


作者:金戈
本文是高性能集群系列文章的第三部分。在本文中,筆者以IBM eServer Cluster 1300為例介紹了Beowulf集群中硬件和網絡體系結構和組成部分。
1 Beowulf集群軟件結構
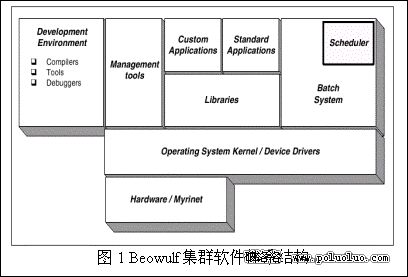
圖1 是Beowulf集群的軟件體系機構。一般來說,Beowulf集群由如下幾個軟件部分組成:
操作系統:勿容置疑,操作系統是任何計算機系統的軟件基礎。相對於桌面系統而言,集群系統對操作系統的任務調度和文件管理方面的要求更高。
並行開發庫:只要是指用於集群中進程通信的軟件庫。消息傳遞和線程是兩種基本的通信方法。但是對於Beowulf集群而言,消息傳遞更適合一些。Beowulf集群常用的開發庫是MPI和PVM。
作業管理:調度作業並管理集群系統的資源,是集群系統的資源得到最大的利用。
系統管理:管理和監控整個集群系統。
開發環境:開發和調試高效能應用的開發工具。
標准應用:一些標准的高性能應用如CFD。
客戶應用:客戶特別定制的應用。
2 操作系統
並不是每種操作系統都適合高性能集群系統。理論上說,硬件的體系結構、操作系統的任務調度方式和IPC的方式是決定應用並行化效果的主要因素。根據這三個因素,我們可以歸納出如下5種實施應用並行化的平台:
單任務操作系統:CPU同時只處理任務隊列中的一個任務。MS DOS是這類系統的代表。
多任務操作系統:基於分時技術的多任務操作系統。雖然在同一時間段,所有的進程都在運行,但是在某一時間點,CPU只執行一個進程。這類操作系統可分為搶占式和非搶占式。單CPU的Unix和NT屬於這種類型。
多CPU多任務操作系統:和單CPU的多任務操作系統不同的是,由於有多個CPU,所以在某個時間點上,可以有多個進程同時運行。多CPU的Unix和NT屬於這種類型。
多CPU多任務操作系統+線程:某些任務當把它分為若干並行的子任務同時在多個CPU上執行時,它會運行的更快,盡管運行這個任務占有的總CPU時間變長了。由於采用多個CPU而使任務結束的時間縮短了。由於應用本身的特性,隨著CPU個數的增加,性能並不會線性增加。Amdal法則說明了這種情況。運行在同一主板上多個CPU的Unix和NT+線程屬於這一類型。SMP系統合適采用這種方法。
多CPU多任務操作系統+消息傳遞:在SMP系統中,由於采用共享內存,所以CPU通信的時間幾乎可以忽略。但是在象集群這種系統中,通信時間成為不得不考慮的因素。這時,使用線程是一種很奢侈的方法。這種情況下,消息傳遞是一種比較好的方法。(本系列文章的第二部分解釋了這種情況)。同一個主板或多個主板上的多個CPU+Unix和NT+消息傳遞屬於這種類型。
Beowulf集群使用第5種類型平台。它可以由SMP和PC服務器組成,以Linux為操作系統,以MPI或PVM這種消息傳遞方式作為通信方法。
3 文件系統
文件系統是操作系統的重要組成部分,用於存儲程序和數據。如何在各節點間高效、一致和簡捷的實現數據共享是集群系統對文件系統提出的挑戰。
3.1 集群和文件系統
很明顯,那種僅能管理本地存儲的文件系統(如EXT和FAT)是無法滿足集群系統對文件共享的要求的。在集群環境下,最容易想到,也是最容易實現的文件系統就是分布式文件系統。相當於本地文件系統,分布式文件系統有如下優點:
網絡透明:對遠程和本地的文件訪問可以通過相同的系統調用完成。
位置透明:文件的全路徑無需和文件存儲的服務綁定,也就是說服務器的名稱或地址並不是文件路徑的一部分。
位置獨立:正是由於服務器的名稱或地址並不是文件路徑的一部分,所以文件存儲的位置的改變並不會導致文件的路徑改變。
分布式文件系統可以使集群的節點間簡捷地實現共享。但是為了提供性能,分布式文件系統通常需要使用本地的緩存(Cache), 所以它很難保證數據在集群系統范圍的一致性。而且往往分布式文件系統中只有一份數據,所以很容易發生單點失效。
建立在共享磁盤(Share-Disk)上的並行文件系統可以克服分布式文件系統的這些缺點。通過使用在節點共享的存儲設備,並行文件系統具有很多優點:
高可用性:克服了分布式文件系統中那種服務器端的單點失效的缺點,提高了文件系統的可用性。
負載均衡:有多個訪問點,彼此可以協調負載。
可擴展性:容易擴展容量和訪問的帶寬
3.2 集群中的數據共享形式
下面通過給出幾個集群中使用具體的數據共享的方法。其中rsync是建立在本地文件系統之上,NFS和Inteemezzo屬於分布式文件系統(確切的說,NFS只是網絡文件系統),GFS屬於並行文件系統,而Backend-database則屬於不同於文件共享的另一種形式的共享。 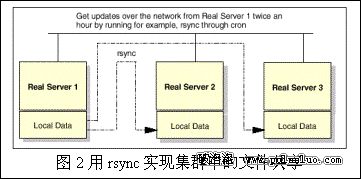
3.2.1 rsync
rsync是一種簡單的文件共享實現方式。集群中的每個節點都有一份數據復本,復本間使用rsync進行同步。因為節點需要的數據就在本地,所以這種方法具有很高的可用性,不會出現單點失效現象。
如果需要的共享的數據量很小,而且很少更新時,可以采用這種方式。靜態網頁和小的FTP站點的可以使用這種共享方式。
3.2.2 NFS
這也是一種容易實現的方式。存儲節點通過NFS將自己本地的文件輸出,其他節點則把存儲節點輸出的文件系統mount到本地文件系統。NFS方式的存在兩個很大的缺點:
性能差:因為所有的文件訪問都必須經過網絡和NFS服務器,所以在訪問流量比較大的情況下,網絡帶寬和NFS服務器都會成為系統的瓶頸。
單點失效:如果NFS服務器的系統失效或者網絡失效都會使得其他節點無法得到數據,從而使整個集群系統癱瘓。
當然使用多個互為備份的NFS服務器可以改善性能和避免單點失效,但是這樣又會帶來如何實時保持備份服務器間數據一致性的問題。 NFS方式適合於共享訪問數據量不大的小型集群系統。
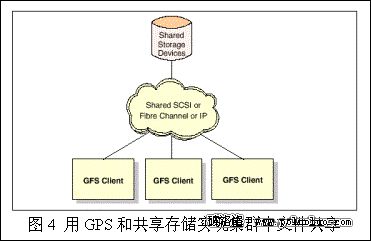
3.2.3 GFS
GFS(Global File System)實現了存儲設備的網絡共享。這些存儲設備可以是共享SCSI(Shared SCSI)和共享通道(Fibre Channel - FC)。GFS包裝這些存儲設備使得它們好像節點本地的文件系統。GFS的主要優點在於:
高可用性:如果一個GFS客戶失效,數據還可以通過其他GFS客戶訪問。
擴展性:因為不需要中心服務器,所有很容易擴展存儲容量和訪問帶寬。
GFS可以將物理上分離的存儲設備虛擬為一個存儲而且能平衡訪問負載。GFS還實現了文件鎖和實時文件系統。
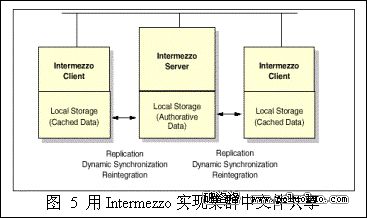
3.2.4 Intermezzo
Intermezzo實現了一個分布式的文件系統。它采用客戶/服務器模式。服務器擁有權威的數據,客戶節點僅有本地緩沖的版本。它們通過普通的網絡進行同步。Intermezzo支持斷開連接下文件操作。在下次恢復連接時,它會集成本地的改動到服務器上。Intermezzo擁有象GFS一樣的可用性和可擴展性。但是它無法保證數據的實時一致性。
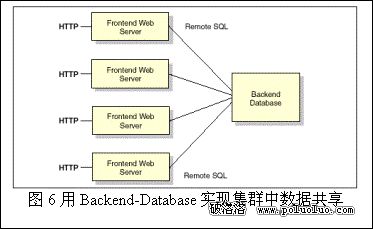
3.2.5 Backend Database
基於後端數據庫的共享是完全不同於文件共享的方式。後端數據庫系統解決了數據的一致性、性能、可用性和可擴展性問題。但是數據庫的訪問方法要比文件訪問復雜的多。
4 並行化應用程序
並行化應用程序,使其更高效的運行是使用Beowulf集群系統的最終目的。一般說,並行化應用程序分為三個步驟:
確定應用程序的並發部分
估計並行的效率
實現應用程序的並發
在並行化應用程序的過程中,需要開發環境、並行開發庫和各種工具的支持。這些軟件都是Beowulf集群軟件體系結構中重要的組成部分。
4.1 確定應用程序的並發部分
從實用的角度說,應用程序有兩種類型的並發:計算和I/O。盡管在多數情況下這兩者是正交的,但是也存在一些應用同時需要這兩種並發性。有一些工具可以用來幫助分析應用程序的並發,而且通常這些工具都是專門為Fortran設計的。
4.2 分析並行的效率
分析並行的效率是並行化應用程序中很重要的一個步驟。正確的分析並行的效率可以幫助你在有限的經費下最大化應用的執行效率。往往Beowulf集群的需要和應用的需要有些許的差別。比如,CPU消耗型的應用往往需要的是稍微快一點的CPU和高速低延遲的網絡,而I/O消耗型的應用需要的是稍微慢一點的CPU和快速以太網。
如果沒有分析工具,你只能使用猜測和估計的辦法完成這一步驟。一般來說,如果在應用的一部分中,計算的時間是分鐘級而數據傳輸的時間是秒級,那麼這一部分可以並行執行。但是如果並行後計算時間降到秒級,你就需要實際測量一下再做權衡。
另外,對於I/O消耗型的應用,Eadline-Dedkov法則對你做決定有些幫助:如果兩個並行系統具有相同的CPU指標,慢CPU和相應具有低速CPU間通信網絡的系統反而具有較好的性能。
4.3 實現應用程序的並發
有兩種方法去實現應用程序的並發:顯式並發和隱式並發。
4.3.1 顯式並行化
顯式並行化是指由開發者決定程序的並行。開發者通過在程序中增加PVM或MPI消息,或者增加程序執行的線程從而達到程序的並行化。顯式並行化通常難以實現和調試。為了簡化顯式並行化,某些開發庫中增加了一些函數用於簡化標准並行方法的實現