一、背景
隨著業務發展,公司業務系統逐漸增多,線上系統的數量也在不斷增加,依靠過去人工巡檢系 統的方式發現系統故障、潛在風險及安全隱患的方式效率越來越低下且
運維人員的工作強度及壓力也在不斷增加,為了提高發現系統故障的及時性、系統維護的專業 性、規范化、科學性同時也能把運維人員從重復的工作中解放出來去做更多有意義的事情,因此我們亟需引入新的監控手段、工具來協助運維工程師解決當前的問 題。
二、建設目標
為保證自有軟件平台運行穩定性,對線上平台進行自動化監控,合理設置監控粒度及監控對象。盡可能的把潛在問題在萌芽狀態解決及消除隱患,以此提高IT技術支持部門的整體集成能力和交付系統運行質量。
建設監控平台的終極目標如下所示:
-
及時發現潛在的問題化被動為主動維護
-
為平台性能優化提供直觀參考依據
-
提高系統維護的專業性和規范性
-
提高用戶體驗,降低服務宕機時間
三、監控平台功能與內容
1、集中監控管理
負責收集和處理來自系統中的各類告警信息,並進行告警信息的匯聚和根源分析,幫助運維人員找出故障發生的原因,快速定位故障點並包含網絡、主機、
數據庫及應用管理(系統軟硬件配置信息、系統性能指標、故障告警和日志管理)。
具體實現:對於日志的歸檔工作采用本地shell及信息收集引擎的方式將系統信息及異常日志集中存儲到監控平台做分析並進行告警、生成報表等工作。
2、統一監控管理界面和多樣的告警方式
通過布局合理的圖形化界面集中反映網絡、系統、數據庫和應用的實時狀態,通過手機短信、郵件以及頁面等多種方式進行告警。
3、自定義告警優先級策略
一般的監控到的結果是成功或者失敗,如Ping不通、訪問網頁出錯、連接不到Socket,發生時這些稱之為故障,故障是最優先的告警。除此之外,還能監控到返回的延時、內容等,如Ping返回的延時、訪問網頁的時間、訪問網頁取到的內容等。利用返回的結果可以自定義告警條件,如Ping監控的返回延時一般是10-30ms之間,當延時大於100ms時候,表示網絡或者服務器可能出現問題,引起網絡響應慢,需要立即檢查是否流量過大或者服務器CPU太高等問題。
4、自定義告警信息內容標准
當服務器或應用發生故障時告警信息內容非常多,如告警運行業務名稱、服務器IP、監控的線路、監控的服務錯誤級別、出錯信息、發生時間等。預先定義告警內容及標准使收到的告警內容具有規范性及可讀性。這點對於用短信接受告警內容特別有意義,短信內容最多是70個字符,要在70個字符完全知道故障內容比較困難,更需要預先定義內容規范。如:“視頻直播服務器10.0.211.65 在2012-10-18 13:00電信線路監控第到1次失敗”,清晰明了的知道故障原因。
5、短信告警功能
目前平台可以實現按照不同業務、責任人通過139郵箱告警功能自動發送告警短消息到相應運維工程師手機之上。
同時可以實現調用第三方API方式進行系統告警功能,第三方API只需須留有手機號碼,短信內容變量即可完成短信的即時發送功能。
6、通過郵件接收匯總報表
實現每天收到一封網站服務器監控的匯總報表郵件,花兩三分鐘總體了解網站和服務器的狀態。
7、監控管理標准
實現對網絡運行狀態、系統服務質量和故障告警等的實時監控管理。
8、豐富的數據報表分析功能
結合上述的各項功能,系統能夠根據工作需要產生標准格式報表,並能夠按條件生成和調整各類報表,以滿足IT系統管理及審計等多種需求。
四、平台監控對象
編號
類型
監控范圍
備注
1
網絡
交換、路由、F5
網絡設備性能參數指標、性能指標超限告警
2
主機
Linux、Windows
監視服務器性能參數指標、性能指標超限告警
3
中間件
Nginx、Tomcat
監視中間件性能參數指標、性能指標超限告警
4
流媒體
Wowza、Nginx
監視流媒體性能參數指標、性能指標超限告警
5
數據庫
MySQL
監視數據庫性能參數指標、性能指標超限告警
五、平台架構設計
1、平台架構邏輯拓撲
平台設計架構如下圖5.1所示
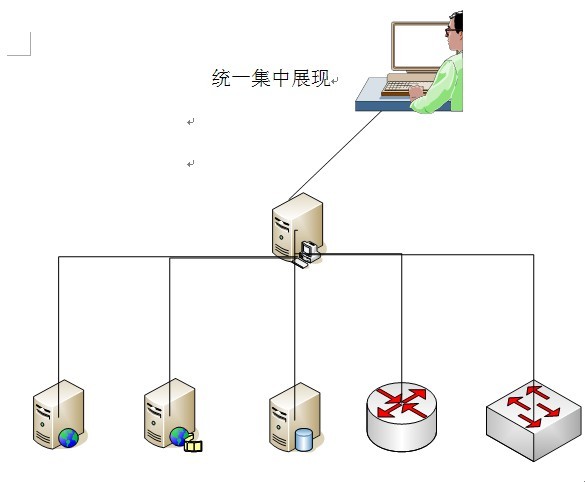
平台采用統一監控,集中展現的方式實現對設備的監控。監控服務器通過部署在各監控對象上的引擎收集信息,通過報表服務器進行過濾、加工、整理,通過統一門戶進行展現及短信告警功能。
2、可用性原則
監控管理軟件的部署不應對原有的系統結構、安全策略等方面做較大修改和調整,對原有系統性能影響最小化,不能對生產系統自身的運行造成不良影響,不能干擾系統的正常運行;盡量少的占用消耗原系統的資源、網絡資源。