


ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, void *buf, size_t count);
以上兩個是linux下的兩個系統調用,用於對文件行基本的I/O操作。fd是非負文件描述符,其實相當於標識一個文件的唯一編號。默認標號0是標准輸入(終端輸入),1是標准輸出(終端輸出),2是標准錯誤。所以用戶通過 open 能夠打開的文件得到的文件描述符的最小編號是3。
在Linux中,read 和 write 是基本的系統級I/O函數。當用戶進程使用read 和 write 讀寫linux的文件時,進程會從用戶態進入內核態,通過I/O操作讀取文件中的數據。內核態(內核模式)和用戶態(用戶模式)是linux的一種機制,用於限制應用可以執行的指令和可訪問的地址空間,這通過設置某個控制寄存器的位來實現。進程處於用戶模式下,它不允許發起I/O操作,所以它必須通過系統調用進入內核模式才能對文件進行讀取。
從用戶模式切換到內核模式,主要的開銷是處理器要將返回地址(當前指令的下一條指令地址)和額外的處理器狀態(寄存器)壓入到棧中,這些數據到會被壓到內核棧而不是用戶棧。另外,一個進程使用系統調用還隱含了一點——調用系統調用的進程可能會被搶占。當內核代表用戶執行系統調用時,若該系統調用被阻塞,該進程就會進入休眠,然後由內核選擇一個就緒狀態,當前優先級最高的進程運行。另外,即使系統調用沒有被阻塞,當系統調用結束,從內核態返回時,若在系統調用期間出現了一個優先級更高的進程,則該進程會搶占使用了系統調用的進程。內核態返回會返回到優先級高的進程,而不是原本的進程。
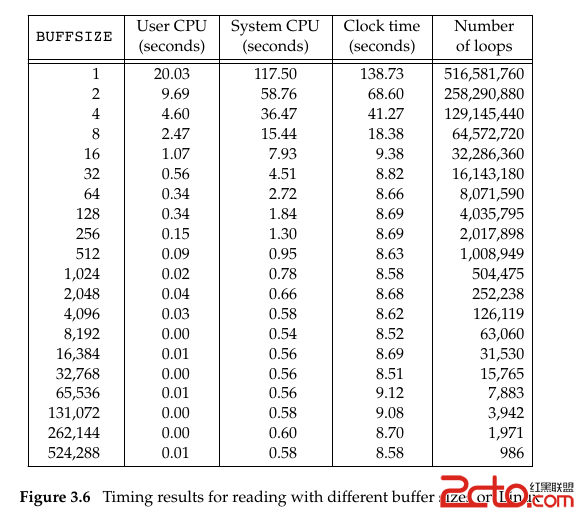
雖然我們可以每次進行讀寫時都使用系統調用,但這樣會增大系統的負擔。當一個進程需要頻繁調用 read 從文件中讀取數據時,它便要頻繁地在用戶態與內核態之間進行切換,極端點地設想一個情景,每次read調用都只讀取一個字節,然後循環調用read讀取n個字節,這便意味著進程要在用戶態和內核態之間切換n次,雖然這是一個及其愚蠢的編程方法,但能夠毫無疑問說明系統調用的開銷。下圖是調用read(int fd, void *buf, size_t count)讀取516,581,760字節,每次read可以讀取的最大字節數量(count的值)的不同對CPU的存取效率的影響。
 vcHL1+7Qoda1o6zWrrrzv+m089ChyPS8zND41Pa806OsU3lzdGVtIENQVcqxvOS89dChtcS3+bbIutzQoaOsyfXWwbu509DL+dT2vNOho9XiysfI9CBCVUZGU0laRSC5/bTzo6zG5Lu6s+XH+LHjv+fUvcHLsrvNrLXEv+mjrLW81sK05sih0KfCyr21tc2hozwvcD4NCjxoMiBpZD0="2rio包">2.RIO包
vcHL1+7Qoda1o6zWrrrzv+m089ChyPS8zND41Pa806OsU3lzdGVtIENQVcqxvOS89dChtcS3+bbIutzQoaOsyfXWwbu509DL+dT2vNOho9XiysfI9CBCVUZGU0laRSC5/bTzo6zG5Lu6s+XH+LHjv+fUvcHLsrvNrLXEv+mjrLW81sK05sih0KfCyr21tc2hozwvcD4NCjxoMiBpZD0="2rio包">2.RIO包
RIO,全稱 Robust I/O,即健壯的IO包。它提供了與系統I/O類似的函數接口,在讀取操作時,RIO包加入了讀緩沖區,一定程度上增加了程序的讀取效率。另外,帶緩沖的輸入函數是線程安全的,這與Stevens的 UNP 3rd Edition(中文版) P74 中介紹的那個輸入函數不同。UNP的那個版本的帶緩沖的輸入函數的緩沖區是以靜態全局變量存在,所以對於多線程來說是不可重入的。RIO包中有專門的數據結構為每一個文件描述符都分配了相應的獨立的讀緩沖區,這樣不同線程對不同文件描述符的讀訪問也就不會出現並發問題(然而若多線程同時讀同一個文件描述符則有可能發生並發訪問問題,需要利用鎖機制封鎖臨界區)。
另外,RIO還幫助我們處理了可修復的錯誤類型:EINTR。考慮read和write在阻塞時被某個信號中斷,在中斷前它們還未讀取/寫入任何字節,則這兩個系統調用便會返回-1表示錯誤,並將errno置為EINTR。這個錯誤是可以修復的,並且應該是對用戶透明的,用戶無需在意read 和 write有沒有被中斷,他們只需要直到read 和 write成功讀取/寫入了多少字節,所以在RIO的rio_read()和rio_write()中便對中斷進行了處理。
#define RIO_BUFSIZE 4096
typedef struct
{
int rio_fd; //與緩沖區綁定的文件描述符的編號
int rio_cnt; //緩沖區中還未讀取的字節數
char *rio_bufptr; //當前下一個未讀取字符的地址
char rio_buf[RIO_BUFSIZE];
}rio_t;
這個是rio的數據結構,通過rio_readinitb(rio_t *, int)可以將文件描述符與rio數據結構綁定起來。注意到這裡的rio_buf的大小是4096,這個參考了上圖,為linux中文件的塊大小。
void rio_readinitb(rio_t *rp, int fd)
/**
* @brief rio_readinitb rio_t 結構體初始化,並綁定文件描述符與緩沖區
*
* @param rp rio_t結構體
* @param fd 文件描述符
*/
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
return;
}
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
/**
* @brief rio_read RIO--Robust I/O包 底層讀取函數。當緩沖區數據充足時,此函數直接拷貝緩
* 沖區的數據給上層讀取函數;當緩沖區不足時,該函數通過系統調用
* 從文件中讀取最大數量的字節到緩沖區,再拷貝緩沖區數據給上層函數
*
* @param rp rio_t,裡面包含了文件描述符和其對應的緩沖區數據
* @param usrbuf 讀取的目的地址
* @param n 讀取的字節數量
*
* @returns 返回真正讀取到的字節數(<=n)
*/
{
int cnt;
while(rp->rio_cnt <= 0)
{
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));
if(rp->rio_cnt < 0)
{
if(errno != EINTR) //遇到中斷類型錯誤的話應該進行讀取,否則就返回錯誤
return -1;
}
else if(rp->rio_cnt == 0) //讀取到了EOF
return 0;
else
rp->rio_bufptr = rp->rio_buf; //重置bufptr指針,令其指向第一個未讀取字節,然後便退出循環
}
cnt = n;
if((size_t)rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, n);
rp->rio_bufptr += cnt; //讀取後需要更新指針
rp->rio_cnt -= cnt; //未讀取字節也會減少
return cnt;
}
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n)
/**
* @brief rio_readnb 供用戶使用的讀取函數。從緩沖區中讀取最大maxlen字節數據
*
* @param rp rio_t,文件描述符與其對應的緩沖區
* @param usrbuf void *, 目的地址
* @param n size_t, 用戶想要讀取的字節數量
*
* @returns 真正讀取到的字節數。讀到EOF返回0,讀取失敗返回-1。
*/
{
size_t leftcnt = n;
ssize_t nread;
char *buf = (char *)usrbuf;
while(leftcnt > 0)
{
if((nread = rio_read(rp, buf, n)) < 0)
{
if(errno == EINTR) //其實這裡可以不用判斷EINTR,rio_read()中已經對其處理了
nread = 0;
else
return -1;
}
leftcnt -= nread;
buf += nread;
}
return n-leftcnt;
}
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
/**
* @brief rio_readlineb 讀取一行的數據,遇到'\n'結尾代表一行
*
* @param rp rio_t包
* @param usrbuf 用戶地址,即目的地址
* @param maxlen size_t, 一行最大的長度。若一行數據超過最大長度,則以'\0'截斷
*
* @returns 真正讀取到的字符數量
*/
{
size_t n;
int rd;
char c, *bufp = (char *)usrbuf;
for(n=1; n 0)
{
if((nwritten = write(fd, bufp, nleft)) <= 0)
{
if(errno == EINTR)
nwritten = 0;
else
return -1;
}
bufp += nwritten;
nleft -= nwritten;
}
return n;
}
以上便是rio的基本輸入輸出函數。注意到rio_writen(int fd, void *, size_t)代表文件描述符的參數是int類型,而不是rio_t類型。因為rio_writen不需要寫緩沖。這是為什麼呢?按道理來說,既然我們為read封裝的rio_readn提供了緩沖區,為什麼不也為write提供一個有緩沖的rio_writen函數呢?
試想一個場景,你正在寫一個http的請求報文,然後將這個報文寫入了對應socket的文件描述符的緩沖區,假設緩沖區大小為8K,該請求報文大小為1K。那麼,如果緩沖區被設置為被填滿才會自動將其真正寫入文件(而且一般也是這樣做的),那就是說如果沒有提供一個刷新緩沖區的函數手動刷新,我還需要額外發送7K的數據將緩沖區填滿,這個請求報文才能真正被寫入到socket當中。所以,一般帶有緩沖區的函數庫都會一個刷新緩沖區的函數,用於將在緩沖區的數據真正寫入文件當中,即使緩沖區沒有被填滿,而這也是C標准庫的做法。然而,如果一個程序員一不小心忘記在寫入操作完成後手動刷新,那麼該數據(請求報文)便一直駐留在緩沖區,而你的進程還在傻傻地等待響應。
絕大部分的系統都提供了C接口的標准IO庫,與RIO包相比,標准IO庫有更加健全的,帶緩沖的並且支持格式化輸入輸出。標准IO和RIO包都是利用read, write等系統調用實現的(在windows等非Unix標准的系統則有其他對應的調用)。既然已經存在一個健全的,帶緩沖的IO借口,那為什麼還需要上述的RIO包呢? 正是標准IO的緩沖機制對文件描述符的讀寫產生了一點負面影響,如果程序員忽略這些問題,那麼在對網絡套接字進行讀寫操作時就會出現很大的問題。
標准IO操作的對象與Unix I/O的不太相同,標准IO接口的操作對象是圍繞流(stream)進行的。當使用標准I/O接口打開或創建一個文件時,我們令一個流和一個文件相關聯。在默認的情況下,使用標准IO打開的文件流是帶有緩沖的(或許是全緩沖,或許是行緩沖)。這樣,在使用fputs等輸出函數時,數據會先被寫入文件流的緩沖區中,等到緩沖滿才真正將數據寫入文件。當FILE *fopen(const char *path, const char *mode);中的參數mode以讀和寫類型(r+,w+,a+等)打開文件時,具有如下限制:
- 如果中間沒有fflush, fseek, fsetpo 或rewind,則在輸出的後面不能直接跟隨輸入。
- 如果中間沒有fseek, fsetpos或 rewind,或者一個輸入操作沒有達到文件尾端,則在輸入操作之後不能直接跟隨輸入。
在Ubuntu15.10 x64中,經過測試,對於普通文件(非socket)的操作,似乎不遵守這個規則讀寫也正常。然而,為了程序的可移植性和健壯性,依然建議遵守標准的規定編程。
man fopen 中的一段話:
If this condition is not met, then a read is allowed to return
the result of writes other than the most recent.) Therefore it is good
practice (and indeed sometimes necessary under Linux) to put an
seek(3) or fgetpos(3) operation between write and read operations on
such a stream. This operation may be an apparent no-op (as in
fseek(…, 0L, SEEK_CUR) called for its synchronizing side effect).
在網絡套接字的編程中,對套接字使用lseek函數是非法的,而fseek,fsetpos和rewind都是通過lseek函數重置當前的文件位置,所以對於套接字來說,可使用的便只有fflush函數,這個函數的作用是刷新緩沖區,將緩沖區中的數據真正寫入文件中。
所以,對於大多數應用程序而言,標准IO更簡單,是優於Unix I/O的選擇。然而在網絡套接字的編程中,建議不要使用標准IO函數進行操作,而要使用健壯的RIO函數。RIO函數提供了帶緩沖的讀操作,與無緩沖的寫操作(對於套接字來說不需要),且是線程安全的。通過RIO包的學習,理解底層Unix I/O的實現也能更好避免在使用上層IO接口中犯錯。
參考書籍:
《深入理解計算機系統》
《Unix網絡編程卷1第三版》
《Unix高級編程第二版》