


1. HAProxy和ebtree簡介
HAProxy是法國人Willy Tarreau個人開發的一個開源軟件,目標是應對客戶端10000以上的同時連接,為後端應用服務器、數據庫服務器提供高性能的負載均衡服務。
在底層數據結構方面,舊版本HAProxy曾經使用過紅黑樹,用於任務調度、負載均衡等方面。但是Willy Tarreau認為,在事件響應非常頻繁的情況下,任務插入、刪除的頻率非常高,這時候使用紅黑樹存在性能瓶頸,尤其不能接受紅黑樹刪除節點的時間復雜度為O(log n)。因此,他發明了一種新的數據結構,叫做彈性二叉樹(elastic binary tree),簡稱ebtree。
目前新版本的HAProxy(本文編寫時最新版本為1.4.23)已使用ebtree,而除了HAProxy之外,還沒有其它著名的開源軟件使用ebtree。可以這麼說,HAProxy最有特色的地方就是ebtree,ebtree名符其實是HAProxy的獨門武器。
ebtree是不平衡的二叉搜索樹(BST),而紅黑樹、AVL樹等都是平衡的BST。傳統的BST最怕的就是退化成線性搜索,因此,紅黑樹等BST插入、刪除時都需要對樹進行平衡化,而平衡化是一個從葉子節點開始,向根節點方向遞歸向上的過程,時間復雜度是O(log n)。
有鑒於此,ebtree為了實現刪除節點時O(1)的時間復雜度,必然放棄保持樹的平衡,為了拒絕由此而來的副作用——退化成線性搜索(或者更准確地說,退化成不受限制的線性搜索),不可避免地引入了一些新的成員和新的思路,且待我慢慢道來。
2. ebtree節點的組成
一個ebtree的節點(以下簡稱ebnode)分為node部分和leaf部分(Willy Tarreau是這樣描述的,但我覺得稱為樹干部分和葉子部分更合適一些,以下就按我的理解來敘述)。樹干負責關聯其它ebnode,由父指針(node_p)和分支(Willy Tarreau稱之為root,包括左分支L和右分支R),以及一個控制樹的高度的特殊成員(bit)組成,葉子負責攜帶數據(data,一般是數據的鍵值,所以下文都稱為key),另外包含一個指向上層的指針(leaf_p)。
一棵ebtree只有一個根節點(root),包含兩個左右分支的指針(L、R)。所有的ebnode總是掛在根節點的左分支下面,根節點的右分支總是為空。在ebtree的遍歷過程中,判斷當前節點是否根節點就是判斷其右指針是否為空。
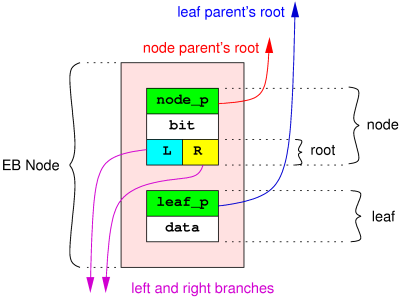
3. 各個指針的附加屬性
在32位平台中,一個指針占用4個字節,例如,地址值0xaabbcc00的下一個地址值是0xaabbcc04,再下一個是0xaabbcc08,也就是說,指針的值的最後兩個比特不能表示一個合法地址。因此,Willy Tarreau充分利用這一點,來保存上述幾個指針的特殊屬性。這是一個很重要的優化,每個ebnode可以節省幾個成員,整個ebtree就節省大量存儲空間。
1) L和R既可以指向其它ebnode的樹干,也可以指向其它ebnode的葉子,還可以指向自己的葉子。在ebtree的遍歷過程中,對樹干和葉子有不同的處理邏輯,L和R有必要知道自己所指向的是樹干還是葉子。
2) 可以知道node_p和leaf_p究竟掛在其它ebnode的左分支下面,還是掛在其右分支下面。
3) 根節點右分支不掛任何樹干和葉子,可以把它也利用上,指示該ebtree是否允許重復鍵值。
熟悉紅黑樹的讀者都知道,紅黑樹也有同樣的優化方法,表示紅黑樹節點顏色的屬性並不占用內存空間。
4. bit的定義
引入bit就是為了限制樹的高度,避免極端不平衡。在一棵不允許重復鍵值的ebtree中,key是32位的情況下,bit的取值范圍是從0到31,此時,它的定義是:子樹所有的鍵中,第一個不同的二進制位的位置。允許重復鍵值的ebtree稍後再詳細介紹。
例如,下圖的右下角子樹中只有兩個鍵,左邊葉子節點的鍵值為300,右邊葉子節點的鍵值為400,300的二進制是100101100,400的二進制是110010000,從右邊數起第7位起(注意,程序員都是從0開始數數的),300和400左邊的位都相同,所以,bit等於7。
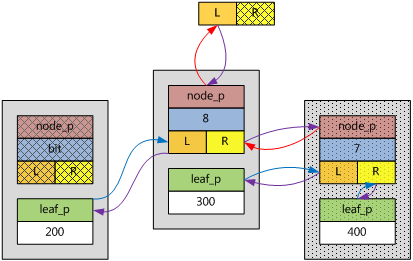
這時候,讀者可能會問,這樣定義bit為什麼能夠限制樹的高度呢?不用著急,馬上隆重介紹bit的兩個重要意義!
5. bit的第一個重要意義
這裡只討論鍵值大於等於零的情況,事實上,ebtree可以支持鍵值為負數,不過,我還沒有仔細研究過這種情況,應該是對符號位進行某些轉換處理。
bit的第一個重要意義:同一個ebnode中的bit和key,聯合決定該ebnode屬下的子樹內,所有key的取值范圍。
先看下圖掛在根節點下面,key = 300的那個ebnode,bit = 8,300的二進制為100101100,從右邊數起第8位是最高位那個1,參考bit的定義,也就是說,該子樹所有的鍵,第8位左邊都是0,所以,它們的取值范圍是從0到511(二進制111111111)。
再看最下面那個ebnode,bit = 5,250的二進制為11111010,從右邊數起第5位是第三個1,再對照bit的定義,該子樹的鍵,第5位左邊都是11,所以,它們的取值范圍是從192(二進制11000000)到255(二進制11111111)。
同理,最右邊那個ebnode,bit = 7,key = 400,取值范圍是256-511。
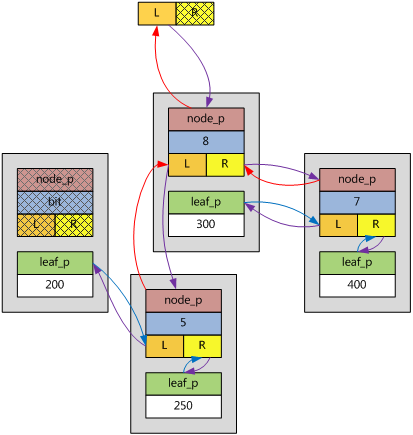
6. bit的第二個重要意義和查找過程
bit的第二個重要意義:如果要查找的數據x在該子樹的取值范圍內,bit可以指示其可能會在左分支下面還是右分支下面。
ebtree的具體查找過程是,遍歷到某個ebnode時,如果key = x,返回查找結果;如果x已經超出bit規定的取值范圍,返回查找失敗;否則,取x的第bit位,如果bit = 0,那麼從該ebnode的左分支查找,反之,從右分支查找;如果已到達葉子還是沒有匹配,返回查找失敗。
還是上一節那個圖,假如要找的鍵x = 249,二進制為11111001,從根節點左分支開始查找,bit = 8,右邊數起第8位為0,於是從它的左分支繼續查找,bit = 5,249右邊數起第5位為1,於是從它的右分支繼續查找,此時已到達葉子,且250 != 249,本次查找失敗。
假如要找的鍵x = 300,因為就在查找路徑的節點上,直接返回結果。
假如要找的鍵x = 600,已經超出該子樹中bit規定的取值范圍,返回查找失敗。
7. 插入不可重復的鍵值
首先,要介紹的是空樹的情況。由前面的敘述可以得知,一棵ebtree為空樹當且僅當它的根節點的左分支為空。所以,此時插入的ebnode就直接掛在根節點的左分支下面,由於新插入的ebnode不存在左右分支,也沒有父節點(上層ebnode),顯然也不需要bit來控制樹的高度,因此,該ebnode的樹干都沒有使用。
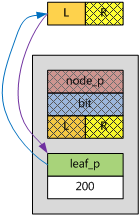
其次,介紹ebtree只有一個ebnode時,再插入一個ebnode的情況。此時,新的ebnode必定插入在根節點與舊的ebnode之間,如果新的鍵值大於原來的鍵值,舊的ebnode掛在新的ebnode的左分支下面,新的ebnode的葉子掛在自己的右分支下面,再計算bit;反之,則左右相反,再計算bit。
下圖的例子,是已有key = 200,再插入key = 300的情形。讀者可以根據上面的描述畫出已有key = 200,再插入key = 100的情形。
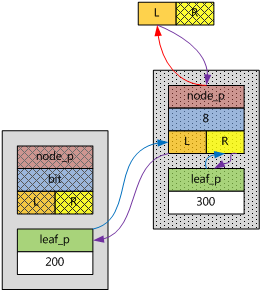
然後,就可以介紹在ebtree中插入新的ebnode的五種基本情形。在這裡,都以上圖為初始狀態。任何具有更多ebnode的情形,都可以通過對ebtree的遍歷,遞推到其中一種情形。
1) 新的鍵值可以插入子樹中,而且小於子樹中的最小鍵值。
假如新插入ebnode的key為100,根據bit的第二個重要意義,100應該在該子樹的左分支下面,而且,100小於200,於是,該ebnode插入在原圖的左分支上,自己的左分支指向自己的葉子,自己的右分支指向原來子樹的左分支。如下圖所示。
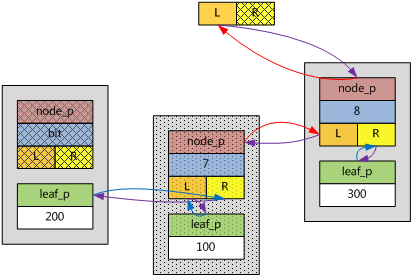
鍵值范圍[0, 200)都屬於這種情形。
2) 新的鍵值可以插入子樹中,該鍵值在確定要插入的兩個ebnode的鍵值之間,且應該在該子樹的左分支下面。
假如新插入ebnode的key為225,根據bit的第二個重要意義,225應該在該子樹的左分支下面,而且,225大於200,於是,該ebnode插入在原圖的左分支上,自己的左分支指向原來子樹的左分支,自己的右分支指向自己的葉子。如下圖所示。
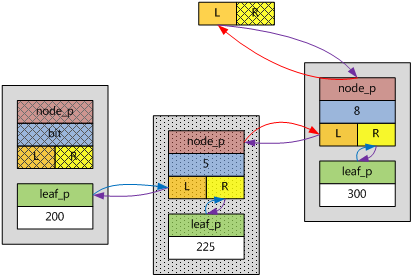
鍵值范圍(200, 255]都屬於這種情形。
3) 新的鍵值可以插入子樹中,該鍵值在確定要插入的兩個ebnode的鍵值之間,且應該在該子樹的右分支下面。
假如新插入ebnode的key為275,根據bit的第二個重要意義,275應該在該子樹的右分支下面,而且,275小於300,於是,該ebnode插入在原圖的右分支上,自己的左分支指向自己的葉子,自己的右分支指向原來子樹的右分支。如下圖所示。
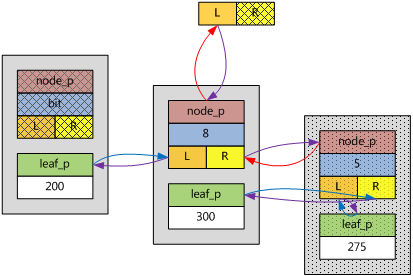
鍵值范圍(255, 300)都屬於這種情形。
4) 新的鍵值可以插入子樹中,而且大於子樹中的最大鍵值。
假如新插入ebnode的key為400,根據bit的第二個重要意義,400應該在該子樹的右分支下面,而且,400大於300,於是,該ebnode插入在原圖的右分支上,自己的左分支指向原來子樹的右分支,自己的右分支指向自己的葉子。如下圖所示。
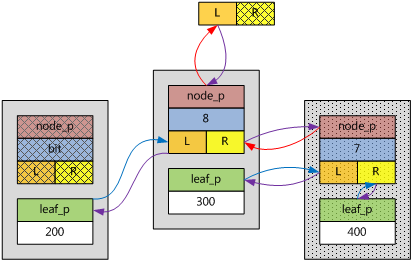
鍵值范圍(300, 511]都屬於這種情形。
5) 新的鍵值不可以插入子樹中。
假如新插入ebnode的key為600,根據bit的第一個重要意義,600不可插入到子樹中,於是,該ebnode插入在原圖的子樹之上,自己的左分支指向原來的子樹,自己的右分支指向自己的葉子。如下圖所示。
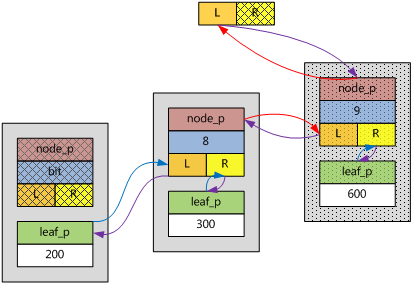
鍵值范圍(511, +∞)都屬於這種情形。
8. bit的第三個重要意義和插入重復的鍵值
ebtree是專門為任務調度而生的,同樣的優先級,必須保證能夠按照任務觸發的次序來進行訪問。所以,ebtree支持存儲重復的鍵值,這一點並不是所有的BST都支持,可以說是ebtree的優點。而且,解決鍵值沖突不會退化成鏈表。
bit的第三個重要意義:bit為負值表示該子樹下所有的鍵都是重復的,而且,該值表示重復子樹的層次。當然,必須要在根節點右指針允許的情況下。
插入第一個重復鍵值,例如300(ebnode底紋為點點),可以參考上一節的第二種和第四種基本情形,不同的是,bit為-1。
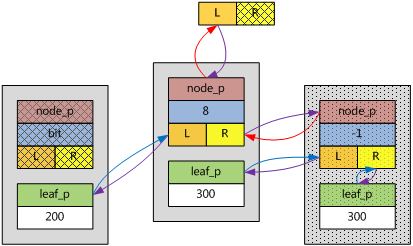
如果再插入一個重復鍵值300(ebnode底紋為方格),應該在重復鍵值子樹上插入,而且是向上生長。
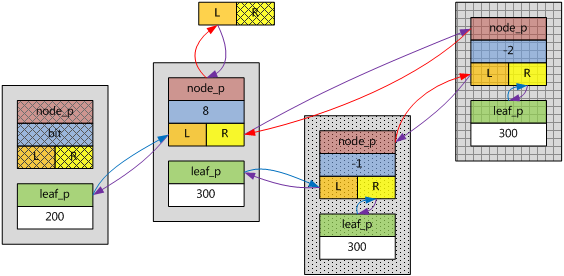
上圖已經有四個ebnode,信息量較大,為了後續敘述方便,把它簡化,去掉幾個指針域,保留bit和key,得到下圖。
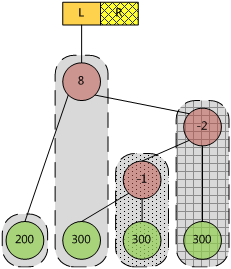
再插入一個300(ebnode底紋為斜方格),得到下面的ebtree。
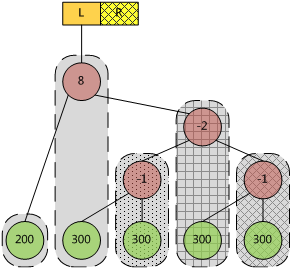
再插入兩個300(ebnode底紋分別為左斜線和右斜線),得到下面的ebtree。
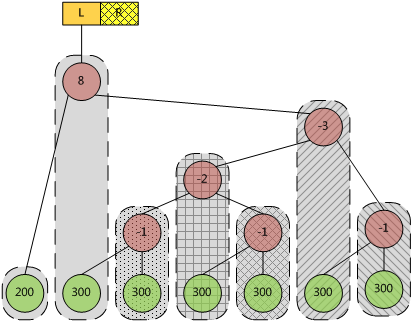
讀者可以思考一下,如果再來一個、兩個、三個300,應該在哪裡插入?如果插入不同於300的其它鍵值,應該在哪裡插入?
從上面幾張圖,大家可以看到,一個ebnode的樹干和葉子會隨著樹的增長而拉長到不同的層次上,好像很有彈性的樣子,這就是彈性二叉樹名字的由來。
9. 刪除節點
刪除一個ebnode,概括起來比較簡單,就是把要刪除的葉子和該葉子的父親(樹干部分)刪除,然後把兄弟掛到祖父下面。因為不需要對樹進行平衡化,不需要訪問其它ebnode,效率很高。
具體操作,分為兩種情況:
1)被刪除的葉子直連自己的樹干,可直接刪除該ebnode,然後對它的兄弟重新指派原來的祖父為父親。
2)被刪除的葉子不是直連自己的樹干,以該葉子的父親(其它ebnode的樹干)替換該ebnode的樹干,然後刪除該ebnode,再把它的兄弟重新指派原來的祖父為父親。
10. 總結
沒有最好的數據結構,只有最合適的數據結構。ebtree有它的優點:
1)支持存儲重復的鍵值,而且,在此情況下,也不會退化成線性操作。
2)刪除節點時,不需要對樹進行平衡化。
3)插入鍵值時,很可能不需要深入到樹的葉子,當然,很多BST都這樣。
4)查詢鍵值時,可以預知子樹的取值范圍,從而可以選擇訪問還是不訪問該子樹。
缺點也很明顯:
1)邏輯比較復雜,熟悉的人不多(希望讀者看完本文之後都有茅塞頓開的感覺)。
2)ebnode占用空間比較多,如果把bit也算一個指針,相當於花了5個指針才攜帶1個數據。
3)鍵值嚴重依賴於可以進行位運算的數據類型。
總而言之,ebtree適合有高頻率插入、刪除操作(例如50萬次/秒)的使用場合,不適合查詢較多、插入、刪除較少的場合,非常不適合用於緩存。