tensorflow-0.8 的一大特性為可以部署在分布式的集群上,本文的內容由Tensorflow的分布式部署手冊翻譯而來,該手冊鏈接為TensorFlow分布式部署手冊
本文介紹了如何搭建一個TensorFlow服務器的集群,並將一個計算圖部署在該分布式集群上。以下操作建立在你對 TensorFlow的基礎操作已經熟練掌握的基礎之上。
以下是一個簡單的TensorFlow分布式程序的編寫實例
# Start a TensorFlow server as a single-process "cluster".
$ python
>>> import tensorflow as tf
>>> c = tf.constant("Hello, distributed TensorFlow!")
>>> server = tf.train.Server.create_local_server()
>>> sess = tf.Session(server.target) # Create a session on the server.
>>> sess.run(c)
'Hello, distributed TensorFlow!'tf.train.Server.create_local_server() 會在本地創建一個單進程集群,該集群中的服務默認為啟動狀態。
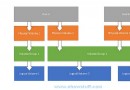
TensorFlow中的集群(cluster)指的是一系列能夠對TensorFlow中的圖(graph)進行分布式計算的任務(task)。每個任務是同服務(server)相關聯的。TensorFlow中的服務會包含一個用於創建session的主節點和一個用於圖運算的工作節點。另外, TensorFlow中的集群可以拆分成一個或多個作業(job), 每個作業可以包含一個或多個任務。下圖為作者對集群內關系的理解。
創建集群的必要條件是為每個任務啟動一個服務。這些任務可以運行在不同的機器上,但你也可以在同一台機器上啟動多個任務(比如說在本地多個不同的GPU上運行)。每個任務會做如下的兩步工作:
tf.train.ClusterSpec 用於對集群中的所有任務進行描述,該描述內容對於所有任務應該是相同的。tf.train.Server 並將tf.train.ClusterSpec 中的參數傳入構造函數,並將作業的名稱和當前任務的編號寫入本地任務中。tf.train.ClusterSpec 的具體方法tf.train.ClusterSpec 的傳入參數是作業和任務之間的關系映射,該映射關系中的任務是通過ip地址和端口號表示的。具體映射關系如下表所示:
tf.train.ClusterSpec constructiontf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
/job:local/task:0 local
/job:local/task:1
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222"
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})
/job:worker/task:0/job:worker/task:1/job:worker/task:2/job:ps/task:0/job:ps/task:1
tf.train.Server 的實例每一個tf.train.Server 對象都包含一個本地設備的集合, 一個向其他任務的連接集合,以及一個可以利用以上資源進行分布式計算的“會話目標”(“session target“)。每一個服務程序都是一個指定作業的一員,其在作業中擁有自己獨立的任務號。每一個服務程序都可以和集群中的其他任何服務程序進行通信。
以下兩個代碼片段講述了如何在本地的2222和2223兩個端口上配置不同的任務。
# In task 0:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=0)# In task 1:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=1)注 :當前手動配置任務節點還是一個比較初級的做法,尤其是在遇到較大的集群管理的情況下。tensorflow團隊正在開發一個自動程序化配置任務的節點的工具。例如:集群管理工具Kubernetes。如果你希望tensorflow支持某個特定的管理工具,可以將該請求發到GitHub issue 裡。
為了將某些操作運行在特定的進程上,可以使用tf.device() 函數來指定代碼運行在CPU或GPU上。例如:
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(...)
biases_2 = tf.Variable(...)
with tf.device("/job:worker/task:7"):
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
# ...
train_op = ...
with tf.Session("grpc://worker7.example.com:2222") as sess:
for _ in range(10000):
sess.run(train_op)在上面的例子中,參數的聲明是通過ps作業中的兩個任務完成的,而模型計算相關的部分則是在work作業裡進行的。TensorFlow將在內部實現作業間的數據傳輸。(ps到work間的向前傳遞;work到ps的計算梯度)
在上面的這個稱為“數據並行化”的公用訓練配置項裡,一般會包含多個用於對不同數據大小進行計算的任務(構成了work作業) 和 一個或多個分布在不同機器上用於不停更新共享參數的任務(構成了ps作業)。 所有的這些任務都可以運行在不同的機器上。實現這養的邏輯有很多的方法,目前TensorFlow團隊采用的是構建鏈接庫(lib)的方式來簡化模型的工作,其實現了如下幾種方法:
tf.Graph,該圖中的一系列節點 (tf.Variable)會通過ps 作業(/job:ps)聲明,而計算相關的多份拷貝會通過work作業(/job:worker)來進行。/job:worker) 都是通過獨立客戶端單獨聲明的。其相互之間結構類似,每一個客戶端都會建立一個相似的圖結構, 該結構中包含的參數均通過ps 作業(/job:ps)進行聲明並使用tf.train.replica_device_setter() 方法將參數映射到不同的任務中。模型中每一個獨立的計算單元都會映射到/job:worker的本地的任務中。tf.train.SyncReplicasOptimizer)一同使用。接下來的代碼是一個分布式訓練程序的大致代碼框架,其中實現了圖間的拷貝和異步訓練兩種方法。該示例中包含了參數服務(parameter server)和工作任務(work task)的代碼。
import tensorflow as tf
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
# 創建並啟動服務
# 其參數中使用task_index 指定任務的編號
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Assigns ops to the local worker by default.
# 將op 掛載到各個本地的worker上
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Build model...
loss = ...
global_step = tf.Variable(0)
train_op = tf.train.AdagradOptimizer(0.01).minimize(
loss, global_step=global_step)
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
# Create a "supervisor", which oversees the training process.
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir="/tmp/train_logs",
init_op=init_op,
summary_op=summary_op,
saver=saver,
global_step=global_step,
save_model_secs=600)
# The supervisor takes care of session initialization, restoring from
# a checkpoint, and closing when done or an error occurs.
with sv.managed_session(server.target) as sess:
# Loop until the supervisor shuts down or 1000000 steps have completed.
step = 0
while not sv.should_stop() and step < 1000000:
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
_, step = sess.run([train_op, global_step])
# Ask for all the services to stop.
sv.stop()
if __name__ == "__main__":
tf.app.run()使用以下命令可以啟動兩個參數服務和兩個工作任務。(假設上面的python腳本名字為 train.py)
# On ps0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=0
# On ps1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=1
# On worker0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=0
# On worker1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=1客戶端(Client)
tensorflow::Session 的程序。一般客戶端是通過python或C++實現的。一個獨立的客戶端進程可以同時與多個TensorFlow的服務端相連 (上面的計算流程一節),同時一個獨立的服務端也可以與多個客戶端相連。集群(Cluster)
- 一個TensorFlow的集群裡包含了一個或多個作業(job), 每一個作業又可以拆分成一個或多個任務(task)。集群的概念主要用與一個特定的高層次對象中,比如說訓練神經網絡,並行化操作多台機器等等。集群對象可以通過tf.train.ClusterSpec 來定義。
作業(Job)
- 一個作業可以拆封成多個具有相同目的的任務(task),比如說,一個稱之為ps(parameter server,參數服務器)的作業中的任務主要是保存和更新變量,而一個名為work(工作)的作業一般是管理無狀態且主要從事計算的任務。一個作業中的任務可以運行於不同的機器上,作業的角色也是靈活可變的,比如說稱之為”work”的作業可以保存一些狀態。
主節點的服務邏輯(Master service)
- 一個RPC 服務程序可以用來遠程連接一系列的分布式設備,並扮演一個會話終端的角色,主服務程序實現了一個tensorflow::Session 的借口並負責通過工作節點的服務進程(worker service)與工作的任務進行通信。所有的主服務程序都有了主節點的服務邏輯。
任務(Task)
- 任務相當於是一個特定的TesnsorFlow服務端,其相當於一個獨立的進程,該進程屬於特定的作業並在作業中擁有對應的序號。
TensorFlow服務端(TensorFlow server)
- 一個運行了tf.train.Server 實例的進程,其為集群中的一員,並有主節點和工作節點之分。
工作節點的服務邏輯(Worker service)
- 其為一個可以使用本地設備對部分圖進行計算的RPC 邏輯,一個工作節點的服務邏輯實現了worker_service.proto 接口, 所有的TensorFlow服務端均包含工作節點的服務邏輯。