cgroup是control group的簡稱,它為Linux內核提供了一種任務聚集和劃分的機制,通過一組參數集合將一些任務組織成一個或多個子系統。
Cgroups是control groups的縮寫,最初由Google工程師提出,後來編進linux內核。
Cgroups是實現IaaS虛擬化(kvm、lxc等),PaaS容器沙箱(Docker等)的資源管理控制部分的底層基礎
子系統是根據cgroup對任務的劃分功能將任務按照一種指定的屬性劃分成的一個組,主要用來實現資源的控制。在cgroup中, 劃分成的任務組以層次結構的形式組織,多個子系統形成一個數據結構中類似多根樹的結構。cgroup包含了多個孤立的子系統,每一個子系統代表單一的資 源,目前,redhat默認支持10個子系統,但默認只掛載了8個子系統,ubuntu 12.04 默認支持8個子系統,但默認只掛載了5個子系統。
當然也用戶可以自定義子系統並進行掛載。
下面對每一個子系統進行簡單的介紹:
blkio 設置限制每個塊設備的輸入輸出控制。例如:磁盤,光盤以及usb等等。
cpu 使用調度程序為cgroup任務提供cpu的訪問。
cpuacct 產生cgroup任務的cpu資源報告。
cpuset 如果是多核心的cpu,這個子系統會為cgroup任務分配單獨的cpu和內存。
devices 允許或拒絕cgroup任務對設備的訪問。
freezer 暫停和恢復cgroup任務。
memory 設置每個cgroup的內存限制以及產生內存資源報告。
net_cls 標記每個網絡包以供cgroup方便使用。
ns 名稱空間子系統。
perf_event 增加了對每group的監測跟蹤的能力,即可以監測屬於某個特定的group的所有線程以及 運行在特定CPU上的線程,此功能對於監測整個group非常有用,具體參見 http://lwn.net/Articles/421574/
以CentOS 6為例
yum install libcgroup
service cgconfig start #開啟cgroups服務
chkconfig cgconfig on #開機啟動
[root@localhost /]# ls /cgroup/ blkio cpu cpuacct cpuset devices freezer memory net_cls
cgroup啟動時,會讀取配置文件/etc/cgconfig.conf的內容,根據其內容創建和掛載指定的cgroup子系統。
/etc/cgconfig.conf是cgroup配置工具libcgroup用來進行cgroup組的定義,參數設定以及掛載點定義的配置文件,
主要由mount和group兩個section構成。
(1)mount section的語法格式如下:
mount {
<controller> = <path>;
...
}
#########################################
# controller:內核子系統的名稱
# path:該子系統的掛載點
#########################################
舉個例子:
mount {
cpuset = /cgroup/red;
}
上面定義相當於如下shell指令:
mkdir /cgroup/red
mount -t cgroup -o cpuset red /cgroup/red
(2)group section的語法格式如下:
group <name> {
[<permissions>]
<controller> {
<param name> = <param value>;
…
}
…
}
################################################################################
## name: 指定cgroup的名稱
## permissions:可選項,指定cgroup對應的掛載點文件系統的權限,root用戶擁有所有權限。
## controller:子系統的名稱
## param name 和 param value:子系統的屬性及其屬性值
#################################################################################
舉個例子:
mount { ## 定義需要創建的cgroup子系統及其掛載點,這裡創建cpu與cpuacct(統計)兩個cgroup子系統
cpu = /mnt/cgroups/cpu;
cpuacct = /mnt/cgroups/cpu;
}
group daemons/www { ## 定義daemons/www(web服務器進程)組
perm { ## 定義這個組的權限
task {
uid = root;
gid = webmaster;
}
admin {
uid = root;
gid = root;
}
}
cpu { ## 定義cpu子系統的屬性及其值,即屬於詞組的任務的權重為1000
cpu.shares = 1000;
}
}
group daemons/ftp { ## 定義daemons/ftp(ftp進程)組
perm {
task {
uid = root;
gid = ftpmaster;
}
admin {
uid = root;
gid = root;
}
}
cpu { ## 定義詞組的任務的權重為500
cpu.shares = 500;
}
}
上面配置文件定義相當於執行了如下shell命令:
mkdir /mnt/cgroups/cpu
mount -t cgroup -o cpu,cpuacct cpu /mnt/cgroups/cpu
mkdir /mnt/cgroups/cpu/daemons
mkdir /mnt/cgroups/cpu/daemons/www
chown root:root /mnt/cgroups/cpu/daemons/www/*
chown root:webmaster /mnt/cgroups/cpu/daemons/www/tasks
echo 1000 > /mnt/cgroups/cpu/daemons/www/cpu.shares
mkdir /mnt/cgroups/cpu/daemons/ftp
chown root:root /mnt/cgroups/cpu/daemons/ftp/*
chown root:ftpmaster /mnt/cgroups/cpu/daemons/ftp/tasks
echo 500 > /mnt/cgroups/cpu/daemons/ftp/cpu.shares
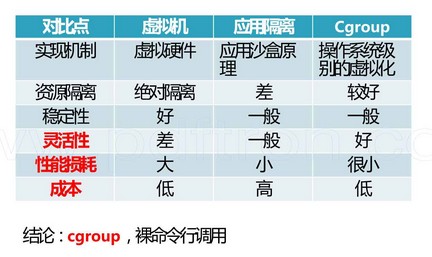
對於虛擬機VM,應用沙盒,cgroups技術選型比較
跑一個耗cpu的腳本
x=0
while [ True ];do
x=$x+1
done;
top可以看到這個腳本基本占了100%的cpu資源
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30142 root 20 0 104m 2520 1024 R 99.7 0.1 14:38.97 sh
下面用cgroups控制這個進程的cpu資源
mkdir -p /cgroup/cpu/foo/ #新建一個控制組foo
echo 50000 > /cgroup/cpu/foo/cpu.cfs_quota_us #將cpu.cfs_quota_us設為50000,相對於cpu.cfs_period_us的100000是50%
echo 30142 > /cgroup/cpu/foo/tasks
然後top的實時統計數據如下,cpu占用率將近50%,看來cgroups關於cpu的控制起了效果
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 30142 root 20 0 105m 2884 1024 R 49.4 0.2 23:32.53 sh
cpu控制組foo下面還有其他的控制,還可以做更多其他的關於cpu的控制
[root@localhost ~]# ls /cgroup/cpu/foo/
cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat notify_on_release tasks
跑一個耗內存的腳本,內存不斷增長
x="a"
while [ True ];do
x=$x$x
done;
top看內存占用穩步上升
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 30215 root 20 0 871m 501m 1036 R 99.8 26.7 0:38.69 sh
30215 root 20 0 1639m 721m 1036 R 98.7 38.4 1:03.99 sh
30215 root 20 0 1639m 929m 1036 R 98.6 49.5 1:13.73 sh
下面用cgroups控制這個進程的內存資源
mkdir -p /cgroup/memory/foo
echo 1048576 > /cgroup/memory/foo/memory.limit_in_bytes #分配1MB的內存給這個控制組
echo 30215 > /cgroup/memory/foo/tasks
發現之前的腳本被kill掉
[root@localhost ~]# sh /home/memory.sh
已殺死
因為這是強硬的限制內存,當進程試圖占用的內存超過了cgroups的限制,會觸發out of memory,導致進程被kill掉。
實際情況中對進程的內存使用會有一個預估,然後會給這個進程的限制超配50%比如,除非發生內存洩露等異常情況,才會因為cgroups的限制被kill掉。
也可以通過配置關掉cgroups oom kill進程,通過memory.oom_control來實現(oom_kill_disable 1),但是盡管進程不會被直接殺死,但進程也進入了休眠狀態,無法繼續執行,仍讓無法服務。
關於內存的控制,還有以下配置文件,關於虛擬內存的控制,以及權值比重式的內存控制等
[root@localhost /]# ls /cgroup/memory/foo/
cgroup.event_control memory.force_empty memory.memsw.failcnt
memory.memsw.usage_in_bytes memory.soft_limit_in_bytes memory.usage_in_bytes tasks
cgroup.procs memory.limit_in_bytes memory.memsw.limit_in_bytes
memory.move_charge_at_immigrate memory.stat memory.use_hierarchy
memory.failcnt memory.max_usage_in_bytes memory.memsw.max_usage_in_bytes
memory.oom_control memory.swappiness notify_on_release
跑一個耗io的腳本
dd if=/dev/sda of=/dev/null &
通過iotop看io占用情況,磁盤速度到了284M/s
30252 be/4 root 284.71 M/s 0.00 B/s 0.00 % 0.00 % dd if=/dev/sda of=/dev/null
下面用cgroups控制這個進程的io資源
mkdir -p /cgroup/blkio/foo
echo '8:0 1048576' > /cgroup/blkio/foo/blkio.throttle.read_bps_device
#8:0對應主設備號和副設備號,可以通過ls -l /dev/sda查看
echo 30252 > /cgroup/blkio/foo/tasks
再通過iotop看,確實將讀速度降到了1M/s
30252 be/4 root 993.36 K/s 0.00 B/s 0.00 % 0.00 % dd if=/dev/sda of=/dev/null
對於io還有很多其他可以控制層面和方式,如下
[root@localhost ~]# ls /cgroup/blkio/foo/
blkio.io_merged blkio.io_serviced blkio.reset_stats
blkio.throttle.io_serviced blkio.throttle.write_bps_device blkio.weight cgroup.procs
blkio.io_queued blkio.io_service_time blkio.sectors
blkio.throttle.read_bps_device blkio.throttle.write_iops_device blkio.weight_device notify_on_release
blkio.io_service_bytes blkio.io_wait_time blkio.throttle.io_service_bytes
blkio.throttle.read_iops_device blkio.time cgroup.event_control tasks