看過很多Hadoop介紹或者是學習的帖子和文章,發現介紹Hadoop I/O系統的很少。很多文章都會介紹HDFS的架構和使用,還有MapReduce編程等等。尤其是在介紹Hadoop的MapReduce編程之前,首先必須了解下Hadoop的I/O知識,要不一看到IntWritable、LongWritable、Text、NullWritable等概念就有點犯暈,看到和普通的Java程序類似的MapReduce程序就覺得很難。如果這時候你知道其實IntWritable就是其他語言如Java、C++裡的int類型,LongWritable就是其他語言裡的long,Text類似String,NullWritable就是Null,這樣你就會很輕易的明白Hadoop 的MapReduce 程序。就像在學習其他編程語言之前必須先學習數據類型一樣,在學習Hadoop的MapReduce編程之前,最好先學習下Hadoop的I/O知識。這裡就簡要介紹Hadoop的I/O知識,就當拋磚引玉吧。
1. 序列化和反序列化
序列化(Serialization)就是結構化的對象轉化為字節流,這樣可以方便在網絡上傳輸和寫入磁盤進行永久存儲(原因看完這部分後就明白了)。反序列化(deserialization)就是指將字節流轉回結構化對象的逆過程。
序列化和反序列化在分布式數據處理裡主要出現在進程間通行和永久存儲兩個應用領域。在Hadoop 系統中,系統中多個節點上的進程間通信是通過遠程過程調用(romote procedure call,R PC)實現的,RPC協議將消息序列轉化為二進制流後發送到遠程節點,遠程節點接著將二進制流反序列化為消息,所以RPC對於序列化有以下要求(也就是進程間通信對於序列化的要求):
(1)緊湊,緊湊的格式可以提高傳輸效率,充分利用網絡帶寬,要知道網絡帶寬是數據中心的一種非常重要的資源。
(2)快速,進程間通信是分布是系統的重要內容,所以必須減少序列化和反序列化的開銷,這樣可以提高整個分布式系統的性能。
(3)可擴展,通信協議為了滿足一些新的需求,比如在方法調用的過程中增加新的參數,或者新的服務器系統要能夠接受老客戶端的舊的格式的消息,這樣就需要直接引進新的協議,序列化必須滿足可擴展的要求。
(4)互操作,可以支持不同語言寫的客戶端(比如C++、java、
Python等等)與服務器交互。
前面說了序列化的目的是可以方便在網絡上傳輸和寫入磁盤進行永久存儲,前面講了進程間通信對於序列化的要求,下面來說一說數據永久存儲對於序列化的要求。前面說的4個序列化的要求也是數據永久存儲所要求的,存貯格式緊湊可以高效的利用存儲空間,快速可以減少讀寫數據的額外開銷,可擴張這樣就可以方便的讀取老格式的數據,互操作就可以滿足不同的編程序言來讀寫永久存貯的數據。
2. Hadoop的序列化格式——Writabale
前面介紹了序列化對於分布式系統是至關重要的,Hadoop 定義了自己的序列化格式Writable,它是通過Java語言實現的,格式緊湊速度快。Writable是Hadoop的核心,很多MapReduce程序都會為鍵和值使用它。
2.1Writabale接口
Writable接口定義了兩個方法,一個將其狀態寫到DataOutput二進制流(往二進制流裡面寫數據),一個從DataInput二進制流讀取其狀態(從二進制流裡讀取數據)。
2.2Writable類
Hadoop自帶的org.apache.hadoop.io包含有廣泛的Writable類可供選擇。下面給出Writable類的層次結構。
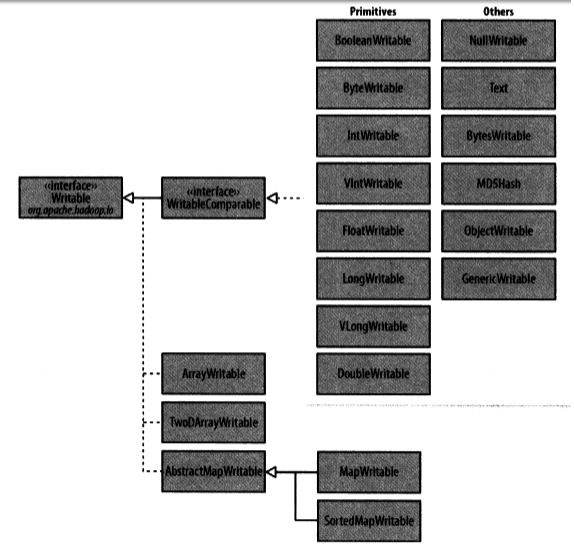
下面介紹幾個常用的Writable類:
(1)Text類:
Text類是針對UTF-8序列(UTF-8是UNICODE的一種變長字節字符編碼,又稱萬國碼)的Writable類,一般認為他等價與java.lang.String的Writable類。但是他和String還是有一些差異的。Text的索引是按編碼後字節序列中的位置來實現的,String是按其所包含的char編碼單元來索引的。看下面的例子:
String s=String("\u0041\u00df\uu6671\ud801\uDc00");
Text t=Text("\u0041\u00df\uu6671\ud801\uDc00");
s.indexof("\u0041")==0 t.find("\u0041")==0
s.indexof("\u00df")==1 t.find("\u00df")==1
s.indexof("\u6671")==2 t.find("\u6671")==3
s.indexof("\ud801\uDc00")==3 t.find(\ud801\uDc00")==6
s.length()==5 s.getBytes("UTF-8").length()==10
t.getLength()==10(1+2+3+4)
通過字節偏移量來進行位置索引,實現對Text類的Unicode字符迭代是非常復雜的,因為不能簡單的通過增加位置的索引值來實現。所以必先將Text對象轉化為java.nio.BytesBuffer對象,然後利用緩沖區對Text對象反復調用bytesToCodePoint()靜態方法,該方法能獲取下一代碼的位置。
由於Text類不像java.lang.String類那樣有豐富的字符串操作API,所以在一些情況下為了方便處理,需要將Text類轉化為String類,這一過程通過toString來實現。
(2)ByteWritable類,二進制數據數組的封裝,它的序列化格式為一個用於指定後面數據字節數的整數域(4字節),後跟字節本身。
(3)NullWritabe,是Writable的一個特殊類型,它的序列化長度為0,類似於null。
(4)ObjectWritable類,是對java基本類型(String,enum,Writable,null或這些類型組成的數組)的一個通用封裝。
(5)Writable集合類,共有4個集合類,其中ArrayWritable是對Writable的數組的實現,TwoDArrayWritable是對Writable的二維數組的實現,MapWritable是對Map的實現,SortedMapWritable是對SortedMap的實現。
(6)定制的Writable類,我們可以根據自己的需求構造自己的Writable類,可以根據需要控制二進制表示和排序順序,由於Writable是MapReduce數據路徑的核心,所以調整二進制表示能對性能殘生顯著效果。
3 Hadoop的序列化框架——Avro
Avro(讀音類似於[ævrə])是Hadoop的一個子項目,由Hadoop的創始人Doug Cutting(也是Lucene,Nutch等項目的創始人,膜拜)牽頭開發,當前最新版本1.3.3。Avro是一個數據序列化系統,設計用於支持大批量數據交換的應用。它的主要特點有:支持二進制序列化方式,可以便捷,快速地處理大量數據;動態語言友好,Avro提供的機制使動態語言可以方便地處理Avro數據。
當前市場上有很多類似的序列化系統,如Google的Protocol Buffers, Facebook的Thrift。這些系統反響良好,完全可以滿足普通應用的需求。針對重復開發的疑惑,Doug Cutting撰文解釋道:Hadoop現存的RPC系統遇到一些問題,如性能瓶頸(當前采用IPC系統,它使用Java自帶的DataOutputStream和DataInputStream);需要服務器端和客戶端必須運行相同版本的Hadoop;只能使用Java開發等。但現存的這些序列化系統自身也有毛病,以Protocol Buffers為例,它需要用戶先定義數據結構,然後根據這個數據結構生成代碼,再組裝數據。如果需要操作多個數據源的數據集,那麼需要定義多套數據結構並重復執行多次上面的流程,這樣就不能對任意數據集做統一處理。其次,對於Hadoop中Hive和Pig這樣的腳本系統來說,使用代碼生成是不合理的。並且Protocol Buffers在序列化時考慮到數據定義與數據可能不完全匹配,在數據中添加注解,這會讓數據變得龐大並拖慢處理速度。其它序列化系統有如Protocol Buffers類似的問題。所以為了Hadoop的前途考慮,Doug Cutting主導開發一套全新的序列化系統,這就是Avro,於09年加入Hadoop項目族中。
Avro是Hadoop中的一個重要的項目,不是三言兩語能說清楚的,這片文章是專門介紹Avro的,感覺寫的不錯,我前面寫的這段來自於這篇文章,地址:[http://langyu.iteye.com/blog/708568]
4 SequenceFile和MapFile
Hadoop的HDFS和MapReduce子框架主要是針對大數據文件來設計的,在小文件的處理上不但效率低下,而且十分消耗內存資源(每一個小文件占用一個Block,每一個block的元數據都存儲在namenode的內存裡)。解決辦法通常是選擇一個容器,將這些小文件組織起來統一存儲。HDFS提供了兩種類型的容器,分別是SequenceFile和MapFile。