


本文主要討論Redis集群相關技術及新發展,關於Redis運維等內容,以後另開主題討論。
本文重點推薦Codis——豌豆莢開源的Redis分布式中間件(該項目於4個月前在GitHub開源,目前star已超過2100)。其和Twemproxy相比,有諸多激動人心的新特性,並支持從Twemproxy無縫遷移至Codis。
本文主要目錄如下,對Redis比較了解的朋友,可跳過前兩部分,直接欣賞Codis相關內容。
1. Redis常見集群技術
1.1 客戶端分片
1.2 代理分片
1.3 Redis Cluster
2. Twemproxy及不足之處
3. Codis實踐
3.1 體系架構
3.2 性能對比測試
3.3 使用技巧、注意事項
好吧我們正式開始。
長期以來,Redis本身僅支持單實例,內存一般最多10~20GB。這無法支撐大型線上業務系統的需求。而且也造成資源的利用率過低——畢竟現在服務器內存動辄100~200GB。
為解決單機承載能力不足的問題,各大互聯網企業紛紛出手,“自助式”地實現了集群機制。在這些非官方集群解決方案中,物理上把數據“分片”(sharding)存儲在多個Redis實例,一般情況下,每一“片”是一個Redis實例。
包括官方近期推出的Redis Cluster,Redis集群有三種實現機制,分別介紹如下,希望對大家選型有所幫助。
這種方案將分片工作放在業務程序端,程序代碼根據預先設置的路由規則,直接對多個Redis實例進行分布式訪問。這樣的好處是,不依賴於第三方分布式中間件,實現方法和代碼都自己掌控,可隨時調整,不用擔心踩到坑。
這實際上是一種靜態分片技術。Redis實例的增減,都得手工調整分片程序。基於此分片機制的開源產品,現在仍不多見。
這種分片機制的性能比代理式更好(少了一個中間分發環節)。但缺點是升級麻煩,對研發人員的個人依賴性強——需要有較強的程序開發能力做後盾。如果主力程序員離職,可能新的負責人,會選擇重寫一遍。
所以,這種方式下,可運維性較差。出現故障,定位和解決都得研發和運維配合著解決,故障時間變長。
這種方案,難以進行標准化運維,不太適合中小公司(除非有足夠的DevOPS)。
這種方案,將分片工作交給專門的代理程序來做。代理程序接收到來自業務程序的數據請求,根據路由規則,將這些請求分發給正確的Redis實例並返回給業務程序。
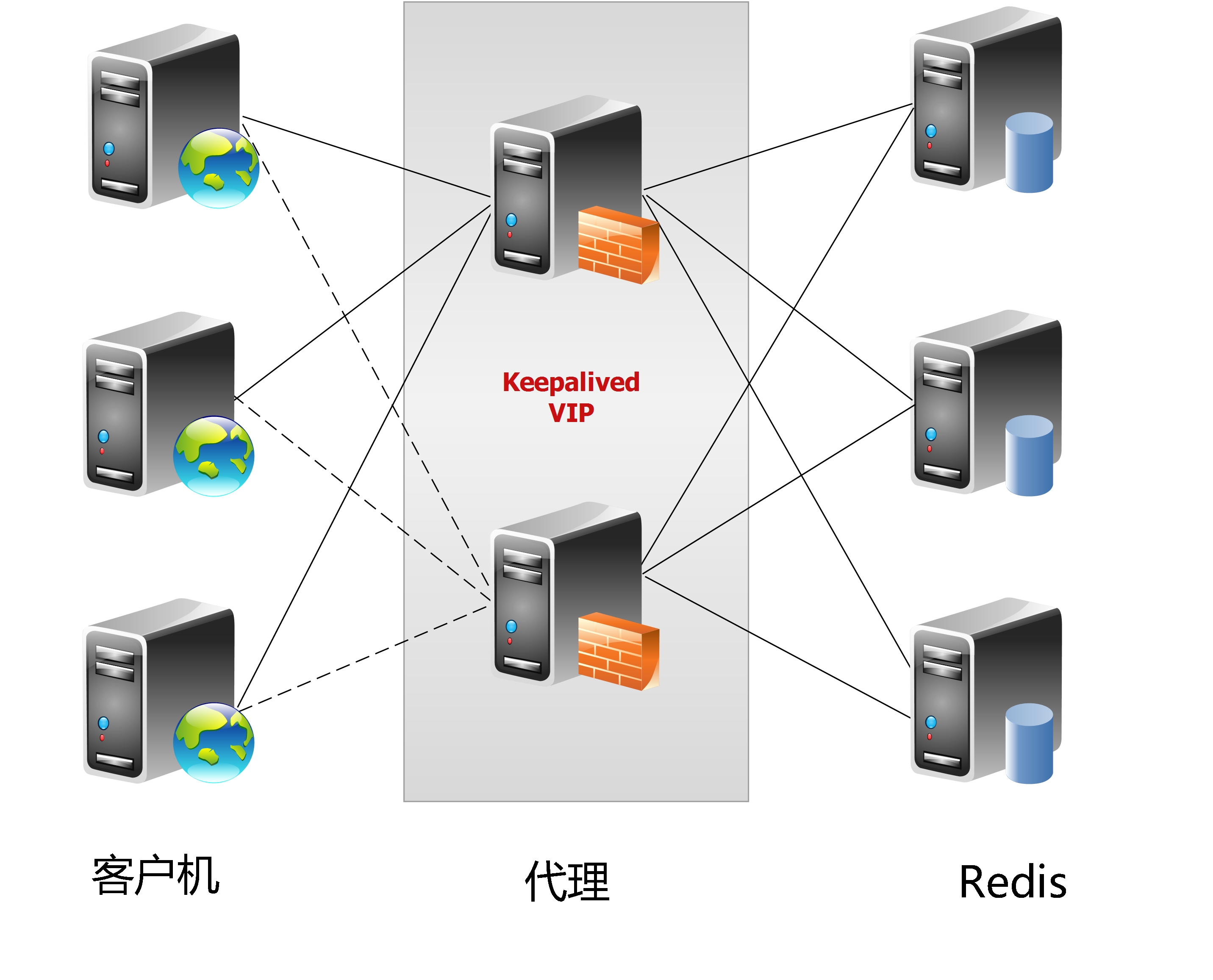
這種機制下,一般會選用第三方代理程序(而不是自己研發),因為後端有多個Redis實例,所以這類程序又稱為分布式中間件。
這樣的好處是,業務程序不用關心後端Redis實例,運維起來也方便。雖然會因此帶來些性能損耗,但對於Redis這種內存讀寫型應用,相對而言是能容忍的。
這是我們推薦的集群實現方案。像基於該機制的開源產品Twemproxy,便是其中代表之一,應用非常廣泛。
在這種機制下,沒有中心節點(和代理模式的重要不同之處)。所以,一切開心和不開心的事情,都將基於此而展開。
Redis Cluster將所有Key映射到16384個Slot中,集群中每個Redis實例負責一部分,業務程序通過集成的Redis Cluster客戶端進行操作。客戶端可以向任一實例發出請求,如果所需數據不在該實例中,則該實例引導客戶端自動去對應實例讀寫數據。
Redis Cluster的成員管理(節點名稱、IP、端口、狀態、角色)等,都通過節點之間兩兩通訊,定期交換並更新。
由此可見,這是一種非常“重”的方案。已經不是Redis單實例的“簡單、可依賴”了。可能這也是延期多年之後,才近期發布的原因之一。
這令人想起一段歷史。因為Memcache不支持持久化,所以有人寫了一個Membase,後來改名叫Couchbase,說是支持Auto Rebalance,好幾年了,至今都沒多少家公司在使用。
這是個令人憂心忡忡的方案。為解決仲裁等集群管理的問題,Oracle RAC還會使用存儲設備的一塊空間。而Redis Cluster,是一種完全的去中心化……
本方案目前不推薦使用,從了解的情況來看,線上業務的實際應用也並不多見。
Twemproxy是一種代理分片機制,由Twitter開源。Twemproxy作為代理,可接受來自多個程序的訪問,按照路由規則,轉發給後台的各個Redis服務器,再原路返回。
這個方案順理成章地解決了單個Redis實例承載能力的問題。當然,Twemproxy本身也是單點,需要用Keepalived做高可用方案。
我想很多人都應該感謝Twemproxy,這麼些年來,應用范圍最廣、穩定性最高、最久經考驗的分布式中間件,應該就是它了。只是,他還有諸多不方便之處。
Twemproxy最大的痛點在於,無法平滑地擴容/縮容。
這樣導致運維同學非常痛苦:業務量突增,需增加Redis服務器;業務量萎縮,需要減少Redis服務器。但對Twemproxy而言,基本上都很難操作(那是一種錐心的、糾結的痛……)。
或者說,Twemproxy更加像服務器端靜態sharding。有時為了規避業務量突增導致的擴容需求,甚至被迫新開一個基於Twemproxy的Redis集群。
Twemproxy另一個痛點是,運維不友好,甚至沒有控制面板。
Codis剛好擊中Twemproxy的這兩大痛點,並且提供諸多其他令人激賞的特性。
Codis由豌豆莢於2014年11月開源,基於Go和C開發,是近期湧現的、國人開發的優秀開源軟件之一。現已廣泛用於豌豆莢的各種Redis業務場景(已得到豌豆莢@劉奇同學的確認,呵呵)。
從3個月的各種壓力測試來看,穩定性符合高效運維的要求。性能更是改善很多,最初比Twemproxy慢20%;現在比Twemproxy快近100%(條件:多實例,一般Value長度)。
Codis引入了Group的概念,每個Group包括1個Redis Master及至少1個Redis Slave,這是和Twemproxy的區別之一。這樣做的好處是,如果當前Master有問題,則運維人員可通過Dashboard“自助式”切換到 Slave,而不需要小心翼翼地修改程序配置文件。
為支持數據熱遷移(Auto Rebalance),出品方修改了Redis Server源碼,並稱之為Codis Server。
Codis采用預先分片(Pre-Sharding)機制,事先規定好了,分成1024個slots(也就是說,最多能支持後端1024個Codis Server),這些路由信息保存在ZooKeeper中。
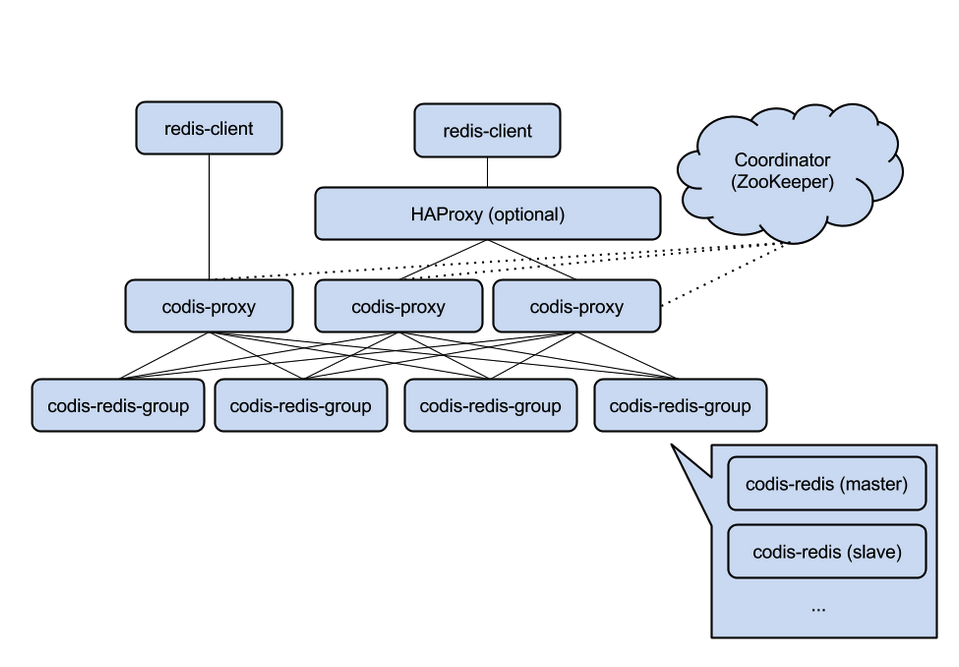
ZooKeeper還維護Codis Server Group信息,並提供分布式鎖等服務。
Codis目前仍被精益求精地改進中。其性能,從最初的比Twemproxy慢20%(雖然這對於內存型應用而言,並不明顯),到現在遠遠超過Twemproxy性能(一定條件下)。
我們進行了長達3個月的測試。測試基於redis-benchmark,分別針對Codis和Twemproxy,測試Value長度從16B~10MB時的性能和穩定性,並進行多輪測試。
一共有4台物理服務器參與測試,其中一台分別部署codis和twemproxy,另外三台分別部署codis server和redis server,以形成兩個集群。
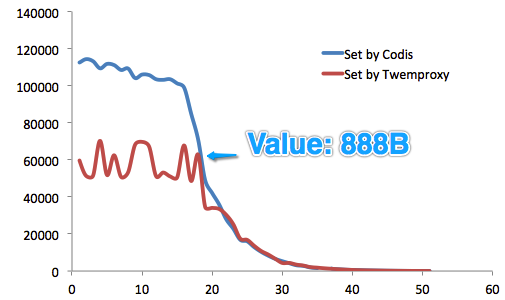
從測試結果來看,就Set操作而言,在Value長度<888B時,Codis性能優越優於Twemproxy(這在一般業務的Value長度范圍之內)。
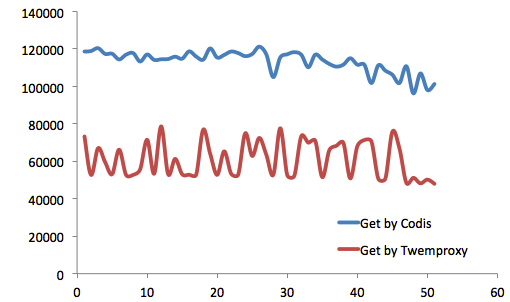
就Get操作而言,Codis性能一直優於Twemproxy。
Codis還有很多好玩的東東,從實際使用來看,有些地方也值得注意。
出品方貼心地准備了Codis-port工具。通過它,可以實時地同步 Twemproxy 底下的 Redis 數據到你的 Codis 集群。同步完成後,只需修改一下程序配置文件,將 Twemproxy 的地址改成 Codis 的地址即可。是的,只需要做這麼多。
Codis提供一個Java客戶端,並稱之為Jodis(名字很酷,是吧?)。這樣,如果單個Codis Proxy宕掉,Jodis自動發現,並自動規避之,使得業務不受影響(真的很酷!)。
Pipeline使得客戶端可以發出一批請求,並一次性獲得這批請求的返回結果。這提升了Codis的想象空間。
從實際測試來看,在Value長度小於888B字節時,Set性能迅猛提升;
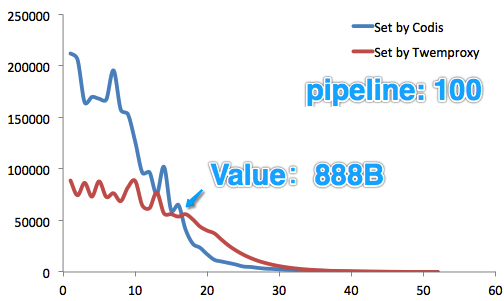
Get性能亦復如是。
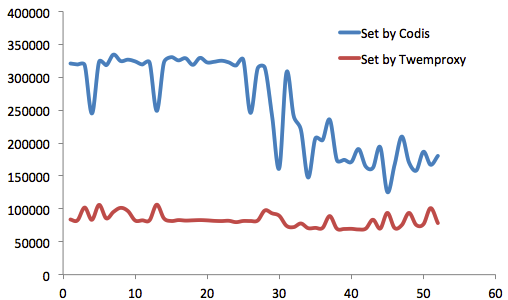
也就是說, Codis僅負責維護當前Redis Server列表,由運維人員自己去保證主從數據的一致性。
這是我最贊賞的地方之一。這樣的好處是,沒把Codis搞得那麼重。也是我們敢於放手在線上環境中上線的原因之一。
好吧,粗淺地說兩個。希望Codis不要變得太重。另外,加pipeline參數後,Value長度如果較大,性能反而比Twemproxy要低一些,希望能有改善(我們多輪壓測結果都如此)。
因篇幅有限,源碼分析不在此展開。另外Codis源碼、體系結構及FAQ,參見如下鏈接:https://github.com/wandoulabs/codis
原文:http://www.infoq.com/cn/articles/effective-ops-part-03