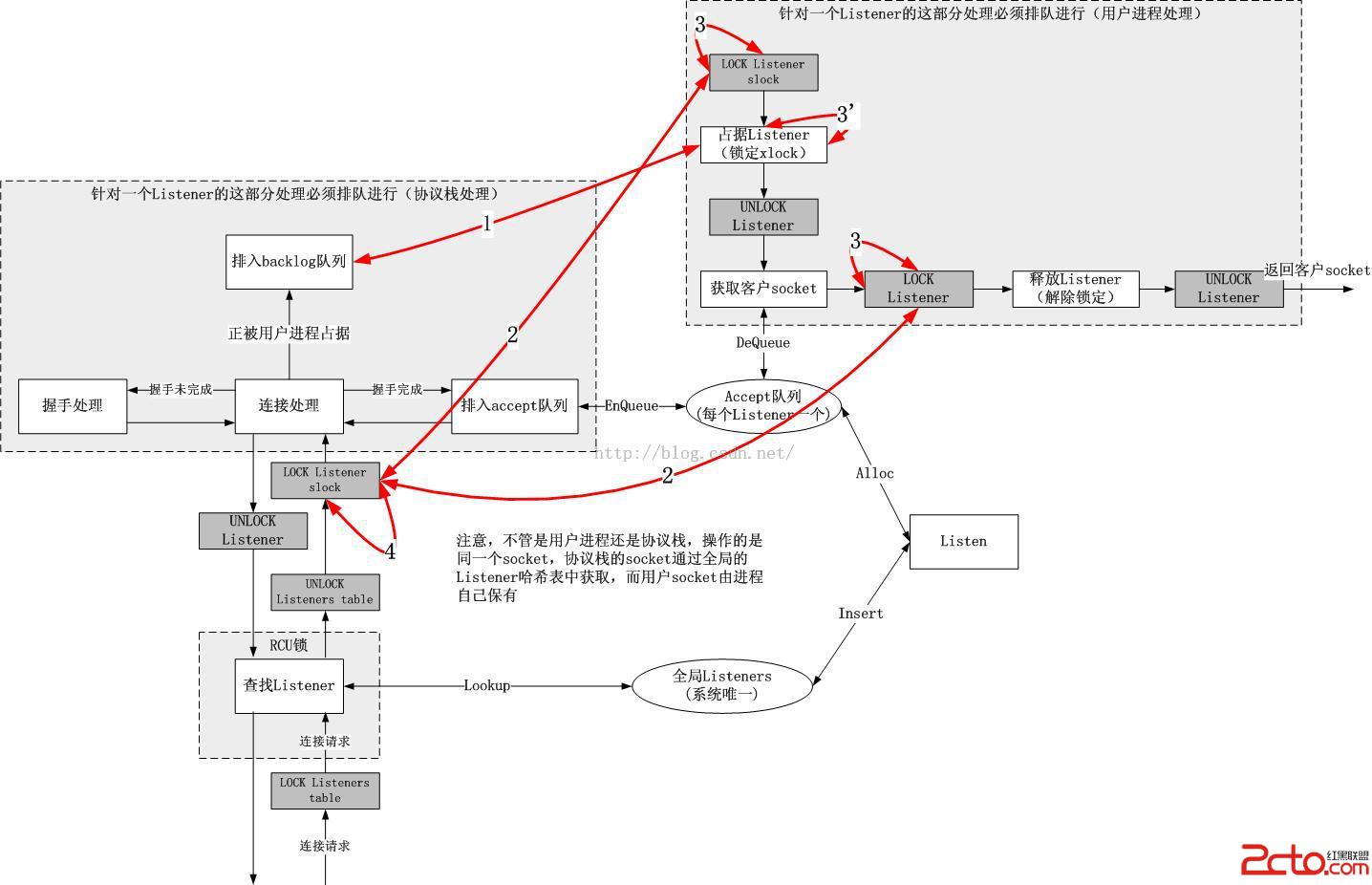
我來一一解釋這些紅線的意義:
1號紅線:
由於用戶進程和協議棧操作的是同一個socket,如果用戶進程正在copy數據包數據,那麼協議棧就要停止同樣的操作,反過來也一樣,因此需要暫時鎖定該socket,然而這種大鎖的開銷過於大,因此Linux內核協議棧的實現采用了一個更加優雅的方式。
協議棧鎖定socket:由於軟中斷處理協議棧,它可能運行在硬中斷之後的任意上下文,因此不能睡眠,故而必須是一把自旋鎖slock,由socket本身保有,該鎖不僅僅保護和用戶進程之間的競態,也保護不同CPU上對同一個socket協議棧操作之間的競態(很常見,一個偵聽socket上可以同時到達很多連接請求[可悲的是,這些請求不能同時被處理!!])。
用戶進程鎖定socket:用戶進程是可以隨時睡眠的,因此可以采用非自旋鎖xlock來保護多個進程之間的競態,然而同時又為了和內核協議棧操作同一個socket的軟中斷互斥,因此在獲取xlock之前,首先要獲取該socket的slock,當獲取xlock之後或者暫時沒有獲得xlock要睡眠的時候,將slock釋放掉。相關的邏輯如下:
stack_process
{
...
spin_lock(socket->slock); //1
process(skb);
spin_unlock(socket->slock);
...
}
user_process
{
...
spin_lock(socket->slock); //2
while(true)
{
...
spin_unlock(socket->slock);
睡眠;
spin_lock(socket->slock); //2
if (占據xlock成功)
{
break;
}
}
spin_unlock(socket->slock);
...
}
可見,Linux采用了以上的方式很完美的解決了兩類問題,第一類問題是操作socket的執行流之間的同步與互斥,第二類問題時軟中斷上下文和進程上下文之間的鎖的不同。
在理解了socket鎖定之後,我們來看下backlog這個隊列是干什麼的。其實很簡單,就是將skb推到當前正占據socket的那個進程的一個隊列裡面,等到進程完成任務,准備釋放socket占有權的時候,如果發現該隊列裡面有skb,那麼在其上下文中處理它們。這實際上是一種職責轉移,這個轉移也可以帶來一些優化效果,那就是直接在socket所屬的用戶進程上下文處理skb,這樣就避免了一部分cache刷新。
2號紅線:
這條線在1號紅線的解釋中已經涉及了,主要就是上述代碼邏輯中的1和2之間的競爭。這個競爭不是最激烈的,本質上它們屬於縱向的競爭,一個內核態軟中斷和一個進程上下文之間的競爭,在同一個CPU上,一般而言,這類競爭的概率很低,因為同一個CPU同時只能執行一個執行流,假設此時它在內核態執行軟中斷,那麼用戶態的進程,它一定在睡眠或者被搶占,比如在accept中睡眠。
用戶態處理和內核態處理,這種縱向的競爭在單CPU上幾乎不會發生,而用戶態的xlock根本就是為了解決用戶進程之間的競爭,內核通過一個backlog在面對這種競爭時轉移了數據包處理職責,事實上在xlock上並不存在競爭,backlog的存在反而帶來了一點優化效果。
3號紅線(結合3'號紅線):
該紅線為了解決多個用戶進程之間的競爭。之所以畫出的是TCP連接處理圖而不是數據傳輸處理圖,是因為連接圖更能體現問題,在服務器端,一個主進程fork出來N多的子進程或者創建多個線程同時在一個繼承下來的socket上accept,這幾乎成了服務器設計的准則,那麼這多個進程/線程同時到達這個slock的時候,爭搶就會很激烈。再看3'號紅線,我們發現針對同一個socket的accept必須排隊進行。
如果你看Linux TCP的實現,你會發現大量的數據結構操作都沒有用鎖,事實上,進入到那裡的,只有你一人,早在入口就排隊了。
在單CPU上,這不會產生什麼後果,因為單CPU即便在最先進的分時搶占調度器的協調下,本質上也是一個排隊模型,充其量可以插隊罷了,TCP實現的slock和xlock只是規范了這個排隊規則而已。然而在多CPU上,仔細想想這有必要嗎?
4號紅線:
說完了用戶態多個進程/線程同時在同一個socket上accept時的排隊,現在看看內核協議棧的處理,也好不到哪裡去。如果多個CPU同時被連接請求中斷,大量的請求針對同一個偵聽socket,那麼大家就要在4號紅線處排隊!而這個情況在單CPU時幾乎並不存在,根本不可能同時有多個CPU執行到同一個地點...
2.多核CPU架構下Linux TCP連接處理性能瓶頸
通過以上針對幾條紅線的描述,到此為止,我已經展示了幾個瓶頸,這些點都是要排隊的點。以上的那個框圖事實上非常好,這些排隊點也無可厚非,因為設計一個系統,就是要自包容解決所有問題,競爭只要存在,就一定要通過排隊來解決它,因此上述的框架根本不用更改,鎖還是留在原處。問題的根本不是鎖的存在,問題的根本在於鎖的不易獲取!
TCP的處理運行在各個CPU上,CPU被當作了一種資源,這是操作系統的核心概念,但是反過來呢?如果把CPU當成服務者本身,而socket當成資源,問題就迎刃而解了。這個思路很重要,我在nf-HiPAC中第一次接觸到了它,原來可以把match和rule顛倒過來玩,然後以這個思想做指導我設計了DxR Pro++,現在還是這個思想,TCP的優化依然可以這麼做。
3.Linux TCP連接處理優化
整體考慮一種連接處理被優化後的TCP實現,我只關心從accept API中會返回什麼。只要我能快速獲取一個客戶socket,並且不破壞listen,bind這些API本身,修改其實現是必須的。
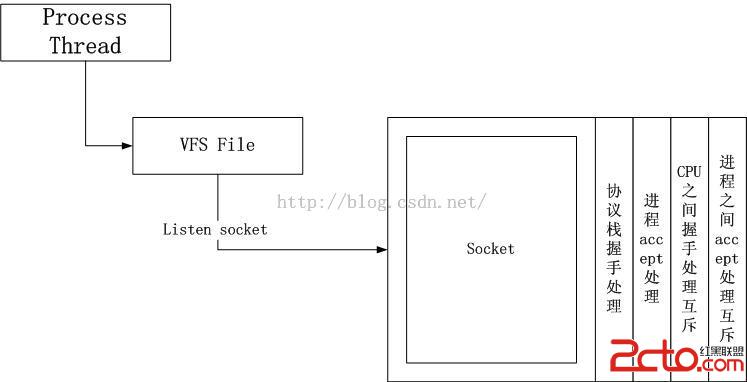
3.1.縱向拆分socket
我將一個listen socket拆分成了兩個部分,上半部和下半部,上半部對應用戶進程,下半部對應內核協議棧。原始的socket是下圖的樣子:
我的socket被改成了下面的樣子:
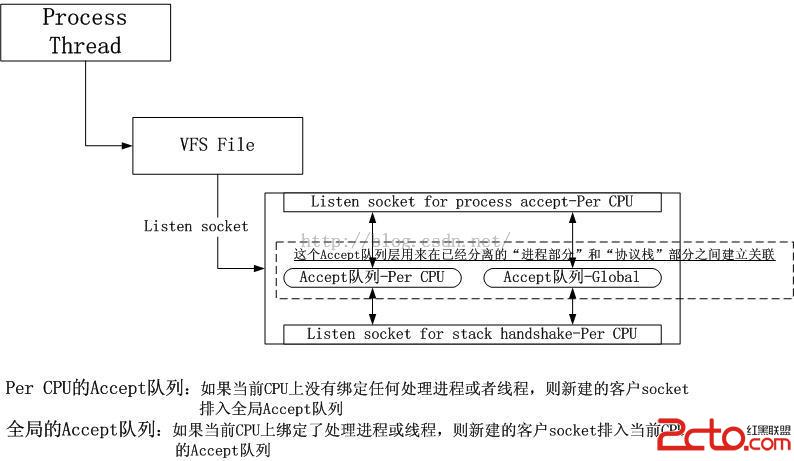
3.1.1.消解1號紅線和2號紅線
一個socket的上半部和下半部只通過一個accept隊列關聯,事實上即使在上半部正在占有socket的時候,下半部依然可以繼續處理。
然而,事實證明,在執行accept的進程綁定CPU的情況下,1號紅線的消解並沒有預期的性能提升,而2號紅線的消解帶來的性能提升影響也不大。如果是不綁定CPU,性能提升反而比綁定更好,看來橫向和縱向並不是獨立的兩塊,它們會相互影響。
3.2.橫向拆分socket
橫向拆分的思路就是將一個socket下半部拆成多個,每一個CPU上強制綁定一個,類似softirqd每一個CPU上一個一樣,這樣可以消解4號紅線。但是為何不拆解socket的上半部呢?我一開始的想法是讓進程自行決定,後來覺得同樣也要強行綁定一個,至於說什麼用戶進程可以自行解除綁定之類的,加一個層次隱藏掉Per CPU socket即可。此時的用戶進程中的文件描述符只是指示一個socket描述符,而該描述符真正指向的是nr_cpus個Per CPU socket,如下圖所示:
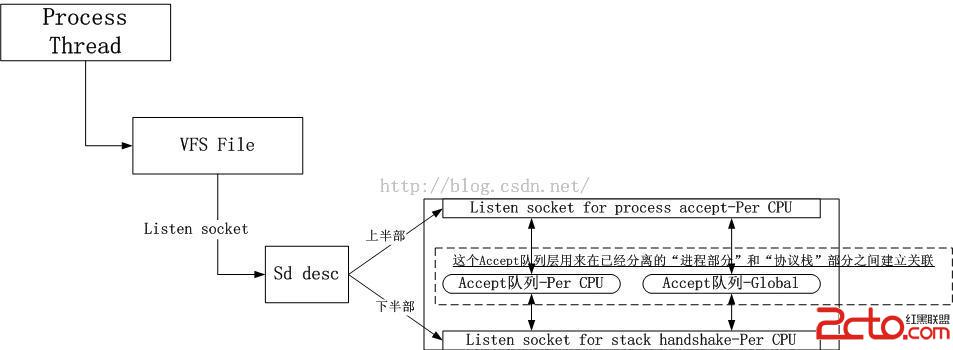
這樣3號紅線,3'號紅線,4號紅線全部消解。事實上,看到這裡好像一切都大功告成了,但是測試的時候,發現還有兩個問題,接下來我會在描述數據結構的拆解中描述這兩個問題。
3.3.全局Listeners哈希表
由於Listener會復制nr_cpus份到每一個CPU上,故而所有的Listeners會被加入到每一個CPU的本地哈希表中,這種以空間換無鎖並行是值得的,因為服務器上並不會出現海量的偵聽服務。
3.4.本地Accept隊列和全局Accept隊列
如果系統中每一個CPU上都綁定有accept進程,那麼可以保證所有的連接請求都會被特定的進程處理,然而如果有一個CPU上沒有綁定任何accept進程,那麼被排隊到該CPU的Accept隊列的客戶socket將不會返回給任何進程,從而造成客戶socket餓死。
因此引入一個全局Accept隊列。相關的代碼邏輯如下:
stack_enqueue_socket
{
if (本CPU上沒有綁定任何與該Listener相關的用戶進程) {
spin_lock(g_table->slock);
enqueue_global(g_table, cli_socket);
spin_unlock(g_table->slock);
} else {
local_irq_save
enqueue_local(per_cpu(table), cli_socket);
local_irq_restore
}
}
user_dequeue_socket_for_accept
{
if (當前進程沒有綁定到當前CPU) {
spin_lock(g_table->slock);
cli_socket = dequeue_global(g_table);
spin_unlock(g_table->slock);
} else {
local_irq_save
cli_socket = dequeue_local(per_cpu(table));
local_irq_restore
}
return cli_socket;
}
事實上,可以看到,全局的Accept隊列是專門為那些頑固不化的進程設置的,但是還是可以以一把小鎖的代價換來性能提升,因為鎖的粒度小多了。
3.5.軟中斷CPU分發問題
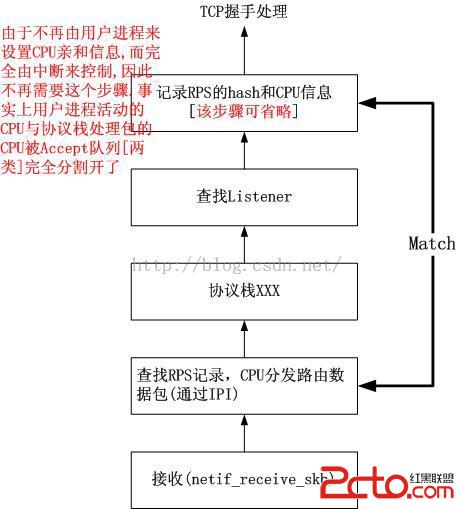
由於每一個CPU上綁定了一個Listener socket的下半部,並且幾乎所有的數據結構都是本地維護的,CPU正式成了TCP的一部分。因此必須保證一件事,那就是3次握手必須由一個CPU處理,否則就會出錯。而由於如今很多啟動了irqbalance的系統,中斷可能會分發到不同的CPU,比如來自特定客戶端的SYN被CPU0處理,而3次握手中的ACK則被CPU1處理,這就造成了錯誤。為了避免這個局面,底層必須維護數據流和CPU之間的映射。這個可以通過RFS的技術來解決。
當第一個SYN包到達之時,處理這個連接握手過程的CPU就確定了,就是當前的CPU,這個和用戶態的進程“跳”到哪個CPU上沒有任何關系。因此實現比RFS要簡單得多。代碼邏輯如下:
netif_receive_skb
{
...
hash = myhash(skb)
cpu = get_hash_cpu(hash);
if (cpu == -1)
{
record_cpu_hash(hash, cpu);
} else if (current_cpu != cpu)
{
enqueue_to_backlog(skb, cpu);
此後由IPI觸發中斷,被別的CPU處理
} else
{
正常的接收邏輯
}
...
}
示意圖如下:
3.6.與REUSEPORT以及fastsocket的關系
我的這個優化版本和REUSEPORT沒有任何關系,REUSEPORT是google的一個patch,非常好用,在我們的一個產品中就用到了這個技術,它可以做到在多個偵聽相同IP地址和端口的不同socket之間做到負載均衡,然而這個負載均衡的效果則完全取決於hash算法。事實上Sina的fastsocket就是在REUSEPORT之上做的優化,其主要做了CPU Affinity方面的優化,效果很不錯。相似的優化還有RPS/RFS patch,然而fastsocket更進一步,它不光延續了RPS/RFS的成果,而且把連接性能瓶頸也解決了,其主要的做法就是采用CPU綁定技術對一個Listen socket在REUSEPORT的基礎上做了橫向拆分,復制了多個Listen socket來reuseport。
fastsocket的做法是用戶進程自己決定是否要綁定CPU,因此哪個CPU處理哪些數據包是通過用戶進程設置的,而我的做法則正好相反,我的優化從下到上,我是由第一個SYN包恰好中斷的那個CPU作為其握手過程後續被處理的CPU,和用戶進程的設置無關,即便用戶進程沒有綁定CPU,它也充其量只是從全局Accept隊列小代價取客戶socket而已,而如果綁定了CPU,那幾乎是全線無鎖操作。結合3.5小節,我們看下fastsocket是怎麼獲得對應處理該數據包的CPU的:
netif_receive_skb
{
...
socket = inet_lookup(skb);
cpu = socket->sk_affinity;
if (current_cpu != cpu)
{
enqueue_to_backlog(skb, cpu);
此後由IPI觸發中斷,被別的CPU處理
} else
{
正常的接收邏輯
}
...
}
fastsocket有一個查socket表的操作,如果是連接處理,對於綁定CPU的socket,可以在本地表中獲取到。如果你覺得fastsocket在這裡平添了一次查找,那你就錯了,事實上這是fastsocket的另一個優化點,即Direct TCP,也就是說在這個位置就查找具體的socket,連路由之類的都放進去,後續的所有查找結果都可以放入,也就可以實現一次查找,多次使用了。
Direct TCP的處理看似不符合協議棧分層處理的規則,在如此的底層處理四層協議,事實上在某些情況也會因此而付出性能代價:
1).如果有大量的包是轉發的呢?
2).如果有大量的包是UDP的呢?
3).如果是攻擊包呢?
4).如果這些包是接下來要被Netfilter刷掉的呢?
...
這有點像另一個類似的Direct技術,即socket的busy poll。想獲得甚高的性能,你必須對你的系統的行為足夠理解,比如你知道這台服務器就是專門處理TCP代理請求的,那麼開啟Direct TCP或者busy poll就是有好處的。
而我認為我的這個優化方案是一個更加通用的方案,實際上只有單點微調,且不會涉及別的情況,只要你能保證數據包到達的中斷行為是優雅的,後面的處理都是水到渠成的,完全自動化。就算是面對了上述4種非正常數據包,一個hash計算的代價也很小,且不需要面臨RCU鎖的內存屏障導致的刷流水問題。現如今,隨著多隊列網卡以及PCI-E MSI的出現和流行,有很多技術可以保證:
1).同一個元組標識的流的數據包到達後總是中斷同一個CPU;
2).處理不同的流的CPU上的負載非常均衡。
只要做到以上2點,其它的事情就不用管了,對於TCP的連接包,數據包會在同一個CPU一路向上一路無鎖到達本地Accept隊列或者全局Accept隊列,接下來會轉向另外一條同樣寬擁有同樣多車道的高速公路,這條新的公路由進程操縱。
最終,優化過的TCP連接處理框圖如下:
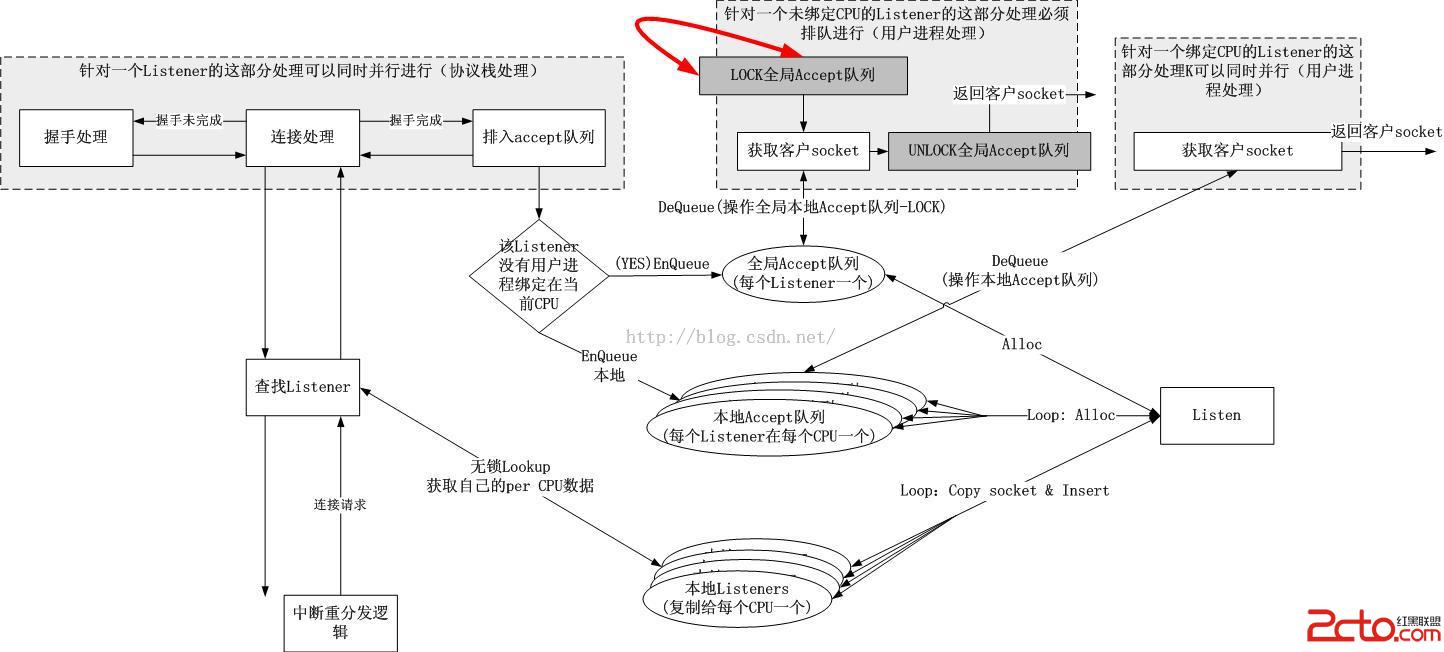
PS:我的這個方案不需要修改應用程序,也無須鏈接任何庫,完全替換內核即可。目前對fastopen並不支持。
對於TCP的非握手包的處理,應該怎麼優化呢?
4.Linux TCP數據處理優化
以前,我們以為TCP典型的C/S處理的服務端是一個一對多的模型,因此listen+accept+fork這種流行的socket編程模型幾乎一致持續到現在。期間衍生出各種MPM技術。這種模型本身就讓人覺得TCP的連接處理就是那個樣子,本身就有一個瓶頸在那裡!事實上,不管是fastsocket,還是我的這個方案,都解決了一對多問題,模型成了多對多的。
那麼對於TCP的數據傳輸處理,它該怎麼優化呢?要知道,它可不是一對多的模型,它是一個天然的一對一的模型,而TCP又是一個嚴格按序的協議,為了保序,采用並行化處理是一個愚蠢的想法。為了優化它,我們先給出可能的瓶頸在哪裡。
4.1.一對一TCP連接的瓶頸分析
由於TCP連接中會有大量的數據傳輸,因此內存拷貝是一個瓶頸,然而本文不關注這個,這個可以通過各種技術解決,比如DMA,零拷貝,分散/聚集IO等,本文關注的是CPU親和力的優化。另外,考慮到這種ESTABLISHED狀態的一對一連接的數量還有對其的操作。
考慮持續到來的短連接,大量的並發,我們來看下內核中ESTABLISHED哈希表的壓力
1).持續的新建連接(握手完成,客戶socket會插入表中),鎖表,排隊;
2).持續的連接釋放,鎖表,排隊;
3).大量的連接同時存在,大量的TIME_WAIT,查詢延遲且連累正常連接;
4).TIME_WAIT socket也面臨持續新建,釋放的問題。
...
如果是長連接,可能會緩解,但病根不除,不絕後患。
由於這個是一對一的對稱模型,TCP的按序性不好做並行化本地操作,因此我也就沒有對其進行橫向拆分,沒了橫向拆分,對於縱向拆分也就沒有了意義,因為勢必會出現多個CPU對隊列的爭搶問題。因此與連接處理的優化原則完全不同。
4.2.優化一對一TCP連接數據傳輸處理部分
如何優化?目標已經很明確,那就是本地化查詢,本地化插入/刪除,盡量減少RCU的內存屏障的影響。
和連接處理不同,我們沒法把CPU當成主角,因為一條連接的處理同一個時刻只能在一個CPU上。因此為了加速處理並且維護cache,建立兩條原則:
1).增加一個ESTABLISHED表的本地cache,該cache可以無鎖操作;
2).在用戶進程等待數據期間,禁止進程遷移。
我的邏輯如下,事實證明真的不錯:
tcp_user_receive/poll
{
0.例行RPS操作
1.設置進程為不可遷移
disable中斷
2.將socket加入當前CPU的本地ESTABLISHED表 (優化點1:如果本地表沒有才加入)
enable中斷
3.sleep_wait_for_data_or_event
4.讀取數據
disable中斷
5.將socket從本地ESTABLISHED表中摘除 (優化點1:不需要摘除)
enable中斷
6.清除不可遷移位
}
tcp_stack_receive
{
1.例行tcp_v4_rcv的操作
2.查找當前CPU的本地ESTABLISHED表
沒有找到的情況下,查找系統全局的ESTABLISHED表
3.例行tcp_v4_rcv的操作
}
很顯然,上述的邏輯基於以下的判斷:既然進程已經在一個CPU上等待數據了,最好的方式就是將這個進程暫時釘死在這個CPU上,並且告知內核協議棧,將軟中斷上來的數據包交給這個CPU。釘死這個進程是暫時的,只為接收一輪數據,這個顯然要在task_struct中增加一個flag或者借一個bit,而通知內核協議棧的軟中斷例程則是通過將該socket加入到本地的ESTABLISHED緩存哈希表中實現的。
在進程獲得了一輪數據之後,為了不影響Linux系統全局的域調度行為(Linux的域調度可以很好的做到進程的負載均衡同時又不破壞cache的熱度),需要將釘死的進程釋放,同時注意優化點1,到底需不需要將socket從本地表摘除呢?鑒於進程遷移一般都是小概率事件,所以進程在相當大的概率下是不會遷移的,因此不摘除socket可以省下一些mips。
4.3.客戶socket與連接處理完全分開處理
一對一的TCP socket數據傳輸處理和本文第一部分描述的連接處理是沒有關系的,accept返回之後,由哪個進程/線程處理這個客戶socket,是否綁定它到特定的CPU,這些都不會影響連接處理的過程。
4.4.Linux原生協議棧的例行優化-prequeue與backlog
事實上,由於涉及到數據拷貝,內核協議棧一直都是傾向於讓用戶進程自己來解析,處理一個skb,而內核要做的只是將skb掛在某個隊列中,這是一個非常常規的優化。Linux協議棧中存在兩個隊列,prequeue和backlog,前者是當協議棧發現沒有任何一個用戶進程占據某個socket的時候,其嘗試將skb掛入一個用戶prequeue隊列,當用戶進程調用recv的時候,自行dequeue並處理之,後者則是當協議棧發現當前socket被某個用戶進程占據的時候,將skb掛入backlog隊列,待用戶進程釋放該socket的時候,自行dequeue並處理之。
4.5.Linux原生協議棧的例行優化-RPS/RFS優化
這實際上是軟件模擬的RSS類似的東西,資料已經不少,其宗旨就是盡量讓協議棧處理的CPU和用戶進程處理的CPU是同一個CPU,我們知道,對於連接處理,由於是一對多的關系,這樣並不可行,然而對於一對一的客戶socket,這樣的效果非常好。
4.6.Linux原生協議棧的例行優化-early demux
Linux協議棧期望如果在確認一個數據流的第一個數據包是本地接收的前提下,免除後續路由查找,只實現socket查找即可。這是一種典型的一次查找,短路使用的優化方案,類似的還有一次查找,多方多次使用,類似於我對nf_conntrack所做的那樣。
4.7.Linux原生協議棧的例行優化-busy poll
顧名思義,就是不等協議棧往上送skb,而是自己直接去底層拿,有點像快遞自提那種。然而由於在底層沒有經過協議棧處理,根本就不確定這個數據包是不是發給自己的,因此這會有一定的風險,但是如果在統計意義上你能確定自己系統的行為,那麼也是可以起到優化效果的。
5.總結
5.1.關於TCP連接處理的優化
如果你把一個Listener僅僅看作是一個被內核協議棧處理的socket,那麼你很容易找到很多值得優化的點,比如這裡把鎖拆分成粒度更細的,那裡判斷一下搶占什麼的,然後代碼就會越來越復雜和龐大。但是反過來,如果你把一個Listener看作是一個基礎設施,那事情就簡單多了。基礎設施是服務於客戶的,它有兩個基本的性質:
1).它永遠在那裡
2).它不受客戶的控制
對於一個TCP Listener,難道它不該是一個基礎設施嗎?它應該和CPU是一伙的,作為資源然後為連接請求服務,它本不應該是搶CPU的家伙,不應該抱有“它如何才能搶到更多的CPU時間,如何才能拽取其它Listener的資源....”這樣的想法去優化它。
Linux內核中有很多這樣的例子,比如ksoftirqd/0,ksoftirqd/0/1,像這種kxxxx/n這類內核線程都可以看作是基礎設施,在每一個CPU上提供相同的服務,不干涉別的CPU,永遠都是取Per CPU的管理數據。按照這樣的想法,當需要提供一個TCP服務的時候,很容易想法建立一個類似的基礎設施,它將永遠在那裡,每一個CPU上一個,為新到來的連接提供連接服務,它服務的產品就是一個客戶socket,至於說怎麼交給進程,通過兩類Accept隊列提供一個服務窗口!我們假設一個偵聽進程或者線程掛掉了,這絲毫不會影響TCP Listener基礎設施,它的進程無關性繼續為其它的進程提供客戶socket,直到所有的偵聽進程全部掛掉或者主動退出,而這很容易用引用計數來跟蹤。
在這個優化版本中,你可以這樣想,從兩類Accept隊列往下,TCP Listener基礎設施與用戶的偵聽進程無關了,不會受到其影響,即便用戶偵聽進程不斷在CPU間跳躍,綁定,解除綁定,它們影響不到Accept隊列下面的TCP Listener基礎設施,受影響的也只是它們自己從哪個Accept隊列裡獲取客戶socket的問題。下面是一個簡圖:
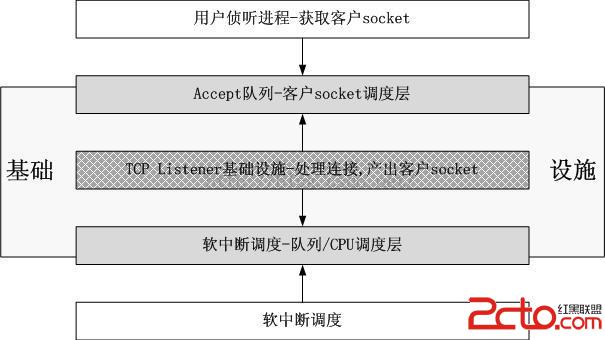
同樣,由於TCP Listener已經基礎設施化了,向上用Accept隊列隔離了用戶進程socket,向下用中斷調度系統隔離了網卡或者網卡隊列,因此也就沒有了很多優化版本中面臨的四種情況:隊列比CPU多,隊列與CPU相等,隊列比CPU少,根本就沒有隊列。
5.2.關於TCP傳輸處理的優化
本文針對這個方面說的不是很多,很大一部分原因在於這部分並不是核心瓶頸,Linux本身的調度系統已經可以很好的應對進程切換,遷移對cache的影響,因此,你會發現,我做的僅有的優化也是針對這兩方面的,同時,增加一個本地ESTABLISHED哈希緩存會帶來小量的性能提升,這個想法來自於我增加的nf_conntrack的cache以及slab分級cache。
5.3.與數據包轉發的統一
前段時間搞過一個Linux轉發性能優化,當時引入了一個虛擬輸出隊列(VOQ),解決加速比的問題,為了實現線速pps,轉發的情況存在網卡帶寬的N加速比問題,因此當時創建轉發基礎設施的時候是把網卡拉過來搭伙合作,而不是CPU,事實上,如果在多隊列網卡上,這二者是完全一致的,網卡隊列可以綁定到CPU,並且還可以一個CPU專門處理輸入,一個專門處理輸出。
配合Per CPU的skb pool(我舉的是卡車運貨的例子),每一個Listener在每一個CPU上都有一個skb pool,這樣對於本地出發的數據包,可以做到無鎖化的分配skb。
現在針對TCP的情況我們可以把轉發和本地接收統一在一起了,對於轉發而言,出口是另一塊網卡,對於本地接收而言,出口是Accept隊列(握手包)或者用戶緩沖區(傳輸包)。如果出口處沒有用戶進程,假設不是放入隊列,而是直接丟棄,那麼Per CPU的Accept隊列真的就是一塊網卡了。


