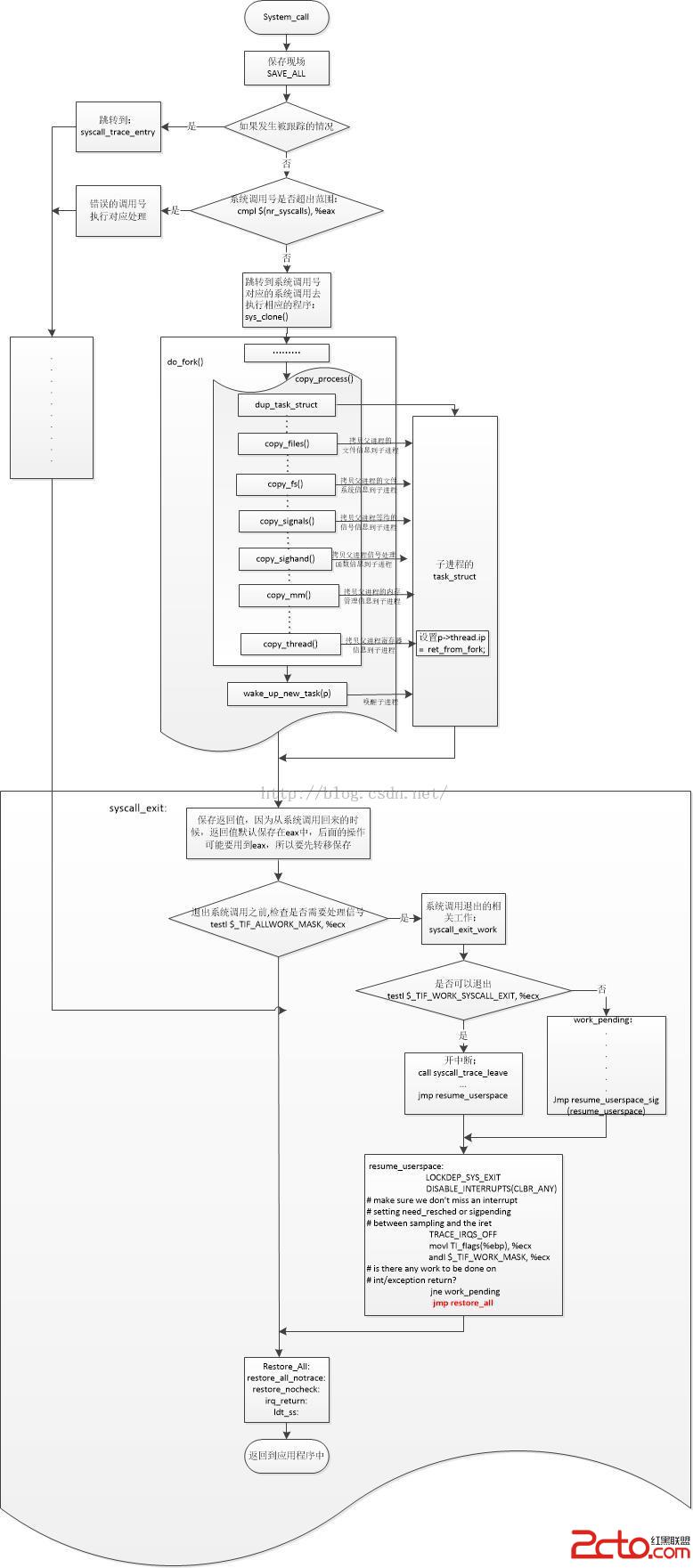
1、進程與程序的關系:
進程是動態的,而程序是靜態的;從結構上看,每個進程的實體都是由代碼斷和相應的數據段兩部分組成的,這與程序的含義很相近;一個進程可以涉及多個程序的執行,一個程序也可以對應多個進程,即一個程序段可在不同數據集合上運行,構成不同的進程;並發性;進程具有創建其他進程的功能;操作系統中的每一個進程都是在一個進程現場中運行的。linux中用戶進程是由fork系統調用創建的。計算機的內存、CPU 等資源都是由操作系統來分配的,而操作系統在分配資源時,大多數情況下是以進程為個體的。
每一個進程只有一個父進程,但是一個父進程卻可以有多個子進程,當進程創建時,操作系統會給子進程創建新的地址空間,並把父進程的地址空間的映射復制到子進程的地址空間去;父進程和子進程共享只讀數據和代碼段,但是堆棧和堆是分離的。
2、進程的組成:
進程控制塊代碼數據進程的代碼和數據由程序提供,而進程控制塊則是由操作系統提供。
3、進程控制塊的組成:
進程標識符進程上下文環境進程調度信息進程控制信息進程標識符:
進程ID進程名進程家族關系擁有該進程的用戶標識進程的上下文環境:(主要指進程運行時CPU的各寄存器的內容)
通用寄存器程序狀態在寄存器堆棧指針寄存器指令指針寄存器標志寄存器等進程調度信息:
進程的狀態進程的調度策略進程的優先級進程的運行睡眠時間進程的阻塞原因進程的隊列指針等當進程處於不同的狀態時,會被放到不同的隊列中。
進程控制信息:
進程的代碼、數據、堆棧的起始地址進程的資源控制(進程的內存描述符、文件描述符、信號描述符、IPC描述符等)進程使用的所有資源都會在PCB中描述。
進程創建時,內核為其分配PCB塊,當進程請求資源時內核會將相應的資源描述信息加入到進程的PCB中,進程退出時內核會釋放PCB塊。通常來說進程退出時應該釋放它申請的資源,如文件描述符等。為了防止進程遺忘某些資源(或是某些惡意進程)從而導致資源洩漏,內核通常會根據PCB中的信息回收進程使用過的資源。
4、task_struct 在內存中的存儲:
在linux中進程控制塊定義為task_struct, 下圖為task_struct的主要成員:
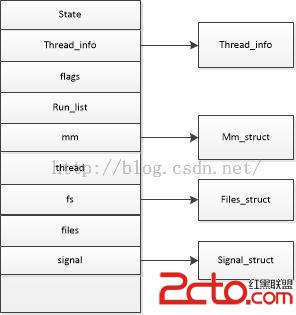
在2.6以前的內核中,各個進程的task_struct存放在他們內核棧的尾端。這樣做是為了讓那些像X86那樣寄存器較少的硬件體系結構只要通過棧指針就能計算出它的位置,而避免使用額外的寄存器來專門記錄。由於現在使用slab分配器動態生成task_struct,所以只需在棧底或棧頂創建一個新的結果struct thread_info(在文件 asm/thread_info.h中定義)
struct thread_info{
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};

5、fork()、vfork()的聯系:
Fork() 在2.6版本的內核中Linux通過clone()系統調用實現fork()。這個系統調用通過一系列的參數標志來指明父、子進程需要共享的資源。Fork()、vfork()和庫函數都根據各自需要的參數標志去調用clone(),然後由clone()去調用do_fork().
do_fork()完成了創建中的大部分工作,它的定義在kernel/fork.c文件中。該函數調用copy_process()函數,然後進程開始運行。Copy_process()函數完成的工作很有意思:
1)、調用dup_task_struct()為新進程創建一個內核堆棧、thread_info結構和task_struct結構,這些值與當前進程的值完全相同。此時子進程和父進程的描述符是完全相同的。
2)、檢查並確保新創建這個子進程後,當前用戶所擁有的進程數目沒有超出給他分配的資源的限制。
3)、子進程著手是自己與父進程區別開來。進程描述符內的許多成員變量都要被清零或設為初始值。那些不是繼承而來的進程描述符成員,主要是統計信息。Task_struc中的大多數據都依然未被修改。
4)、子進程的狀態被設置為TASK_UNINTRRUPTIBLE,以保證它不會被投入運行。
5)、copy_process()調用copy_flags()以更新task_struct 的flags成員。表明進程是否擁有超級用戶權限的PF_SUPERPRIV標志被清0.表明進程還沒有調用exec()函數的PF_FORKNOEXEC標志被設置。
6)、調用alloc_pid()為新進程分配一個有效的PID。
7)、根據傳遞給clone() 的參數標志,copy_process()拷貝或共享打開的文件、文件系統信息、信號處理函數、進程地址空間和命名空間等。在一般情況下,這些資源會被給定進程的所有線程共享;否則,這些資源對每個進程是不同的因此被拷貝到這裡。
8)、最後copy_process()做掃尾工作並返回一個指向子進程的指針。
在回到do_fork()函數,如果copy_process()函數成功返回,新創建的子進程被喚醒並讓其投入運行。內核有意選擇子進程首先執行(雖然總是想子進程先運行,但是並非總能如此)。因為一般子進程都會馬上調用exec()函數,這樣可以避免寫時拷貝(copy-on-write)的額外開銷,如果父進程首先執行的話,有可能會開始向地址空間寫入。
Vfork() 除了不拷貝父進程的頁表項外vfork()和fork()的功能相同。子進程作為父進程的一個單獨的線程在它的地址空間裡運行,父進程被阻塞,直到子進程退出或執行exec()。子進程不能向地址空間寫入(在沒有實現寫時拷貝的linux版本中,這一優化是很有用的)。
do_fork() --> clone() --> fork() 、vfork() 、__clone() ----->exec()
clone()函數的參數及其意思如下:
CLONE_FILES 父子進程共享打開的文件
CLONE_FS 父子進程共享文件系統信息
CLONE_IDLETASK 將PID設置為0(只供idle進程使用)
CLONE_NEWNS 為子進程創建新的命名空間
CLONE_PARENT 指定子進程與父進程擁有同一個父進程
CLONE_PTRACE 繼續調試子進程
CLONE_SETTID 將TID寫回到用戶空間
CLONE_SETTLS 為子進程創建新的TLS
CLONE_SIGHAND 父子進程共享信號處理函數以及被阻斷的信號
CLONE_SYSVSEM 父子進程共享System V SEM_UNDO語義
CLONE_THREAD 父子進程放進相同的進程組
CLONE_VFORK 調用Vfork(),所以父進程准備睡眠等待子進程將其喚醒
CLONE_UNTRACED 防止跟蹤進程在子進程上強制執行CLONE_PTRACE
CLONE_STOP 以TASK_SROPPED狀態開始執行
CLONE_SETTLS 為子進程創建新的TLS(thread-local storage)
CLONE_CHILD_CLEARTID 清除子進程的TID
CLONE_CHILD_SETTID 設置子進程的TID
CLONE_PARENT_SETTID 設置父進程的TID
CLONE_VM 父子進程共享地址空間
二、GDB追蹤fork()系統調用。
GDB 調試的相關內容可以參考:GDB追蹤內核啟動 篇 這裡不再占用過多篇幅贅述。下面先直接上圖,在詳細分析代碼的運行過程。
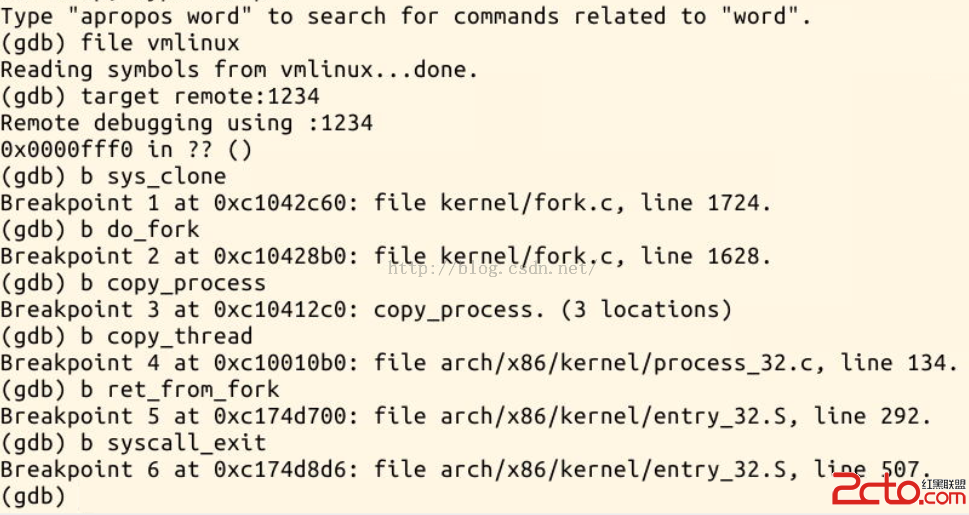
啟動GDB後分別在sys_clone、do_fork、copy_process、copy_thread、ret_from_fork、syscall_exit等位置設置好斷點,見證fork()函數的執行過程(運行環境與GDB追蹤內核啟動 篇完全一致)
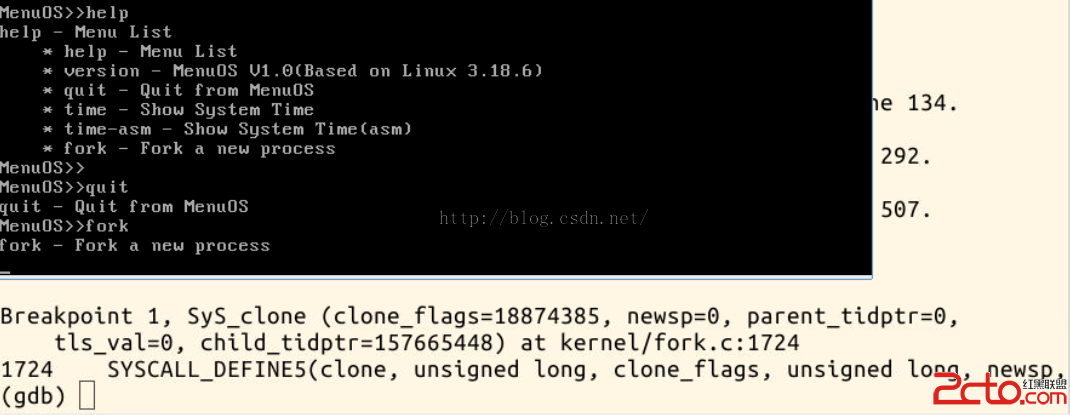
可以看到,當我們在menuos中運行fork 命令的時候,內核會先調用clone,在sys_clone 斷點處停下來了。
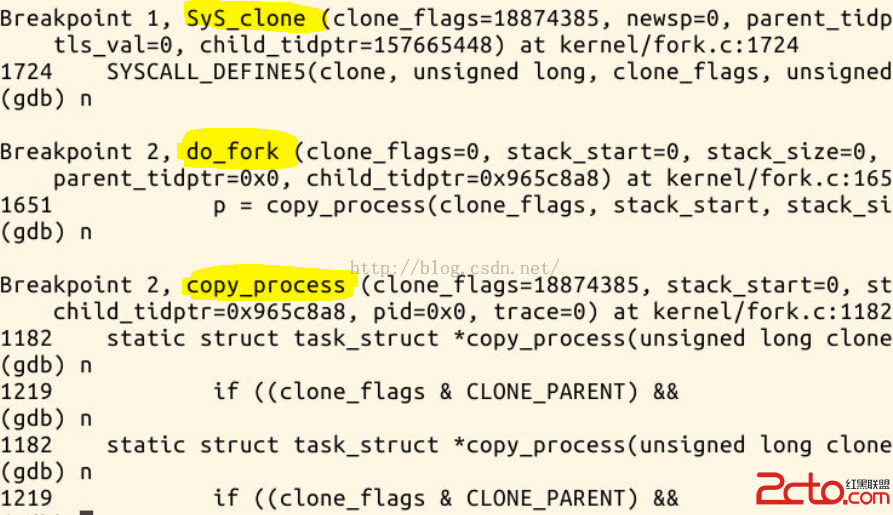
在調用sys_clone() 後,內核根據不同的參數去調用do_fork()系統調用。進入do_fork()後就去又運行了copy_process().
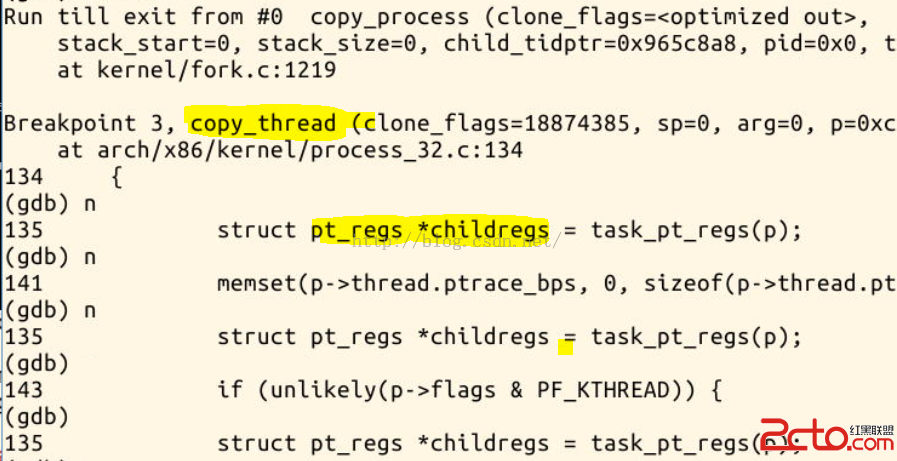
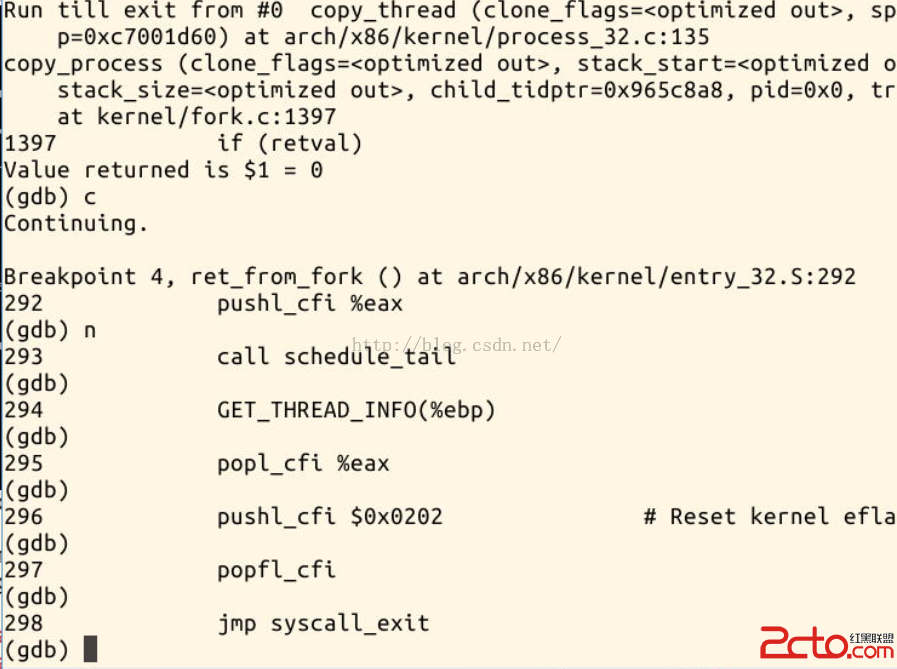
在copy_process() 中又運行了copy_thread(),然後跳轉到了ret_from_fork 處運行一段匯編代碼,再然後就跳到了syscall_exit(這是在arch/x86/kernel/entry_32.S中的一個標號,是執行系統調用後用於退出內核空間的匯編程序。),

可以看到,GDB追蹤到syscall_exit 後就無法繼續追蹤了.................
三、代碼分析(3.18.6版本的內核)
在3.18.6版本的內核 kernel/fork.c文件中:
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0, 0, NULL, NULL);
}
#endif
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, int __user *, parent_tidptr, int, tls_val,int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags, int __user *, parent_tidptr, int __user *, child_tidptr, int, tls_val)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp, int, stack_size, int __user *, parent_tidptr, int __user *, child_tidptr, int, tls_val)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, int __user *, parent_tidptr, int __user *, child_tidptr, int, tls_val)
#endif
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
#endif
從以上fork()、vfork()、clone() 的定義可以看出,三者都是根據不同的情況傳遞不同的參數直接調用了do_fork()函數,去掉了中間環節clone()。
進入do_fork 後:
在do_fork中首先是對參數做了大量的參數檢查,然後就執行就執行 copy_process將父進程的PCB復制一份到子進程,作為子進程的PCB,再然後根據copy_process的返回值P判斷進程PCB復制是否成功,如果成功就先喚醒子進程,讓子進程就緒准備運行。
所以在do_fork中最重要的也就是copy_process()了,它完成了子進程PCB的復制與初始化操作。下面就進入copy_process中看看內核是如何實現的:
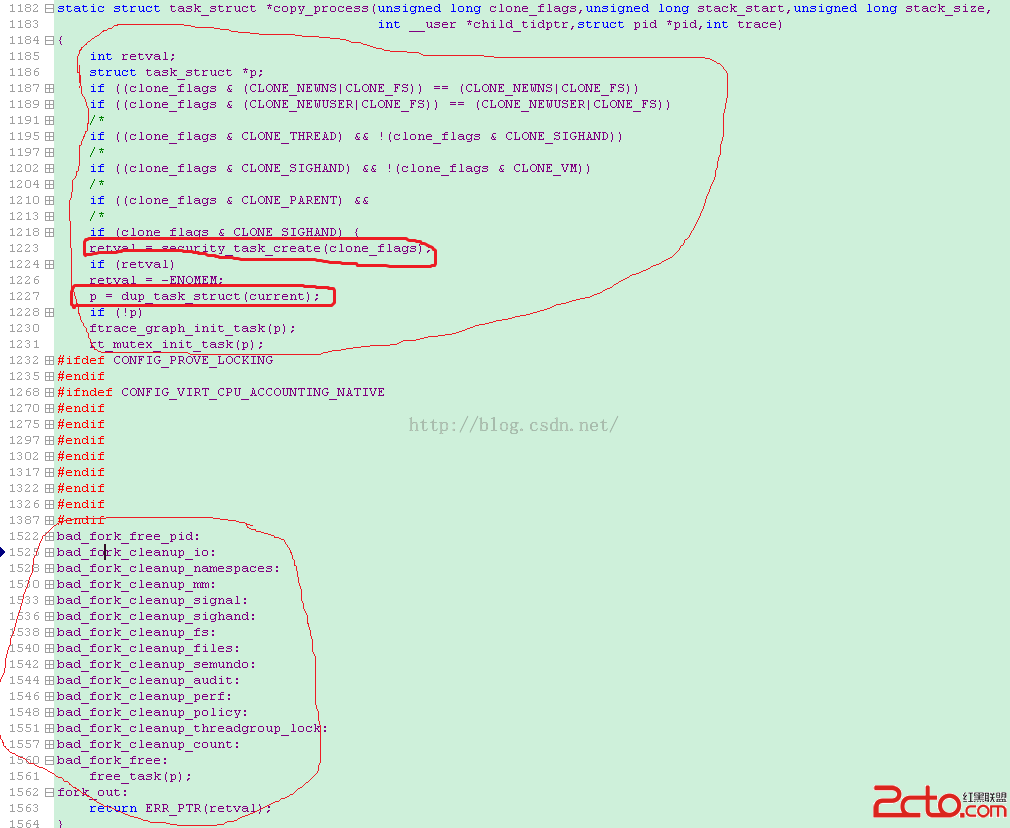
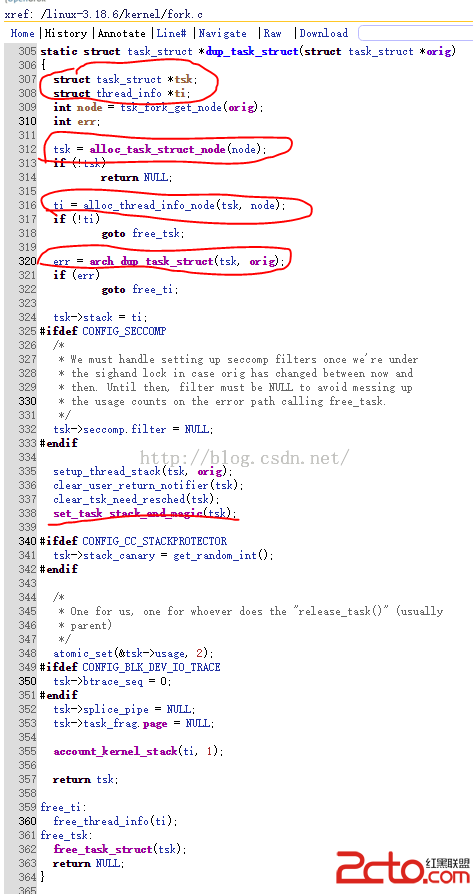
先從整體上看一下,發現,copy_process中開頭一部分的代碼同樣是參數的檢查和根據不同的參數執行一些相關的操作,然後創建了一個任務,接著dup_task_struct(current)將當前進程的task_struct 復制了一份,並將新的task_struct地址作為指針返回!
在dup_task_struct中為子進程創建了一個task_struct結構體、一個thread_info 結構體,並進行了簡單的初始化,但是這是子進程的task_struct還是空的所以接下來的中間一部顯然是要將父子進程task_struct中相同的部分從父進程拷貝到子進程,然後不同的部分再在子進程中進行初始化。
最後面的一部分則是,出現各種錯誤後的退出口。
下面來看一下中間那部分:如何將父子進程相同的、不同的部分區別開來。
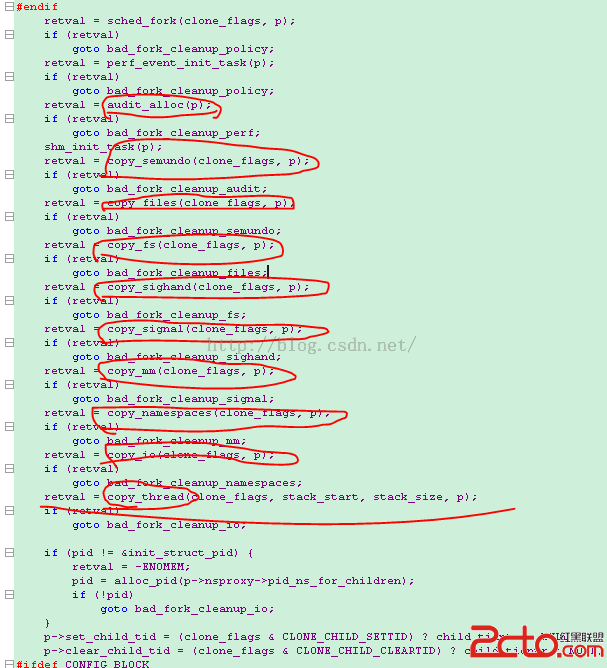
可以看到,內核先是將父進程的stask_struct中的內容不管三七二十一全都拷貝到子進程的stask_struct中了(這裡面大部分的內容都是和父進程一樣,只有少部分根據參數的不同稍作修改),每一個模塊拷貝結束後都進行了相應的檢查,看是否拷貝成功,如果失敗就跳到相應的出口處執行恢復操作。最後又執行了一個copy_thread(),
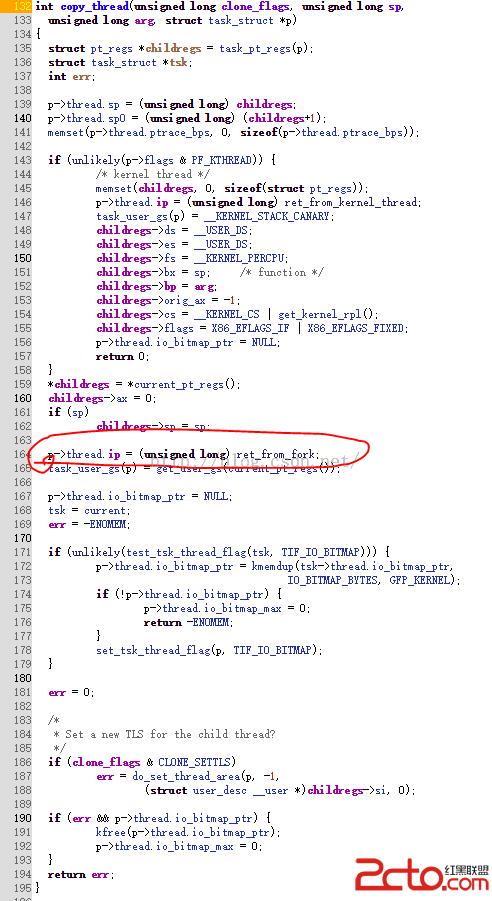
在copy_thread這個函數中做了兩件非常重要的事情:1、就是把子進程的 eax 賦值為 0,childregs->ax = 0,使得 fork 在子進程中返回 0;2、將子進程喚醒後執行的第一條指令定向到 ret_from_fork。所以這裡可以看到子進程的執行從ret_from_fork開始。
借來繼續看copy_process中的代碼。拷貝完父進程中的內容後,就要對子進程進行“個性化”,

從代碼也可以看出,這裡是對子進程中的其他成員進程初始化操作。然後就退出了copy_process,回到了do_fork()中。
再接著看一下do_fork()中“掃尾“工作是怎麼做的:
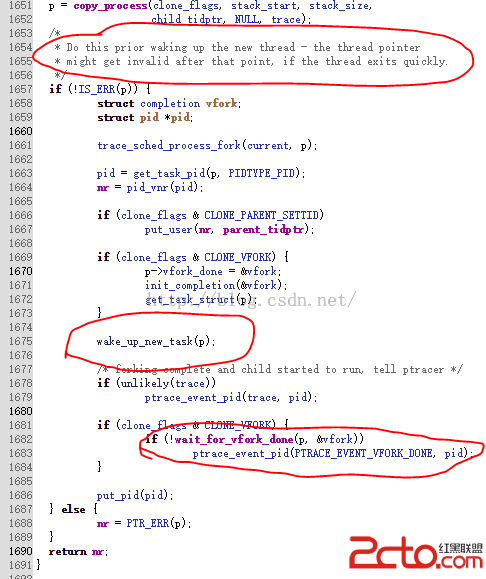
前面植根據參數做一些變量的修改,後面兩個操作比較重要,如果是通過fork() 創建子進程,那麼最後就直接將子進程喚醒,但是如果是通過vfork()來創建子進程,那麼就要通知父進程必須等子進程運行結束才能開始運行。
總結:
綜上所述:內核在創建一個新進程的時候,主要執行了一下任務:
1、父進程執行一個系統調用fork()或vfork();但最後都是通過調用do_fork()函數來操作,只不過fork(),vfork()傳遞給do_fork()的參數不同。
2、在do_fork()函數中,前面做參數檢查,後面負責喚醒子進程(如果是vfork則讓父進程等待),中間部分負責創建子進程和子進程的PCB的初始化,這些工作都在copy_process()中完成。
3、在copy_process()中先是例行的參數檢查和根據參數進行配置;然後是調用大量的copy_***** 函數將父進程task_struct中的內容拷貝到子進程的task_struct中,然後對於子進程與父進程之間不同的地方,在子進程中初始化或是清零。
4、完成子進程的創建和初始化後,將子進程喚醒,優先讓子進程先運行,因為如果讓父進程先運行的話,由於linux的寫時拷貝機制,父進程很可能會對數據進行寫操作,這時就需要拷貝數據段和代碼斷的內容了,但如果先執行子進程的話,子進程通常都會通過exec()轉去執行其他的任務,直接將新任務的數據和代碼拷過來就行了,而不需要像前面那樣先把父進程的數據代碼拷過來,然後拷新任務的代碼的時候又將其覆蓋掉。
5、執行完copy_process()後就回到了do_fork()中,接著父進程回到system_call中執行syscall_exit: 後面的代碼,而子進程則先從ret_from_fork: 處開始執行,然後在回到system_call 中去執行syscall_exit:.
ENTRY(ret_from_fork)
CFI_STARTPROC
pushl_cfi %eax
call schedule_tail
GET_THREAD_INFO(%ebp)
popl_cfi %eax
pushl_cfi $0x0202 # Reset kernel eflags
popfl_cfi
jmp syscall_exit
CFI_ENDPROC
END(ret_from_fork)
6、父進程和子進程最後都是通過system_call 的出口從內核空間回到用戶空間,回到用戶空間後,由於fork()函數對父子進程的返回值不同,所以根據返回值判斷出回來的是父進程還是子進程,然後分別執行不同的操作。