HAProxy 的 1.5.11 版本不支持重啟或重新加載配置時的零停機時間。相反,它支持快速重載——當一個新的 HAProxy 實例啟動時,它嘗試使用 SO_REUSEPORT 去綁定老 HAProxy 監聽的相同端口並給老 HAProxy 實例發送信號去關閉。這種技術非常接近現代 Linux 內核的零停機時間,但這仍舊會經歷一個短暫的時隙——當兩個進程都綁定到端口時。在這個關鍵的時隙中,由於Linux內核自身(丟棄)處理多個接受進程的方式可能有流量會被丟掉。特別要提出來的,這個問題會潛在導致從 HAProxy 過來的新連接有一個 RST。這個問題是 SYN 包在老 HAProxy 被調用關閉前會被先放進其套接字隊列中,這導致了這些連接的 RST。
這個問題有許多解決辦法。例如,Willy Tarreau,HAProxy 的主要維護者,建議用戶在重啟 HAProxy 時丟掉 SYN 包,利用 TCP 的自動修復。不幸的是,RFC 6298 規定的初始 SYN 的超時時間是1s,Linux 內核堅守此規定。 因此,丟棄 SYN 意味著任何試圖在 HAProxy 加載的 20-50ms 之間重建的連接將會遭受一個額外的秒級或更長的延遲。確切的時間依賴於客戶端的 TCP 實現,而一些移動設備重試時間為 200ms,很多設備只在 3S 後重試。鑒於 HAProxy 重載的次數和和 Yelp 的流量,這成為了我們服務可靠性的一個障礙。
為了避免延遲,我們采用了Willy提議的方案。他的方案實際上在不丟棄數據包上表現很好,但是額外的一秒延時是個問題。我們更好的解決方案是延遲 SYN包直到重載已經完成,因為這樣做只會對新的連接產生HAProxy重載所需要的延遲。 為了實現這種方案,我們求助於Linux隊列原則 (qdiscs)。Linux隊列原則是用來管理Linux內核處理網絡數據包的方式。具體地說就是你可以控制數據包是如何入隊和出隊,這提供了速率限 制,優先或指定輸出數據包的能力。有關更多qdiscs的詳情, 我極力推薦lartc howto以及相關的man頁面。
我們的一個SRE(網站可靠性工程師),Josh Snyder花了一些晚上的時間閱讀了Linux內核源代碼,發現了一個文檔記錄很少的工具:plug排隊原則(qdisc),qdisc是從Linux 3.4以來就存在了。使用plug qdisc和以下標准Linux技術, 我們可以實現HAProxy重載零宕機:
tc:Linux流量控制。這使我們能夠建立基於過濾器路由連接的排隊規則。在最新的Linux版本上自帶libnlutils,它提供了一些較新的qdiscs接口(如plug qdisc)。
iptables:用於包過濾和NAT(網絡地址轉換)的Linux工具。這個工具允許我們標識進入的SYN包。
SmartStack客戶端連接到loopback接口向HAProxy請求,HAProxy幸好將進入的包變成為輸出包。這意味著我們可以在loopback接口上建立如圖1的隊列原則。
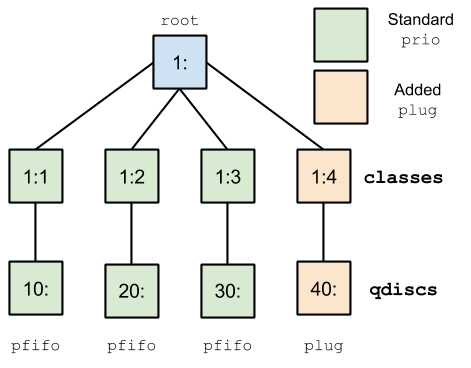
Figure 1: Queueing Discipline
該設置的一個分類實現了使用 prio qdisc 隊列規定的標准 pfifo_fast, 但只是使用了第四個“plug“通道。plug qdisc 並沒有使他們退出隊列,而是擁有隊列數據包的性能。與一個 iptables 命令相結合的性能來允許我們在整個 HAProxy 重載期間重新定向,然後拔掉後重載的 SYN 插頭的數據包。該控鍵(‘1:1’, ‘30:’等等)是允許我們一起連接 qdiscs,並且使用過濾器發送特定 qdiscs 的數據包。有關更多的信息,請查閱 lartc howto上面所引用的。
然後,我們把我們調用 qdisc_tool 的這個功能編進腳本。該工具允許我們的基礎設施“保護”HAProxy 重載我們 plug 流量,重啟haproxy,然後松開這個插頭,交付延遲所有的 SYN 數據包。這個調用看起來像:
qdisc_tool protect <normal HAProxy reload command>
由 GitHub 托管的 qdisc 命令
我們可以輕易地在諸如 Ubuntu Trusty 的 linux 發行版本上使用標准的用戶空間實用工具來復制該技術。如果你的設置並沒有 nl-qdisc-add,但有3.4+ Linux 內核,那麼你可以通過 netlink 來手動地操縱該插頭。
在我們優雅重載HAProxy之前,我們必須先使用tc和nl-qdisc-add設置上面提到的隊列規則。注意下面的每個命令必須以root運行。
# Set up the queuing discipline tc qdisc add dev lo root handle 1: prio bands 4 tc qdisc add dev lo parent 1:1 handle 10: pfifo limit 1000 tc qdisc add dev lo parent 1:2 handle 20: pfifo limit 1000 tc qdisc add dev lo parent 1:3 handle 30: pfifo limit 1000 # Create a plug qdisc with 1 meg of buffer nl-qdisc-add --dev=lo --parent=1:4 --id=40: plug --limit 1048576 # Release the plug nl-qdisc-add --dev=lo --parent=1:4 --id=40: --update plug --release-indefinite # Set up the filter, any packet marked with “1” will be # directed to the plug tc filter add dev lo protocol ip parent 1:0 prio 1 handle 1 fw classid 1:4
setup_qdisc.sh 在 GitHub 上
我們希望所有的 SYN 包被路由到塞入通道,這我們可以通過 iptables 實現。我們使用一個本地鏈路地址,以便我們在重載時重定向我們想要的流量,客戶如果希望避免塞入可以生成一個請求到127.0.0.1,這是一直可用的一 個選項。請注意,這是假設你已經建立了一個連接到 169.254.255.254的本地鏈路。
iptables -t mangle -I OUTPUT -p tcp -s 169.254.255.254 --syn -j MARK --set-mark 1
setup_iptables.sh 在 GitHub 上
一旦一切都成立,我們優雅重載 HAProxy 所需要做的是:在重載前緩存 SYN,重載,然後在重載後釋放所有 SYN。這將導致任何嘗試在重啟過程中嘗試建立的連接經歷一個延遲,這個延遲等於 HAProxy 重啟時間。
nl-qdisc-add --dev=lo --parent=1:4 --id=40: --update plug --buffer service haproxy reload nl-qdisc-add --dev=lo --parent=1:4 --id=40: --update plug --release-indefinite
plug_manipulation.sh 在 GitHub 上
在生產中我們觀察到這項技術對重啟過程中的新進連接增加了約 20ms 的延遲,但沒有請求被丟棄。
這個設計具有一定的優點和缺點。最大的缺點是其只針對傳出連接而不針對傳入的流量。其原因是隊列規則在 Linux 上的工作方式,既你只能對傳出的流量整形。而對於傳入的流量,首先必須重定向到一個中介接口,然後再對中介接口的傳出流量進行整形。我們正在研究類似的集 成解決方案以應用在我們外部的負載均衡器中,但尚未投入生產環境。
此外,qdiscs 也應該調整地更有效。例如,我們以第一優先級將 qdisc 塞入,並調整 priomap 從而確保 SYN 包總是先於其他包被處理,或者調整 pfifo/qdiscs 的緩沖器大小。我認為這些可以在非環回口的接口上應用,塞入插件必須在第一優先級以確保 SYN 的輸送能力。
我們決定采用這種解決方案而不是 huptime, 修改傳遞到 HAProxy 的文件描述符,或在多個本地HAProxy 實例之間跳轉的原因是因為我們認為采用 qdisc 方案的風險是最低的。huptime 被很快地排除,因為由於一個老的 libc 版本,我們無法讓它在我們的機器上運行正常,並且我們也不確定LD_PRELOAD 機制是否會在一些復雜如 HAProxy 上工作。一個工程師在一個黑客馬拉松上概念驗證式地實施了文件描述符補丁,但是補丁的復雜性以及有可能引入大量分叉促使我們放棄了這個想法。它表明合理地 文件描述符傳遞真的是困難的。 在這三種方案裡面,我們最嚴肅地考慮過在同一台機器上運行多個 HAProxy 實例,使用 NAT,nginx 或另一個 HAProxy 實例來做切換。最終我們否決了這種方案因為有許多的實施不確定因素,以及基礎架構的維護等級。
使用我們的解決方案,我們基本保持零基礎設施,相信 Linux 內核和 HAProxy 可以處理。這幾個月裡, 這個方案一直在生產環境運行,我們沒有發現任何問題,這種方案沒有辜負我們的信任。
為了證明這個解決方案確實有效,我們可以啟動一個nginx HTTP後端,與此同時HAProxy作為前端,Apache Benchmark產生很多流量,當我們重啟HAProxy的時候,我們來看看發生了什麼。我們可以用這種方式評估不同的解決方案。
所有的測試都是在一個新的c3.large AWS機器上用Ubuntu Trusty和3.13 Linux內核進行的。HAProxy 1.5.11被編譯在本地,用TARGET=linux2628(編譯命令)。Nginx使用默認配置方式啟動,並在8001端口進行監聽,服務器發送一 個簡單的“pong”回答用來代替默認的html。我們編譯HAProxy的基本配置,它有一個單獨的後端,端口是8001,與之對應的前端端口是16000。
在這個實驗裡,我們僅僅重啟HAProxy,使用‘-sf’選項,它會以最快速度進行重啟處理。這是一個不那麼真實的測試,因為我們每100ms重啟一次HAProxy,但是這個實驗可以說明這一點(解決方案是否有效)。
# Restart haproxy every 100ms while [ 1 ]; do ./haproxy -f /tmp/haproxy.cfg -p /tmp/haproxy.pid -sf $(cat /tmp/haproxy.pid) sleep 0.1 done
reload_experiment.sh 在 GitHub 上
$ ab -c 10 -n 10000 169.254.255.254:16000/ Benchmarking 169.254.255.254 (be patient) ... apr_socket_recv: Connection reset by peer (104) Total of 3652 requests completed
重加載結果托管在 GitHub 上
socket 重置了!重啟HAProxy已經導致了失敗請求,即便我們的後端是正常的。下面讓我們告訴Apache基准測試器來繼續接受錯誤並生成更多的請求:
$ ab -r -c 10 -n 200000 169.254.255.254:16000/ Benchmarking 169.254.255.254 (be patient) ... Complete requests: 200000 Failed requests: 504 ... 50% 2 95% 2 99% 3 100% 15 (longest request)
reload_longer_result 托管在 GitHub 上
只有 0.25% 的請求失敗。這也不是太壞,但仍高於我們 0 的目標。
現在讓我們嘗試下丟掉 SYN 包的方法。這個方法可以以高的重啟速率以達到重試連接的效果,為得到可靠的結果我每秒重啟一次 HAProxy。
# Restart haproxy every second while [ 1 ]; do sudo iptables -I INPUT -p tcp --dport 16000 --syn -j DROP sleep 0.2 ./haproxy -f /tmp/haproxy.cfg -p /tmp/haproxy.pid -sf $(cat /tmp/haproxy.pid) sudo iptables -D INPUT -p tcp --dport 16000 --syn -j DROP sleep 1 done
iptables_experiment.sh 托管在 GitHub
$ ab -c 10 -n 200000 169.254.255.254:16000/ Benchmarking 169.254.255.254 (be patient) ... Complete requests: 200000 Failed requests: 0 ... 50% 2 95% 2 99% 6 100% 1002 (longest request)
iptables_result托管在GitHub
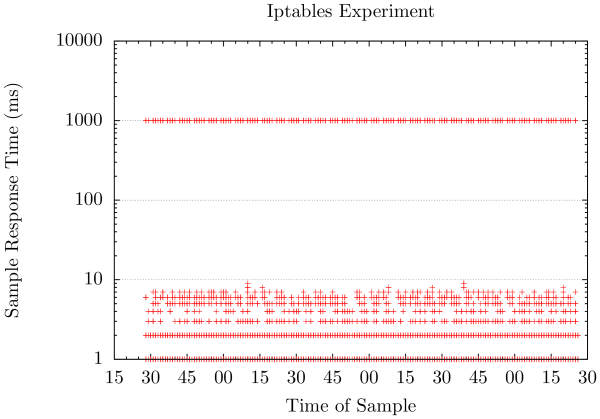
圖2: Iptables實驗結果
正如預期的那樣,我們沒有丟棄請求但收到了一個額外的一秒鐘的延遲。在請求繪制圖圖2中我們可以看到明顯地看到命中重啟時的兩個峰值,其需要滿滿的一秒來完成請求。小於百分之一的測試請求觀察到了高延遲,但這仍足以成為一個問題。
在這個實驗中,我們將使用 ‘-sf’ 選項重啟HAProxy以使用我們的隊列策略來延時傳入的SYN包。為確保我們不是因為運氣,我們做了一百萬的請求。在本試驗中我們對HAProxy重啟了1500次以上。
# Restart haproxy every 100ms while [ 1 ]; do sudo nl-qdisc-add --dev=lo --parent=1:4 --id=40: --update plug --buffer &> /dev/null ./haproxy -f /tmp/haproxy.cfg -p /tmp/haproxy.pid -sf $(cat /tmp/haproxy.pid) sudo nl-qdisc-add --dev=lo --parent=1:4 --id=40: --update plug--release-indefinite &> /dev/nullsleep 0.100 done
tc_experiment.sh 托管在 GitHub
$ ab -c 10 -n 1000000 169.254.255.254:16000/ Benchmarking 169.254.255.254 (be patient) ... Complete requests: 1000000 Failed requests: 0 ... 50% 2 95% 2 99% 8 100% 29 (longest request)
tc_result 托管在 GitHub
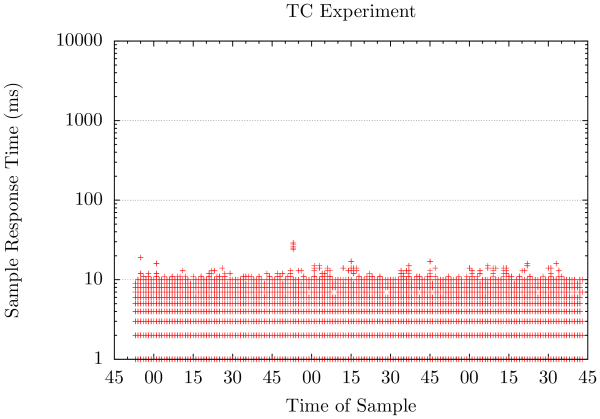
圖3: TC實驗結果
成功啦!重啟HAProxy已基本對我們的流量沒有影響,在圖3中可以看僅造成了輕微的延遲。請注意,該方法主要依賴HAProxy重載配置所花費 的時間,由於我們使用了一個精簡的配置,結果好的有點離譜。在我們的生產環境中,HAProxy重啟時我們能觀察到一個20ms的延遲影響。
這項技術似乎在我們實現目標——為開發構建提供堅實的基礎服務設施上運行地很好。通過延遲SYN包進入每台機器上運行的HAProxy負載均衡器, 我們能夠最小化HAProxy重載所影響到的流量,這允許在達成我們SOA的情況下添加,刪除和更改服務後端,而不必恐懼該過程顯著影響用戶的流量。
譯文:http://www.oschina.net/translate/zero-downtime-haproxy-reloads