本文將著重於討論Hadoop集群的體系結構和方法,及它如何與網絡和服務器基礎設施的關系。最開始我們先學習一下Hadoop集群運作的基礎原理。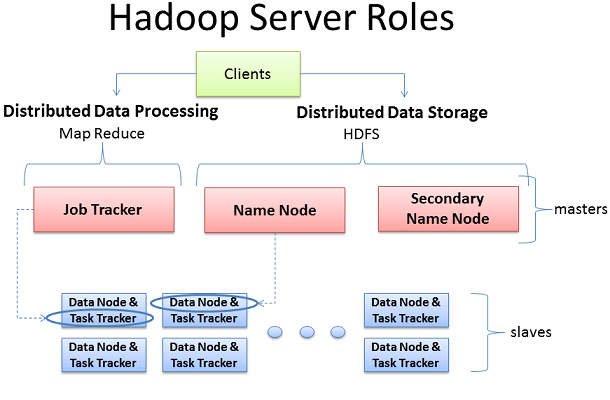
Hadoop裡的服務器角色
Hadoop主要的任務部署分為3個部分,分別是:Client機器,主節點和從節點。主節點主要負責Hadoop兩個關鍵功能模塊HDFS、 Map Reduce的監督。當Job Tracker使用Map Reduce進行監控和調度數據的並行處理時,名稱節點則負責HDFS監視和調度。從節點負責了機器運行的絕大部分,擔當所有數據儲存和指令計算的苦差。 每個從節點既扮演者數據節點的角色又沖當與他們主節點通信的守護進程。守護進程隸屬於Job Tracker,數據節點在歸屬於名稱節點。
Client機器集合了Hadoop上所有的集群設置,但既不包括主節點也不包括從節點。取而代之的是客戶端機器的作用是把數據加載到集群中,遞交 給Map Reduce數據處理工作的描述,並在工作結束後取回或者查看結果。在小的集群中(大約40個節點)可能會面對單物理設備處理多任務,比如同時Job Tracker和名稱節點。作為大集群的中間件,一般情況下都是用獨立的服務器去處理單個任務。
在真正的產品集群中是沒有虛擬服務器和管理層的存在的,這樣就沒有了多余的性能損耗。Hadoop在Linux系統上運行的最好,直接操作底層硬件設施。這就說明Hadoop實際上是直接在虛擬機上工作。這樣在花費、易學性和速度上有著無與倫比的優勢。
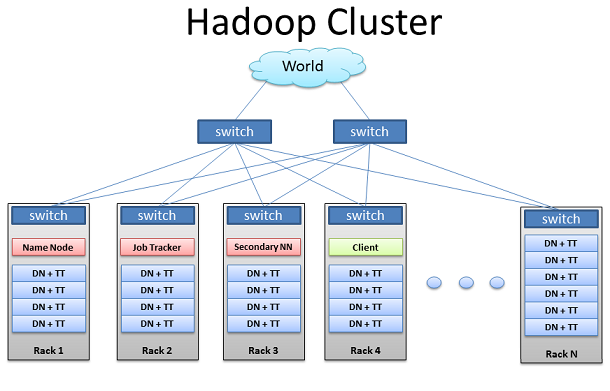
Hadoop集群
上面是一個典型Hadoop集群的構造。一系列機架通過大量的機架轉換與機架式服務器(不是刀片服務器)連接起來,通常會用1GB或者2GB的寬帶 來支撐連接。10GB的帶寬雖然不常見,但是卻能顯著的提高CPU核心和磁盤驅動器的密集性。上一層的機架轉換會以相同的帶寬同時連接著許多機架,形成集 群。大量擁有自身磁盤儲存器、CPU及DRAM的服務器將成為從節點。同樣有些機器將成為主節點,這些擁有少量磁盤儲存器的機器卻有著更快的CPU及更大 的DRAM。
下面我們來看一下應用程序是怎樣運作的吧:

hadoop的工作流程
在計算機行業競爭如此激烈的情況下,究竟什麼是Hadoop的生存之道?它又切實的解決了什麼問題?簡而言之,商業及政府都存在大量的數據需要被快速的分析和處理。把這些大塊的數據切開,然後分給大量的計算機,讓計算機並行的處理這些數據 — 這就是Hadoop能做的。
下面這個簡單的例子裡,我們將有一個龐大的數據文件(給客服部門的電子郵件)。我想快速的截取下“Refund”在郵件中出現的次數。這是個簡單的 字數統計練習。Client將把數據加載到集群中(File.txt),提交數據分析工作的描述(word cout),集群將會把結果儲存到一個新的文件中(Results.txt),然後Client就會讀結果文檔。
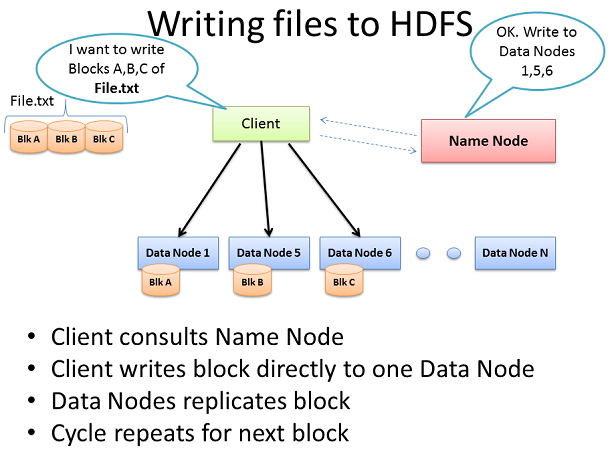
向HDFS裡寫入File
Hadoop集群在沒有注入數據之前是不起作用的,所以我們先從加載龐大的File.txt到集群中開始。首要的目標當然是數據快速的並行處理。為 了實現這個目標,我們需要竟可能多的機器同時工作。最後,Client將把數據分成更小的模塊,然後分到不同的機器上貫穿整個集群。模塊分的越小,做數據 並行處理的機器就越多。同時這些機器機器還可能出故障,所以為了避免數據丟失就需要單個數據同時在不同的機器上處理。所以每塊數據都會在集群上被重復的加 載。Hadoop的默認設置是每塊數據重復加載3次。這個可以通過hdfs-site.xml文件中的dfs.replication參數來設置。
Client把File.txt文件分成3塊。Cient會和名稱節點達成協議(通常是TCP 9000協議)然後得到將要拷貝數據的3個數據節點列表。然後Client將會把每塊數據直接寫入數據節點中(通常是TCP 50010協議)。收到數據的數據節點將會把數據復制到其他數據節點中,循環只到所有數據節點都完成拷貝為止。名稱節點只負責提供數據的位置和數據在族群 中的去處(文件系統元數據)。
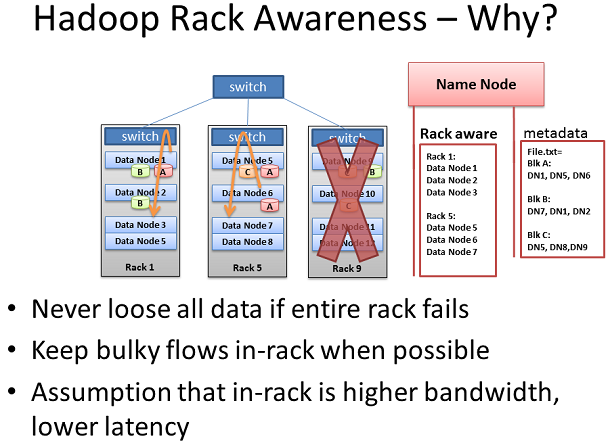
Hadoop的Rack Awareness
Hadoop還擁有“Rack Awareness”的理念。作為Hadoop的管理員,你可以在集群中自行的定義從節點的機架數量。但是為什麼這樣做會給你帶來麻煩呢?兩個關鍵的原因 是:數據損失預防及網絡性能。別忘了,為了防止數據丟失,每塊數據都會拷貝在多個機器上。假如同一塊數據的多個拷貝都在同一個機架上,而恰巧的是這個機架 出現了故障,那麼這帶來的絕對是一團糟。為了阻止這樣的事情發生,則必須有人知道數據節點的位置,並根據實際情況在集群中作出明智的位置分配。這個人就是 名稱節點。
假使通個機架中兩台機器對比不同機架的兩台機器會有更多的帶寬更低的延時。大部分情況下這是真實存在的。機架轉換的上行帶寬一般都低於其下行帶寬。 此外,機架內的通信的延時一般都低於跨機架的(也不是全部)。那麼假如Hadoop能實現“Rack Awareness”的理念,那麼在集群性能上無疑會有著顯著的提升!是的,它真的做到了!太棒了,對不對?
但是掃興的事情發生了,首次使用你必須手動的去定義它。不斷的優化,保持信息的准確。假如機架轉換能夠自動的給名稱節點提供它的數據節點列表,這樣又完美了?或者反過來,數據節點可以自行的告知名稱節點他們所連接的機架轉換,這樣也的話也同樣完美。
在括補結構中網絡中,假如能知道名稱節點可以通過OpenFlow控制器查詢到節點的位置,那無疑是更加令人興奮的。
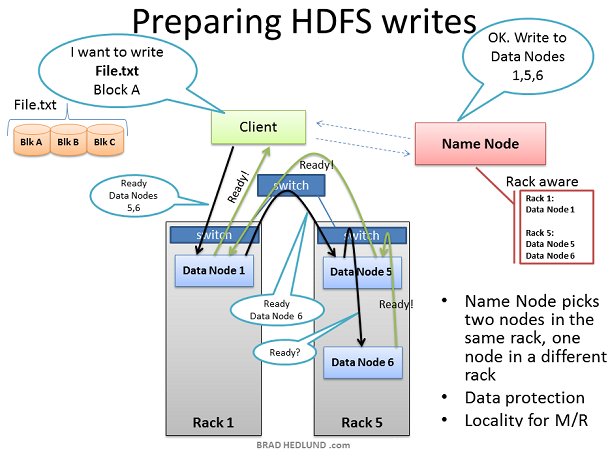
准備HDFS寫入
現在Client已經把File.txt分塊並做好了向集群中加載的准備,下面先從Block A開始。Client向名稱節點發出寫File.txt的請求,從名稱節點處獲得通行證,然後得到每塊數據目標數據節點的列表。名稱節點使用自己的 Rack Awareness數據來改變數據節點提供列表。核心規則就是對於每塊數據3份拷貝,總有兩份存在同一個機架上,另外一份則必須放到另一個機架上。所以給 Client的列表都必須遵從這個規則。
在Client將File.txt的“Block A”部分寫入集群之前,Client還期待知道所有的目標數據節點是否已准備就緒。它將取出列表中給Block A准備的第一個數據節點,打開TCP 50010協議,並告訴數據節點,注意!准備好接收1塊數據,這裡還有一份列表包括了數據節點5和數據節點6,確保他們同樣已准備就緒。然後再由1傳達到 5,接著5傳達到6。
數據節點將從同樣的TCP通道中響應上一級的命令,只到Client收到原始數據節點1發送的的“就緒”。只到此刻,Client才真正的准備在集群中加載數據塊。
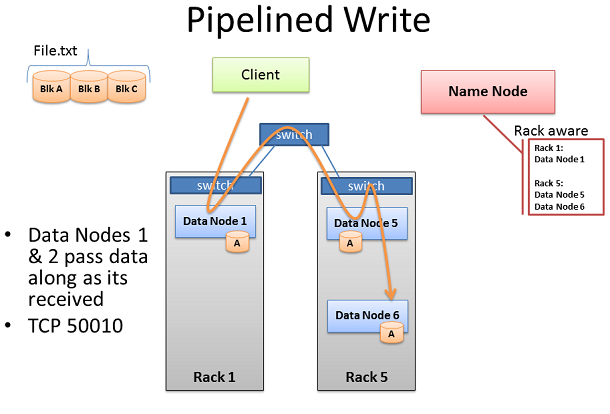
HDFS載入通道
當數據塊寫入集群後,3個(當然數據節點個數參照上文的設置)數據節點將打開一個同步通道。這就意味著,當一個數據節點接收到數據後,它同時將在通道中給下一個數據節點送上一份拷貝。
這裡同樣是一個借助Rack Awareness數據提升集群性能的例子。注意到沒有,第二個和第三個數據節點運輸在同一個機架中,這樣他們之間的傳輸就獲得了高帶寬和低延時。只到這個數據塊被成功的寫入3個節點中,下一個就才會開始。
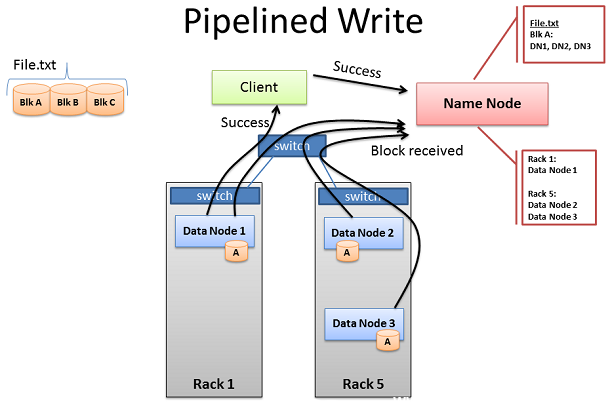
HDFS通道載入成功
當3個節點都成功的接收到數據塊後,他們將給名稱節點發送個“Block Received”報告。並向通道返回“Success”消息,然後關閉TCP回話。Client收到成功接收的消息後會報告給名稱節點數據已成功接收。 名稱節點將會更新它元數據中的節點位置信息。Client將會開啟下一個數據塊的處理通道,只到所有的數據塊都寫入數據節點。
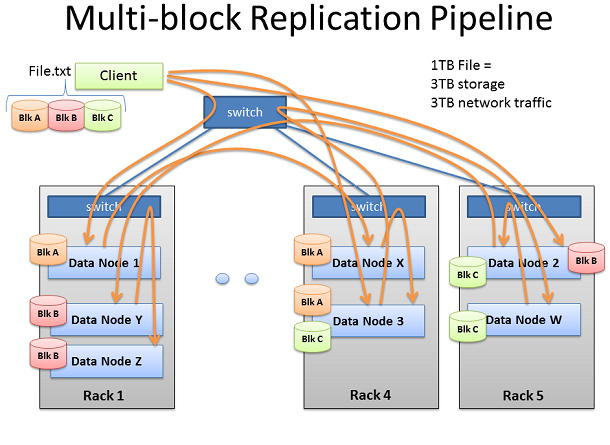
Hadoop會使用大量的網絡帶寬和存儲。我們將代表性的處理一些TB級別的文件。使用Hadoop的默認配置,每個文件都會被復制三份。也就是1TB的文件將耗費3TB的網絡傳輸及3TB的磁盤空間。
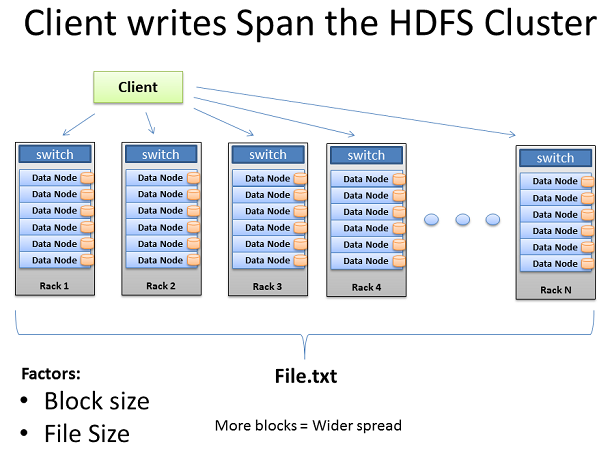
Client寫入跨度集群
每個塊的復制管道完成後的文件被成功寫入到集群。如預期的文件被散布在整個集群的機器,每台機器有一個相對較小的部分數據。個文件的塊數越多,更多 的機器的數據有可能傳播。更多的CPU核心和磁盤驅動器,意味著數據能得到更多的並行處理能力和更快的結果。這是建造大型的、寬的集群的背後的動機,為了 數據處理更多、更快。當機器數增加和集群增寬時,我們的網絡需要進行適當的擴展。
擴展集群的另一種方法是深入。就是在你的機器擴展更多個磁盤驅動器和更多的CPU核心,而不是增加機器的數量。在擴展深度上,你把自己的注意力集中 在用較少的機器來滿足更多的網絡I/O需求上。在這個模型中,你的Hadoop集群如何過渡到萬兆以太網節點成為一個重要的考慮因素。
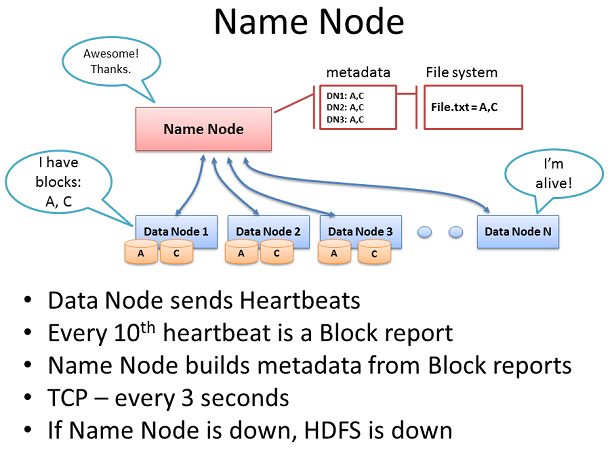
名稱節點
名稱節點包含所有集群的文件系統元數據和監督健康狀況的數據節點以及協調對數據的訪問。這個名字節點是HDFS的中央控制器。它本身不擁有任何集群數據。這個名稱節點只知道塊構成一個文件,並在這些塊位於集群中。
數據節點每3秒通過TCP信號交換向名稱節點發送檢測信號,使用相同的端口號定義名稱節點守護進程,通常TCP 9000。每10個檢測信號作為一個塊報告,那裡的數據節點告知它的所有塊的名稱節點。塊報告允許名稱節點構建它的元數據和確保第三塊副本存在不同的機架 上存在於不同的節點上。
名稱節點是Hadoop分布式文件系統(HDFS)的一個關鍵組件。沒有它,客戶端將無法從HDFS寫入或讀取文件,它就不可能去調度和執行Map Reduce工作。正因為如此,用雙電源、熱插拔風扇、冗余網卡連接等等來裝備名稱節點和配置高度冗余的企業級服務器使一個不錯的想法。
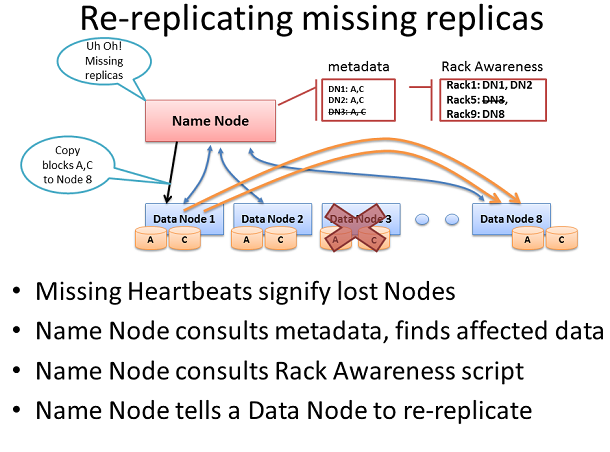
重新復制缺失副本
如果名稱節點停止從一個數據節點接收檢測信號,假定它已經死亡,任何數據必須也消失了。基於塊從死亡節點接受到報告,這個名稱節點知道哪個副本連同節點塊死亡,並可決定重新復制這些塊到其他數據節點。它還將參考機架感知數據,以保持在一個機架內的兩個副本。
考慮一下這個場景,整個機架的服務器網絡脫落,也許是因為一個機架交換機故障或電源故障。這個名稱節點將開始指示集群中的其余節點重新復制該機架中丟失的所有數據塊。如果在那個機架中的每個服務器有12TB的數據,這可能是數百個TB的數據需要開始穿越網絡。
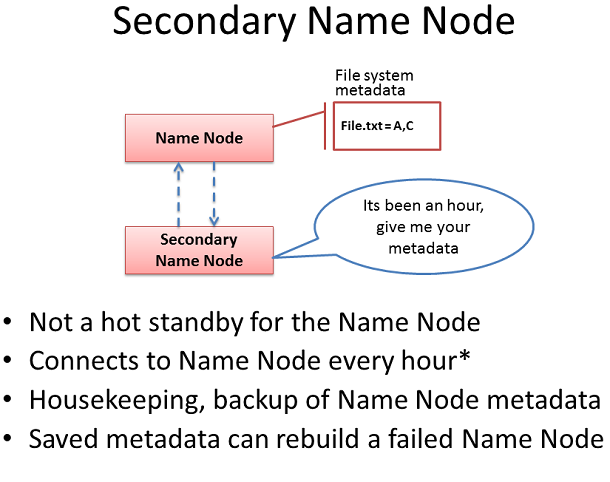
二級名稱節點
Hadoop服務器角色被稱為二級名稱節點。一個常見的誤解是,這個角色為名稱節點提供了一個高可用性的備份,這並非如此。
二級名稱節點偶爾連接到名字節點,並獲取一個副本的名字節點內存中的元數據和文件用於存儲元數據。二級名稱節點在一個新的文件集中結合這些信息,並將其遞送回名稱節點,同時自身保留一份復本。
如果名稱節點死亡,二級名稱節點保留的文件可用於恢復名稱節點。
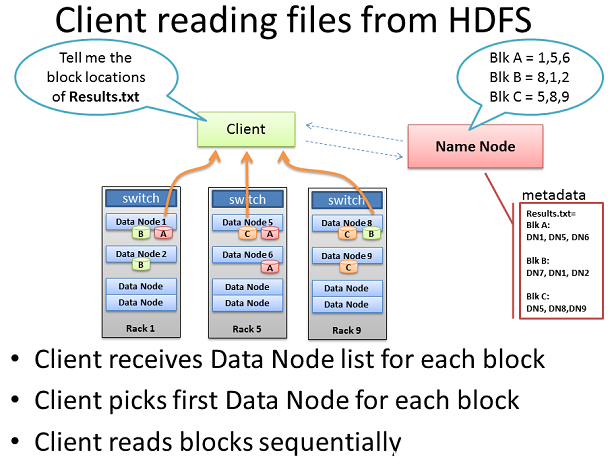
從HDFS客戶端讀取
當客戶想要從HDFS讀取一個文件,它再一次咨詢名稱節點,並要求提供文件塊的位置。
客戶從每個塊列表選擇一個數據節點和用TCP的50010端口讀取一個塊。直到前塊完成,它才會進入下一個塊。
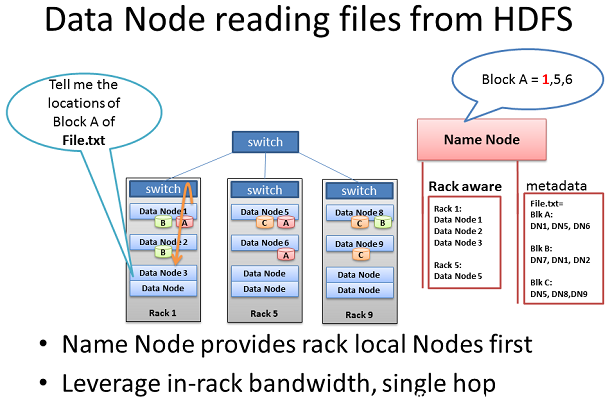
從HDFS中讀取數據節點
有些情況下,一個數據節點守護進程本身需要從HDFS中讀取數據塊。一種這樣的情況是數據節點被要求處理本地沒有的數據,因此它必須從網絡上的另一個數據節點檢索數據,在它開始處理之前。
另一個重要的例子是這個名稱節點的Rack Awareness認知提供了最佳的網絡行為。當數據節點詢問數據塊裡名稱節點的位置時,名稱節點將檢查是否在同一機架中的另一種數據節點有數據。如果是 這樣,這個名稱節點從檢索數據裡提供了機架上的位置。該流程不需要遍歷兩個以上的交換機和擁擠的鏈接找到另一個機架中的數據。在機架上檢索的數據更快,數 據處理就可以開始的更早,,工作完成得更快。
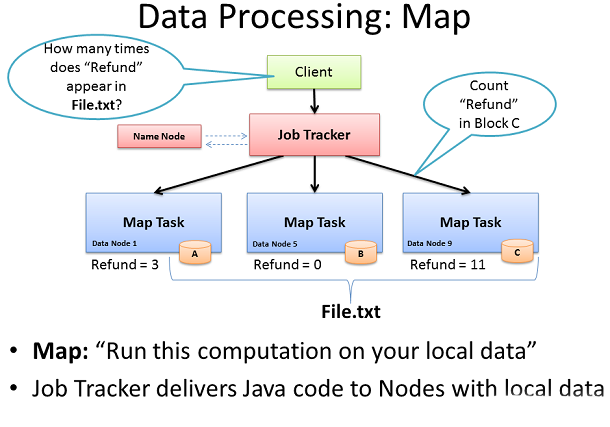
Map Task
現在file.txt在我的機器集群中蔓延,我有機會提供極其快速和高效的並行處理的數據。包含Hadoop的並行處理框架被稱為Map Reduce,模型中命名之後的兩個步驟是Map和Reduce。
第一步是Map過程。這就是我們同時要求我們的機器他們本地的數據塊上來運行一個計算。在這種情況下,我們要求我們的機器對“Refund”這個詞在File.txt的數據塊中出現的次數進行計數。
開始此過程,客戶端機器提交Map Reduce作業的Job Tracker,詢問“多少次不會在File.txt 中出現Refund”(意譯Java代碼)。Job Tracker查詢名稱節點了解哪些數據節點有File.txt塊。Job Tracker提供了這些節點上運行的Task Tracker與Java代碼需要在他們的本地數據上執行的Map計算。這個Task Tracker啟動一個Map任務和監視任務進展。這Task Tracker提供了檢測信號並向Job Tracker返回任務狀態。
每個Map任務完成後,每個節點在其臨時本地存儲中存儲其本地計算的結果。這被稱作“中間數據”。 下一步將通過網絡傳輸發送此中間數據到Reduce任務最終計算節點上運行。

Map Task非本地
雖然Job Tracker總是試圖選擇與當地數據做Map task的節點,但它可能並不總是能夠這樣做。其中一個原因可能是因為所有的節點與本地數據,已經有太多的其他任務運行,並且不能接受了。
在這種情況下, Job Tracker將查閱名稱節點的Rack Awareness知識,可推薦同一機架中的其他節點的名稱節點。作業跟蹤器將把這個任務交給同一機架中的一個節點,節點去尋找的數據時,它需要的名稱節點將指示其機架中的另一個節點來獲取數據。
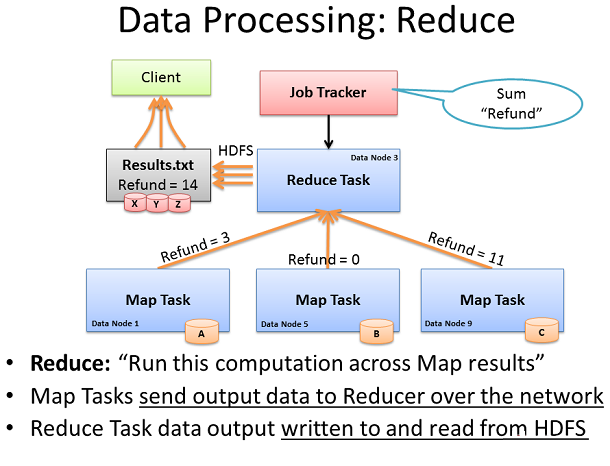
Reduce Task從Map Tasks計算接收到的數據
第二階段的Map Reduce框架稱為Reduce。機器上的Map任務已經完成了和生成它們的中間數據。現在我們需要收集所有的這些中間數據,組合並提純以便進一步處理,這樣我們會有一個最終結果。
Job Tracker在集群中的任何一個節點上開始一個Reduce任務,並指示Reduce任務從所有已完成的Map任務中獲取中間數據。Map任務可能幾乎 同時應對Reducer,導致讓你一下子有大量的節點發送TCP數據到一個節點。這種流量狀況通常被稱為“Incast”或者“fan-in”。對於網絡 處理大量的incast條件,其重要的網絡交換機擁有精心設計的內部流量管理能力,以及足夠的緩沖區(不太大也不能太小)。
Reducer任務現在已經從Map任務裡收集了所有的中間數據,可以開始最後的計算階段。在本例中,我們只需添加出現“Refund”這個詞的總數,並將結果寫入到一個名為Results的txt文件裡。
這個名為Results的txt文件,被寫入到HDFS以下我們已經涵蓋的進程中,把文件分成塊,流水線復制這些塊等。當完成時,客戶機可以從HDFS和被認為是完整的工作裡讀取Results.txt。
我們簡單的字數統計工作並不會導致大量的中間數據在網絡上傳輸。然而,其他工作可能會產生大量的中間數據,比如對TB級數據進行排序。
如果你是一個勤奮的網絡管理員,你將了解更多關於Map Reduce和你的集群將運行的作業類型,以及作業類型如何影響你的網絡流量。如果你是一個Hadoop網絡明星,你甚至能夠提出更好的代碼來解決Map Reduce任務,以優化網絡的性能,從而加快工作完工時間。
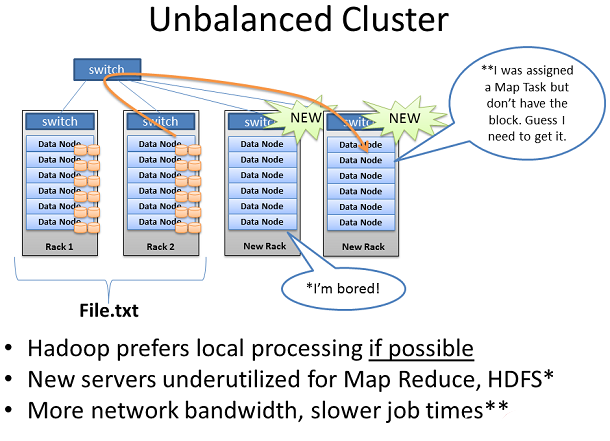
不平衡的Hadoop集群
Hadoop可以為你的組織提供一個真正的成功,它讓你身邊的數據開發出了很多之前未發現的業務價值。當業務人員了解這一點,你可以確信,很快就會有更多的錢為你的Hadoop集群購買更多機架服務器和網絡。
當你在現有的Hadoop集群裡添加新的機架服務器和網絡這種情況時,你的集群是不平衡的。在這種情況下,機架1&2是我現有的包含 File.txt的機架和運行我的Map Reduce任務的數據。當我添加了兩個新的架到集群,我的File.txt數據並不會自動開始蔓延到新的機架。
新的服務器是閒置的,直到我開始加載新數據到集群中。此外,如果機架1&2上服務器都非常繁忙,Job Tracker可能沒有其他選擇,但會指定File.txt上的Map任務到新的沒有本地數據的服務器上。新的服務器需要通過網絡去獲取數據。作為結果, 你可能看到更多的網絡流量和較長工作完成時間。
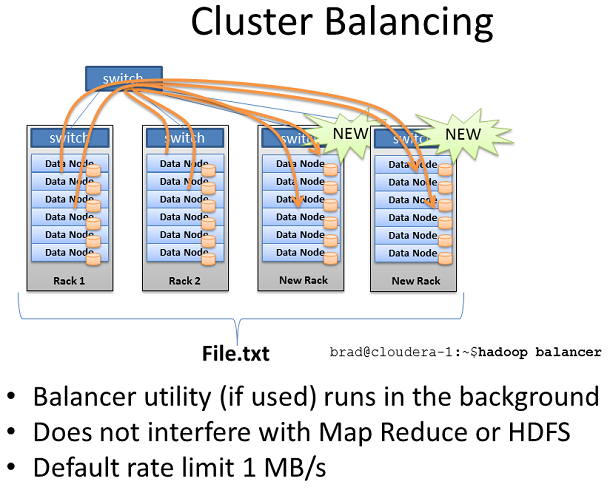
Hadoop集群均衡器
為了彌補集群的平衡性,Hadoop還包含了均衡器。
Balancer目光聚焦於節點間有效儲存的差異,力所能及的將平衡維持在一定的臨界值上。假如發現剩余大量儲存空間的節點,Balancer將找 出儲存空間剩余量少的節點並把數據剪切到有大量剩余空間的節點上。只有的終端上輸入指令Balancer才會運行,當接收到終端取消命令或者終端被關閉 時,Balancer將會關閉。
Balancer可以調用的網絡帶寬很小,默認只有1MB/s。帶寬可以通過hdfs-site.xml文件中的dfs.balance.bandwidthPerSec參數來設置。
Balancer是集群的好管家。沒當有新機組添加時候就會用到它,甚至一經開啟就會運行整個星期。給均衡器低帶寬可以讓它保持著長時間的運行。