result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) { // 冒泡排序
// 找到了更加合適的socket,需要重新hash
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = udp_ehashfn(net, daddr, hnum,
saddr, sport);
matches = 1;
}
} else if (score == badness && reuseport) { // reuseport套接字散列定位
// 找到了同樣reuseport的socket,進行定位
matches++;
if (reciprocal_scale(hash, matches) == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}
result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) {
// 在reuseport情形下,意味著找到了更加合適的socket組,需要重新hash
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = udp_ehashfn(net, daddr, hnum,
saddr, sport);
if (select_ok) {
struct sock *sk2;
// 找到了一個組,接著進行組內hash。
sk2 = reuseport_select_sock(sk, hash, skb,
sizeof(struct udphdr));
if (sk2) {
result = sk2;
select_ok = false;
goto found;
}
}
matches = 1;
}
} else if (score == badness && reuseport) {
// 這個else if分支的期待是,在分層查找不適用的時候,尋找更加匹配的reuseport組,注意4.5/4.6以後直接尋找的是一個reuseport組。
// 在某種意義上,這回退到了4.5之前的算法。
matches++;
if (reciprocal_scale(hash, matches) == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}
struct sock *reuseport_select_sock(struct sock *sk,
u32 hash,
struct sk_buff *skb,
int hdr_len)
{
...
prog = rcu_dereference(reuse->prog);
socks = READ_ONCE(reuse->num_socks);
if (likely(socks)) {
/* paired with smp_wmb() in reuseport_add_sock() */
smp_rmb();
if (prog && skb) // 可以用BPF來從用戶態注入自己的定位邏輯,更好實現基於策略的負載均衡
sk2 = run_bpf(reuse, socks, prog, skb, hdr_len);
else
// reciprocal_scale簡單地將結果限制在了[0,socks)這個區間內
sk2 = reuse->socks[reciprocal_scale(hash, socks)];
}
...
}
#define MAX 18 struct sock *reusesk[MAX];每當OpenVPN創建一個reuseport的UDP套接字的時候,我會將其順序加入到reusesk數組中去,最終的查找算法修改如下:
result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) {
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = inet_ehashfn(net, daddr, hnum,
saddr, htons(sport));
#ifdef EXTENSION
// 直接取索引指示的套接字
result = reusesk[hash%MAX];
// 如果只有一組reuseport的套接字,則直接返回,否則回退到原始邏輯
if (num_reuse == 1)
break;
#endif
matches = 1;
}
} else if (score == badness && reuseport) {
matches++;
if (((u64)hash * matches) >> 32 == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}
非常簡單的修改。除此之外,每當有套接字被銷毀,除了將其數組對應的索引位設置為NULL之外,對其它索引為的元素沒有任何影響,後續有新的套接字被創建的時候,只需要找到一個元素為NULL的位置加進去就好了,這就解決了由於套接字位置變動造成數據包被定向到錯誤的套接字問題(因為索引指示的位置元素已經由於移動位置而變化了)。這個問題的影響有時是劇烈的,比如後續所有的套接字全部向前移動,將影響多個套接字,有時影響又是輕微的,比如用最後一個套接字填補設置為NULL的位置,令人遺憾的是,即使是4.6的內核,其采用的也是上述後一種方式,即末尾填充法,雖然只是移動一個套接字,但問題依然存在。幸運的是,4.6內核的reuseport支持BPF,這意味著你可以在用戶態自己寫代碼去控制套接字的選擇,並可以實時注入到內核的reuseport選擇邏輯中。首先,我們可以將一個reuseport套接字組中所有的套接字按照其對應的PID以及內存地址之類的唯一標識,HASH到以下16bits的線性空間中(其中第一個套接字占據端點位置),如下圖所示:
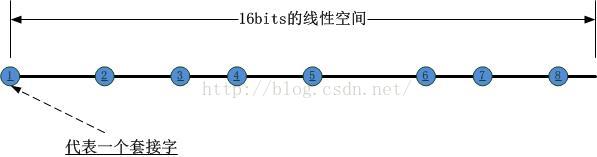
這樣N個socket就將該線性空間分割成了N個區間,我們把這個HASH的過程稱為第一類HASH!接下來,當一個數據包到達時,如何將其對應到某一個套接字呢?此時要進行第二類hash運算,這個運算的對象是數據包攜帶的源IP/源端口對,HASH的結果對應到前述16bits的線性空間中,如下圖所示:
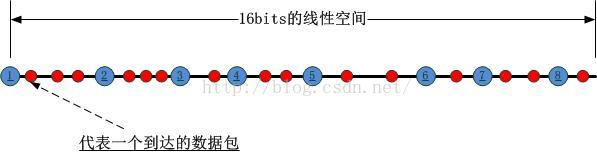
我們將第二類HASH值左邊的第一個第一類HASH值對應的套接字作為被選定的套接字,如下圖所示:
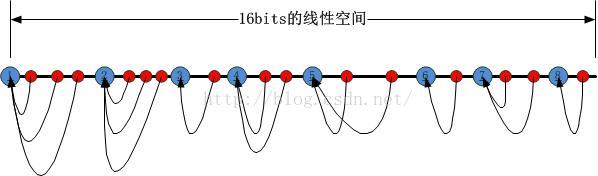
可以很容易看出來,如果第一類HASH值的節點被刪除或者新添加(意味著套接字的銷毀和新建),受到影響的僅僅是該節點與其右邊的第一個第一類HASH節點之間的第二類HASH節點,如下圖所示:
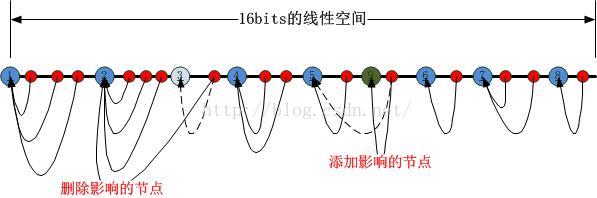
這就是簡化版的“一致性HASH”的原理。如果想在新建,銷毀的時候,一點都不受影響,那就別折騰這些算法了,還是老老實實搞數組吧。