Apache Hadoop是一個用來構建大規模共享存儲和計算設施的軟件。Hadoop集群已經應用在多種研究和開發項目中,並且,Yahoo!, EBay, Facebook, LinkedIn, Twitter等公司,越來越多的的把它應用在生產環境中。 這些已有的經驗是技術和投入的結晶,在許多情況下至關重要。因此,適當的使用Hadoop集群可以保證我們的投入能夠獲得最佳回報。
這篇博文簡單總結了一些Hadoop應用的最佳實踐。實際上,類似於設計模式,我們引進一個網格模式的的概念,來提供一個通用且可復用的針對運行在網格上的應用的解決方案。
這篇博文列舉了表現良好的應用的特點並且提供了正確使用Hadoop框架的各種特性和功能的指導。這些特點很大程度上這由其本身特點而定,閱讀這篇文檔的一個好方法是從本質上理解應用,這些最佳實踐在Hadoop的多租戶環境下卓有成效,而且不會與框架本身的大多數原則和限制產生矛盾。
博文還強調了一些Hadoop應用的反模式。
概述
Hadoop上的數據處理應用一般使用Map-Reduce模型。
一個Map-Reduce作業通常會把輸入的數據集拆分成許多獨立的數據段,按照完全並行的方式一個map任務處理一段。框架把map的輸出排序,然後作為reduce的輸入。通常輸入和輸出都儲存在文件系統。框架負責調度、監控任務的執行以及重啟失敗的任務。
Map-Reduce應用可以指定輸入輸出的位置,並提供了map與reduce功能的實現,體現在Hadoop中是Mapper 和Reducer.這些只是作業配置的一部分參數。Hadoop客戶端提交作業(jar或者其他可執行的程序)和配置給JobTracker,而JobTracker負責把程序和配置分發到各個slave,調度和監控任務的執行,並返回狀態信息給客戶端。
Map/Reduce框架的處理是基於<key, value>這樣的鍵值對,也就是說,框架吧輸入數據視作一系列<key, value>鍵值對集合,然後產出另一些鍵值對作為輸出。
這是 Map-Reduce應用的典型數據流
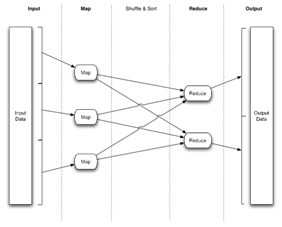
絕大多數在網格上運行的Map-Reduce應用都不會直接實現較低層次的Map-Reduce接口,而是借助於較高抽象層次的語言,例如Pig。
Oozie 是一個非常好的網格上的工作流管理和調度方案。Oozie 支持多種應用接口 (Hadoop Map-Reduce, Pig, Hadoop Streaming, Hadoop Pipes, 等等.) 並且支持基於時間或數據可用性的調度。
網格模式
這一部分是關於網格上運行的Map-Reduce應用的最佳實踐
輸入
Hadoop Map-Reduce 為處理海量數據而設計。maps過程以一種高度並行的方式來處理數據, 通常一個map至少處理一個HDFS block,一般是128M。
-
默認情況下,每個map最多處理一個HDFS 文件。 這意味著假如應用需要處理大量的文件,最好一個map能夠處理多個。可以通過一種特定的輸入格式來達成這個目的,就是MultiFileInputFormat。即使對於那些只處理很少小文件的應用,每個map處理多個文件的效率也更高。
-
假如應用需要處理的數據量非常大,即使文件尺寸很大,每個map處理128M以上的數據也會更有效率。
網格模式: 合並小文件以減少map數量,在處理大數據集的時候用比較大的HDFS 塊大小。
Maps
maps的數量通常取決於輸入大小, 也即輸入文件的block數。 因此,假如你的輸入數據有10TB,而block大小為128M,則需要82,000個map。
因為啟動任務也需要時間,所以在一個較大的作業中,最好每個map任務的執行時間不要少於1分鐘。
就像在上面“輸入”部分所解釋的,對於那種有大量小文件輸入的的作業來說,一個map處理多個文件會更有效率。
網格模式:除非應用的map過程是CPU密集型,否則一個應用不應該有60000-70000個map。
當在map處理的block比較大的時候,確保有足夠的內存作為排序緩沖區是非常重要的,這可以加速map端的排序過程。假如大多數的map輸出都能在排序緩沖區中處理的話應用的性能會有極大的提升。這需要運行map過程的JVM具有更大的堆。記住反序列化輸入的內存操作不同於磁盤操作;例如,Pig應用中的某些class將硬盤上的數據載入內存之後占用的空間會是其本來尺寸的3、4倍。在這種情況下,應用需要更大的JVM堆來讓map的輸入和輸出數據能夠保留在內存中。
如果應用處理的輸入文件尺寸較大,每個map處理一個完整的HDFS block,數據段大一點更有效率。舉個例子,讓每個map處理更多數據,方法之一是讓輸入文件有更大的HDFS block尺寸,例如512M或者更多。
一個極端的例子是Map-Reduce開發團隊用了大約66000個map來做PetaSort,也即66000個map要處理1PB數據,平均每個map 12.5G。
原則是大量運行時間很短的map會有損生產力。
網格模式:確保map的大小,使得所有的map輸出可以在排序緩沖區中通過一次排序來完成操作。
合適的map數量有以下好處:
-
減少了調度的負擔;更少的map意味著任務調度更簡單,集群中可用的空閒槽更多。
-
有足夠的內存將map輸出容納在排序緩存中,這使map端更有效率;
-
減少了需要shuffle map輸出的尋址次數,每個map產生的輸出可用於每一個reduce,因此尋址數就是map個數乘以reduce個數;
-
每個shuffled的片段更大,這減少了建立連接的相對開銷,所謂相對開銷是指相對於在網絡中傳輸數據的過程。
-
這使reduce端合並map輸出的過程更高效,因為合並的次數更少,因為需要合並的文件段更少了。
上述指南需要注意,一個map處理太多的數據不利於失敗轉移,因為單個map失敗可能會造成應用的延遲。
Combiner
適當的使用Combiner可以優化map端的聚合。Combiner最主要的好處在於減少了shuffle過程從map端到reduce端的傳輸數據量。
Shuffle
適當的使用Combiner可以優化map端的聚合。Combiner最主要的好處在於減少了shuffle過程從map端到reduce端的傳輸數據量。
Combiner 也有一個性能損失點,因為它需要一次額外的對於map輸出的序列化/反序列化過程。不能通過聚合將map端的輸出減少到20-30%的話就不適用combiner。可以用 combiner input/output records counters(譯者注:這是一個hadoop mapreduce 的counter名稱,所以采用了原名未翻譯)來衡量Combiner的效率。
網格模式:Combiners可以減少shuffle階段的網絡流量。但是,要保證Combiner 的聚合是確實有效的。
Reduces
reduces的性能很大程度上受shuffle的性能所影響。
應用配置的reduces數量是一個決定性的因素。
太多或者太少的reduce都不利於發揮最佳性能:
-
太少的reduce會使得reduce運行的節點處於過度負載狀態,在極端情況下我們見過一個reduce要處理100g的數據。這對於失敗恢復有著非常致命的負面影響,因為失敗的reduce對作業的影響非常大。
-
太多的reduce對shuffle過程有不利影響。在極端情況下會導致作業的輸出都是些小文件,這對NameNode不利,並且會影響接下來要處理這些小文件的mapreduce應用的性能。
網格模式:在大多數情況下,應用應該保證每個reduce處理1-2g數據,最多5-10g。
輸出
我們需要記住一個重要的因素——應用的輸出文件數取決於配置的reduce數。從我們上文中對reduce的討論可知,reduce數的選擇十分關鍵。
此外,還需要考慮其它一些因素:
-
考慮采用合適的壓縮器(壓縮速度vs性能)對輸出進行壓縮,提高HDFS的寫入性能。
-
每個reduce不要輸出多個文件,避免生成附屬文件。我們一般用附屬文件來記錄統計信息,如果這些信息不多的話,可以使用計數器。
-
為輸出文件選擇合適的格式。對於下游消費者程序來說,用zlib/gzip/lzo等算法來對大量文本數據進行壓縮往往事與願違。因為zlib/gzip/lzo文件是不能分割的,只能整個進行處理。這會引起惡劣的負載均衡和故障恢復問題。作為改善,可以使用SequenceFile和TFile格式,它們不但是壓縮的,而且是可以分割的。
-
如果每個輸出文件都很大(若干GB),請考慮使用更大的輸出塊(dfs.block.size)。
網格模式: 應該確保應用的輸出是數量不多的大文件,每個文件跨越多個HDFS塊,而且經過適當的壓縮。
分布式緩存(Distributed Cache)
分布式緩存可以高效的分發與具體應用相關的較大尺寸的只讀文件。這是Map/Reduce框架提供的機制,用於暫時存儲與特定應用相關的文件(如text, archives, jars等)。
這個框架會在slave節點上執行任務之前將必要的文件拷貝到該節點。它如此高效是因為在個作業中所需要的文件只會被復制一遍,還因為它能夠緩存slave節點上的未歸檔文件。它也被作為基本軟件分發機制用於map和reduce 任務。這種機制可以把jar和本地庫放置在map/reduce任務的classpath或者本地庫路徑下。
分布式緩存設計之初是為了分發一些尺寸不是很大,從幾M到幾十M的附件。目前實現的分布式緩存的弱點在於不能夠指定具體的附件只能應用於特定的map或者reduce。
在極少數情況下,由具體任務本身來拷貝其所需的附件要比使用分布式緩存更合適。例如,那種reduce數很少的應用,而且需要的附屬文件尺寸非常大(超過512M)。
網格模式:應用應該保證分布式緩存中的附件不能夠比任務本身的I/O消耗更多。
計數器(Counters)
計數器(Counters) 展現一些全局性的統計度量,這些度量由mapreduce框架本身,也可由應用來設定。應用可以自行定義任意的計數器並且在map或者reduce方法中更新它們的值。框架會對計數器的值做全局聚合。
計數器適合於追蹤記錄一些量不是很大,但是很重要的全局性信息。不應該用於一些粒度過細的信息統計。
使用計數器的代價非常昂貴,因為在應用的生命周期內JobTracker 需要給每一個map/reduce任務維護一組計數器(定義了多少個就維護多少個)。
網格模式:應用自定義的計數器不應該超過25個。
壓縮
Hadoop Map-Reduce 可以在應用中對map輸出的中間數據和reduce的輸出數據進行指定的壓縮。
-
壓縮中間數據: 正如在 shuffle 部分所講的,對map輸出的中間數據進行合適的壓縮可以減少map到reduce之間的網絡數據傳輸量,從而提高性能。Lzo 壓縮格式是一個壓縮map中間數據的合理選擇,它有效利用了CPU。
-
壓縮應用輸出:就如在 輸出 部分所講的, 使用合適的壓縮格式壓縮輸出數據能夠減少應用的運行時間。Zlib/Gzip 格式在大多數情況下都是比較適當的選擇,因為它在較高壓縮率的情況下壓縮速度也還算可以,bzip2 就慢得多了。
全排序輸出
抽樣
有時候,應用需要產生全排序的輸出。在這種情況下,一個通用的反模式是只使用一個reduce,這樣就能強制數據集中在一處做聚合。很明顯,這樣做效率不高,這樣不僅加大了執行reduce的那個節點的負載,還對失敗恢復有嚴重的不良影響。
更好的辦法是對輸入抽樣,然後以此來使用sampling partitioner 代替默認的hash partitioner。這樣可以獲得更好的負載平衡和失敗恢復。
連接(join)有序數據集
另一種網格設計模式是關於兩個有序數據集的連接,其中一個數據集的大小並非另一個的嚴格倍數。例如,一個數據集有512個buckets,另一個有200個。
在這種情況下,確保輸入的數據集是整體有序的(全排序,如同在商議部分所提到的)意味著可以使用兩個數據集中的任意一個來作為基數。Pig 就是用這種發發來進行高效的連接。
HDFS 操作 & JobTracker 操作
NameNode 很重要而且負擔要比一般的節點重,所以在進行HDFS 操作的時候要注意對性能的影響。特別是,應用程序不要在map/reduce任務中做非I/O操作,也即像遍歷目錄,遞歸統計等這樣的元數據操作。
同樣,不要在應用程序中連接JobTracker來獲得關於集群統計的數據。
網格模式:應用不應該在代碼中執行任何文件系統的元數據操作,這種操作應該在作業提交的時候被嚴格禁止。除此以外,應用程序不應該自己連接JobTracker 。
User Logs
與用戶執行的任務相關的task-logs,也即 map/reduce 任務的標准輸出和錯誤信息儲存在執行這個任務的節點的本地磁盤上。
因為每個節點都是共享存儲的一部分,所以Map-Reduce 框架對儲存在節點上的log數量實際上是有限制的。
Web界面
Hadoop Map-Reduce 框架提供了一個簡單的web界面來監控運行中的作業,查看已完成作業的歷史,以及其他一些從JobTracker獲得的信息
要明白這個web界面是給人看的而不是自動程序。
通過一些屏幕自動化軟件來從web界面獲取信息是不可行的。web界面上的某些部分,像查看歷史作業,非常消耗JobTracker 的資源,如果使用屏幕自動化軟件這麼做可能會導致一些性能問題。
假如真有這麼一個自動統計匯總的需求,最好去咨詢 Map-Reduce的開發團隊。
工作流
Oozie 是一個適用於網格應用的非常好的工作流管理和調度系統。Oozie 可以基於時間或者數據可用性來管理和計劃工作流。使用Oozie來管理和調度的低延遲要求的,產品級的項目已經越來越多。
設計Oozie 的時候考慮的一個重要因素是Hadoop 更適宜於批量處理大量數據。正因如此,用幾個中等規模的Map-Reduce組成處理流程,要比用更多的小型的Map-Reduce作業更好。在極端情況下一個流程可能由幾百上千個作業組成,這是很明顯的反模式。更好的做法是能夠將這些Map-Reduce作業重新組裝成較少的幾個過程,每個過程處理更多的數據,這有助於提高整個流程的性能並降低延遲。
網格模式:工作流中一個Map-Reduce作業應該至少處理十幾G數據。
反模式
這部分會總結一些網格應用通用的反模式。這些東西大多數情況下都與大規模、分布式、批量數據處理系統的原則相悖。這是對應用開發人員的提醒,因為網格軟件逐漸規范化固定化,特別是即將發布的20.Fred版本,對於具有下面列出的這些反模式的應用更難容忍。
不愛使用像Pig這樣的高層次抽象接口。
-
處理幾千個小文件(小於1個block的大小,一般是128M),一個map只能處理一個小文件。
-
處理大量數據的,但HDFS block比較小,導致產生數萬個map。
-
map數量非常多,每個map的運行時間卻非常短(例如5秒)。
-
簡單聚合卻不用Combiner。
-
產生的map數量多於6、7萬。
-
處理大數據集的時候只用很少的reduce(例如只用1個)。
-
用Pig 腳本處理大數據集的時候沒有用PARALLEL關鍵字。
-
用1個reduce為所有輸出進行全局排序。
-
用很多reduce來處理數據,以致每個reduce只能處理1-2G數據。
-
輸出文件多且小。
-
用分布式緩存分發過多的文件或過大的文件(幾百M)。
-
一個任務有幾十上百個計數器。
-
在map/reduce 任務理執行文件系統元數據操作(例如 listStatus)。
-
用屏幕自動化軟件來收集web界面上的信息,作業、隊列狀態,更糟的是查看已完成作業的歷史。
-
工作流由成百上千個小作業做成,每個都只處理少量數據。


