


內核版本:2.6.34
ICMP模塊比較簡單,要注意的是icmp的速率限制策略,向IP層傳輸數據ip_append_data()和 ip_push_pending_frames()。
在net/ipv4/af_inet.c中的inet_init()注冊icmp協議,從這裡也可以看出,ICMP模塊是綁 定在IP模塊之上的。inet_add_protocol()會將icmp_protocol加入到全局量inet_protos中。
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
printk(KERN_CRIT "inet_init: Cannot add ICMP protocol\n");
icmp_protocol定義如下:
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.no_policy = 1,
.netns_ok = 1,
};
除了注冊icmp協議,還要對icmp模塊初始化,這部分由icmp_init()完成。
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
icmp_init()函數做的事很簡單,register_pernet_subsys(&icmp_sk_ops),而注冊icmp網絡子系統過程中會調用 icmp_sk_ops.init(即icmp_sk_init函數)來完成它的初始化,下面具體看icmp_sk_init()函數。
首先為net為配CPU數目 (nr_cpu_ids)個struct sock結構體空間,這裡的net是全局的網絡名,一般是init_inet。
net->ipv4.icmp_sk = kzalloc(nr_cpu_ids * sizeof(struct sock *), GFP_KERNEL);
每個CPU i,它的sock結構體位於net中的icmp_sk[i]。於每 個CPU i,初始化剛剛分配的icmp_sk[i]:
-第一步,inet_ctl_sock_create()創建sk,並在net->ipv4.icmp_sk[i] = sk中將其賦值給icmp_sk[i]。
-第二步:ICMP發送緩存區大小sk_sndbuf設置為128K
for_each_possible_cpu(i) {
struct sock *sk;
err = inet_ctl_sock_create(&sk, PF_INET,
SOCK_RAW, IPPROTO_ICMP, net);
if (err < 0)
goto fail;
net->ipv4.icmp_sk[i] = sk;
sk->sk_sndbuf =
(2 * ((64 * 1024) + sizeof(struct sk_buff)));
sock_set_flag(sk, SOCK_USE_WRITE_QUEUE);
inet_sk(sk)->pmtudisc = IP_PMTUDISC_DONT;
}
忽略發往廣播地址的icmp echo報文;忽略發往廣播地址的錯誤的響應報文;
net- >ipv4.sysctl_icmp_echo_ignore_all = 0; net->ipv4.sysctl_icmp_echo_ignore_broadcasts = 1; net->ipv4.sysctl_icmp_ignore_bogus_error_responses = 1;
設置icmp處理速率,這裡的ratelimit和ratemask參 數在後面限速處理時會具體用到。
net->ipv4.sysctl_icmp_ratelimit = 1 * HZ; net->ipv4.sysctl_icmp_ratemask = 0x1818; net->ipv4.sysctl_icmp_errors_use_inbound_ifaddr = 0;
初始化工作完成後,還是從icmp的接收開始,icmp_rcv 完成icmp報文的處理。
取得icmp報頭,此時skb->transport_header是在IP模塊處理中的ip_local_deliver_finish() 將其設置為了指向icmp報頭的位置。
icmph = icmp_hdr(skb);
根據icmp的類型type交由不同的處理函數去完成。
icmp_pointers[icmph->type].handler(skb);
icmp_pointers是在icmp.c中定義的全局量,部分如下:
static const struct icmp_control icmp_pointers[NR_ICMP_TYPES + 1] = {
[ICMP_ECHOREPLY] = {
.handler = icmp_discard,
},
[1] = {
.handler = icmp_discard,
.error = 1,
},
……
}
比如對於收到的icmp報文type為0或1(響應答復或目的不可達),協議棧要做的就是丟棄掉它 – icmp_discard()。下 面以icmp echo和icmp timestamp為例說明。
收到icmp echo報文執行icmp_echo()
icmp_param是回復時信息,它直接 拷貝了echo的ICMP報頭icmp_hdr(skb),僅僅改變了報頭的type = ICMP_ECHO_REPLY,然後調用icmp_reply()處理發送。
struct icmp_bxm icmp_param; icmp_param.data.icmph = *icmp_hdr(skb); icmp_param.data.icmph.type = ICMP_ECHOREPLY; icmp_param.skb = skb; icmp_param.offset = 0; icmp_param.data_len = skb->len; icmp_param.head_len = sizeof(struct icmphdr); icmp_reply(&icmp_param, skb);
收到icmp timestamp報文後執行icmp_timestamp()
經過IP層處理,skb- >data指向icmp報頭的位置,而報頭最小為4字節,所以這裡判斷skb->len < 4,是則丟棄該報文。從這裡也可以看出 ,時間戳請求報文可以只有4節字頭部,而沒有時間戳信息。
if (skb->len < 4) goto out_err;
這段代碼設置時間戳響應的時間戳信息,包括接收時間戳和發送時間戳,兩者分別代表主機收到報文 的時間,發送響應報文的時間,而從這部分代碼也可以看出icmp_param.data.times[2] = icmp_param.data.times[1]協議棧簡 單的將接收和發送時間戳置為相同的。時間戳的計算很簡單,格林尼治時間的當天時間的微秒數。最後skb_copy_bits()從skb的 ICMP報文內容拷貝4節字的時間到icmp_param_data.times[0],即發起時間戳,所以最後情形如下:
icmp_param_data.times[0] 發起時間戳,從請求報文中拷貝
icmp_param_data.times[0] 接收時間戳,處理ICMP報頭時的 時間
icmp_param_data.times[0] 發送時間戳,設置為與接收時間戳相同
getnstimeofday(&tv); icmp_param.data.times[1] = htonl((tv.tv_sec % 86400) * MSEC_PER_SEC + tv.tv_nsec / NSEC_PER_MSEC); icmp_param.data.times[2] = icmp_param.data.times[1]; if (skb_copy_bits(skb, 0, &icmp_param.data.times[0], 4)) BUG();
前面已經說過,icmp_param就是要發送ICMP報文的內容,上面設置了內容,接下來設置報頭,同樣是直接拷貝 了ICMP請求的報頭,改變type為ICMP_TIMESTAMPREPLY。注意這裡的data_len設置為0,因為它與icmp echo不同,一定是沒有分 片的,即沒有paged_data部分。head_len設置為icmphdrlen+12,這裡是為了調用icmp_reply()回復時的統一,實現表示ICMP部 分的長度,主要是有分片時會根據head_len來跳過報頭而只拷貝每個分片的內容。
icmp_param.data.icmph = *icmp_hdr(skb); icmp_param.data.icmph.type = ICMP_TIMESTAMPREPLY; icmp_param.data.icmph.code = 0; icmp_param.skb = skb; icmp_param.offset = 0; icmp_param.data_len = 0; icmp_param.head_len = sizeof(struct icmphdr) + 12;
最後調用icmp_reply()回復,這與icmp_echo()是相同的 。
icmp_reply(&icmp_param, skb);
注意兩者設置icmp_param參數時的區別:
icmp_echo()中 icmp_param.data_len=skb->len;
icmp_param.head_len=sizeof(struct icmphdr);
icmp_timestamp()中icmp_param.data_len=0。
icmp_param.head_len=sizeof(struct icmphdr) +12;
icmp_reply()
通過ip_route_output_key()查找路由信息,存放在rt中。路由項在這裡有兩個作用:一是限速是 針對每個路由項的,在icmpv4_xrlim_allow()中會用到;二是將報文傳遞給IP層需要用到rt。仔細觀察流程可以發現,報文在協 議棧傳遞過程中,在IP層會 查找一次路由表獲取到了rt,而在這裡又查找了一次路由表,似乎是重復了。其實不是,IP層查 找是在報文接收階段,這裡的查找是在報文的發送階段。
{
struct flowi fl = { .nl_u = { .ip4_u =
{ .daddr = daddr,
.saddr = rt->rt_spec_dst,
.tos = RT_TOS(ip_hdr(skb)->tos) } },
.proto = IPPROTO_ICMP };
security_skb_classify_flow(skb, &fl);
if (ip_route_output_key(net, &rt, &fl))
goto out_unlock;
}
協議棧對於部分ICMP報文進行了限速,但這種限速不是整體的,而是針對每個路由項的,即限制每個地址發送ICMP報 文的限率。icmpv4_xrlim_allow()判斷該icmp報文是否需要被限速,如果能接收,則調用icmp_puash_reply()發送響應。
if (icmpv4_xrlim_allow(net, rt, icmp_param->data.icmph.type,
icmp_param->data.icmph.code))
icmp_push_reply(icmp_param, &ipc, &rt);
icmpv4_xrlim_allow() -> xrlim_allow() 限速處理
速 率有關的參數是在icmp_init() -> icmp_sk_init()創建ICMP的sock時設置的,ratelimit是限制的速率,即TBF代碼段中的 timeout,可以理解成一個令牌;ratemask是被限制速率的ICMP的報文類型,(1 << type & retemask) == 1判斷是否 限速,type即ICMP類型,可見默認情況下[3]dest unreachable, [4]source quench, [11]time exceeded, [12]parameter problem才會被限速。
net->ipv4.sysctl_icmp_ratelimit = 1 * HZ; net->ipv4.sysctl_icmp_ratemask = 0x1818;
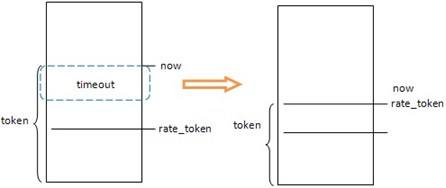
限速使用了Token Bucket Filter(令牌環過濾器)思想,大致是每個 到來的令牌從數據隊列中收集一個數據包,然後從桶中刪除。令牌被耗盡時,數據包將停止發送一段時間。
ICMP的限速使用 的就是這種思想,不過時間作為令牌,它的增長是連續的;每來一個報文,拿走一個令牌,則是一個時間段timeout,令牌也限 定了最大數目是XRLIM_BURST_FACTOR為6;簡單來講就是每過timeout時間,令牌數就加1,當令牌數達到6時不再增加;而來一 個報文,令牌數就減一,當令牌數為空時,不再減少,該報文也被丟棄;在這種情況下,在過timeout時間,才會處理下一個報 文。實現的代碼段如下:
#define XRLIM_BURST_FACTOR 6
int xrlim_allow(struct dst_entry *dst, int timeout)
{
unsigned long now, token = dst->rate_tokens;
int rc = 0;
now = jiffies;
token += now - dst->rate_last;
dst->rate_last = now;
if (token > XRLIM_BURST_FACTOR * timeout)
token = XRLIM_BURST_FACTOR * timeout;
if (token >= timeout) {
token -= timeout;
rc = 1;
}
dst->rate_tokens = token;
return rc;
}
dst->rate_tokens記錄上一次的令牌,dst->rate_last記錄上一次訪問時間,now – dst->rate_last為經 過的時間即增加的令牌數;當token>=timeout時即至少還有一個令牌,反回rc=1表示仍有令牌,不用限速;否則返回rc=0, 限速。
icmp_push_reply() 發送回復報文
取出icmp使用的sock sk
sk = icmp_sk(dev_net((*rt)- >u.dst.dev));
if中的ip_append_data()函數表示把數據添加到sk->sk_write_queue,這個函數是用於上層向IP層 傳輸報文,它會進行分片的操作,實際是幫IP層做了分片。具體函數調用參見後面的ip_append_data()函數分析。正常情況 ip_append_data()返回0,即if的執行語句不會被觸發。
if (ip_append_data(sk, icmp_glue_bits, icmp_param,
icmp_param->data_len+icmp_param->head_len,
icmp_param->head_len,
ipc, rt, MSG_DONTWAIT) < 0)
ip_flush_pending_frames(sk);
else if進入條件是sk->sk_write_queue中已有數據,顯然在if的判斷語句中已 經將報文添加到了sk->sk_write_queue中,所以會進入else if執行語句調用ip_push_pending_frames()將報文傳遞給IP層。 而在ip_append_data()函數中可以看到,它只是拷貝了報文內容,並沒有生成ICMP報頭,ICMP報頭生成當然也是在通過 ip_push_pending_frames()將報文發給IP層前生成的。取出skb,計算所有分片一起的校驗和,然過通過 csum_partial_copy_nocheck()生成新的icmp報頭,最後調用ip_push_pending_frames()發送數據到IP層。函數 ip_push_pending_frames()函數分析也參見後文。
else if ((skb = skb_peek(&sk->sk_write_queue)) !=
NULL) {
struct icmphdr *icmph = icmp_hdr(skb);
__wsum csum = 0;
struct sk_buff *skb1;
skb_queue_walk(&sk->sk_write_queue, skb1) {
sum = csum_add(csum, skb1->csum);
}
csum = csum_partial_copy_nocheck((void *)&icmp_param->data,
(char *)icmph,
icmp_param->head_len, csum);
icmph->checksum = csum_fold(csum);
skb->ip_summed = CHECKSUM_NONE;
ip_push_pending_frames(sk);
}
ip_append_data() 添加要傳遞到IP層的數據
傳入參數的解釋:
getfrag() – 復制數據,這裡使用函數指針 隱藏了復制細節,因為針對icmp, udp的復制是不同的;
from – 被復制的數據,在icmp模塊中該參數傳入的是struct icmp_bxm;
length – IP報文內容長度
transhdrlen – 傳輸報頭長度,盡管ICMP歸為網絡層協議,但這裡的transhdrlen 也是包括它的,所以更好的解釋是表示IP上一層的報頭,比如ICMP報頭,IGMP報頭,UDP報頭等長度

ip_append_data()函 數比較復雜,這裡以兩個例子來解釋這個函數:發送50 Byte的echo報文,發送600 Byte的echo報文。56字節echo報文在IP層不 需要分片;600字節echo報文在IP層需要分片。ip_append_data()還可以多次調用來收集數據,而在ICMP模塊中這點並不能體現 出來,在以後UDP或TCP時再以解釋多次調用的情況。
example 1:50 Byte echo報文 [假設MTU=520]
如果 sk_write_queue為空,則證明是第一個分片,50字節的報文只需要一個分片。這裡會設置exthdrlen,表示鏈路層額外的報頭長 ,一般情況下是0,所以此時length和transhdrlen值仍是傳入的值。而sk->sk_sndmsg_page和sk->sk_sndmsg_off與發散/ 聚合IO有關,這裡先不考慮。
if (skb_queue_empty(&sk->sk_write_queue)) {
….
sk->sk_sndmsg_page = NULL;
sk->sk_sndmsg_off = 0;
if ((exthdrlen = rt->u.dst.header_len) != 0) {
length += exthdrlen;
transhdrlen += exthdrlen;
}
…
}
設置各種參數的值,hh_len表示以太網報頭的長度,16字節對齊;fragheaderlen表示分片報頭長度,即IP報頭; maxfraglen表示最大分片長度。各參數值:hh_len = 16, fragheaderlen = 20, maxfraglen = 516,注意要求的節字對齊。
hh_len = LL_RESERVED_SPACE(rt->u.dst.dev); fragheaderlen = sizeof(struct iphdr) + (opt ? opt->optlen : 0); maxfraglen = ((mtu - fragheaderlen) & ~7) + fragheaderlen;

此時sk- >sk_write_queue還為空,跳轉至alloc_new_skb執行分配新的skb。
if ((skb = skb_peek_tail(&sk- >sk_write_queue)) == NULL) goto alloc_new_skb;
fraggap在上一個skb沒有8字節對齊時設置為多余的字節數,否則的話fraggap=0;datalen表示 IP報文長度(不包括IP報頭),fraglen表示以太網幀報文長度(不包括以太網頭),alloclen表示要分配的內容長度,下面代碼省 略了一些內容。各參數值: fraggap=0, datalen=50, fraglen=70, alloclen=70。
fraggap = 0; datalen = length + fraggap; fraglen = datalen + fragheaderlen; alloclen = datalen + fragheaderlen;
分配報文skb空間,大小為alloclen+hh_len+15,alloclen + hh_len就是報文 的長度,15個字節為預留部分。
if (transhdrlen) {
skb = sock_alloc_send_skb(sk,
alloclen + hh_len + 15,
(flags & MSG_DONTWAIT), &err);
}
skb_reserve()保留skb頭的hh_len大小,skb_put()擴展skb大小到fraglen,然後設置network_header和 transport_header指向skb的正確位置,data指向ICMP報頭的位置,具體可以看下面的圖示:
skb_reserve(skb, hh_len); …… data = skb_put(skb, fraglen); skb_set_network_header(skb, exthdrlen); skb->transport_header = (skb->network_header + fragheaderlen); data += fragheaderlen;
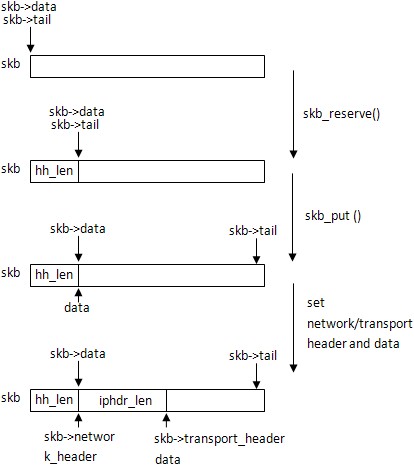
copy是要拷貝的長度,為傳輸層報頭後的內容大小。getfrag()函數實現數據的拷貝,在icmp模塊中, getfrag()指向icmp_glue_bits()函數,它從[from] + offset處拷貝copy個字節到data + transhdrlen處。
copy =
datalen - transhdrlen - fraggap;
if (copy > 0 && getfrag(from, data + transhdrlen, offset, copy, fraggap, skb) < 0) {
err = -EFAULT;
kfree_skb(skb);
goto error;
}
偏移offset加上已經拷貝的字節數copy,fraggap=0,length減去的就是IP報文內容長度,由於報文才56字節,一個 分片足夠,所以length=0,然後把新生成的skb放入sk->sk_write_queue中,然後執行下次while循環。各參數值:copy=42, offset=42, length=0, 更新transhdrlen=0。
offset += copy; length -= datalen - fraggap; transhdrlen = 0; …… __skb_queue_tail(&sk->sk_write_queue, skb); continue;
while循環判斷條件是length > 0,因此跳出循環,完成了向IP層發送的數據生成,結果如下,注意, ICMP報頭還是沒有填寫的:

example 2:600 Byte echo 報文[假設MTU=520]
同樣,開始時sk->sk_write_queue()為空,初始 的設置與上述例子完全相同,不同處在於datalen此時比最大分片還要大,因此要設置datalen=maxfraglen-fragheaderlen。
if (datalen > mtu - fragheaderlen) datalen = maxfraglen - fragheaderlen;
在完全第一個分片後,同樣會將分片skb放入sk_write_queue隊列,並進入 下一次while循環。此時各參數的值:datalen=496, fraglen=516, alloclen=516, skb->len=516,
copy=488, offset=488, length=600-496=104, 更新transhdrlen=0。 __skb_queue_tail(&sk->sk_write_queue, skb); continue;
再次進入while循環,此時不同的是length=104,證明還有數據需要拷貝,此時會對待拷貝的數據進行判斷 ,下面所指的填充滿是針對maxfraglen而言的。
@copy > 0,表示上個報文未被填充滿,這種情況在多次調用 ip_append_data()時會發生,這裡都是一次調用ip_append_data()的情況,所以不會出現,此時會填充數據到上個skb中
@copy = 0,表示上個報文被填充滿,這個例子現在就是這種情況,此時會分配新的skb
@copy < 0,表示上 個報文多填充了數據,這時因為maxfraglen是mtu8字節對齊後的值,所以maxfraglen范圍是[mtu-7, mtu],而在某些特殊情況下 ,比如上個報文已被填滿(實際還可能有[1, 7]字節的空間),待填充字節數n < 8,這時會把這n個節字補在最後一個報文的 尾部。
對這個例子而言,上個skb剛好被填充滿,copy=0,此時分配新的skb。
copy = mtu - skb->len; if (copy < length) copy = maxfraglen - skb->len;
分配新skb的流程與上個skb的分配過程相同,變化的只是偏移量offset,另外, icmp報頭只存在於第一個分片中,因為它也屬於IP內容的一部分,在這次拷貝完成後length=0,函數返回,最後結果如下:

ip_push_pending_frames() 將待發送的報文傳遞給網絡層
待發送的報文分片都在sk->sk_write_queue上,這 裡要做的就是從sk_write_queue上取出所有分片,合並成一個報文,添加IP報頭信息,使用ip_local_out()傳遞給網絡層處理。
要注意的是這裡的合並並不是真正的合並,只有第一個分片形成了skb,剩下的分片都放到了skb_shinfo(skb)- >frag_list上,雖然最後向下傳遞的只是一個skb,並實際上分片工作已經完成了,網絡層並不需要再次分片,由網絡的上層 完成分片是出於效率的考慮,雖然與協議標准有所出入。
首先從sk_write_queue上取出第一個分片,skb是最終向下傳遞的報 文,tail_skb指向skb的frag_list鏈表尾,即最後一個分片。
if ((skb = __skb_dequeue(&sk- >sk_write_queue)) == NULL) goto out; tail_skb = &(skb_shinfo(skb)->frag_list);
將skb->data指向ip報頭的位置
if (skb->data < skb_network_header(skb)) __skb_pull(skb, skb_network_offset(skb));
tmp_skb表示現在要插入skb的分片,首先通過__skb_pull()除去這些 分片的IP報頭,因為分片共用skb的IP報頭。然後通過tail_skb處理將tmp_skb鏈入frag_list中;最後增加報文長度計數,以前 說明過,skb->len代表linear buffer + paged buffer,skb->data_len代表paged_buffer,這裡插入的分片是增加了 paged buffer大小,所以對skb->len和skb->data_len都增加分片的長度。
while ((tmp_skb = __skb_dequeue
(&sk->sk_write_queue)) != NULL) {
__skb_pull(tmp_skb, skb_network_header_len(skb));
*tail_skb = tmp_skb;
tail_skb = &(tmp_skb->next);
skb->len += tmp_skb->len;
skb->data_len += tmp_skb->len;
skb->truesize += tmp_skb->truesize;
tmp_skb->destructor = NULL;
tmp_skb->sk = NULL;
}
這裡是生成skb的IP報頭,設置其中的值
iph = (struct iphdr *)skb->data; iph->version = 4; ……. skb->mark = sk->sk_mark;
最終通過ip_local_out()傳遞給IP層
err = ip_local_out(skb);